









参考李飞飞cs231n2017课程:
http://vision.stanford.edu/teaching/cs231n/2017/syllabus.html
该分类器的基本思想是通过将测试图像与训练集带标签的图像进行比较,来给测试图像打上分类标签。
1. Nearest Neighbor Classifier
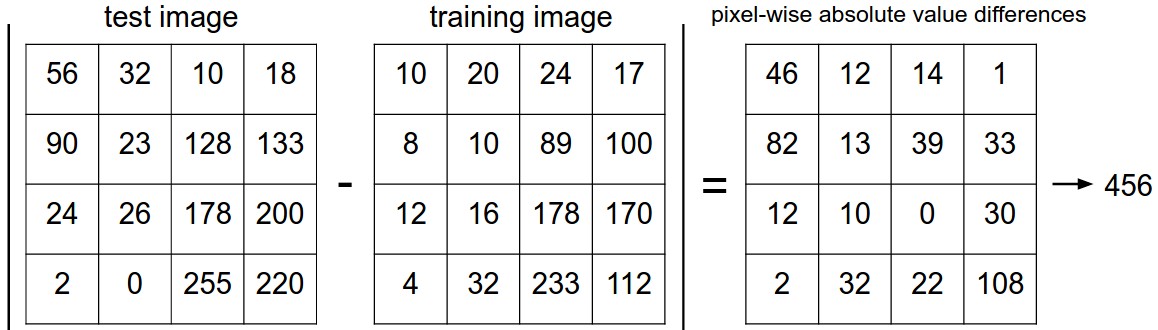
1.1 计算方法【L1 distance】:逐个比较图像中所有像素的值,计算误差和。
d
1
(
I
1
,
I
2
)
=
∑
p
∣
I
1
p
−
I
2
p
∣
d_1 (I_1, I_2) = \sum_{p} \left| I^p_1 - I^p_2 \right|
d1(I1,I2)=∑p∣I1p−I2p∣
1.2 计算方法【L2 distance】:逐个比较图像中所有像素的值,计算误差和, 与之前一样计算像素差异,每一次有求差后平方,相加最后取平方根。
d
2
(
I
1
,
I
2
)
=
∑
p
(
I
1
p
−
I
2
p
)
2
d_2 (I_1, I_2) = \sqrt{\sum_{p} \left( I^p_1 - I^p_2 \right)^2}
d2(I1,I2)=∑p(I1p−I2p)2
在numpy代码中,只需要替换一行代码。 计算距离的行替换为:
distances = np.sqrt(np.sum(np.square(self.Xtr - X[i,:]), axis = 1))
请注意,在上面包含了np.sqrt调用,但在实际的最近邻居应用程序中,可以省略平方根操作,因为平方根是单调函数。 也就是说,它缩放距离的绝对大小,但它保留了排序,因此最近的邻居有或没有它是相同的。
L1 VS L2
当涉及两个矢量之间的差异时,L2距离比L1距离更加unforgiving。 即,L2距离更喜欢许多中等分歧而不是一个大分歧。 L1和L2距离(或等效于一对图像之间差异的L1 / L2范数)是 p-norm中最常用的特殊情况。
2. 代码中实现 最近邻 和 K-近邻 类器
首先,将CIFAR-10数据作为4个数组加载到内存中:训练数据/标签和测试数据/标签。 在下面的代码中,Xtr(大小为50,000 x 32 x 32 x 3)保存训练集中的所有图像,相应的1维数组Ytr(长度为50,000)保存训练标签(从0到9):
Xtr, Ytr, Xte, Yte = load_CIFAR10('data/cifar10/') # a magic function we provide
# flatten out all images to be one-dimensional
Xtr_rows = Xtr.reshape(Xtr.shape[0], 32 * 32 * 3) # Xtr_rows becomes 50000 x 3072
Xte_rows = Xte.reshape(Xte.shape[0], 32 * 32 * 3) # Xte_rows becomes 10000 x 3072
- train and evaluate a classifier:
nn = NearestNeighbor() # create a Nearest Neighbor classifier class
nn.train(Xtr_rows, Ytr) # train the classifier on the training images and labels
Yte_predict = nn.predict(Xte_rows) # predict labels on the test images
# and now print the classification accuracy, which is the average number
# of examples that are correctly predicted (i.e. label matches)
print 'accuracy: %f' % ( np.mean(Yte_predict == Yte) )
Here is an implementation of a simple Nearest Neighbor classifier with the L1 distance that satisfies this template:
import numpy as np
class NearestNeighbor(object):
def __init__(self):
pass
def train(self, X, y):
""" X is N x D where each row is an example. Y is 1-dimension of size N """
# the nearest neighbor classifier simply remembers all the training data
self.Xtr = X
self.ytr = y
def predict(self, X):
""" X is N x D where each row is an example we wish to predict label for """
num_test = X.shape[0]
# lets make sure that the output type matches the input type
Ypred = np.zeros(num_test, dtype = self.ytr.dtype)
# loop over all test rows
for i in xrange(num_test):
# find the nearest training image to the i'th test image
# using the L1 distance (sum of absolute value differences)
distances = np.sum(np.abs(self.Xtr - X[i,:]), axis = 1)
min_index = np.argmin(distances) # get the index with smallest distance
Ypred[i] = self.ytr[min_index] # predict the label of the nearest example
return Ypred
注:
self.Xtr:
行:N个训练样本 ,列:每个样本的像素值(,1)

X[i,:]: 第i个测试样本
[[],[],[],…]-[ ]: 获得当前第i个测试图片和每一个训练集样本的误差(以矩阵形式呈现,行为一张图片每个像素点 的误差,列为N个样本),并经过sum按行求和。
2. K-Nearest Neighbors
不再是在训练集中找到最近的单个图像(k=1),而是找到最前面的k个最近的图像,并让它们在测试图像的标签上投票。 特别是,当k = 1时,我们恢复最近邻分类器。 直观地说,较高的k值具有平滑效应,使分类器更能抵抗异常值:

K-Nearest Neighbors 算法的代码实现
# assume we have Xtr_rows, Ytr, Xte_rows, Yte as before
# recall Xtr_rows is 50,000 x 3072 matrix
Xval_rows = Xtr_rows[:1000, :] # take first 1000 for validation
Yval = Ytr[:1000]
Xtr_rows = Xtr_rows[1000:, :] # keep last 49,000 for train
Ytr = Ytr[1000:]
# find hyperparameters that work best on the validation set
validation_accuracies = []
for k in [1, 3, 5, 10, 20, 50, 100]:
# use a particular value of k and evaluation on validation data
nn = NearestNeighbor()
nn.train(Xtr_rows, Ytr)
# here we assume a modified NearestNeighbor class that can take a k as input
Yval_predict = nn.predict(Xval_rows, k = k)
acc = np.mean(Yval_predict == Yval)
print 'accuracy: %f' % (acc,)
# keep track of what works on the validation set
validation_accuracies.append((k, acc))
3. 最近邻分类器的优劣
优点
- 实现和理解起来非常简单。
- 分类器没有训练时间,因为所需要的只是存储并可能索引训练数据。
- Nearest Neighbor分类器的计算复杂度研究是一个活跃的研究领域,若干Approximate Nearest Neighbor (ANN)算法和库的使用可以提升Nearest Neighbor分类器在数据上的计算速度(比如:FLANN)。这些算法可以在准确率和时空复杂度之间进行权衡,并通常依赖一个预处理/索引过程,这个过程中一般包含kd树的创建和k-means算法的运用。
缺点
-
分类器必须记住所有训练数据并将其存储起来,以便于未来测试数据用于比较。这在存储空间上是低效的,数据集的大小很容易就以GB计。
-
在测试时计算成本高,因为对测试示例进行分类需要与每个训练示例进行比较,在实践中我们经常关心测试时间效率远远超过训练时的效率。
-
数据是低维时,最近邻分类器有时可能是一个不错的选择,但它很少适用于实际的图像分类设置。 因为图像是高维物体(即它们通常包含许多像素),且高维空间上的距离可能非常违反直觉。 高维数据(尤其是图像)上的基于像素的距离可能非常不直观。 像素距离根本不对应于感知或语义相似性。
-
总结:原始像素值上使用L1或L2距离是不够的,因为距离与图像的背景和颜色分布的相关性比与其语义内容的相关性更强。















 1245
1245











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









