









作者:jiangzz 电话:15652034180 微信:jiangzz_wx 微信公众账号:jiangzz_wy
大数据(Big Data)
随着信息化互联网|物联网发展要求,万物互联趋势势在必行。随之引发架构的演变由单一架构向高并发分布式架构演变。数据的存储与计算也开始由原始的单机模式演变为分布式存储。
- 高并发互联网设计 LNMP、数据库主从RDBMS|NoSQL、Spring Cloud/Dubbo微服务、Docker/Kubernates等容器技术。
- 海量数据存储|数据分析 :分布式存储-HDFS、实时计算、离线计算等
- 机器学习: 高级数据分析Machine Learing 例如 Mahout、Spark Mllib、FlinkMllib等
面临问题
存储
-
单机存储:容量受限、扩展性差、数据灾备维护复杂
-
分布式存储:使用集群实现对大规模数据集实现的并行化的读写,提升系统的吞吐能力,目前分布式文件存储实现的方式主要分为两种:文件的完整存储、基于数据块的存储等
分析
- 单机计算:受限于单机主频、CPU/GPU、内存、网络等限制。
- 分布式计算:将计算任务交给专门的计算集群负责任务的计算。打破单机计算的瓶颈,实现并行计算。使用多台物理主机,模拟多核CPU的计算能力。
Hadoop诞生
人称Hadoop之父的Doug Cutting,Apache软件基金会主席,是Lucene、Nutch 、Hadoop等项目的发起人。最开始Hadoop只是Apache Lucene的子项目Nutch的一部分。Lucene是全球第一个开源的全文检索引擎工具包, Nutch基于Lucene,并具有网页抓取和解析的功能,可以实现一个搜索引擎的开发,但是如果投入使用的话就必须在极短时间内做出反应,并且能够实现短时间内对亿级数量的网页进行分析处理,这就需要考虑分布式任务处理、故障恢复、负载均衡这些问题。后来Doug Cutting 借鉴谷歌的Google File System和MapReduce:Simplified Data Processing On Large Clusters两篇论文,移植了其中的技术,随后Yahoo招募了Doug Cutting及其负责的项目。并且在2006年2月份正式的将Nutch中存储和分析板块彻底分离,成为一套独立软件并且更名为hadoop。
HDFS:Hadoop 分布式文件存储系统,解决海量数据的存储问题(非常重要)
Map Reduce:Hadoop项目分布式计算框架(老),已经成为大数据计算的标杆。是早期分布式计算解决方案。期间该方案在2010年又被Yahoo团队做了一次升级,主要解决的是MapReduce在大规模计算集群的扩展性问题,但是并没有本质改变MapReduce计算本质。因为MapReduce计算的是通过对数据做磁盘迭代计算。导致计算速度不算太快。2013年下半年出现了Spark是一款基于内存的分布式计算框架,用于替代Hadoop的MapReduce,被人们称为第二代大数据计算引擎。
Hadoop HDFS
Hadoop编译
安装编译依赖
[root@CentOS ~]# yum install -y autoconf automake libtool cmake gcc* ncurses-devel openssl-devel
安装protobuf-2.5.0.tar.gz
hadoop使用protocol buffer进行通信,需要下载和安装protobuf-2.5.0.tar.gz。
[root@CentOS ~]# tar -zxf protobuf-2.5.0.tar.gz
[root@CentOS ~]# cd protobuf-2.5.0
[root@CentOS protobuf-2.5.0]# ./configure
[root@CentOS protobuf-2.5.0]# make && make install
配置Maven编译环境
[root@CentOS ~]# tar -zxf apache-maven-3.3.9-bin.tar.gz -C /usr
[root@CentOS ~]# vi .bashrc
M2_HOME=/usr/apache-maven-3.6.0
MAVEN_OPTS="-Xms256m -Xmx768m -XX:PermSize=128m -XX:MaxPermSize=256M"
JAVA_HOME=/usr/java/latest
CLASSPATH=.
PATH=$PATH:$JAVA_HOME/bin:$M2_HOME/bin
export JAVA_HOME
export CLASSPATH
export PATH
export M2_HOME
export MAVEN_OPTS
[root@CentOS ~]# source .bashrc
编译hadoop源码
[root@CentOS ~]# wget http://us.mirrors.quenda.co/apache/hadoop/common/hadoop-2.9.2/hadoop-2.9.2-src.tar.gz
[root@CentOS ~]# tar -zxf hadoop-2.9.2-src.tar.gz
[root@CentOS ~]# cd hadoop-2.9.2-src
[root@CentOS hadoop-2.9.2-src]# mvn package -Pdist,native -DskipTests -Dtar
在编译的时候需要保证电脑联网,因为在编译的时候还需要下载tomcat。编译的目标文件:hadoop-2.9.2-src/hadoop-dist/target 目录下,成功后会看到如下界面:
[INFO] ---------------------------------------------------------------------
[INFO] Reactor Summary:
[INFO] Apache Hadoop Main ................................. SUCCESS [ 10.140 s]
[INFO] Apache Hadoop Project POM .......................... SUCCESS [ 5.495 s]
...略....
[INFO] Apache Hadoop Tools Dist ......SUCCESS [ 14.265 s]
[INFO] Apache Hadoop Tools ...............SUCCESS [ 0.070 s]
[INFO] Apache Hadoop Distribution .......... SUCCESS [01:00 min]
HDFS基本概念
是一个基于分布式存储通用的文件系统,该系统特点容易部署、对系统硬件要求低,搭建成本可控。可以使得数据存储大小和集群过程呈现一种线性关系 (目前最大已知规模2000台左右规模,实际在生产环境下集群规模一般在10~100台左右)。HDFS文件系统的架构图:
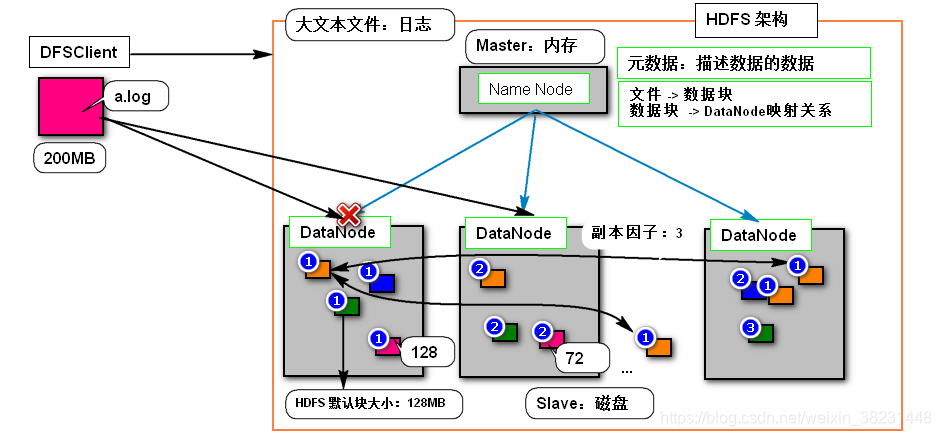
NameNode:使用内存存储集群中的元数据(文件命名空间-文件目录结构、数据块到DataNode映射)
DataNode:负责响应客户端对数据块的读写请求,向NameNode汇报自身状态信息。
Block:是HDFS切分文件的尺度,默认是128MB,一个文件最多只有 一个不足128MB块
副本因子:HDFS为了防止DataNode宕机导致块的丢失,允许一个块又多个备份,默认备份是3
为什么HDFS不擅长存储小文件?
| 案例 | NN | DN |
|---|---|---|
| 1文件128MB | 1条数据块映射元数据 | 128MB磁盘存储*(副本因子) |
| 1000文件总计128MB | 1000*1条数据块映射元数据 | 128MB磁盘存储*(副本因子) |
因为Namenode使用单机的内存存储,因此由于小文件会占用更多的内存空间,导致了Namenode内存浪费。
Secondary(辅助) NameNode & NameNode关系?
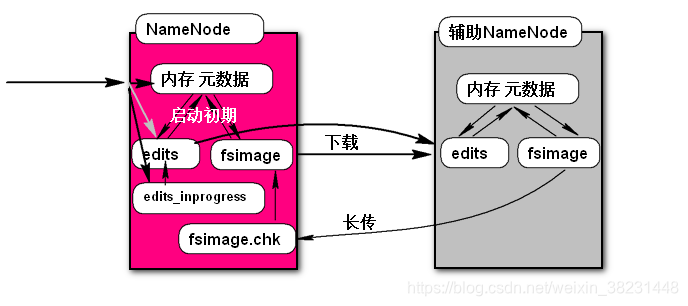
fsimage:存储在Namenode服务所在物理主机磁盘上的一个二进制文本文件。记录了元数据信息
edits:存储在Namenode服务所在物理主机磁盘上的一个二进制文本文件,记录了对元数据修改操作。
当第一次启动Namenode服务的时候,系统会加载fsimage和edits文件进行合并得到最新元数据信息,并且更新fsimage和edits,一旦服务启动成功后,在服务允许期间不再更新fsimage,只是将操作记录在edits中。导致namenode在长期运行之后重启导致namenode启动时间过长,还可能导致edits文件过大。因此Hadoop HDFS引入Secondary Namenode 辅助Namenode在运行期间完成对元数据的备份和整理。
HDFS环境搭建(单机|伪分布式)
-
安装虚拟器并且安装CentOS-6.5 64位 (参考[CentOS 64安装.wmv](./CentOS 64安装.wmv))
-
安装jdk-8u171-linux-x64.rpm配置JAVA_HOME环境变量(~/.bashrc)
[root@CentOS ~]# rpm -ivh jdk-8u171-linux-x64.rpm
[root@CentOS ~]# ls -l /usr/java/
total 4
lrwxrwxrwx. 1 root root 16 Mar 26 00:56 default -> /usr/java/latest
drwxr-xr-x. 9 root root 4096 Mar 26 00:56 jdk1.8.0_171-amd64
lrwxrwxrwx. 1 root root 28 Mar 26 00:56 latest -> /usr/java/jdk1.8.0_171-amd64
[root@CentOS ~]# vi .bashrc
JAVA_HOME=/usr/java/latest
PATH=$PATH:$JAVA_HOME/bin
CLASSPATH=.
export JAVA_HOME
export PATH
export CLASSPATH
[root@CentOS ~]# source ~/.bashrc # 加载环境变量
- 配置主机名和IP映射关系
[root@CentOS ~]# ifconfig
eth0 Link encap:Ethernet HWaddr 00:0C:29:37:20:59
inet addr:`192.168.40.128` Bcast:192.168.40.255 Mask:255.255.255.0
inet6 addr: fe80::20c:29ff:fe37:2059/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:246948 errors:0 dropped:0 overruns:0 frame:0
TX packets:22719 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:370063776 (352.9 MiB) TX bytes:2150553 (2.0 MiB)
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
inet6 addr: ::1/128 Scope:Host
UP LOOPBACK RUNNING MTU:16436 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:0 (0.0 b) TX bytes:0 (0.0 b)
[root@CentOS ~]# vi /etc/hosts # 一定是自己的IP
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.40.128 CentOS
-
配置Linux免密码登陆(Linux系统间登陆方式)
基于口令登陆需要输入用户名和密码
基于秘钥登陆方式
[root@CentOS ~]# ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Created directory '/root/.ssh'.
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
4b:29:93:1c:7f:06:93:67:fc:c5:ed:27:9b:83:26:c0 root@CentOS
The key's randomart image is:
+--[ RSA 2048]----+
| |
| o . . |
| . + + o .|
| . = * . . . |
| = E o . . o|
| + = . +.|
| . . o + |
| o . |
| |
+-----------------+
[root@CentOS ~]# ssh-copy-id CentOS
The authenticity of host 'centos (192.168.40.128)' can't be established.
RSA key fingerprint is 3f:86:41:46:f2:05:33:31:5d:b6:11:45:9c:64:12:8e.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'centos,192.168.40.128' (RSA) to the list of known hosts.
root@centos's password:
Now try logging into the machine, with "ssh 'CentOS'", and check in:
.ssh/authorized_keys
to make sure we haven't added extra keys that you weren't expecting.
[root@CentOS ~]# ssh root@CentOS
Last login: Tue Mar 26 01:03:52 2019 from 192.168.40.1
[root@CentOS ~]# exit
logout
Connection to CentOS closed.
- 关闭防火墙
# 临时关闭服务
[root@CentOS ~]# service iptables stop
iptables: Setting chains to policy ACCEPT: filter [ OK ]
iptables: Flushing firewall rules: [ OK ]
iptables: Unloading modules: [ OK ]
[root@CentOS ~]# service iptables status
iptables: Firewall is not running.
# 关闭开机自动启动
[root@CentOS ~]# chkconfig iptables off
[root@CentOS ~]# chkconfig --list | grep iptables
iptables 0:off 1:off 2:off 3:off 4:off 5:off 6:off
- 安装配置Hadoop
解压并且配置环境变量
[root@CentOS ~]# tar -zxf hadoop-2.6.0_x64.tar.gz -C /usr/
[root@CentOS ~]# ls /usr/hadoop-2.6.0/
bin etc include lib libexec LICENSE.txt NOTICE.txt README.txt sbin share
[root@CentOS ~]# vi ~/.bashrc
HADOOP_HOME=/usr/hadoop-2.6.0
JAVA_HOME=/usr/java/latest
PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
CLASSPATH=.
export JAVA_HOME
export PATH
export CLASSPATH
export HADOOP_HOME
[root@CentOS ~]# source ~/.bashrc
[root@CentOS ~]# hadoop version
Hadoop 2.6.0
Subversion Unknown -r Unknown
Compiled by root on 2016-08-01T20:48Z
Compiled with protoc 2.5.0
From source with checksum 18e43357c8f927c0695f1e9522859d6a
This command was run using /usr/hadoop-2.6.0/share/hadoop/common/hadoop-common-2.6.0.jar
配置hadoop配置文件etc/hadoop/{core-site.xml|hdfs-site.xml|slaves}
core-site.xml(配置的是NameNode访问入口,以及服务存储的根目录)
[root@CentOS ~]# vi /usr/hadoop-2.6.0/etc/hadoop/core-site.xml
<!--nn访问入口-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://CentOS:9000</value>
</property>
<!--hdfs工作基础目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/hadoop-2.6.0/hadoop-${user.name}</value>
</property>
[root@CentOS ~]# vi /usr/hadoop-2.6.0/etc/hadoop/hdfs-site.xml
<!--block副本因子-->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!--配置Sencondary namenode所在物理主机-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>CentOS:50090</value>
</property>
<!--设置datanode最大文件操作数-->
<property>
<name>dfs.datanode.max.xcievers</name>
<value>4096</value>
</property>
<!--设置datanode并行处理能力-->
<property>
<name>dfs.datanode.handler.count</name>
<value>6</value>
</property>
[root@CentOS ~]# vi /usr/hadoop-2.6.0/etc/hadoop/slaves
CentOS
-
HDFS启动
如果是第一次初始化启动HDFS服务,需要创建一个空的fsimage文件,以便Namenode在启动的时候加载
[root@CentOS ~]# hdfs namenode -format # 创建初始化所需的fsimage文件
...
19/03/26 01:31:09 INFO namenode.NNConf: Maximum size of an xattr: 16384
19/03/26 01:31:09 INFO namenode.FSImage: Allocated new BlockPoolId: BP-1143348175-192.168.40.128-1553535069443
19/03/26 01:31:09 INFO common.Storage: Storage directory `/usr/hadoop-2.6.0/hadoop-root/dfs/name has been successfully formatted.`
19/03/26 01:31:09 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
...
[root@CentOS ~]# ls /usr/hadoop-2.6.0/hadoop-root/dfs/name/current/
fsimage_0000000000000000000 fsimage_0000000000000000000.md5 seen_txid VERSION
启动HDFS的服务
[root@CentOS ~]# start-dfs.sh
Starting namenodes on [CentOS]
CentOS: starting namenode, logging to /usr/hadoop-2.6.0/logs/hadoop-root-namenode-CentOS.out
CentOS: starting datanode, logging to /usr/hadoop-2.6.0/logs/hadoop-root-datanode-CentOS.out
Starting secondary namenodes [CentOS]
CentOS: starting secondarynamenode, logging to /usr/hadoop-2.6.0/logs/hadoop-root-secondarynamenode-CentOS.out
[root@CentOS ~]# jps
2097 SecondaryNameNode
2280 Jps
1993 DataNode
1918 NameNode
或者访问:http://[IP]:50070/
HDFS Shell(脚本)
[root@CentOS ~]# hdfs dfs -help
Usage: hadoop fs [generic options]
[-appendToFile <localsrc> ... <dst>]
[-cat [-ignoreCrc] <src> ...]
[-checksum <src> ...]
[-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...]
[-copyFromLocal [-f] [-p] [-l] <localsrc> ... <dst>]
[-copyToLocal [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-cp [-f] [-p | -p[topax]] <src> ... <dst>]
[-get [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-help [cmd ...]]
[-ls [-d] [-h] [-R] [<path> ...]]
[-mkdir [-p] <path> ...]
[-moveFromLocal <localsrc> ... <dst>]
[-moveToLocal <src> <localdst>]
[-mv <src> ... <dst>]
[-put [-f] [-p] [-l] <localsrc> ... <dst>]
[-rm [-f] [-r|-R] [-skipTrash] <src> ...]
[-tail [-f] <file>]
[-text [-ignoreCrc] <src> ...]
[-touchz <path> ...]
[root@CentOS ~]# hadoop fs -ls /
[root@CentOS ~]# hadoop fs -touchz /aa.log
[root@CentOS ~]# hdfs dfs -ls /
Found 1 items
-rw-r--r-- 1 root supergroup 0 2019-03-26 01:47 /aa.log
[root@CentOS ~]# hdfs dfs -appendToFile /root/install.log /aa.log
[root@CentOS ~]# hdfs dfs -mkdir -p /aa/bb
[root@CentOS ~]# hdfs dfs -cp /aa.log /aa/bb
[root@CentOS ~]# hdfs dfs -mv /aa.log /install.log
[root@CentOS ~]# md5sum install.log
98b85629951ad584feaf87e28c073088 install.log
[root@CentOS ~]# rm -rf install.log
[root@CentOS ~]# hadoop fs -copyToLocal /install.log /root
[root@CentOS ~]# md5sum install.log
98b85629951ad584feaf87e28c073088 install.log
[root@CentOS ~]# hdfs dfs -rm -r -f /aa
19/03/26 01:53:04 INFO fs.TrashPolicyDefault: Namenode trash configuration: Deletion interval = 0 minutes, Emptier interval = 0 minutes.
Deleted /aa
HDFS 垃圾回收站
用户可以通过配置core-site.xml,开启NameNode的垃圾回收。NameNode会根据fs.trash.interval配置配置垃圾回收的频率,默认单位是分钟。
<property>
<name>fs.trash.interval</name>
<value>1</value>
</property>
表示1分钟内,如果用户不处理删除文件,系统会自动删除回收战的内容。该种机制就是为了防止用户的误操作。
[root@CentOS ~]# hdfs dfs -rm -r -f /install.log
19/03/26 17:58:31 INFO fs.TrashPolicyDefault: Namenode trash configuration: Deletion interval = 1 minutes, Emptier interval = 0 minutes.
Moved: 'hdfs://CentOS:9000/install.log' to trash at: hdfs://CentOS:9000/user/root/.Trash/Current
[root@CentOS ~]# hdfs dfs -ls -R /user
drwx------ - root supergroup 0 2019-03-26 17:58 /user/root
drwx------ - root supergroup 0 2019-03-26 17:59 /user/root/.Trash
drwx------ - root supergroup 0 2019-03-26 17:58 /user/root/.Trash/190326175900
-rw-r--r-- 1 root supergroup 8815 2019-03-26 01:47 /user/root/.Trash/190326175900/install.log
[root@CentOS ~]# hdfs dfs -put /root/hadoop-2.6.0_x64.tar.gz /
[root@CentOS ~]# hdfs dfs -rm -r -f -skipTrash /hadoop-2.6.0_x64.tar.gz
Deleted /hadoop-2.6.0_x64.tar.gz
[root@CentOS ~]# hdfs dfs -ls -R /user
drwx------ - root supergroup 0 2019-03-26 17:58 /user/root
drwx------ - root supergroup 0 2019-03-26 18:00 /user/root/.Trash
NameNode的安全模式
是对HDFS的一种保护机制,1)正常情况下当系统在加载fsimage的初期会自动进入安全模式,在该模式下系统不接受外界的任何请求,当加载完数据检查系统完毕,系统会自动离开安全模式。2)如果当DataNode/NameNode使用空间不足时,系统会自动进入安全模式。3).当系统维护时,管理员也可手动的将NameNode切换成安全模式,维护结束再离开。
[root@CentOS ~]# hdfs dfsadmin -safemode get
Safe mode is OFF
[root@CentOS ~]# hdfs dfsadmin -safemode enter
Safe mode is ON
[root@CentOS ~]# hdfs dfs -put /root/install.log /
put: Cannot create file/install.log._COPYING_. Name node is in safe mode.
[root@CentOS ~]# hdfs dfsadmin -safemode leave
Safe mode is OFF
[root@CentOS ~]# hdfs dfs -put /root/install.log /
机架 Rack Aware
使用Rack标示去表示在大规模HDFS集群中DataNode节点所在物理主机所属机架的映射关系。这样hadoop在管理存储和计算的时候,会优先考虑机架内部恢复和机架内部计算原则,提升系统的计算效率(网络带宽有一定提升)。
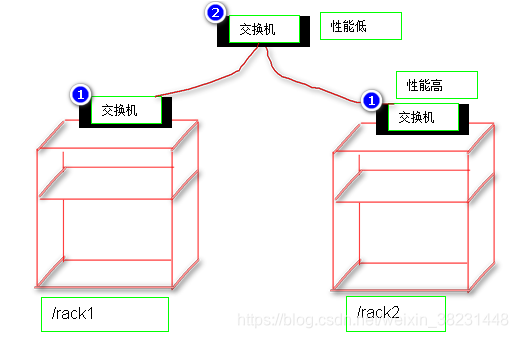
[root@CentOS ~]# hdfs dfsadmin -printTopology
Rack: /default-rack # 机架标示
192.168.40.128:50010 (CentOS) ## DataNode物理主机
Java API HDFS (Windows)
-
配置windos开发环境
-
解压hadoop的安装包
-
将winutil.exe和hadoop.dll文件拷贝到hadoop安装目录下的bin目录
-
在Windows上配置CentOS的主机名和IP的映射关系
192.168.40.128 CentOS -
配置HADOOP_HOME环境变量
-
重启IDEA开发工具,否则IDAE无法识别HADOOP_HOME,因为windows执行代码程序需要通过HADOOP_HOME定位winutil.exe和hadoop.dll文件。
-
-
关闭HDFS权限

方案1:配置hdfs-site.xml关闭HDFS权限管理(临时关闭),配置完后重启hdfs服务
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
方案2:欺骗hadoop告诉hadoop当前就是root用户,可以通过添加虚拟机启动参数方式
java -DHADOOP_USER_NAME=root xxxxx
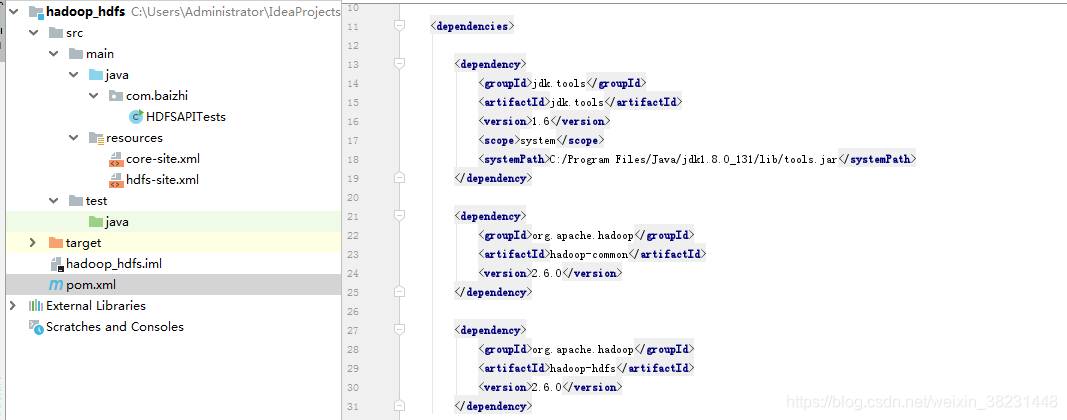
Maven依赖hdfs
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.6.0</version>
</dependency>
上传文件
Configuration conf = new Configuration();
conf.addResource("core-site.xml");
conf.addResource("hdfs-site.xml");
FileSystem fs=FileSystem.get(conf);
Path src = new Path("file:///F:\\Java大数据资料\\笔记.md");
Path dst = new Path("/");
fs.copyFromLocalFile(src,dst);
---
Configuration conf = new Configuration();
conf.addResource("core-site.xml");
conf.addResource("hdfs-site.xml");
FileSystem fs=FileSystem.get(conf);
InputStream in=new FileInputStream("F:\\Java大数据资料\\笔记.md");
Path dst = new Path("/笔记1.md");
OutputStream os=fs.create(dst);
IOUtils.copyBytes(in,os,1024,true);
下载文件
Configuration conf = new Configuration();
conf.addResource("core-site.xml");
conf.addResource("hdfs-site.xml");
FileSystem fs=FileSystem.get(conf);
Path dst = new Path("file:///C:\\Users\\Administrator\\Desktop\\笔记.md");
Path src = new Path("/笔记.md");
fs.copyToLocalFile(src,dst);//如果测试失败,请尝试它的重载方法
---
Configuration conf = new Configuration();
conf.addResource("core-site.xml");
conf.addResource("hdfs-site.xml");
FileSystem fs=FileSystem.get(conf);
Path dst = new Path("/笔记.md");
InputStream in= fs.open(dst);
OutputStream os=new FileOutputStream("C:\\Users\\Administrator\\Desktop\\笔记.md");
IOUtils.copyBytes(in,os,1024,true);
删除文件
Configuration conf = new Configuration();
conf.addResource("core-site.xml");
conf.addResource("hdfs-site.xml");
FileSystem fs=FileSystem.get(conf);
Path delete = new Path("/笔记1.md");
---
Configuration conf = new Configuration();
conf.addResource("core-site.xml");
conf.addResource("hdfs-site.xml");
FileSystem fs=FileSystem.get(conf);
Trash trash=new Trash(fs,conf);
Path delete = new Path("/笔记.md");
trash.moveToTrash(delete);
Map Reduce
概述
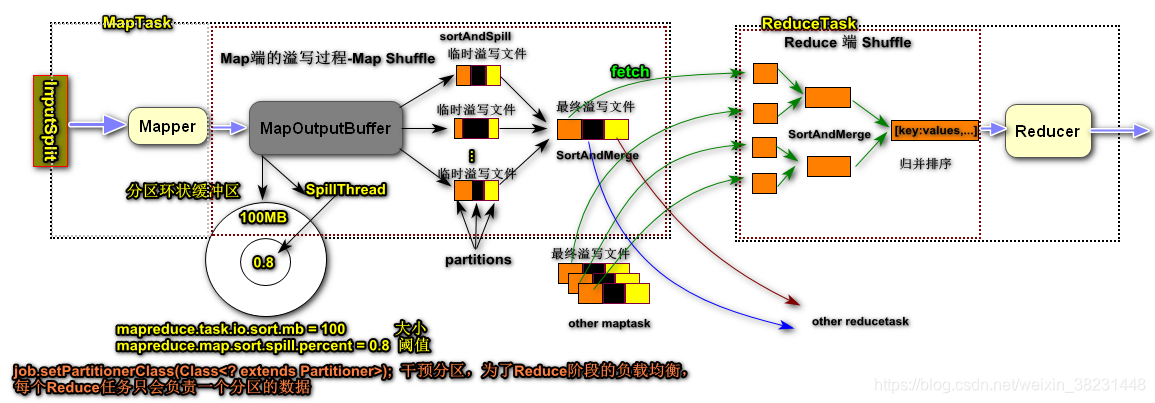
Map Reduce是一个 Hadoop 的并行计算框架,借鉴了函数式编程(Scala 编程应用在Spark)思想和矢量编程(任务做阶段化拆分,每个阶段都可以设定并行度)。Hadoop 中是充分利用了存储节点(Data Node)运行所在主机的计算资源(CPU、内存、网络、少许磁盘-存储计算中间结果)完成对任务的并行计算。Map Reduce框架会在所有的DataNode所在的物理主机启动一个计算资源管理者-Node Manager用于管理本地的计算资源,默认系统会将计算资源均分8个等份,每个等份抽象成一个Container。还会再找一些其他的主机启动一个资源管理中心-Resource Manager,用于管理集群的计算资源。
当用户提交一个计算任务给MapReduce框架,框架会将任务拆分成Map阶段和Reduce阶段(矢量编程思想将任务拆分成两个阶段),框架会根据Map/Reduce阶段的任务并行度.在任务提交初期会启动一个任务管理者(每个任务都有自己的任务管理者)-MRAppMaster(该进程会浪费掉1个计算资源)用于管理Map阶段和Reduce阶段任务执行。在任务执行时期,每个阶段会根据阶段任务的并行度分配计算资源(每个计算资源启动一个Yarn Child),由MRAppMaster完成对阶段任务的检测管理。
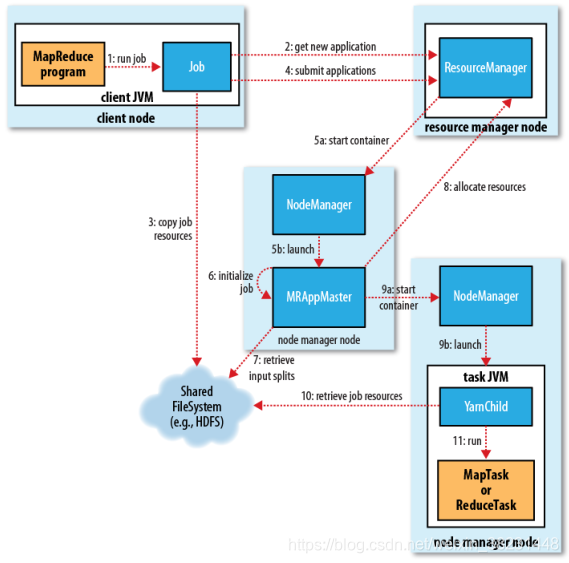
ResourceManager:负责任务资源的统一调度,管理NodeManager资源,启动MRAppMaster
NodeManager:用于管理本机上的计算资源,默认会将本机的计算资源拆分为8个等份,每个等份抽象成Container
MRAppMaster:任何一个执行的任务都会有一个MRAppMaster负责YarnChild任务的执行和监测。
YarnChild:是具体执行的MapTask或者是ReduceTask的统称。
任务执行期间系统会启动MRAppmaster和YarnChild负责任务的执行,一旦任务执行结束MRAppMaster和YarnChild会自动退出。
环境搭建
yarn-site.xml
<!--配置MapReduce计算框架的核心实现Shuffle-洗牌-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--配置资源管理器所在的目标主机-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>CentOS</value>
</property>
<!--关闭物理内存检查-->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!--关闭虚拟内存检查-->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
mapred-site.xml-该文件不存在,需要手动创建
<!--MapRedcue框架资源管理器的实现-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
启动yarn计算框架
[root@CentOS ~]# start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /usr/hadoop-2.6.0/logs/yarn-root-resourcemanager-CentOS.out
CentOS: starting nodemanager, logging to /usr/hadoop-2.6.0/logs/yarn-root-nodemanager-CentOS.out
查看进程
[root@CentOS ~]# jps
5091 ResourceManager
5172 NodeManager
1332 NameNode
1413 DataNode
1525 SecondaryNameNode
5477 Jps
ResourceManager内嵌一个web服务吗,用于查看整个集群的资源调度信息http://ip:8088
入门案例
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-jobclient</artifactId>
<version>2.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.6.0</version>
</dependency>
日志文件格式如下(1TB):
日志级别 URL 用户ID 日期
INFO /product 001 2019-03-26 10:00:00
INFO /cart 003 2019-03-26 10:00:00
INFO /product 001 2019-03-26 10:00:00
INFO /cart 002 2019-03-26 10:00:00
INFO /order 004 2019-03-26 10:00:00
1.按照URL统计每个板块访问的次数,并且使用柱状图显示?
商品板块 2
购物车 2
订单 1
create table t_click(
level varchar(32),
url varchar(128),
uid varchar(32),
click_time timestamp
)
select url,sum(1) from t_click group by url
reduce(key,values) map(key,value)
reduce(url,[1,1,1,...]) map(url,1)
Map
public class ClickMappper extends Mapper<LongWritable, Text,Text, IntWritable> {
//INFO /product 001 2019-03-26 10:00:00
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] tokens = value.toString().split(" ");
context.write(new Text(tokens[1]),new IntWritable(1));
}
}
Reduce
public class ClickReducer extends Reducer<Text, IntWritable,Text,IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int total=0;
for (IntWritable value : values) {
total=value.get();
}
context.write(key,new IntWritable(total));
}
}
Job任务
public class CustomJobSubmitter extends Configured implements Tool {
public int run(String[] strings) throws Exception {
//1.封装Job对象
Job job=Job.getInstance(getConf());
//2.设置任务的读取、写出数据格式
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
//3.设置数据读入和写出路径
Path src = new Path("/demo/click");
TextInputFormat.addInputPath(job,src);
Path dst = new Path("/demo/result");//必须不存在,否则任务提交失败
TextOutputFormat.setOutputPath(job,dst);
//4.设置数据处理逻辑代码片段
job.setMapperClass(ClickMappper.class);
job.setReducerClass(ClickReducer.class);
//5.设置Mapper和Reducer输出key-value类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//6.任务提交
//job.submit();
job.waitForCompletion(true);
return 0;
}
public static void main(String[] args) throws Exception {
ToolRunner.run(new CustomJobSubmitter(),args );
}
}
发布任务
- 远程jar发布
job.setJarByClass(CustomJobSubmitter.class);
hadoop jar xxxxx.jar com.baizhi.CustomJobSubmitter
- 本地测试(本地模拟Map Reduce逻辑-
测试)

解决方案
覆盖NativeIO类,修改access实现,将该方法的实现短路。
public static boolean access(String path, NativeIO.Windows.AccessRight desiredAccess) throws IOException {
return true;
//return access0(path, desiredAccess.accessRight());
}
- 跨平台提交
项目添加配置文件

提交代码需要添加如下
//设置配置信息
conf.addResource("core-site.xml");
conf.addResource("hdfs-site.xml");
conf.addResource("yarn-site.xml");
conf.addResource("mapred-site.xml");
conf.set("mapreduce.job.jar","file:///jar包路径");
In/OutputFormat
Split&Record Reader
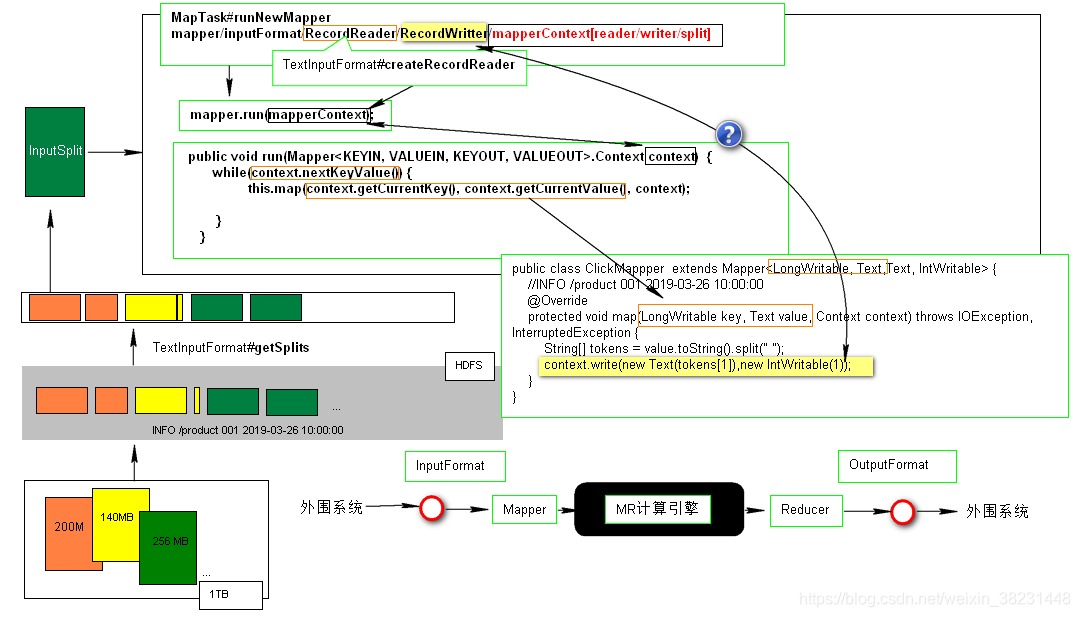
In/OutputFormat实战
对接文件系统-(读取):
TextInputFormat: (必须掌握)
切片计算 :以文件为单位,对一个文件按照SplitSize计算切片大小(0~140.8 MB)
Key-Value : 行字节偏移量LongWritable | 当前文本行 ,确定Mapper<LongWritable,Text,X,X>
NLineInputFormat
切片计算 :以文件为单位,对一个文件按照行切割,默认是1行一个切片
Key-Value : 行字节偏移量LongWritable | 当前文本行 ,确定Mapper<LongWritable,Text,X,X>
mapreduce.input.lineinputformat.linespermap = 10000
KeyValueTextInputFormat
切片计算 :以文件为单位,对一个文件按照SplitSize计算切片大小(0~140.8 MB)
Key-Value : Text
\tText ,确定Mapper<Text,Text,X,X>
mapreduce.input.keyvaluelinerecordreader.key.value.separator=|
CombineTextInputFormat(小文件计算优化)
切片计算 :对N个文件按照SplitSize计算切片大小(0~140.8 MB),多个文件对应一个切片
Key-Value :行字节偏移量LongWritable | 当前文本行 ,确定Mapper<LongWritable,Text,X,X>
MultipleInputs 实现 Join
1、在Map端分别对不同格式的数据定制Mapper和InputFormat
2、所有的Mapper输出KEY-VALUE必须保证一致
3、所有Map输出的KEY必须是 join 字段
4、针对不同的Mapper输出,通过对值做标记,这样才可以在Reduce端区分数据
DBOutputFormat(重点)
//1.配置数据链接参数
DBConfiguration.configureDB(conf,
"driver",
"url",
"username",
"password"
);
//2.设置任务的写出数据格式
job.setOutputFormatClass(DBOutputFormat.class);
//3.设置数据写出路径
DBOutputFormat.setOutput(job,"t_user_order","id","name","age","items","price");
//4.Reduce端输出的Key类型必须实现DBWritable接口
job.setOutputKeyClass(Class<? extends DBWritable>);
Writable和DBWritable用法
Writable:当自定义Map端输出Value类型,必须实现Writable接口,因为框架将会对Map的输出做本地磁盘的序列化。如果用户需要自定义Map端输出key类型,和值类型相比较多个排序的需求因此如果用户需要自定map端的输出key类型,必须实现WritableComparable接口。
DBWriteable:当用户使用DBOutputFormat时候,强制要求Reducer端的输出key类型必须实现DBWriteable接口,此时需要用户实现write方法给?赋值。通过使用DBOutputFormat可以获知,Reducer端输出的Key-Value类型所限与用户使用的OutputFormat。因此Reduce端的输出key-value类型和Writable接口没有任何关系。
Jar包依赖问题
- 运行时依赖(Yarn Child依赖)
方案1
要求用户将依赖的jar包拷贝给所有的计算节点(NodeManager运行所在主机)
[root@CentOS ~]# hadoop jar xxx.jar 入口类 -libjars 依赖jar包1,依赖jar包2,....
方案2
[root@CentOS ~]# hdfs dfs -mkdir /libs
[root@CentOS ~]# hdfs dfs -put mysql-connector-java-5.1.46.jar /libs
conf.setStrings("tmpjars","/libs/xxx1.jar,/libs/xxx2.jar,...");
- 提交时依赖(client node)
需要用户配置HADOOP_CLASSPATH环境变量(/root/.bashrc),通常这种依赖发生在切片计算阶段。
HADOOP_CLASSPATH=/root/mysql-connector-java-5.1.46.jar
export HADOOP_CLASSPATH
[root@CentOS ~]# source .bashrc
[root@CentOS ~]# hadoop classpath #查看hadoop的类路径
/usr/hadoop-2.6.0/etc/hadoop:/usr/hadoop-2.6.0/share/hadoop/common/lib/*:/usr/hadoop-2.6.0/share/hadoop/common/*:/usr/hadoop-2.6.0/share/hadoop/hdfs:/usr/hadoop-2.6.0/share/hadoop/hdfs/lib/*:/usr/hadoop-2.6.0/share/hadoop/hdfs/*:/usr/hadoop-2.6.0/share/hadoop/yarn/lib/*:/usr/hadoop-2.6.0/share/hadoop/yarn/*:/usr/hadoop-2.6.0/share/hadoop/mapreduce/lib/*:/usr/hadoop-2.6.0/share/hadoop/mapreduce/*:`/root/mysql-connector-java-5.1.46.jar`:/usr/hadoop-2.6.0/contrib/capacity-scheduler/*.jar
案例参考 DBInputFormat案例。
任务提交源码追踪
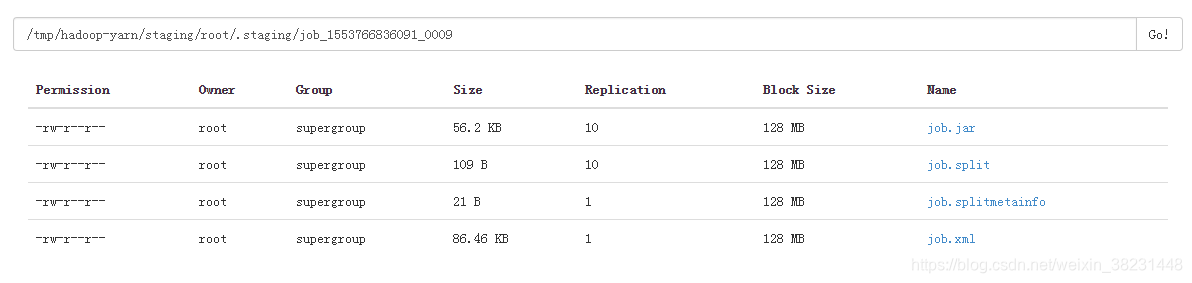
job.waitForCompletion(true);
submit
final JobSubmitter submitter = getJobSubmitter(fs, yarn);
submitter.submitJobInternal(Job.this, cluster);
checkSpecs(job);//检查输出目录是否为null
JobID jobId = submitClient.getNewJobID();//获取jobid
copyAndConfigureFiles(job, submitJobDir);//拷贝代码片段以及依赖jars
int maps = writeSplits(job, submitJobDir);//计算切片
writeConf(conf, submitJobFile);//生成job.xml
submitClient.submitJob(jobId, submitJobDir,...);
ApplicationSubmissionContext appContext =
createApplicationSubmissionContext(conf, jobSubmitDir, ts);//构建MR AP所需信息
resMgrDelegate.submitApplication(appContext);//任务提交
OutputFormat(Redis)
RedisOutpoutFormat
public class RedisOutpoutFormat extends OutputFormat<String,String> {
public RecordWriter<String, String> getRecordWriter(TaskAttemptContext context) throws IOException, InterruptedException {
Configuration conf = context.getConfiguration();
RedisConfiguration redisConf = new RedisConfiguration(conf);
return new RedisHashRecordWriter(redisConf.getHost(),redisConf.getPort(),redisConf.getDescriptKey());
}
public void checkOutputSpecs(JobContext context) throws IOException, InterruptedException { }
public OutputCommitter getOutputCommitter(TaskAttemptContext context) throws IOException, InterruptedException {
return new FileOutputCommitter(FileOutputFormat.getOutputPath(context),
context);
}
}
RedisHashRecordWriter
public class RedisHashRecordWriter extends RecordWriter<String,String> {
private Jedis jedis;
private String descriptKey;
private Pipeline pipeline;
public RedisHashRecordWriter(String host,int port,String descriptKey) {
this.jedis = new Jedis(host,port);
pipeline=jedis.pipelined();
this.descriptKey=descriptKey;
}
public void write(String key, String value) throws IOException, InterruptedException {
//启用Redis的批处理
pipeline.hset(descriptKey,key,value);
}
public void close(TaskAttemptContext context) throws IOException, InterruptedException {
pipeline.sync();//批量提交
jedis.close();//关闭链接
}
}
RedisConfiguration
public class RedisConfiguration {
private Configuration conf;
public RedisConfiguration(Configuration conf) {
this.conf = conf;
}
public static final String REDIS_HOST="redis.host";
public static final String REDIS_PORT="redis.port";
public static final String REDIS_DESCRIPT_KEY="redis.descriptKey";
public static void configRedis(Configuration conf,String host,int port,String descriptKey){
conf.set(REDIS_HOST,host);
conf.setInt(REDIS_PORT,port);
conf.set(REDIS_DESCRIPT_KEY,descriptKey);
}
public String getHost(){
return conf.get(REDIS_HOST);
}
public int getPort(){
return conf.getInt(REDIS_PORT,6379);
}
public String getDescriptKey(){
return conf.get(REDIS_DESCRIPT_KEY);
}
}
代码中使用如下
public class CustomJobSubmitter extends Configured implements Tool {
public int run(String[] strings) throws Exception {
//1.封装Job对象\
Configuration conf = getConf();
RedisConfiguration.configRedis(conf,
"CentOS",
6379,
"url_click");
Job job=Job.getInstance(conf);
//2.设置任务的读取、写出数据格式
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(RedisOutpoutFormat.class);
//3.设置数据读入和写出路径
Path src = new Path("file:///D:/demo/click");
TextInputFormat.addInputPath(job,src);
//4.设置数据处理逻辑代码片段
job.setMapperClass(ClickMappper.class);
job.setReducerClass(ClickReducer.class);
//5.设置Mapper和Reducer输出key-value类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(String.class);
job.setOutputValueClass(String.class);
//6.任务提交
//job.submit();
job.waitForCompletion(true);
return 0;
}
public static void main(String[] args) throws Exception {
ToolRunner.run(new CustomJobSubmitter(),args );
}
}
Shuffle&任务调优
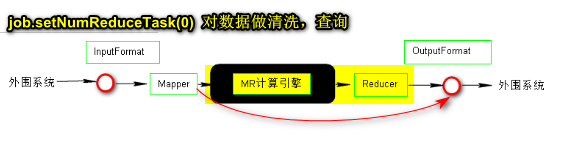
NumReduceTask = 0
public class CustomJobSubmitter extends Configured implements Tool {
public int run(String[] strings) throws Exception {
//1.封装Job对象
Job job=Job.getInstance(getConf());
//2.设置任务的读取、写出数据格式
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
//3.设置数据读入和写出路径
Path src = new Path("file:///D:/demo/click");
TextInputFormat.addInputPath(job,src);
Path dst = new Path("file:///D:/demo/result");//必须不存在,否则任务提交失败
TextOutputFormat.setOutputPath(job,dst);
//4.设置数据处理逻辑代码片段
job.setMapperClass(ClickMappper.class);
//5.设置Mapper和Reducer输出key-value类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setNumReduceTasks(0);//设置NumReducecTask 0
//6.任务提交
//job.submit();
job.waitForCompletion(true);
return 0;
}
public static void main(String[] args) throws Exception {
ToolRunner.run(new CustomJobSubmitter(),args );
}
}
NumReduceTask = 3
- 如何干预MapReduce分区策略?
job.setPartitionerClass(...)
- MapReduce输出特点是什么?
分区内部有序,默认按照Map端输出key的升序
- 什么是Mapreduce数据倾斜?
是因为选取的Key不合理,到时分区数据分布不均匀。在任务计算第二阶段Reduce计算带来压力。
- Reduce并行度是靠什么决定的?和Map端计算区别是什么?
Map端并行度是通过计算任务切片决定的,Reduce端是通过job.setNumReduceTask(n)
MapReduce调优策略
- 避免小文件计算,适当线下合并
- 调整环装缓冲区的参数,减少Map任务的IO操作
- 开启Map段压缩
conf.setBoolean("mapreduce.map.output.compress",true);
conf.setClass("mapreduce.map.output.compress.codec", GzipCodec.class, CompressionCodec.class);
- 如果条件允许,可以考虑在Map端预执行Reduce逻辑-Map端的Combiner
是一种针对Mapshuffle的优化,主要是通过在Map端本地支持局部Reduce操作,该操作可以极大减轻网络IO占用,减少key的排序量,但是并不是所有的操作都支持Combiner:
- Combiner默认不会开启,需要程序员编码设置
- 要求Combiner不可以改变Map端最终的输出key-value类型(Combiner输入和输出类型一致)
- 必须满足计算支持迭代,例如:求和、最大值、最小值 ,但是 平均值就不适用
job.setCombinerClass(ClickCombiner.class);
----
public class ClickCombiner extends Reducer<Text, IntWritable,Text,IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
System.out.println("--ClickCombiner---");
int total=0;
for (IntWritable value : values) {
total += value.get() ;
}
context.write(key,new IntWritable(total));
}
}
- 适当调整NodeManager管理Container的个数和内存大小
yarn.nodemanager.resource.cpu-vcores = 8
yarn.nodemanager.resource.memory-mb = 8192
Map Reduce 使用场景
- 网络日志清洗数据 ETL (Extract Transfer Load),一般这种操作不需要Reduce即可完成
- 基于大数据数据统计和报表 求最大、求最小、求平均 使用柱状图、饼状图展示。
- 画像生成-为后续AI学习提供计算所需数据模型 特征向量 线性回归|逻辑回归
杯子-画像
| 容量 | 材质 | 颜色 | 是否保温 | 口径 | 品牌 |
|---|---|---|---|---|---|
| 中 | 陶瓷 | 黑 | 是 | 10CM | xx |
人
| 身高 | 体重 | 颜值 | 年龄 | 性别 | 收入 | 消费 |
|---|---|---|---|---|---|---|
| 178 | 130 | 10 | 25 | true | 100W | 50W |
-
个性化推荐 通过MapReduce 生成算法所需数据样本
- 基于用户的协同推荐算法
- 基于物品协同过滤算法(比较多)
数据格式(MapReduce ETL或者统计得来)
userid/itemid/score
1,101,5.0
1,102,3.0
1,103,2.5
2,101,2.0
2,102,2.5
2,103,5.0
2,104,2.0
3,101,2.5
3,104,4.0
3,105,4.5
3,107,5.0
4,101,5.0
4,103,3.0
4,104,4.5
4,106,4.0
5,101,4.0
5,102,3.0
5,103,2.0
5,104,4.0
5,105,3.5
5,106,4.0
- 安装Mahout(下载Mahout算法库)
[root@CentOS ~]# tar -zxf apache-mahout-distribution-0.13.0.tar.gz -C /usr/
- 将准备好的数据存储到/recomand
- 调用Mahout的推荐算法(MapReduce任务实现的算法,该算法分为4个阶段,共计9个MapReduce任务)
[root@CentOS ~]# hadoop jar /usr/apache-mahout-distribution-0.13.0/mahout-mr-0.13.0-job.jar org.apache.mahout.cf.taste.hadoop.item.RecommenderJob --input /recomand --output /recomand-out -s SIMILARITY_LOGLIKELIHOOD
1 [104:2.8088317,106:2.5915816,105:2.5748677]
2 [105:3.5743618,106:3.3991857]
3 [103:4.336442,106:4.0915813,102:4.0915813]
4 [102:3.6903737,105:3.6903737]
5 [107:3.663558]
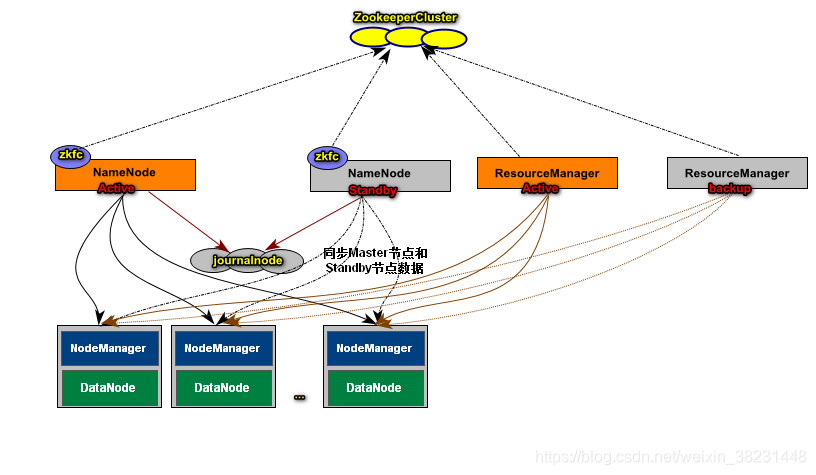
Hadoop HA构建
概述
-
NameNode HA构建 存储
-
ResourceManager HA构建 计算
准备工作
- 安装三台CentOS-6.5 64 bit操作系统(完成JDK、SSH免密码认证、IP主机名映射、关闭防火墙等工作)
主机和服务启动映射表
| 主机 | 服务 |
|---|---|
| CentOSA | NameNode、zkfc、DataNode、JournalNode、Zookeeper、NodeManager |
| CentOSB | NameNode、zkfc、DataNode、JournalNode、Zookeeper、NodeManager、ResourceManager |
| CentOSC | DataNode、JournalNode、Zookeeper、NodeManager、ResourceManager |
主机信息
| 主机名 | IP信息 |
|---|---|
| CentOSA | 192.168.40.129 |
| CentOSB | 192.168.40.130 |
| CentOSC | 192.168.40.131 |
JDK安装和配置
[root@CentOSX ~]# rpm -ivh jdk-8u171-linux-x64.rpm
[root@CentOSX ~]# vi .bashrc
JAVA_HOME=/usr/java/latest
PATH=$PATH:$JAVA_HOME/bin
CLASSPATH=.
export JAVA_HOME
export CLASSPATH
export PATH
[root@CentOSX ~]# source .bashrc
IP主机名映射
[root@CentOSX ~]# vi /etc/hosts
192.168.40.129 CentOSA
192.168.40.130 CentOSB
192.168.40.131 CentOSC
关闭防火墙
[root@CentOSX ~]# service iptables stop
iptables: Setting chains to policy ACCEPT: filter [ OK ]
iptables: Flushing firewall rules: [ OK ]
iptables: Unloading modules: [ OK ]
[root@CentOSX ~]# chkconfig iptables off
SSH免密码认证
[root@CentOSX ~]# ssh-keygen -t rsa
[root@CentOSX ~]# ssh-copy-id CentOSA
[root@CentOSX ~]# ssh-copy-id CentOSB
[root@CentOSX ~]# ssh-copy-id CentOSC
Zookeeper
[root@CentOSX ~]# tar -zxf zookeeper-3.4.6.tar.gz -C /usr/
[root@CentOSX ~]# mkdir /root/zkdata
[root@CentOSA ~]# echo 1 >> /root/zkdata/myid
[root@CentOSB ~]# echo 2 >> /root/zkdata/myid
[root@CentOSC ~]# echo 3 >> /root/zkdata/myid
[root@CentOSX ~]# touch /usr/zookeeper-3.4.6/conf/zoo.cfg
[root@CentOSX ~]# vi /usr/zookeeper-3.4.6/conf/zoo.cfg
tickTime=2000
dataDir=/root/zkdata
clientPort=2181
initLimit=5
syncLimit=2
server.1=CentOSA:2887:3887
server.2=CentOSB:2887:3887
server.3=CentOSC:2887:3887
[root@CentOSX ~]# /usr/zookeeper-3.4.6/bin/zkServer.sh start zoo.cfg
[root@CentOSX ~]# /usr/zookeeper-3.4.6/bin/zkServer.sh status zoo.cfg
JMX enabled by default
Using config: /usr/zookeeper-3.4.6/bin/../conf/zoo.cfg
Mode: `follower|leader`
[root@CentOSX ~]# jps
5879 `QuorumPeerMain`
7423 Jps
搭建Hadoop 集群(HDFS)
解压并配置HADOOP_HOME
[root@CentOSX ~]# tar -zxf hadoop-2.6.0_x64.tar.gz -C /usr/
[root@CentOSX ~]# vi .bashrc
HADOOP_HOME=/usr/hadoop-2.6.0
JAVA_HOME=/usr/java/latest
PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
CLASSPATH=.
export JAVA_HOME
export CLASSPATH
export PATH
export HADOOP_HOME
[root@CentOSX ~]# source .bashrc
配置core-site.xml
<!--配置Namenode服务ID-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/hadoop-2.6.0/hadoop-${user.name}</value>
</property>
<property>
<name>fs.trash.interval</name>
<value>30</value>
</property>
<!--配置机架脚本-->
<property>
<name>net.topology.script.file.name</name>
<value>/usr/hadoop-2.6.0/etc/hadoop/rack.sh</value>
</property>
<!--配置ZK服务信息-->
<property>
<name>ha.zookeeper.quorum</name>
<value>CentOSA:2181,CentOSB:2181,CentOSC:2181</value>
</property>
<!--配置SSH秘钥位置-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
配置机架脚本
[root@CentOSX ~]# touch /usr/hadoop-2.6.0/etc/hadoop/rack.sh
[root@CentOSX ~]# chmod u+x /usr/hadoop-2.6.0/etc/hadoop/rack.sh
[root@CentOSX ~]# vi /usr/hadoop-2.6.0/etc/hadoop/rack.sh
while [ $# -gt 0 ] ; do
nodeArg=$1
exec</usr/hadoop-2.6.0/etc/hadoop/topology.data
result=""
while read line ; do
ar=( $line )
if [ "${ar[0]}" = "$nodeArg" ] ; then
result="${ar[1]}"
fi
done
shift
if [ -z "$result" ] ; then
echo -n "/default-rack"
else
echo -n "$result "
fi
done
[root@CentOSX ~]# touch /usr/hadoop-2.6.0/etc/hadoop/topology.data
[root@CentOSX ~]# vi /usr/hadoop-2.6.0/etc/hadoop/topology.data
192.168.40.129 /rack01
192.168.40.130 /rack01
192.168.40.131 /rack03
配置hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--开启自动故障转移-->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!--解释core-site.xml内容-->
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>CentOSA:9000</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>CentOSB:9000</value>
</property>
<!--配置日志服务器的信息-->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://CentOSA:8485;CentOSB:8485;CentOSC:8485/mycluster</value>
</property>
<!--实现故障转切换的实现类-->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
配置slaves
CentOSA
CentOSB
CentOSC
启动HDFS(集群初始化启动)
[root@CentOSX ~]# hadoop-daemon.sh start journalnode (等待10s钟)
[root@CentOSA ~]# hdfs namenode -format
[root@CentOSA ~]# hadoop-daemon.sh start namenode
[root@CentOSB ~]# hdfs namenode -bootstrapStandby
[root@CentOSB ~]# hadoop-daemon.sh start namenode
#注册Namenode信息到zookeeper中,只需要在CentOSA或者B上任意一台执行一下指令
[root@CentOSA|B ~]# hdfs zkfc -formatZK
[root@CentOSA ~]# hadoop-daemon.sh start zkfc
[root@CentOSB ~]# hadoop-daemon.sh start zkfc
[root@CentOSX ~]# hadoop-daemon.sh start datanode
查看机架信息
[root@CentOSB ~]# hdfs dfsadmin -printTopology
Rack: /rack01
192.168.40.129:50010 (CentOSA)
192.168.40.130:50010 (CentOSB)
Rack: /rack03
192.168.40.131:50010 (CentOSC)
Resource Manager搭建
yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>cluster</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>CentOSB</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>CentOSC</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>CentOSA:2181,CentOSB:2181,CentOSC:2181</value>
</property>
mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
启动|关闭Yarn服务
[root@CentOSB ~]# yarn-daemon.sh start|stop resourcemanager
[root@CentOSC ~]# yarn-daemon.sh start|stop resourcemanager
[root@CentOSX ~]# yarn-daemon.sh start|stop nodemanger
更多精彩内容关注















 2995
2995











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









