






在学习过程中尝试使用parsel库去解析网页,但是在用Selector的css选择器定位元素取值的时候出现了问题,返回的空列表。。请教大神帮忙看下怎么解决?
贴码:
import requests
import parsel
# 目标网站地址
url = 'https://dydytt.net/html/gndy/china/index.html'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36 Edg/126.0.0.0'
}
response = requests.get(url=url, headers=headers)
response.encoding = 'gb2312'
get_html = response.text
# print(get_html)
# 解析网页,通过css选择器
selector = parsel.Selector(get_html)
lis = selector.css('.tbspan')
# 通过遍历 把需要的内容提取出来
info_list = []
for li in lis:
# info = li.css('a.ulink').getall()[1]
# title = li.css('a.ulink::text').getall()[1]
link = li.css('a.ulink::attr(href)').getall()[1]
movie_url = 'https://dydytt.net' + link
info_list.append(movie_url)
for child_li in info_list:
# 请求子页面,获取子页面内容
child_response = requests.get(url=movie_url, headers=headers)
child_response.encoding = 'gb2312'
get_child_html = child_response.text
child_selector = parsel.Selector(get_child_html)
# print(child_selector)
# 到这一步还能返回内容
child_lis = child_selector.css('td::text').getall()
#但是到这儿返回的就是空列表了
为什么是td?
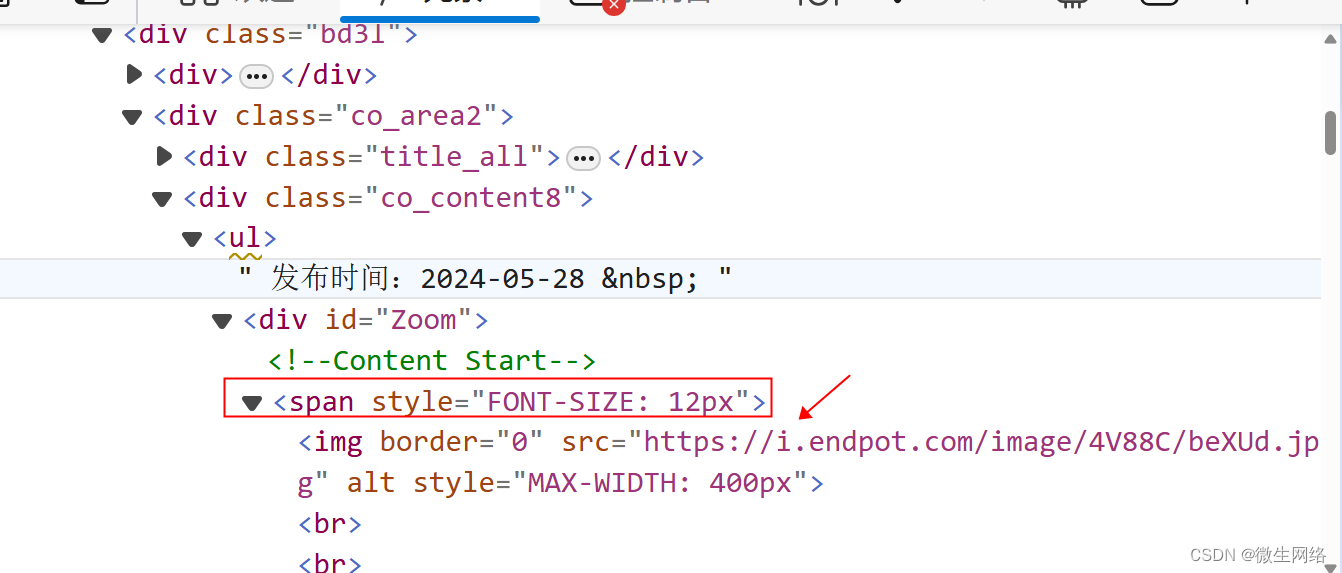
通过F12 看到 文本内容是在span标签里面的
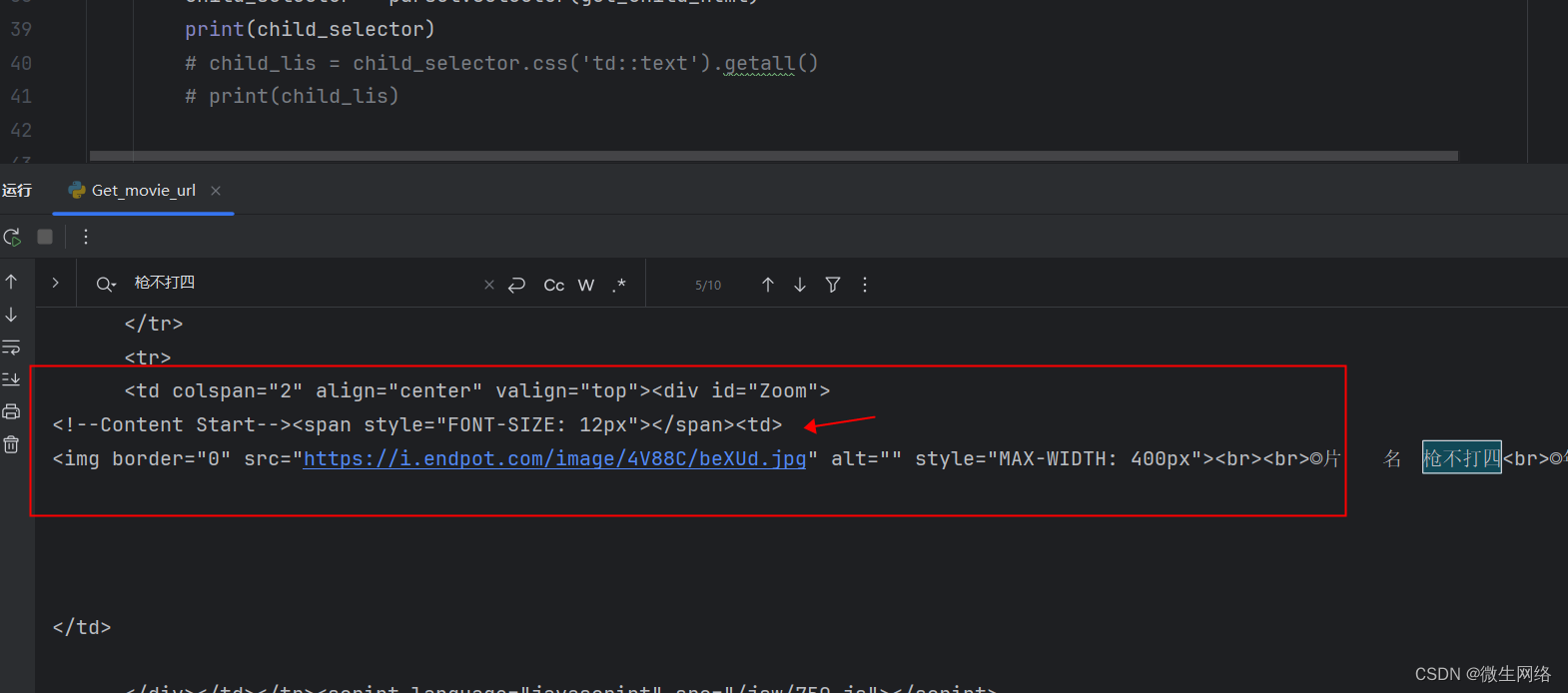
但是通过打印child_selector 返回的内容上看,span标签后面还有一个td标签
但是无论是通过span还是td 都无法取到我想要的值!!!
希望有大神看见 指教指教















 104
104

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









