






在Apache Spark中,RDD(Resilient Distributed Dataset,弹性分布式数据集)是其核心概念之一。RDD 是对分布式数据集的抽象表示,它代表了可分区、可并行操作的数据集合。
RDD的本质:
-
分布式数据集: RDD 是 Spark 中对数据的抽象表示,它是一组被分割成多个分区(partitions)的元素的集合。这些分区可以分布在集群中的多台计算机上,使得数据能够并行处理。
-
不可变性: RDD 是不可变的数据结构,一旦创建就不能被修改。任何对 RDD 的操作都会生成一个新的 RDD,而不会影响原始的 RDD,这符合函数式编程的概念。
-
容错性: RDD 具有弹性(resilient)和容错的特性。通过记录数据的变换操作(转换操作),RDD 可以在发生错误时重新计算丢失的数据,以保证计算的正确性。
-
惰性计算: RDD 支持惰性计算(lazy evaluation),即在执行转换操作时,并不会立即执行,而是等到遇到动作操作(action)时才会触发实际计算。
-
可并行操作: RDD 提供了一系列的转换操作(如map、filter、reduce等),这些操作允许在分布式集群上并行执行,以便对数据进行转换和处理。
-
数据来源: RDD 可以由外部数据源(如HDFS、本地文件系统、数据库等)创建,也可以由其他RDD经过转换操作生成。
RDD 的本质在于提供了一种高度抽象的数据处理模型,允许以高效的方式在分布式环境中进行数据操作和计算。虽然在 Spark 中,RDD 的使用逐渐被更高层次的抽象如DataFrame和Dataset所取代,但是了解 RDD 仍然有助于理解 Spark 的底层原理和数据处理模型。
在 Apache Spark 的源码中,RDD(Resilient Distributed Dataset)的主要实现类是 org.apache.spark.rdd.RDD。这个类是 Spark 中核心的抽象,它提供了分布式计算的基本数据结构。
RDD类的属性和方法
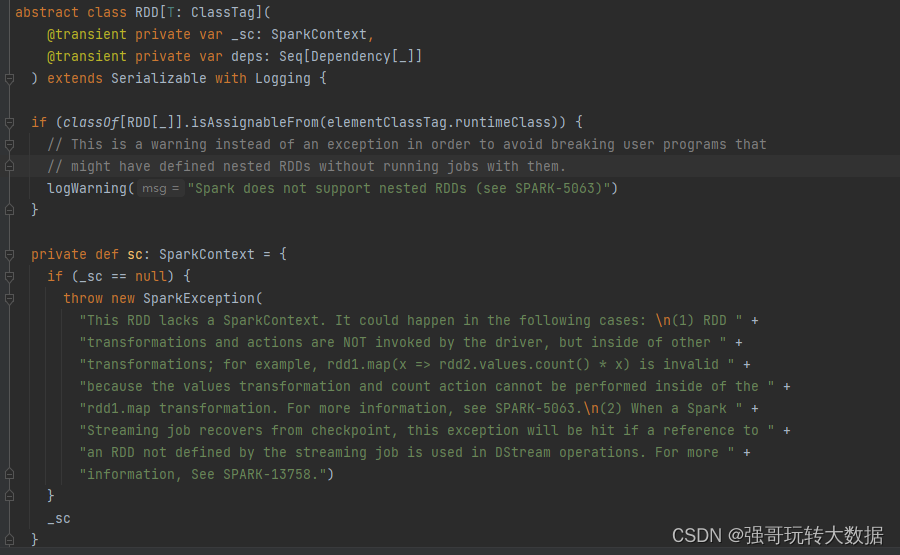
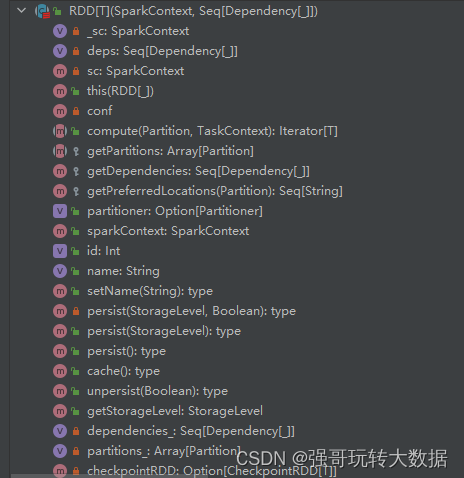
org.apache.spark.rdd.RDD 类包含了一系列属性和方法,其中一些核心的属性和方法包括:
属性(部分)
id: Int- RDD 的唯一标识符。partitions: Array[Partition]- 用于分区的抽象。dependencies: Seq[Dependency[_]]- RDD 之间的依赖关系。context: Option[SparkContext]- RDD 所属的 SparkContext。
方法(部分)
map[U](f: T => U): RDD[U]- 对 RDD 中的每个元素应用函数f。filter(f: T => Boolean): RDD[T]- 过滤 RDD 中满足给定条件的元素。reduce(f: (T, T) => T): T- 对 RDD 中的元素进行聚合操作。collect(): Array[T]- 将 RDD 中的所有元素收集到数组中。persist(storageLevel: StorageLevel): RDD[T]- 将 RDD 缓存在内存或磁盘中以便复用。
这些方法和属性是 org.apache.spark.rdd.RDD 类中常用的一部分。实际上,RDD 类包含了更多的方法和属性,用于支持广泛的转换和操作,用于分布式计算和处理数据。
子类和继承关系
在 Spark 源码中,org.apache.spark.rdd.RDD 类有多个子类和继承类。一些常见的子类和继承类包括:
org.apache.spark.rdd.ShuffledRDD- 表示通过分区器(Partitioner)进行 shuffle 操作的 RDD。org.apache.spark.rdd.CoGroupedRDD- 用于执行 co-group 操作的 RDD。org.apache.spark.rdd.CheckpointRDD- 代表检查点(checkpoint)的 RDD。org.apache.spark.sql.Dataset- Spark SQL 中的 Dataset 类,是 RDD 的抽象之一。
此外,在不同的模块和扩展中,还可能会有其他RDD的子类或实现类,用于不同的特定用途和优化。这些子类和继承类扩展了 org.apache.spark.rdd.RDD 类的功能,提供了更多特定的功能或优化。















 550
550











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









