







🌿挑战100天不停更,刷爆 hive sql🧲
详情请点击🔗我的专栏🖲,共同学习,一起进步~
文章目录
NUM: 第6天 - 数据扩容和收缩
详情请点击🔗我的专栏🖲,共同学习,一起进步~
-----------------------------------分割线-----------------------------------
4-27日修改✏
有个坑, 先写在前面,方便大家闭坑,这里非常感谢@Alexzit 提出关于问题一的升序排序问题哈,给我了启发,我又本地换成spark引擎重新跑了下, 发现还有其他问题, 这里一并解答了
问题:collect_set()/collect_list()是否是有序的??
再看下面问题一 :根据a字段降序扩充成b字段, 这里会先使用collect_set()或者collect_list()收集,再用concat_ws()拼接成字符串,因为是降序的,所以预期的输出结果是应该是4-- 4 3 2 1但是 输出结果却是1432我反复查看了sql,自己也疑惑了好久, 我明明是排序后分组,然后再拼接, 为什么不是按照顺序的呢? 后来终于发现了问题,collect_set()/collect_list()并不是有序的~~下面详细来说说:
1 ) 大家都知道
collect_set()是去重,collect_list()不去重,这是两者的却别, 但是往往就忽略到了还有排序问题,collect_set()是无序的,collect_list()是有序的, 但是不能保证全局有序 ,collect_set底层是LinkedHashSet实现的collect_list()的底层是使用ArrayList来实现的,当put到这个ArrayList的时候,不一定哪个Mapper先,哪个Mapper后,所以就会产生局部排序的问题,所以就区分开了,但是 我们要的是全局有序
2)那么如何解决呢? 我们需要对collect_list()/collect_set()外面再使用sort_array()再进行排序即可
下面的代码我就不改了哈 , 大家写的时候注意就可以了!! 也欢迎大家有问题留言~~ 相互学习,共同进步♥
🧨不废话,刷题~~🧨
表结构

1)数据的扩充(a字段不变,b字段根据a字段递减)
思路
- 通过
split(space(a的最大值), ' '),计算出对应的数组 - 将数组通过侧视图
lateral view + explode炸裂函数一行转为多列 - 通过开窗函数
row_number()取出行号 - 将原表和行号进行左外关联,条件是
1=1,取出所有字段的值,并判断a字段的值大于且等于行号,就可以求出a的递减了,因为行号是从1开始的 - 根据a分组 ,
collect_set收集行号并用concat_ws()拼接即可
SQL
SELECT c.a,
concat_ws(',', collect_set(CAST(c.rn as string))) as b
from (SELECT t6.a,
b.rn
FROM t6
left join(
SELECT
row_number() over () as rn
from (SELECT split(space(5), ' ') as x) a lateral view explode(x) ex) b
on
1 = 1
where t6.a >= b.rn
order BY t6.a,
b.rn DESC) c
group by c.a;
输出结果

2)数据的扩充(a字段不变,b字段根据a字段递减,并去除偶数 (% 2 =1))
思路
同上,多加子查询条件即可
SQL
SELECT
c.a,
concat_ws(',',collect_set(CAST(c.rn as string))) as b
from
(SELECT
t6.a,
b.rn
FROM
t6
left join(
SELECT
row_number() over() as rn
from
(
SELECT
split(space(5),
' ') as x) a lateral view explode(x) ex) b
on
1 = 1
where
t6.a >= b.rn and b.rn % 2 = 1
order BY
t6.a,
b.rn DESC) c
group by c.a;
输出结果
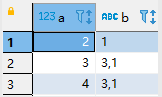
3)处理字符串的累计拼接(将小于等于a字段的值聚合拼接起来)
思路
- 小于等于a是指的当前值和对应的所有字段进行比较,然后求出小于等于a字段的结果
- 左外关联并对比a的大小,查出对应的所有数据,此时左表的每行数据对应多行自身表的数据
- 将a分组,并将a字段对比好的数据收集成集合并拼接
SQL
select
t.a,
concat_ws(',',
collect_set(cast(t.a1 as string))) as b
from
(select
t6.a,
b.a1
from
t6
left join (select a as a1 from t6 ) b on
1 = 1
where
t6.a >= b.a1
order by
t6.a,
b.a1 ) t
group by
t.a;
输出结果
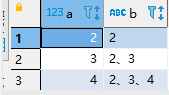
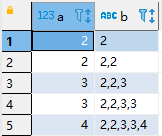
4)a字段有重复,怎么实现字段的累计拼接
思路
- 如果a字段有重复,证明同样a数据需要执行多次计算
- 将关联的两张表都开窗,取出行号并对比
SQL
insert into t6 values(2),(3);
select a,
b
from (
select t.a,
t.rn,
concat_ws(',', collect_list(cast(t.a1 as string))) as b
from (
select a.a,
a.rn,
b.a1
from
-- 取a值和行号
(select a,
row_number() over (order by a ) as rn
from t6) a
left join
-- 取a值和行号
(select a as a1,
row_number() over (order by a ) as rn
from t6) b on
1 = 1
where a.a >= b.a1
and a.rn >= b.rn
order by a.a,
b.a1) t
group by t.a,
t.rn
order by t.a,
t.rn) tt;
输出结果
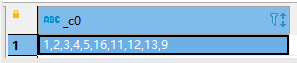
5)数据的展开(如何将字符串"1-5,16,11-13,9"扩展成 “1,2,3,4,5,16,11,12,13,9”?注意顺序不变)
思路
lateral view outer posexplode():
SQL
select
concat_ws(',',collect_list(cast(rn as string)))
from
(
select
a.rn,
b.num,
b.pos
from
(
select
row_number() over() as rn
from
(select split(space(20),' ') as x) t lateral view explode(x) pe) as a lateral view outer posexplode(split('1-5,16,11-13,9',',')) b as pos,num
where
a.rn between cast(split(num,'-')[0] as int) and cast(split(num,'-')[1] as int) or a.rn = num
order by
pos,
rn
) t;
输出结果
















 861
861











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











