









文章目录
一、Spark粗粒度架构
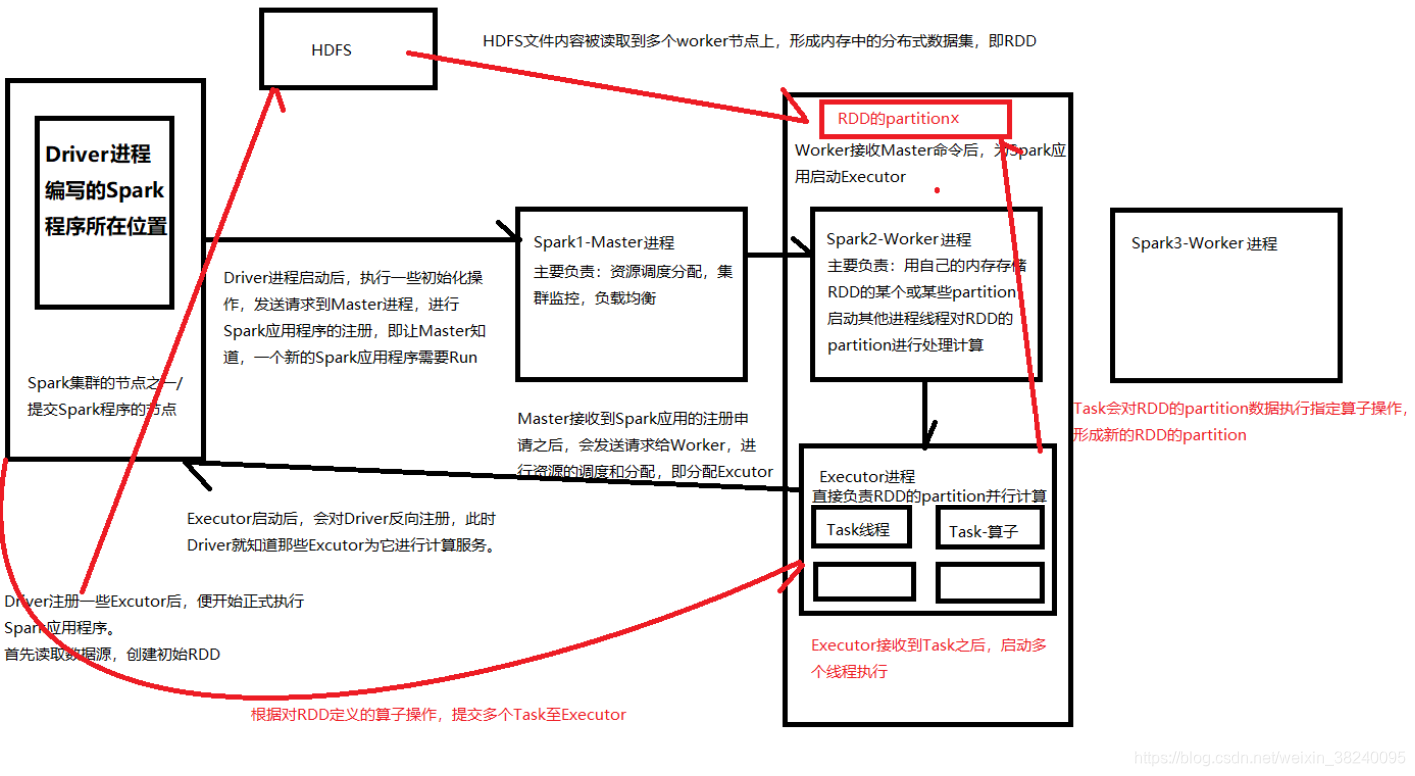
二、Spark基本工作原理
- 分布式
- 基于内存
- 迭代式计算
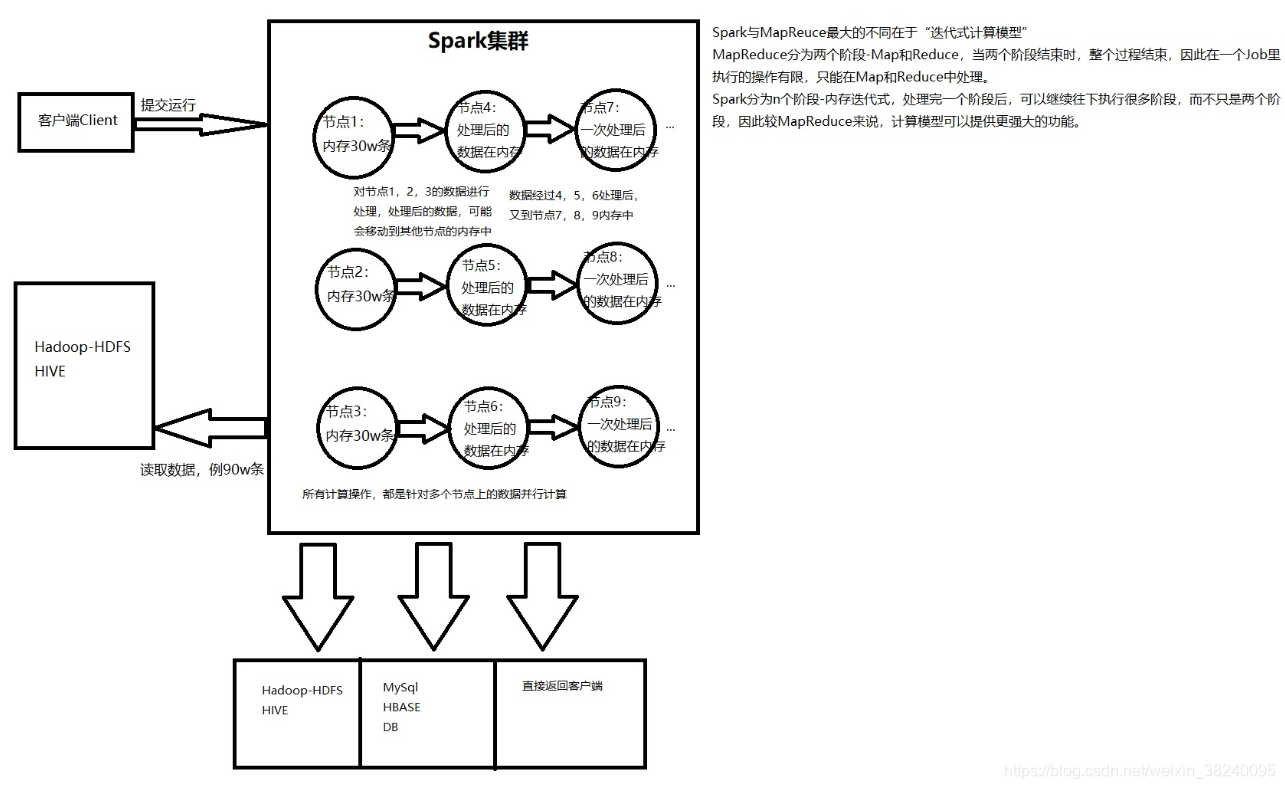
【防裂说明】Spark与MapReduce最大的不同在于“迭代式计算模型”
(1)MapReduce分为两个阶段-Map和Reduce,当两个阶段结束时,整个过程结束。因此在一个Job里执行的操作有限,只能在Map和Reduce中处理。
(2)Spark分为n个阶段-内存迭代式,处理完一个阶段后,可以继续往下执行很多阶段,而不只是两个阶段。因此较MapReduce来说,计算模型可以提供更强大的功能。
三、RDD(Resillient Distributed Dataset,弹性分布式数据集)
- RDD是Spark的核心抽象。实际上,一个RDD就是 每一批 节点上的 每一批 数据。
- RDD从逻辑抽象上来说是一种包含数据的元素集合,分为多个分区。每个分区分布在集群的不同节点上,从而RDD中的数据可以被并行操作。
- RDD一般通过Hadoop上的文件(即HDFS文件)或Hive表来进行创建,有时可以通过应用程序的集合来创建。
- RDD最重要的特性:容错性。 可以自动从节点失败状态中恢复,即如果某个节点上的RDD Partition由于节点故障导致数据丢失,那么RDD会通过自己的数据源重新计算该Partition。
- RDD的数据默认情况下存放于内存,但内存资源不足时,Spark将自动将RDD分区写入磁盘。
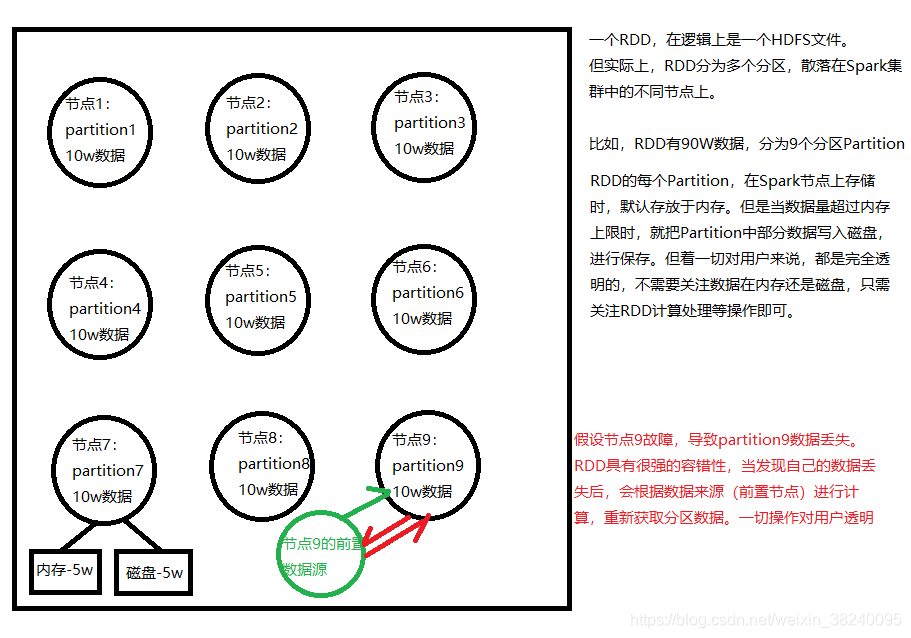
【防裂说明】
(1)一个RDD,在逻辑上是一个HDFS文件。但实际上,RDD划分为多个分区,散落在Spark集群中的不同节点上。如图,RDD有90w条数据,分为9个分区Partition。
(2)RDD的每个Partition,在Spark节点上存储时,默认存放于内存。但当数据量超过内存上限时,九八Partition中部分数据写入磁盘,进行保存。但这一切对用户来说,都是完全透明的,不需要关注数据在内存还是磁盘,只需关注RDD计算处理等操作即可。
(3)假设节点9故障,导致partition9数据丢失。RDD具有很强的容错性,当发现当前节点的分区数据丢失后,会根据数据来源(前置节点)进行计算,重新获取分区数据。一切操作对用户透明。
四、Spark开发
- 过程:首发RDD来源+算子[循环往复]->RDD+算子[循环往复]+…=数据
- 应用场景:离线批处理/延迟性交互式数据处理,SQL查询,实时计算
五、Demo:wordcount
1. Java版本
//1. 创建SparkConf对象,设置Spark应用的配置信息
/*
* 使用setMaster可以设置Spark应用程序将连接的Spark集群的主节点URL;若设为local,则代表在本地运行
*/
SparkConf conf = new SparkConf()
.setAppName( "WordCountLocal")
.setMaster( "local");
//2. 创建JavaSparkContext对象
/*
* 在Spark中,SparkContext是Spark所有功能的入口,无论Java/ Scala/Python 编写。
* 主要作用:初始化Spark应用程序所需的核心组件,包括:调度器(DAGSchedule/TaskSchedule),还会到Spark Master节点上注册等。
* SparkContext是Spark中最为重要的一个对象,但编写不同类型的Spark应用程序,使用的SparkContext是不同的
* 若使用 Scala,使用的是原生SparkContext对象
* 若使用Java,使用的是JavaSparkContext对象
* 若开发Spark SQL程序,使用的是SQLContext,HiveContext
* 若开发Spark Streaming程序,使用的是独有的SparkContext
* 以此类推
*/
JavaSparkContext sc= new JavaSparkContext(conf );
//3. 针对输入源,创建初始的RDD
/*
* 输入源中的数据打散,分配到RDD每个partition中,从而形成一个初始的分布数据集
* SparkContext中,根据文件的输入源创建RDD的方法->textFile()
* 在Java中,创建的普通RDD,都是JavaRDD
* 如果数据来自 hdfs/本地文件,创建的RDD中的每个元素相当于文件的一行
*/
JavaRDD<String> lines = sc.textFile("C:\\Users\\Z-Jay\\Desktop\\spark.txt" );
//4. 对初始RDD进行transformation操作,即计算
/*
*通常操作会创建 function,并配合map、flatMap等算子执行
*通常,若function比较简单,则创建匿名内部类;若比较复杂,则单独实现一个实现function接口
*/
/*FlatMapFunction<INTYPE,OUTTYPE>
* flatmap算子的作用:将RDD的一个元素,拆分成一个或多个元素。将每一行拆分为单个单词
*/
JavaRDD<String> words = lines .flatMap(new FlatMapFunction<String, String>() {
private static final long serialVersionUID = 1L;
@Override
public Iterator<String> call(String line ) throws Exception {
return Arrays.asList( line.split(" ")).iterator();
}
});
//5. 将每一个单词映射为(word,1)的形式,便于累加统计
/*
* 将每个元素映射为一个(v1,v2)的Tuple2类型的元素
* mapToPair算子要求PairFunction配合使用:
*第一个泛型参数代表了输入类型
*第二个和第三个泛型参数代表输出Tuple2的第一个值和第二个值类型
* JavaPairRDD的两个泛型参数,分别代表了Tuple第一个值和第二个值的类型
*/
JavaPairRDD<String, Integer> pairs = words .mapToPair(new PairFunction<String, String, Integer>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<String, Integer> call(String word) throws Exception {
return new Tuple2<String,Integer>(word,1);
}
});
//6. 紧接着需要以单词作key,统计单词出现的次数
/*
* 使用reduceByKey算子,对每个key对应的value,都进行reduce累加操作
*/
JavaPairRDD<String, Integer> wordCounts = pairs.reduceByKey(new Function2<Integer, Integer, Integer>() {
private static final long serialVersionUID = 1L;
@Override
public Integer call(Integer v1 , Integer v2) throws Exception {
return v1 +v2 ;
}
});
/*
* 之前使用的flatMap,mapToPar,reduceByKey等操作都叫做Transformation操作,
* 一个应用中只有Transformation无法执行,必须在最后使用action操作如 foreach触发
*/
wordCounts.foreach(new VoidFunction<Tuple2<String,Integer>>() {
private static final long serialVersionUID = 1L;
@Override
public void call(Tuple2<String, Integer> wordCount) throws Exception {
System. out.println(wordCount ._1 +" appeared "+wordCount. _2+ " times ");
}
});
sc.close();
2. Scala版本(关键代码在原理剖析中体现)
3. Spark-shell编写(了解)
4. 原理剖析
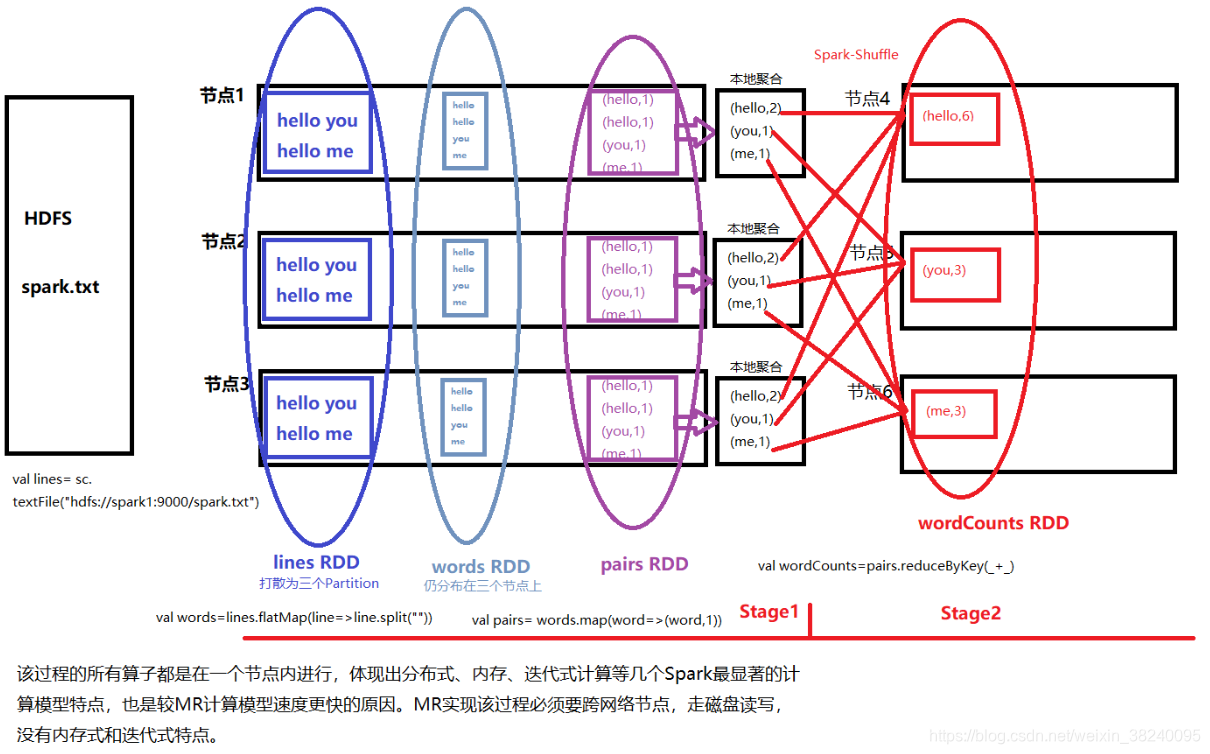 【防裂说明】该过程的所有算子都是在一个节点内进行,体现出分布式、内存式、迭代式计算等几个Spark最显著的计算模型特点,也是较MR计算模型速度更快的原因。MR实现该过程必须要要跨网络节点,走磁盘读写,没有内存式和迭代式特点。
【防裂说明】该过程的所有算子都是在一个节点内进行,体现出分布式、内存式、迭代式计算等几个Spark最显著的计算模型特点,也是较MR计算模型速度更快的原因。MR实现该过程必须要要跨网络节点,走磁盘读写,没有内存式和迭代式特点。
六、如何将Spark应用提交至集群?
如果需要提交至Spark上运行,只需要修改以下几个地方:
- 将SparkConf的setMaster去掉,默认自动连接。
- 不再震度地本地文件,修改位hadoop-hdfs上的真正大数据文件。
- 将打包后的Spark工程的jar包和对应Shell脚本上传至主节点。
- 修改Shell脚本中的路径并chmod执行spark-submit脚本,提交该应用至集群运行。















 1107
1107

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









