







Python创建线程的两种方式
Python有两种方式创建线程:
一种是创建一个新的类并继承threading.Thread类, 然后重写run()方法;
另外一种是单独编写函数func, 并使用threading.Thread(target=func), 该方法会被run()调用。
下面我们使用线程实现打印一个从begin到end的整数的需求。
继承Thread类创建线程
import threading
import time
class ThreadDemo(threading.Thread):
def __init__(self, begin, end):
super().__init__()
self.begin = begin
self.end = end
def run(self):
"""
重写run()方法
"""
for i in range(self.begin, self.end):
print(i)
thread_demo = ThreadDemo(1, 999)
thread_demo.start()
使用target调用
import threading
def print_range(start, end):
for i in range(start, end):
print(i)
thread_func = threading.Thread(target=print_range, args=(1, 10))
thread_func.start()
线程的方法
start
start() 方法用来启动一个线程。
它在一个线程里最多只可被调用一次, 调用它时会执行run()函数。
run
线程执行的具体方法。
你可以在子类里重写这个方法; 如果使用target传入函数名称以及参数,也会调用并执行这个方法。
真正调起线程的是start方法, 而run方法只是一个普通函数。
使用上面的例子稍加改造验证一下:
首先使用start方法:
import threading
import time
def print_range(start, end):
for i in range(start, end):
print(i, end=" ")
time.sleep(0.1)
func1 = threading.Thread(target=print_range, args=(1, 10))
func2 = threading.Thread(target=print_range, args=(1, 10))
func1.start()
func2.start()
输出
1 1 2 2 3 3 4 4 5 5 6 6 7 7 8 8 9 9
可以看到线程是并发执行。
使用run方法:
import threading
import time
def print_range(start, end):
for i in range(start, end):
print(i, end=" ")
time.sleep(0.1)
func1 = threading.Thread(target=print_range, args=(1, 10))
func2 = threading.Thread(target=print_range, args=(1, 10))
func1.run()
func2.run()
输出
1 2 3 4 5 6 7 8 9 1 2 3 4 5 6 7 8 9
可以看出, 是按照顺序执行的, 并不是并发执行。
join
阻塞本线程, 直到线程结束或者timeout超时
import threading
import time
def print_range(start, end):
for i in range(start, end):
print("{} {}".format(threading.current_thread().name, i))
print("{} {}".format(threading.current_thread().name, threading.current_thread().is_alive()))
time.sleep(0.1)
func1 = threading.Thread(target=print_range, args=(1, 5))
func2 = threading.Thread(target=print_range, args=(1, 5))
func1.start()
func1.join()
print(func1.is_alive())
func2.start()
输出
Thread-1 1
Thread-1 True
Thread-1 2
Thread-1 True
Thread-1 3
Thread-1 True
Thread-1 4
Thread-1 True
False # 线程1阻塞直到结束
Thread-2 1
Thread-2 True
Thread-2 2
Thread-2 True
Thread-2 3
Thread-2 True
Thread-2 4
Thread-2 True
daemon
用于创建守护线程, 当所有的非守护线程都结束时, 守护线程会自动结束, 整个Python程序也会结束。
设置线程1为守护线程, 当非守护线程2结束时, 整个程序都会结束
import threading
import time
def print_range(start, end):
for i in range(start, end):
print("{} {}".format(threading.current_thread().name, i))
time.sleep(0.1)
func1 = threading.Thread(target=print_range, args=(1, 5000), daemon=True)
func2 = threading.Thread(target=print_range, args=(1, 5))
func1.start()
func2.start()
输出
Thread-1 1
Thread-2 1
Thread-1 2
Thread-2 2
Thread-2 3
Thread-1 3
Thread-2 4
Thread-1 4 # 非守护线程结束
Thread-1 5 # 守护线程也随之结束, 程序结束
线程锁
多线程运行时, 所有线程共享内存, 需要操作全局变量时, 多个线程会竞争资源, 导致全局变量处于一个不可预测的状态。
引用廖雪峰老师的例子, 存取的数量相等, 无论循环多少次,最终的结果应该是0
import threading
balance = 0
def change_it(n):
# 先存后取,结果应该为0:
global balance
balance = balance + n
balance = balance - n
def run_thread(n):
for i in range(1000000):
change_it(n)
t1 = threading.Thread(target=run_thread, args=(5,))
t2 = threading.Thread(target=run_thread, args=(8,))
t1.start()
t2.start()
t1.join()
t2.join()
print(balance)
加大一个数量级的循环后,最终的balance是6。
如果没有线程锁的存在, 一个线程读的时候正好另外一个线程写, 就会导致余额不正确。
- acquire() 会使线程处于lock状态
- release() 会释放锁
- acquire() 和 release() 在一个线程中总是成对出现的
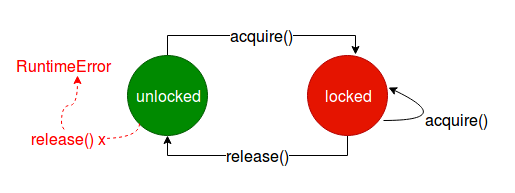
锁的好处:
- 保证了一段代码在一个线程中完整的执行
坏处:
- 降低了多线程运行的效率
- 多个线程存在多个锁的情况下,线程之间在试图获取对方的锁时,有可能导致程序死锁, 死锁后线程都会挂起, 只能强制杀死程序。
使用with代替acquire()和release()
acquire() 和 release() 可以被用作with的上下文管理器:当进入语句时acquire()被调用, 退出语句时release()被调用。
以下语句:
with some_lock:
do_something()
等同于
some_lock.acquire()
try:
do_something()
finally:
some_lock.release()
线程之间的通信
wait()、notify()和notify_all() 方法用于线程间的通信
- wait(timeout=None)
释放锁, 然后阻塞线程, 直至其他线程的notify()和notify_all()唤起该线程。 一旦被唤起, 它会重新获取锁并返回。 它可以设置超时时间 - notify(n=1)
唤起一个或者多个处于waiting状态的线程, 线程的唤起是随机的。
注意: 不会释放锁。 - notify_all()
唤起所有处于waiting状态的线程。
注意: 不会释放锁。
生产者-消费者模型
线程间通信的典型应用是生产者-消费者模型。
生产者生产商品, 当生产到最大库存的时候通知消费者消费;消费者消费产品, 当库存为0的时候通知生产者生产。
实现代码如下:
import threading
import random
import time
class Producer(threading.Thread):
def run(self):
class_name = __class__.__name__
global max_amount
global products
while True:
# 获得锁
condition.acquire()
# 继续生产
if len(products) < max_amount:
product = random.randint(1, 100)
print("{} produce {}".format(class_name, product))
products.append(product)
else:
# 生产完毕, 通知消费者
print("{} notify Consumer".format(class_name))
condition.notify()
condition.wait()
print("{} unlock".format(class_name))
condition.release()
time.sleep(1)
class Consumer(threading.Thread):
def run(self):
class_name = __class__.__name__
global max_amount
global products
while True:
# 获得锁
condition.acquire()
# 继续消费
if len(products) > 0:
consume = products.pop(0)
print("{} consume {}".format(class_name, consume))
else:
# 消费完毕, 通知生产者
print("{} notify Producer".format(class_name))
condition.notify()
condition.wait()
print("{} unlock".format(class_name))
condition.release()
time.sleep(1)
products = []
max_amount = 5
condition = threading.Condition()
producer = Producer()
consumer = Consumer()
producer.start()
consumer.start()
改造一下生产者-消费者模型, 实现生产者每生产1个商品, 消费者便消费掉。只需在生产者生产后调用wait(), 生产者线程阻塞, 释放锁;消费者消费掉产品,调用notify()通知生产者继续生产。
代码如下:
import threading
import random
import time
class Producer(threading.Thread):
def run(self):
class_name = __class__.__name__
global max_amount
global products
while True:
# 获得锁
condition.acquire()
# 继续生产
while len(products) < max_amount:
product = random.randint(1, 100)
print("{} produce {}".format(class_name, product))
products.append(product)
condition.wait()
# 生产完毕, 通知消费者
# print("{} notify Consumer".format(class_name))
# condition.notify()
#
# print("{} unlock".format(class_name))
# condition.release()
# time.sleep(1)
class Consumer(threading.Thread):
def run(self):
class_name = __class__.__name__
global max_amount
global products
while True:
# 获得锁
condition.acquire()
# 继续消费
while len(products) > 0:
consume = products.pop(0)
print("{} consume {}".format(class_name, consume))
# condition.wait()
# 消费完毕, 通知生产者
print("{} notify Producer".format(class_name))
condition.notify()
print("{} unlock".format(class_name))
condition.release()
time.sleep(1)
products = []
max_amount = 5
condition = threading.Condition()
producer = Producer()
consumer = Consumer()
producer.start()
consumer.start()
交替打印奇偶数
给定一个数字范围, 使用多线程交替打印奇偶数。注意循环退出的位置。
import threading
class Even(threading.Thread):
def __init__(self, range_num):
super().__init__()
self.range_num = range_num
def run(self):
global num
condition.acquire()
while True:
if num % 2 == 0:
if num == self.range_num:
break
print("{} {}".format(__class__.__name__, num))
num += 1
else:
condition.notify()
# 循环退出必须在notify后, 否则另外一个线程会一直处于wait状态
if num == self.range_num:
break
condition.wait()
condition.release()
class Odd(threading.Thread):
def __init__(self, range_num):
super().__init__()
self.range_num = range_num
def run(self):
global num
condition.acquire()
while True:
if num % 2 == 1:
if num == self.range_num:
break
print("{} {}".format(__class__.__name__, num))
num += 1
else:
condition.notify()
# 循环退出必须在notify后, 否则另外一个线程会一直处于wait状态
if num == self.range_num:
break
condition.wait()
condition.release()
condition = threading.Condition()
num = 0
even_thread = Even(10)
odd_thread = Odd(10)
even_thread.start()
odd_thread.start()
even_thread.join()
odd_thread.join()
线程安全的数据类型
线程安全:多线程环境中,共享数据同一时间只能有一个线程来操作。
原子操作:原子操作就是不会因为进程并发或者线程并发而导致被中断的操作
当对全局资源存在写操作时,如果不能保证写入过程的原子性,会出现脏读脏写的情况,即线程不安全。Python的GIL只能保证原子操作的线程安全,因此在多线程编程时我们需要通过加锁来保证线程安全。上面我们用互斥锁实现了线程安全, 在Python中有些数据类型本身就是线程安全的, 比如queue.Queue和collections.deque。
使用Queue编写一个生产者-消费者模型:
from threading import Thread, Condition
import time
import random
from queue import Queue
queue = Queue(10)
class ProducerThread(Thread):
def run(self):
nums = range(5)
global queue
while True:
num = random.choice(nums)
queue.put(num)
print("Produce: {}".format(num))
time.sleep(random.random())
class ConsumerThread(Thread):
def run(self):
global queue
while True:
num = queue.get()
queue.task_done()
print("Consume: {}".format(num))
time.sleep(random.random())
ProducerThread().start()
ConsumerThread().start()
Timer类
指定n秒后执行操作
from threading import Timer
def hello():
print("hello, world")
t = Timer(10, hello)
t.start() # after 10 seconds, "hello, world" will be printed
GIL 全局解释器锁
GIL的来源
由于物理上得限制,各CPU厂商在核心频率上的比赛已经被多核所取代。为了更有效的利用多核处理器的性能,就出现了多线程的编程方式,而随之带来的就是线程间数据一致性和状态同步的困难。即使在CPU内部的Cache也不例外,为了有效解决多份缓存之间的数据同步时各厂商花费了不少心思,也不可避免的带来了一定的性能损失。
Python当然也逃不开,为了利用多核,Python开始支持多线程。而解决多线程之间数据完整性和状态同步的最简单方法自然就是加锁。 于是有了GIL这把超级大锁,而当越来越多的代码库开发者接受了这种设定后,他们开始大量依赖这种特性(即默认python内部对象是thread-safe的,无需在实现时考虑额外的内存锁和同步操作)。
GIL的缺陷
就像python解释器中一把大锁,能够保证线程对数据的大部分常规修改操作(类原子操作:也就是不可分割,如append,pop)的安全,python全局解释器锁有一个特点,执行15毫秒后的操作系统cpu轮转机制(也就是定期释放锁),也就是说某一个线程在获得GIL锁后被执行15ms,会自动释放GIL锁,GIL被释放后该线程又会进入就绪列队,等待运行,这个时候其他线程可以获取GIL锁,从而获取CPU资源执行任务,下一次下回来的时候继续从第一个线程之前离开的位置继续执行,这种模式保证了多线程之间的同时被执行,不会导致一段时间了只有一个线程被执行知道执行完,这明显不合理。
来看一下单线程和多线程的执行效率对比, 我们用两个单线程进行1亿的计数, 和用两个多线程并发计数, 看一下执行效率:
from threading import Thread
import time
def my_counter():
i = 0
for _ in range(100000000):
i = i + 1
return True
def main():
start_time = time.time()
for tid in range(2):
t = Thread(target=my_counter)
t.start()
t.join()
end_time = time.time()
print("Total time: {}".format(end_time - start_time))
if __name__ == '__main__':
main()
运行结果: Total time: 9.658979654312134
from threading import Thread
import time
def my_counter():
i = 0
for _ in range(100000000):
i = i + 1
return True
def main():
thread_array = {}
start_time = time.time()
for tid in range(2):
t = Thread(target=my_counter)
t.start()
thread_array[tid] = t
for i in range(2):
thread_array[tid].join()
end_time = time.time()
print("Total time: {}".format(end_time - start_time))
if __name__ == '__main__':
main()
运行结果:Total time: 11.66282033920288
由于GIL锁的存在, 多线程的并发效率比单线程还要差一些, 但是Python3.6比Python2.7的并发效率要好一些。
所以Python一般用multiprocess多进程来代替多线程。
参考
- https://www.cnblogs.com/ryxiong-blog/p/10730085.html
- https://www.liaoxuefeng.com/wiki/1016959663602400/1017629247922688
- https://www.cnblogs.com/SuKiWX/p/8804974.html
- https://www.cnblogs.com/ArsenalfanInECNU/p/10022740.html















 1492
1492











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









