







写在前面
咕咕咕~
堂妹又回来啦😀
早前读者群小伙伴希望我出「机器学习入门系列」,这就来安排~
接下来,我会按照自己的节(慢)奏(慢)推出机器学习入门算法系列文章。
我给这个系列取名为「人工智"胀"」,是人工智「能」和人工智「障」的兄弟,
我知道我的读者很多不是这个领域的同学,没事儿,
我们边玩边学,希望轻松看文的同时有所收获。
当然,如果真的是想学技术,建议文档和源码。
带有情绪的技术文,本身就是图个乐~
开篇之作,我们先看个简易入门款:KNN。
KNN全称是 K Nearest Neighbors,直译就是「K个最近的邻居」。
理解一下这个表述,要「K个最近的邻居干啥呢」?
邻居是相对的概念,相对应的那个主体就是要讨论的对象。
换句话:“近朱者赤,近墨者黑”。
所以,用近邻对象的特征来表示主体的特征,即K近邻算法。
举个极端例子:
当你想要了解某个人的特征,可以参考他身边人的特征,
他身边人的性格也就大致上代表了他的性格。
这里面有两个问题:
问题1:参考几个人?
问题2:怎么衡量"身边"这个概念?
K值代表要参考的人数,当K为1,表示你只参考离它最近的☝️个人,显然很片面。
所以,K值怎么选得到的结果最准确,这是个学问,后面我们慢慢来看。
"身边"这个概念,可以量化成多种度量方式,最朴素的做法:欧氏距离。
一句总结:通过计算一群人和目前对象各自的欧氏距离,得到与目标对象距离最近的K个人,这K个人中出现频率最高的性格标签即为目标对象的性格标签。
so,快看看你身边有多少🦊朋🐕友(doge)。
大概原理如上,光说不练假把式。
我直接在数据集上验证一下这个算法的效果。
我在某数据集上进行了算法实现,
并给出了把准确率从76%提升到100%的优化思路和实现方案。
代码链接已公开在文末,开箱即用。
实验背景
-
数据来源:某约会网站上多个候选对象的三种行为数据统计。
-
情境假设:我结合自己的要求,利用已有数据构建算法模型。当有新的候选人来的时候,直接丢进模型,我就知道是不是我喜欢的类型,如果是,再考虑要不要约出来喝咖啡。节省大家时间,真是太机智了😉。
-
堂妹声明:以下措词不要代入我本人,结合场景介绍算法,而已。
我将候选人分为三大类:
-
类别标签一:不喜欢的人(didnotlike)
-
类别标签二:魅力一般的人(smallDoses)
-
类别标签三:极具魅力的人(largeDoses)
而三大类别对应的考核标准如下:
-
特征一:每年乘坐飞机的里程数
-
特征二:玩视频游戏所消耗的时间百分比
-
特征三:每周消费的冰淇凌公升数
我们来做一个可视化,对整体的数据分布有个认识~
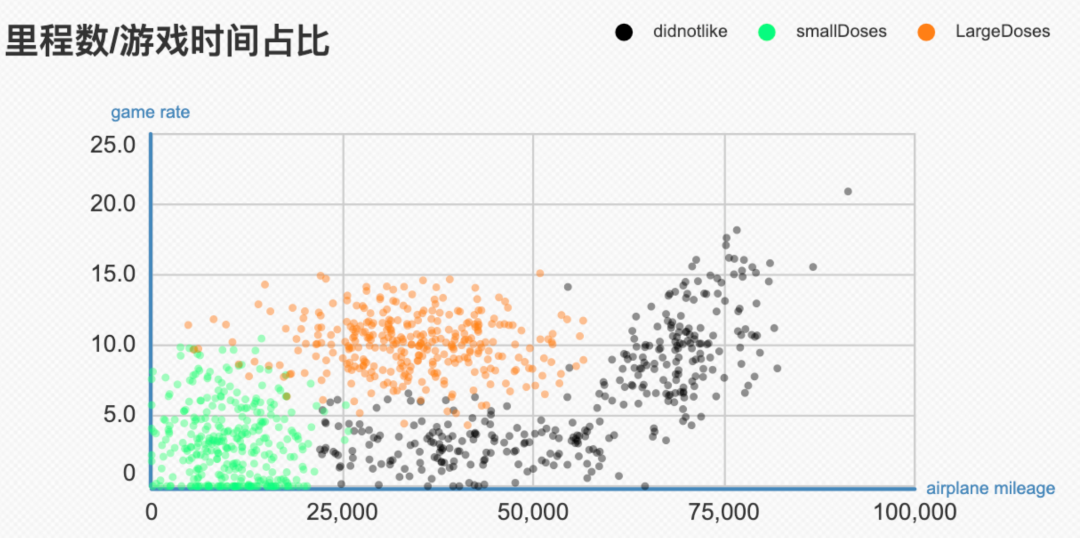
从上面这幅图我们有个初步印象:如果考虑飞机里程和游戏时间这两个因素,🛬里程多的大概率被划分到不喜欢的一类。
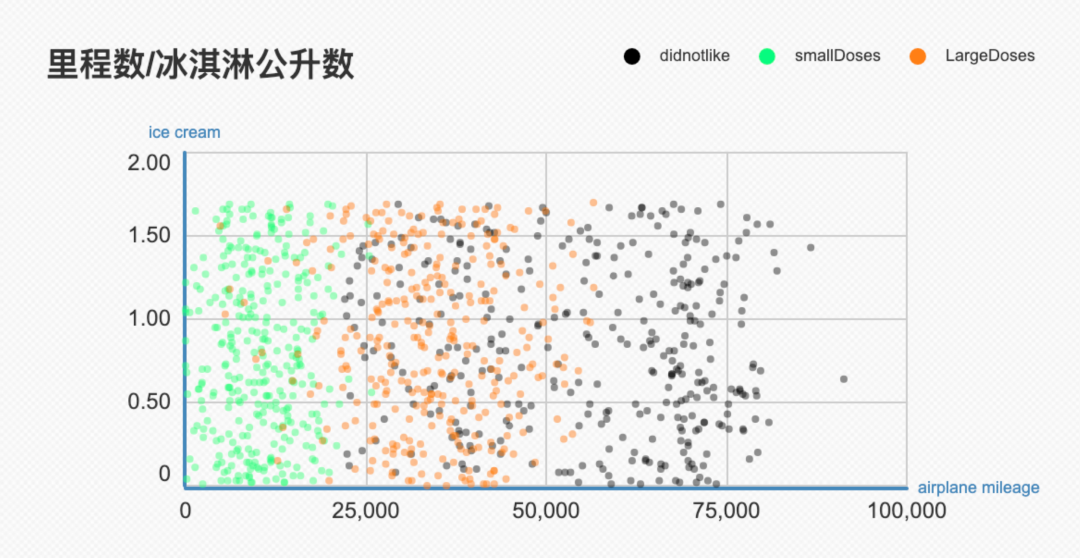
如果考虑飞机里程和喜欢吃冰激凌的程度两个因素,吃多少冰激凌不影响,有适当外出习惯的同学最佳。
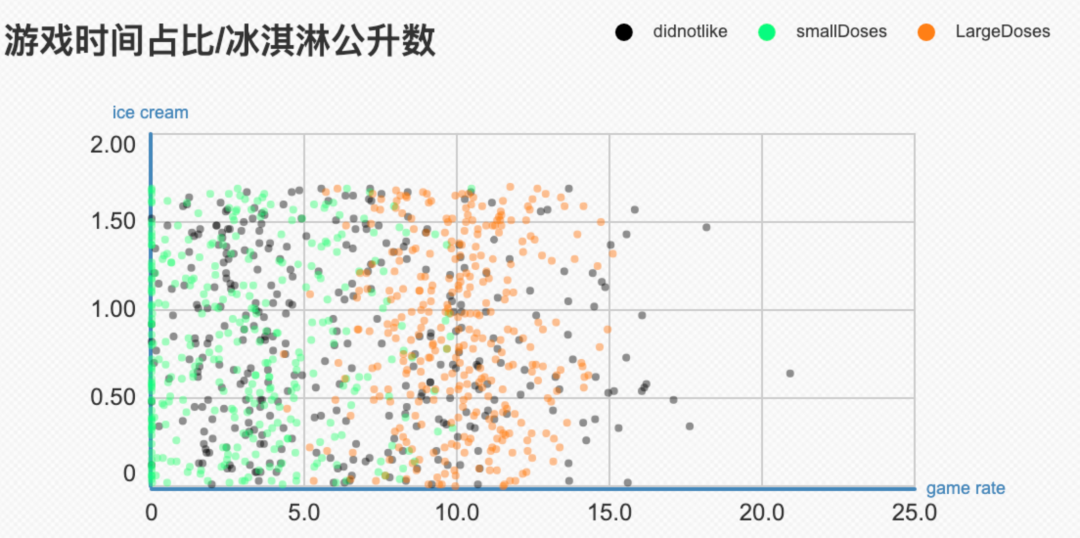
再看看玩游戏时间和冰激凌两个因素,从上面这幅图没有看出什么明显信息。
因此,初步结论:
-
太喜欢往外跑的,不考虑;
-
冰激凌的摄入量对选择影响不大。
带着这样的初步判断,我们实现一下算法。
算法实现
算法流程:
1. 准备待评测的数据
2. 计算待评测数据与每个已知数据的欧式距离
3. 将距离的结果排序,取前K个最近距离的类别标签
4. 统计类别标签出现的频率
5. 出现频率最高的类别标签即为待测数据的类别标签。
根据这个流程,我们实现KNN算法如下:
def classify(testData, knownData, labels, k):
'''
testData代表待测数据
knownData代表已知数据
labels代表已知数据的标签
k代表统计前k个数据
'''
DataSetSize = knownData.shape[0]
#计算输入数据与已知数据的欧式距离
diffMat = np.tile(testMat,(dataSetSize,1)) - dating #距离相减
sqDiffMat = diffMat**2 #求平方
sqDistances = sqDiffMat.sum(axis=1) #求和
sqDistances = sqrt(sqDistances) #求根号
sortedDisIndices = (sqDistances).argsort() #将距离排序
classCount = {}
for i in range(k):
votelLabel = labels[sortedDisIndices[i]] #取前K个标签
classCount[votelLabel] = classCount.get(votelLabel,0) + 1 #统计标签出现的频率
sortedClassCount = sorted(classCount.items(),key=operator.itemgetter(1),reverse=True) #将标签根据频率排序
return sortedClassCount[0][0] #返回频率最高的标签我们将现有数据分为两部分,一部分作为已知数据用于计算得到类别结果,俗称预测结果,一部分用于验证结果的准确性。
代码片段如下所示:
from dataload import Data # 读取数据函数,自己定义(github中有写)
dataset = Data()
ratio = 0.1 #准备划分10%数据测试
k = 10 #取前K个点的测试标签
datingmat, datinglabel = dataset.load_data('data.txt') #读取数据和标签,读取为矩阵形式
accuracy = result_knn(k,ratio,datinglabel,datingmat) #输入测试数据
print('accuracy rate: ',acccuracy) #输出测试准确率
def result_knn(k,ratio,datinglabel,datingmat):
'''
计算测试数据的准确率
'''
count = 0 #计算测试准确的个数
test_num = int(ratio * len(datinglabel)) #分出前10%当作未知数据进行测试
for i in range(test_num): #测试未知数据
class_result =classify(datingmat[i,:],datingmat[test_num:,:],datinglabel[test_num:], k) #测试第i个数据的标签
if class_result == self.datinglabel[i]: #判断测试是否正确
count += 1
return count/test_num将通过KNN算法计算得出的结果和其对应的真实标签计算准确率,
$ python test_knn.py
The best accuracy is : 76.0%只有76%,这个不太行呀🙃。
我们再来分析一下数据,发现不同特征的数据分布差别很大,如下表:
| 里程数 | 游戏时间 | 冰淇淋量(升) | |
| 最大值 | 91273.0 | 20.1 | 1.7 |
| 最小值 | 0.0 | 0.0 | 0.0 |
有过先验知识的同学一眼就能看出来,在计算距离的过程中,里程数变化较小的幅度就能引起结果的巨变,所以相当于前面的计算方式无形之中给了里程数一个高置信度。
置信度:指结果依赖某个特征的程度,高置信度也就是说这个特征对结果产生的影响比其他的特征影响大。
这时候就想到经典的规范数据分布的操作:归一化。
我们将所有的特征进行归一化,给每个特征相同的置信度,公式如下:
然后再次进行进行计算
$ python test_knn.py --autonorm
The best accuracy is : 94.0%结果显示准确率94%,论归一化的重要性!
到这儿关于KNN基本的流程差不多快结束了,我们回到最开始的问题:
-
K值选多少合适?
-
怎么衡量距离近?
这两个方面涉及KNN的优化,可选方案如下:
1. 选择最优K值
如开头所说,如果K=1,也就是只考虑最相似的一个数据,容易受噪点的影响。
如果K值过大,那可能会引入过的干扰类别标签,导致决策失误。
这时候我们可以通过「交叉验证法」来找到最佳K值。
交叉验证法是个比较常见的方法了,周志华老师的西瓜书前几章就有讲。
交叉验证法:将数据分为n组,循环选取某一组数据作为未知数据进行测试,其他数据作为已知数据计算结果,循环n次。
在这个算法中,每次取不同的K值,用交叉验证法验证N次,取N次的平均准确率作为对应K值的测试结果,直到找到最好的K值。
2. 对距离函数做加权处理
当我们计算欧式距离时,离我们更近的对象是不是可以更具有影响力?
而KNN将前K个距离的影响看作是相同的(计数时都看做加1)
那我们为每个点的距离增加一个权重,使得距离近的点可以得到更大的权重
那结果会不会更好一点?
加权处理的方法有很多,例如:反函数、高斯函数:
反函数:
该方法就是返回距离的倒数,公式如下:
其中W是权重,D是距离,这种方法能够给近邻一个大的权重,但是有时候会使算法对噪声数据变得特别敏感,例如某个噪声数据距离测试点特别近时,测得的权重很大,所以我们加入const作为约束,缓解权重过大的情况。
高斯函数:
高斯函数,公式如下:
其中a是曲线的高度、b是曲线中心在x轴的偏移、c是半峰宽度(函数峰值一半处相距宽度),高斯函数相较于反函数在权重分配上更合理。
例如当两个特征特别近时,反函数分配的权重可能是无穷大,而高斯函数的权重最大为a,结果更可控。
3.优化特征的置信度
上述做了归一化之后,将每个特征都看做是相同的置信度,但这样会把一些隐藏信息给忽略掉,过犹不及~
例如:冰淇淋的公升数变化并没有引起结果很大的变化,我们是否可以考虑将这个特征的置信度给减弱呢?
在这里,我们直接用第三种优化方案进行实践,一起来看下优化有没有效果。
我们采用网格法搜索🔍特征的最佳置信度:
网格法:给定参数的取值范围,根据指定规则生成一组数据。遍历数据集合得到最佳参数。
在这个例子中,就是构造三个特征参数列表,遍历获得对应每个特征的最佳组合。
代码节选如下:
import numpy as np
airplane_mileage, game_rate, ice_cream = [i for i in range(0,2,0.1)], [y for y in range(0,2,0.1)], [z for z in range(0,2,0.1)] #指定超参数范围
max_accuracy = 0.0
datingmat = autoNorm(datingmat) #归一化数据(自己定义的函数)
for am in airplane_mileage: #三组参数测试,得出最佳参数组合
for gr in game_rate:
for ic in ice_cream:
dating = (np.array([am,gr,ic]).reshape(3,1))*datingmat #获取处理后的数据
accuracy = result_knn(k,ratio,datinglabel,datingmat)
if accuracy >= max_accuracy:
max_accuracy = accuracy #保存测试的最佳准确率
parameter_gr, parameter_am, parameter_ic = gr, am, ic #保存最佳特征置信度的参数
print('Accuracy rate : {}\n Best airplane_mileage confidence : {} \n Best game_rate confidence : {} \n Best ice_cream : {}'.format(max_accuracy,parameter_am,parameter_gr,parameter_ic))最终我们得到的特征的最佳置信度为 0.21,1.99,0.08
$ python test_knn.py --autonorm --grid_serach
The best accuracy is : 100.0%
The best confidence is :
airplane mileage:0.21 game rate:1.99 ice cream:0.08准确率从95%提升到100%!!!! ✿✿ヽ(°▽°)ノ✿
我们来看下这组最优的置信度:
-
里程置信度为0.21,处于中间水平
-
游戏时间占比占据最高置信度
-
冰淇淋公升数置信度几乎为零
回想一下前面我们的预判,冰激凌确实对结果没什么影响~
那为什么置信度高低会影响准确率呢?
大家可以考虑这么个例子:
假设考虑x(0,0)和y(1,1)两点,计算欧式距离为,这时候每一个维度的置信度为1,如果将这两个维度的置信度变成(2,1),那么欧式距离为
,当置信度变成(0.5,1)时,欧式距离为
显而易见,当位置不变,置信度改变时,距离的远近也会改变。某个维度置信度高,则结果对这个维度的信息更加敏感,反之亦然。
在实际情况中,置信度则反映了结果对于每个维度的隐性敏感度。
所以🦆,从数据整体分布来看。表面上我很在意外出✈️里程数,实际最在意的是男孩子玩游戏的时间,相信大部分👧女孩子都比较在意叭(doge)
So,找对象,凭感觉是一方面,数据说话也是硬道理😁
堂妹在这儿用的是K=10,10%的数据测试准确率。大家可以尝试采用不同K值测试结果!!!
结束啦
完结式撒花💐~
完整链接戳:
https://github.com/JDZTZ/machine_learning
喜欢堂妹这个系列的小伙伴欢迎「分享、点赞」,
鼓励堂妹多多产出,我在澡堂子里等你们🦆~
什么?你还不知道怎么加入澡堂子?
微信扫一扫下方二维码,关注「九点澡堂子」
获取堂妹为你准备的求职大礼包、精品行业报告😘
回复「糖友福利」获取澡堂子专属福利💖















 2546
2546











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









