







本文主要讲
1、什么是RDD
2、RDD是如何从数据中构建
一、什么是RDD?
RDD:弹性分布式数据集,Resillient Distributed Dataset的缩写。
个人理解:RDD是一个容错的、并行的数据结构,可以让用户显式的将数据存储到磁盘和内存中,并能控制数据的分区。同时RDD还提供一组丰富的API来操作它。本质上,RDD是一个只读的分区集合,一个RDD可以包含多个分区,每个分区就是一个dataset片段。RDD可以互相依赖
二、RDD是如何从数据中构建
2.1、RDD源码
Internally, each RDD is characterized by five main properties
A list of pattitions
A function for computing each split
A list of dependencies on each RDDs
optionally, a partitioner for key-value RDDs(e.g. to say that RDD is hash-partitioned)
optionally, a list of preferred locations to compute each split on (e.g. block locations for an HDFS file)
RDD基本都有这5个特性:
1、每个RDD 都会有 一个分片列表。 就是可以被切分,和hadoop一样,能够被切分的数据才能并行计算
2、有一个函数计算每一个分片。这里是指下面会提到的compute函数
3、对其他RDD的依赖列表。依赖区分宽依赖和窄依赖
4、可选:key-value类型的RDD是根据hash来分区的,类似于mapreduce当中的partitioner接口,控制哪个key分到哪个reduce
5、可选:每一个分片的有效计算位置(preferred locations),比如HDFS的block的所在位置应该是优先计算的位置
2.2、宽窄依赖
如果一个RDD的每个分区最多只能被一个Child RDD的一个分区所使用, 则称之为窄依赖(Narrow dependency), 如果被多个Child RDD分区依赖, 则称之为宽依赖(wide dependency)
例如 map、filter是窄依赖, 而join、groupby是宽依赖
2.3、源码分析
RDD的5个特征会对应到源码中的 4个方法 和一个属性
RDD.scala是一个总的抽象,不同的子类会对下面的方法进行定制化的实现。比如compute方法,不同子类在实现的时候是不同的。
// 该方法只会被调用一次。由子类实现,返回这个RDD下的所有Partition
protected def getPartitions: Array[Partition]
// 该方法只会被调用一次。计算该RDD和父RDD的关系
protected def getDenpendencies: Seq[Dependency[_]] = deps
//对分区进行计算,返回一个可遍历的结果
def compute(split: Partition, context: TaskContext): Iterator[T]
//可选的,指定优先位置,输入参数是split分片,输出结果是一组优先的节点位置
protected def getPreferredLocations(split: Partition): Seq(String)= Nil
// 可选的,分区的方法,针对第4点,控制分区的计算规则
@transient val partitioner: Option[Partitioner] = None
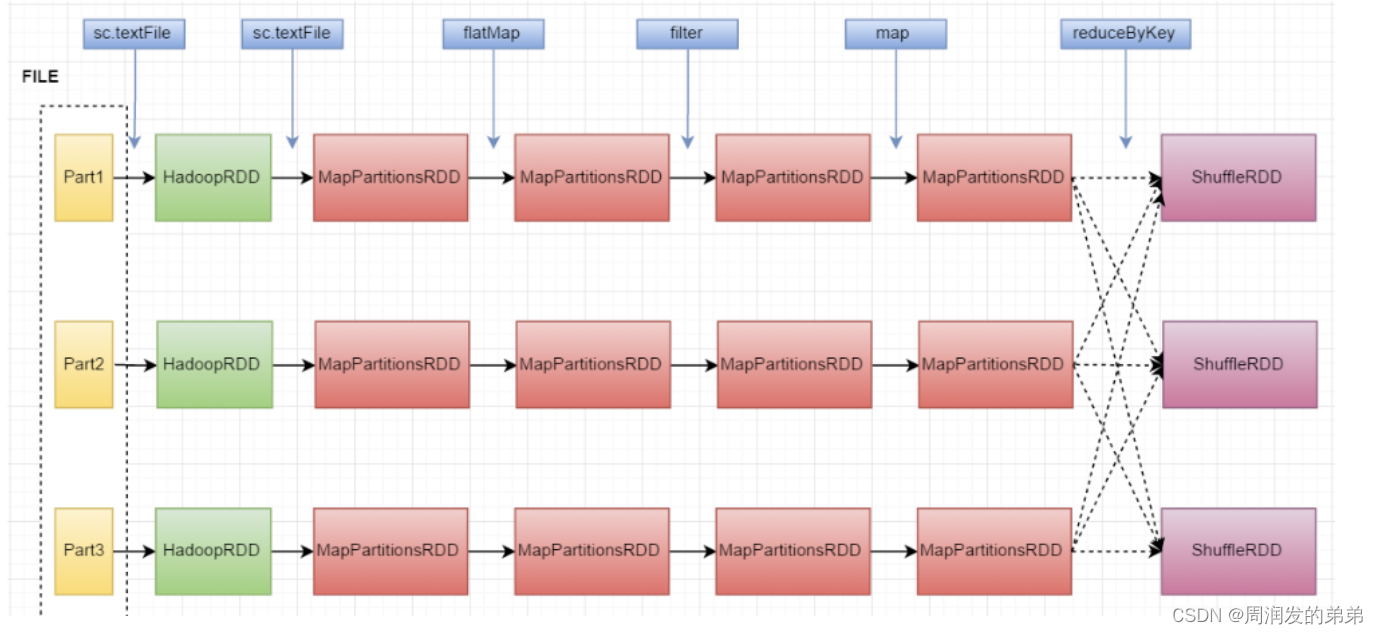
拿官网上的workcount举例:
val textFile = sc.textFile("文件目录/test.txt")
val counts = textFile.flatMap(line => line.split(" "))
.filter(_.length >= 2)
.map(word => (word, 1))
.reduceByKey(_ + _)
counts.saveAsTextFile("hdfs://...")这里涉及到几个RDD的转换
1、textfile是一个hadoopRDD经过map转换后的MapPartitionsRDD,
2、经过flatMap后仍然是一个MapPartitionsRDD
3、经过filter方法之后生成了一个新的MapPartitionRDD
4、经过map函数之后,继续是一个MapPartitionsRDD
5、经过最后一个reduceByKey编程了ShuffleRDD
文件分为一个part1,part2,part3经过spark读取之后就变成了HadoopRDD,再按上面流程理解即可
2.3.1、代码分析:SparkContext 类
本次只看textfile方法,注释上说明
Read a text file from HDFS, a local file system (available on all nodes), or any Hadoop-supported file system URI, and return it as an RDD of Strings. 读取text文本从hdfs上、本地文件系统,或者hadoop支持的文件系统URI中, 返回一个String类型的RDD
看代码:
hadoopFile最后返回的是一个HadoopRDD对象,然后经过map变换后,转换成MapPartitionsRDD,鱿鱼HadoopRDD没有重写map函数,所以调用的是父类的RDD的map
def textFile(path: String,
minPartitions: Int = defaultMinPartitions): RDD[String] = withScope {
assertNotStopped() // 忽略不看
hadoopFile(path, classOf[TextInputFormat], classOf[LongWritable], classOf[Text], minPartitions)
.map(pair => pair._2.toString).setName(path)
}看下hadoopFile方法
1、广播hadoop的配置文件
2、设置文件的输入格式之类的,也决定的文件的读取方式
3、new HadoopRDD,并返回
def hadoopFile[K, V](path: String,
inputFormatClass: Class[_ <: InputFormat[K, V]],
keyClass: Class[K],
valueClass: Class[V],
minPartitions: Int = defaultMinPartitions): RDD[(K, V)] = withScope {
assertNotStopped()
// 做一些校验
FileSystem.getLocal(hadoopConfiguration)
// A Hadoop configuration can be about 10 KiB, which is pretty big, so broadcast it.
val confBroadcast = broadcast(new SerializableConfiguration(hadoopConfiguration))
val setInputPathsFunc = (jobConf: JobConf) => FileInputFormat.setInputPaths(jobConf, path)
new HadoopRDD(
this,
confBroadcast,
Some(setInputPathsFunc),
inputFormatClass,
keyClass,
valueClass,
minPartitions).setName(path)
}2.3.2、源码分析:HadoopRDD类
先看注释
An RDD that provides core functionality for reading data stored in Hadoop (e.g., files in HDFS, sources in HBase, or S3), using the older MapReduce API (org.apache.hadoop.mapred).
看注释可以知道,HadoopRDD是一个专为Hadoop(HDFS、Hbase、S3)设计的RDD。使用的是以前的MapReduce 的API来读取的。
HadoopRDD extends RDD[(K, V)] 重写了RDD中的三个方法
override def compute(theSplit: Partition, context: TaskContext): InterruptibleIterator[(K, V)] = {}
override def getPartitions: Array[Partition] = {}
override def getPreferredLocations(split: Partition): Seq[String] = {}分别来看一下
HadoopRDD#getPartitions
1、读取配置文件
2、通过inputFormat自带的getSplits方法来计算分片,获取所有的Splits
3、创建HadoopPartition的List并返回
这里是不是可以理解,Hadoop中的一个分片,就对应到Spark中的一个Partition
override def getPartitions: Array[Partition] = {
val jobConf = getJobConf()
// add the credentials here as this can be called before SparkContext initialized
SparkHadoopUtil.get.addCredentials(jobConf)
try {
// 通过配置的文件读取方式获取所有的Splits
val allInputSplits = getInputFormat(jobConf).getSplits(jobConf, minPartitions)
val inputSplits = if (ignoreEmptySplits) {
allInputSplits.filter(_.getLength > 0)
} else {
allInputSplits
}
// 创建Partition的List
val array = new Array[Partition](inputSplits.size)
for (i <- 0 until inputSplits.size) {
// 创建HadoopPartition
array(i) = new HadoopPartition(id, i, inputSplits(i))
}
array
} catch {
异常处理
}
}HadoopRDD#compute
compute的作用主要是 根据输入的partition信息生成一个InterruptibleIterator。
iter中的逻辑主要是
1、把Partition转成HadoopPartition,通过InputSplit创建一个RecordReader
2、重写Iterator的getNext方法,通过创建的reader调用next方法读取下一个值
compute方法通过Partition来获取Iterator接口,以遍历Partition的数据
override def compute(theSplit: Partition, context: TaskContext): InterruptibleIterator[(K, V)] = {
val iter = new NextIterator[(K, V)] {...}
new InterruptibleIterator[(K, V)](context, iter)
}
override def compute(theSplit: Partition, context: TaskContext): InterruptibleIterator[(K, V)] = {
val iter = new NextIterator[(K, V)] {
//将compute的输入theSplit,转换为HadoopPartition
val split = theSplit.asInstanceOf[HadoopPartition]
......
//c重写getNext方法
override def getNext(): (K, V) = {
try {
finished = !reader.next(key, value)
} catch {
case _: EOFException if ignoreCorruptFiles => finished = true
}
if (!finished) {
inputMetrics.incRecordsRead(1)
}
(key, value)
}
}
}HadoopRDD#getPreferredLocations
getPreferredLocations方法比较简单,直接调用SplitInfoReflections下的inputSplitWithLocationInfo方法获得所在的位置。
override def getPreferredLocations(split: Partition): Seq[String] = {
val hsplit = split.asInstanceOf[HadoopPartition].inputSplit.value
val locs: Option[Seq[String]] = HadoopRDD.SPLIT_INFO_REFLECTIONS match {
case Some(c) =>
try {
val lsplit = c.inputSplitWithLocationInfo.cast(hsplit)
val infos = c.getLocationInfo.invoke(lsplit).asInstanceOf[Array[AnyRef]]
Some(HadoopRDD.convertSplitLocationInfo(infos))
} catch {
case e: Exception =>
logDebug("Failed to use InputSplitWithLocations.", e)
None
}
case None => None
}
locs.getOrElse(hsplit.getLocations.filter(_ != "localhost"))
}2.3.3、源码分析:MapHadoopRDD类
An RDD that applies the provided function to every partition of the parent RDD.
经过RDD提供的function处理后的 父RDD 将会变成MapHadoopRDD
MapHadoopRDD重写了父类的partitioner、getPartitions和compute方法
private[spark] class MapPartitionsRDD[U: ClassTag, T: ClassTag](
var prev: RDD[T],
f: (TaskContext, Int, Iterator[T]) => Iterator[U], // (TaskContext, partition index, iterator)
preservesPartitioning: Boolean = false)
extends RDD[U](prev) {
override val partitioner = if (preservesPartitioning) firstParent[T].partitioner else None
override def getPartitions: Array[Partition] = firstParent[T].partitions
override def compute(split: Partition, context: TaskContext): Iterator[U] =
f(context, split.index, firstParent[T].iterator(split, context))
override def clearDependencies() {
super.clearDependencies()
prev = null
}
}在partitioner、getPartitions、compute中都用到了一个firstParent函数,可以看到,在MapPartition中并没有重写partitioner和getPartitions方法,只是从firstParent中取了出来
再看下firstParent是干什么的,其实就是取的父依赖
/** Returns the first parent RDD */
protected[spark] def firstParent[U: ClassTag]: RDD[U] = {
dependencies.head.rdd.asInstanceOf[RDD[U]]
}再看一下MapPartitionsRDD继承的RDD,它继承的是RDD[U] (prev),这里的prev指的是我们的HadoopRDD,也就是说HadoopRDD变成了我们这个MapPartitionRDD的OneToOneDependency依赖,OneToOneDependency是窄依赖
def this(@transient oneParent: RDD[_]) =
this(oneParent.context , List(new OneToOneDependency(oneParent)))再来看map方法
/**
* Return a new RDD by applying a function to all elements of this RDD.
* 通过将函数应用于新RDD的所有元素,返回新的RDD。
*/
def map[U: ClassTag](f: T => U): RDD[U] = withScope {
val cleanF = sc.clean(f)
new MapPartitionsRDD[U, T](this, (context, pid, iter) => iter.map(cleanF))
}flatMap方法
/**
* Return a new RDD by first applying a function to all elements of this
* RDD, and then flattening the results.
*/
def flatMap[U: ClassTag](f: T => TraversableOnce[U]): RDD[U] = withScope {
val cleanF = sc.clean(f)
new MapPartitionsRDD[U, T](this, (context, pid, iter) => iter.flatMap(cleanF))
}filter方法
/**
* Return a new RDD containing only the elements that satisfy a predicate.
* 返回仅包含满足表达式 的元素的新RDD。
*/
def filter(f: T => Boolean): RDD[T] = withScope {
val cleanF = sc.clean(f)
new MapPartitionsRDD[T, T](
this,
(context, pid, iter) => iter.filter(cleanF),
preservesPartitioning = true)
}观察代码发现,他们返回的都是MapPartitionsRDD对象,不同的仅仅是传入的function不同而已,经过前面的分析,这些都是窄依赖
注意:这里我们可以明白了MapPartitionsRDD的compute方法的作用了:
1、在没有依赖的条件下,根据分片的信息生成遍历数据的iterable接口
2、在有前置依赖的条件下,在父RDD的iterable接口上给遍历每个元素的时候再套上一个方法
2.3.4、源码分析:PairRDDFunctions 类
接下来,该reduceByKey操作了。它在PairRDDFunctions里面
reduceByKey稍微复杂一点,因为这里有一个同相同key的内容聚合的一个过程,它调用的是combineByKey方法。
/**
* Merge the values for each key using an associative reduce function. This will also perform
* the merging locally on each mapper before sending results to a reducer, similarly to a
* "combiner" in MapReduce.
*/
def reduceByKey(partitioner: Partitioner, func: (V, V) => V): RDD[(K, V)] = self.withScope {
combineByKeyWithClassTag[V]((v: V) => v, func, func, partitioner)
}
/**
* Generic function to combine the elements for each key using a custom set of aggregation
泛型函数,将每个key的元素 通过自定义的聚合 来组合到一起
* functions. Turns an RDD[(K, V)] into a result of type RDD[(K, C)], for a "combined type" C
*
* Users provide three functions:
*
* - `createCombiner`, which turns a V into a C (e.g., creates a one-element list)
* - `mergeValue`, to merge a V into a C (e.g., adds it to the end of a list)
* - `mergeCombiners`, to combine two C's into a single one.
*
* In addition, users can control the partitioning of the output RDD, and whether to perform
* map-side aggregation (if a mapper can produce multiple items with the same key).
*
* @note V and C can be different -- for example, one might group an RDD of type
* (Int, Int) into an RDD of type (Int, Seq[Int]).
*/
def combineByKeyWithClassTag[C](
createCombiner: V => C,
mergeValue: (C, V) => C,
mergeCombiners: (C, C) => C,
partitioner: Partitioner,
mapSideCombine: Boolean = true,
serializer: Serializer = null)(implicit ct: ClassTag[C]): RDD[(K, C)] = self.withScope {
require(mergeCombiners != null, "mergeCombiners must be defined") // required as of Spark 0.9.0
// 判断keyclass是不是array类型,如果是array并且在两种情况下throw exception。
if (keyClass.isArray) {
if (mapSideCombine) {
throw SparkCoreErrors.cannotUseMapSideCombiningWithArrayKeyError()
}
if (partitioner.isInstanceOf[HashPartitioner]) {
throw SparkCoreErrors.hashPartitionerCannotPartitionArrayKeyError()
}
}
val aggregator = new Aggregator[K, V, C](
self.context.clean(createCombiner),
self.context.clean(mergeValue),
self.context.clean(mergeCombiners))
//虽然不太明白,但是此处基本上一直是false,感兴趣的看后面的参考文章
if (self.partitioner == Some(partitioner)) {
self.mapPartitions(iter => {
val context = TaskContext.get()
new InterruptibleIterator(context, aggregator.combineValuesByKey(iter, context))
}, preservesPartitioning = true)
} else {
// 默认走这个方法
new ShuffledRDD[K, V, C](self, partitioner)
.setSerializer(serializer)
.setAggregator(aggregator)
.setMapSideCombine(mapSideCombine)
}
}2.3.5、源码分析:ShuffledRDD类
看上面代码最后传入了self和partitioner ,并set了三个值,shuffled过程暂时不做解析。这里看下ShuffledRDD的依赖关系(getDependencies方法),它是一个宽依赖
override def getDependencies: Seq[Dependency[_]] = {
val serializer = userSpecifiedSerializer.getOrElse {
val serializerManager = SparkEnv.get.serializerManager
if (mapSideCombine) {
serializerManager.getSerializer(implicitly[ClassTag[K]], implicitly[ClassTag[C]])
} else {
serializerManager.getSerializer(implicitly[ClassTag[K]], implicitly[ClassTag[V]])
}
}
List(new ShuffleDependency(prev, part, serializer, keyOrdering, aggregator, mapSideCombine))
}总结:我们讲了RDD的基本组成结构,也通过一个wordcount程序举例来说明代码是如果运行的,希望大家可以从源码入手,学习spark,共勉!
















 2156
2156











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











