







spark主要的机器学习API是基于DataFrame的一组模型,它们包含在spark.ml包中。
包的概述
在顶层,该软件包公开了3个主要的抽象类:转换器、评估器、管道。
转换器
通常通过一个新列附加到DataFrame来转换数据。
常用转换器:
Banarizer:根据指定的阈值将连续变量转换对应的二进制值
Bucketizer:与Banarizer类似,该方法根据阈值列表,将连续变量转换为多项值
HashingTF:一个哈希转换器,输入为标记文本的列表,返回一个带有计数器有预定长度的向量
IDF:该方法计算文档列表的逆向文件频率
MaxAbsScaler:将数据调整到[-1.0,1.0]的范围内
MinMaxScaler:将数据调整到[0,1.0]的范围内
NGram:此方法的输入为标记文本的列表,返回结果为一系列的n-gram:以两个词,三个词或者更多N个词为一个N-gram,输入[‘open’,‘your’,‘eyes’],输出[‘open your’,‘your eyes’]
Normalizer:该方法使用P范数将数据缩放为单位范数中(默认L2)
OneHotEncoder:该方法将分类列编码为二进制向量列
PCA:主成分分析法降维
SQLTransormer:使用SQL语法传递sql语句
StandardScaler:标准化列,使其拥有零均值和等于1的标准差
Tokenizer(分词器):默认分词器将字符串转成小写,所以以空格为分割符分词
VectorAssember:将多个数字(向量)列合并为一列向量。
df = spark.createDataFrame([[1,2,3],[4,5,6]],['a','b','c'])
import pyspark.ml.feature as ft
#spark.createDataFrame([1,2,3],['a','b','c'])TypeError: Can not infer schema for type: <class 'int'>
ft.VectorAssembler(inputCols=['a','b','c'],outputCol='features').\
transform(df).select('features').collect()
结果:

VectorIndexer:该方法为类别列生成索引向量
…
评估器
可以视为需要评估的统计模型,对观测对象预测或分类
分类:
LogisticRegression
DecisionTreeClassifier
RandomForestClassifier
NaiveBayes
MultilayerPerceptronClassifier
OneVsRest:将多分类转换为二分类问题
回归:
LinearRegression:最简单的线性回归模型,假设了特征与连续标签以及误差项的常态之间的线性关系
DecisionTreeRegressor:标签是连续的
GBTRegressor:与DecisionTreeRegressor一样,区别在于标签的数据类型
GeneralizedLinearRegression:允许标签具有不同的误差项分布(高斯分布、gamma,poisson泊松分布、binomial二项分布)
RandomForestRegressor:适合连续的标签,而不是离散标签
IsotonicRegression:你和一个形式自由,非递减的行到数据中
AFTSurvivalRegression:适合加速失效的时间回归模型
聚类:
KMeans
LDA
BisectingKMeans(二分K均值分类算法)
GaussianMixture(高斯混合模型)
管道
用来表示从转换到评估 端到端的过程,这个过程可以对输入的一些原始数据执行必要的数据加工,最后评估统计模型

实践
数据下载地址:http://www.tomdrabas.com/data/LearningPySpark/births_transformed.csv.gz
1.加载数据
import pyspark.sql.types as typ
labels = [
('INFANT_ALIVE_AT_REPORT',typ.IntegerType()),
('BIRTH_PLACE',typ.IntegerType()), #('BIRTH_PLACE',typ.StringType()),
('MOTHER_AGE_YEARS',typ.IntegerType()),
('FATHER_COMBINED_AGE',typ.IntegerType()),
('CIG_BEFORE',typ.IntegerType()),
('CIG_1_TRI',typ.IntegerType()),
('CIG_2_TRI',typ.IntegerType()),
('CIG_3_TRI',typ.IntegerType()),
('MOTHER_HEIGHT_IN',typ.IntegerType()),
('MOTHER_PRE_WEIGHT',typ.IntegerType()),
('MOTHER_DELIVERY_WEIGHT',typ.IntegerType()),
('MOTHER_WEIGHT_GAIN',typ.IntegerType()),
('DIABETES_PRE',typ.IntegerType()),
('DIABETES_GEST',typ.IntegerType()),
('HYP_TENS_PRE',typ.IntegerType()),
('HYP_TENS_GEST',typ.IntegerType()),
('PREV_BIRTH_PRETERM',typ.IntegerType())
]
schema = type.StructType([typ.StructField(e[0],e[1],False) for e in labels])
births = spark.read.csv('./data/births_transformed.csv',header=True,schema=schema)

2.创建转换器
由于统计模型只能做数值转换,所以如果有不是数值的列,要做转换,然后创建一个转换器
import pyspark.ml.feature as ft
births = births.withColumn('**_INT',births['**'].cast(typ.IntegerType()))
encoder = ft.OneHotEncoder(inputCol='**_INT',outputCol='**_VEC')
本次数据不需要
使用VectorAssembler方法将所有特征整合在一起
featuresCreator = ft.VectorAssembler(inputCols=[col[0] for col in labels[1:]]\
#+ [encoder.getOutputCol()],
,outputCol = 'features'
)
3.创建一个评估器
import pyspark.ml.classification as cl
logistic = cl.LogisticRegression(maxIter=10,regParam=0.01,\
labelCol='INFANT_ALIVE_AT_REPORT')
4.创建一个管道
from pyspark.ml import Pipeline
pipeline = Pipeline(stages=[featuresCreator,logistic])
5.拟合模型
先把数据集训练集和测试集,用randomSplit()
births_train,births_test,val = births.randomSplit([0.7,0.2,0.1],seed=666)
运行管道并评估模型
transform方法获得预测
model = pipeline.fit(births_train)
test_model = model.transform(births_test)
获取预测的一个结果:
 rawPrediction:特征和B系数线性组合的值
rawPrediction:特征和B系数线性组合的值
probability:是预测每个列别计算出的概率
prediction:预测类别
6.评估模型性能
import pyspark.ml.evaluation as ev
evaluator = ev.BinaryClassificationEvaluator(rawPredictionCol='probability',
labelCol = 'INFANT_ALIVE_AT_REPORT')
print(evaluator.evaluate(test_model,{evaluator.metricName:'areaUnderROC'}))
print(evaluator.evaluate(test_model,{evaluator.metricName:'areaUnderPR'}))
rawPredictionCol可以是rawPrediction,也可以是probability列

7.保存模型
可以保存管道定义,不仅可以保存管道结构,还可以保存所有转换器和评估器的定义
pipelinePath = './infant_OneHotEncoder_Logistic_Pipeline'
pipeline.write().overwrite().save(pipelinePath)
加载,预测结果一样
loadPipeline = Pipeline.load(pipelinePath)

超参调优
概念:找到模型的最佳参数:例如正确估计逻辑回归模型所需要的做大迭代次数或者决策树的最大深度
网格搜索法
根据给定的评估指标,循环便利定义的参数值列表,估计各个单独的模型,从而选择一个最佳的模型
注意:定义的要优化的参数或者参数值太多,可能需要大量实践才能选出最佳模型
首先指定要优化参数的模型,然后确定要优化的参数以及优化的参数的值,然后使用使用ParamGridBuilder()对象,使用.addGrid()方法将参数添加到网格中,使用build方法构建网格。
第一个参数是要优化的模型的参数对象,第二个参数是要循环的值的列表。
接下来,比较模型,使用CrossValidator,该模型循环遍历值的网格,评估各个模型
import pyspark.ml.tuning as tune
logistic = cl.LogisticRegression(
labelCol = 'INFANT_ALIVE_AT_REPORT'
)
grid = tune.ParamGridBuilder()\
.addGrid(logistic.maxIter,[2,10,50])\
.addGrid(logistic.regParam,[0.01,0.05,0.3])\
.build()
cv = tune.CrossValidator(
estimator = logistic,
estimatorParamMaps=grid,
evaluator = evaluator
)
cvModel将返回最佳估计的参数模型
#创建一个用于循环的管道
pipeline = Pipeline(stages=[featuresCreator])
data_transformer = pipeline.fit(births_train)
#寻找模型最佳参数组合
cvModel = cv.fit(data_transformer.transform(births_train))
验证模型效果
data_train = data_transformer.transform(births_test)
results = cvModel.transform(data_train)
print(evaluator.evaluate(results,{evaluator.metricName:'areaUnderROC'}))
print(evaluator.evaluate(results,{evaluator.metricName:'areaUnderPR'}))
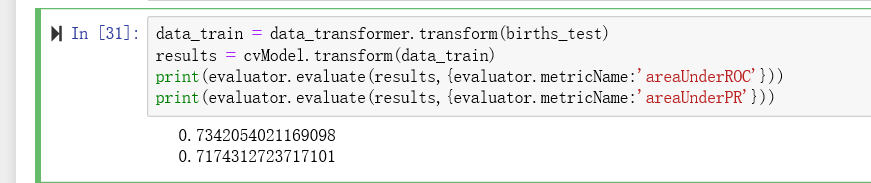
结果确实更好
训练集划分
为了选择最佳模型,TrainValidationSplit模型对输入的数据集,划分两个子集:较小的训练集和较大的验证集。
先使用ChiSqSelector选出前五个特征,限制模型的复杂度
过程与上面类似
selector = ft.ChiSqSelector(
numTopFeatures = 5,
featuresCol = featuresCreator.getOutputCol(),
outputCol = 'selectedFeatures',
labelCol = 'INFANT_ALIVE_AT_REPORT'
)
logistic = cl.LogisticRegression(
labelCol = 'INFANT_ALIVE_AT_REPORT',
featuresCol = 'selectedFeatures'
)
pipeline = Pipeline(stages=[featuresCreator,selector])
data_transformer = pipeline.fit(births_train)
tsv = tune.TrainValidationSplit(
estimator = logistic,
estimatorParamMaps=grid,
evaluator = evaluator
)
tvsModel = tsv.fit(data_transformer.transform(births_train))
data_train = data_transformer.transform(births_test)
results = cvModel.transform(data_train)
print(evaluator.evaluate(results,{evaluator.metricName:'areaUnderROC'}))
print(evaluator.evaluate(results,{evaluator.metricName:'areaUnderPR'}))
结果:特征少的模型表现差一些,但是效果也不是很明显

PySpark ML其他功能
特征提取
NLP相关特征提取
text_data = spark.createDataFrame([
['''Machine learning can be applied to a wide variety
of data types, such as vectors, text, images, and
structured data. This API adopts the DataFrame from
Spark SQL in order to support a variety of data types.'''],
['''DataFrame supports many basic and structured types;
see the Spark SQL datatype reference for a list of
supported types. In addition to the types listed in
the Spark SQL guide, DataFrame can use ML Vector types.'''],
['''A DataFrame can be created either implicitly or
explicitly from a regular RDD. See the code examples
below and the Spark SQL programming guide for examples.'''],
['''Columns in a DataFrame are named. The code examples
below use names such as "text," "features," and "label."''']
], ['input'])
#对文本进行标记,该模型会删除文本的空格间隔,逗号,句号,反斜杠和引号
tokenizer = ft.RegexTokenizer(
inputCol='input',
outputCol='input_arr',
pattern='\s+|[,.\"]'
)
tok = tokenizer \
.transform(text_data) \
.select('input_arr')
tok.take(1)
结果

#删除停用词
stopwords = ft.StopWordsRemover(
inputCol=tokenizer.getOutputCol(),
outputCol='input_stop')
stopwords.transform(tok).select('input_stop').take(1)

构建NGram模型和管道
ngram = ft.NGram(n=2,
inputCol=stopwords.getOutputCol(),
outputCol="nGrams")
pipeline = Pipeline(stages=[tokenizer, stopwords, ngram])
data_ngram = pipeline \
.fit(text_data) \
.transform(text_data)
data_ngram.select('nGrams').take(1)

得到NGram,可以进一步处理了
离散连续变量
将值划分成分级类别
造数据:
import numpy as np
x = np.arange(0, 100)
x = x / 100.0 * np.pi * 4
y = x * np.sin(x / 1.764) + 20.1234
schema = typ.StructType([
typ.StructField('continuous_var',
typ.DoubleType(),
False
)
])
data = spark.createDataFrame([[float(e), ] for e in y], schema=schema)

使用QuantileDiscretizer模型将连续变量分为5个分类级别
discretizer = ft.QuantileDiscretizer(
numBuckets=5,
inputCol='continuous_var',
outputCol='discretized')
data_discretized = discretizer.fit(data).transform(data)
data_discretized \
.groupby('discretized')\
.mean('continuous_var')\
.sort('discretized')\
.collect()

可以将此变量视为分类,使用One-HotEncoder进行编码
标准化连续变量
标准化连续变量有助于理解特征的关系,计算效率
首先,创建一个向量代表连续向量,然后构建normalizer和管道。通过将withMean,withStd设置为True,该方法将删除均值并让方差缩放为单位长度
vectorizer = ft.VectorAssembler(
inputCols=['continuous_var'],
outputCol= 'continuous_vec')
normalizer = ft.StandardScaler(
inputCol=vectorizer.getOutputCol(),
outputCol='normalized',
withMean=True,
withStd=True
)
pipeline = Pipeline(stages=[vectorizer, normalizer])
data_standardized = pipeline.fit(data).transform(data)

分类、聚类、回归相关实例也均可在https://github.com/drabastomek/learningPySpark/blob/master/Chapter06/LearningPySpark_Chapter06.ipynb找到
参考:
pyspark实战指南-第六章ML包介绍















 7368
7368











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









