







1.树——非线性数据结构
树在计算机科学的各个领域中被广泛应用:操作系统、图像学、数据库系统、计算机网络
跟自然界中的树一样,数据结构也分为:根、枝和叶等三个部分。一般数据结构的图示把根放在上方,叶放在下方。
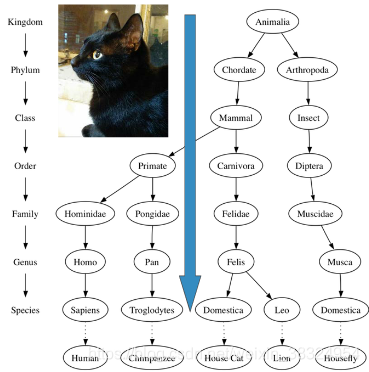
2.分类树的特征
(1)分类体系是层次化的。树是一种分层结构,越接近顶部的层越普遍,越接近底部的层越独特。
(2)一个节点的子节点与另一个节点的子节点相互之间是隔离、独立的
猫属Felis和蝇属Musca下面都有Domestica的同名节点,但相互之间并无任何关联,可以修改其中一个Domestica而不影响另一个。
(3)每一个叶节点都具有唯一性
可以用从根开始到达每个种的完全路径来唯一标识每个物种,例如:动物界—>脊索门—>哺乳纲—>食肉目—>猫科—>猫属—>家猫种
3.树的例子
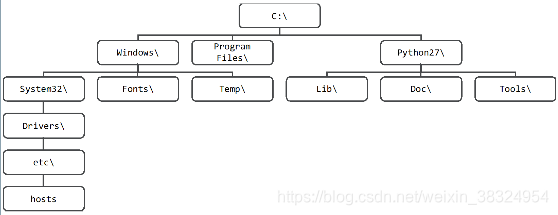
(1)文件系统
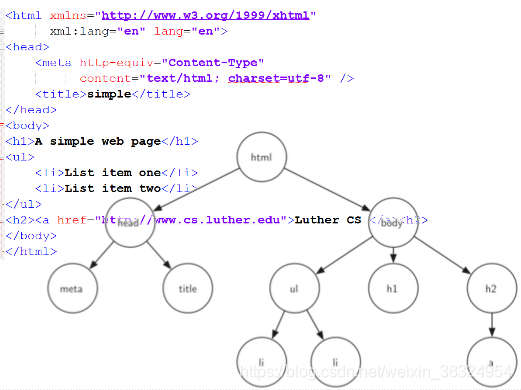
(2)HTML文档(嵌套标记)
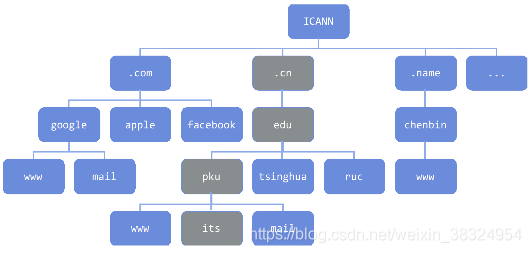
(3)域名体系
4.树结构相关术语
- 节点(Node):组成树的基本部分。每个节点具有名称,或“键值”,节点还可以保存额外数据项,数据项根据不同的应用而变。
- 边(Edge):边是组成树的另一个基本部分。每条边恰好连接两个节点,表示节点之间具有关联,边具有出入方向;每个节点(除根节点)恰有一条来自另一节点的入边;每个节点可以有多条连到其它节点的出边。
- **根(Root):**树种唯一一个没有入边的节点。
- **路径(Path):**由边依次连接在一起的节点的有序列表。如HTML—>BODY—>UL—>LI,是一条路径。
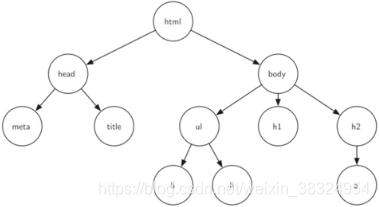
- 子节点(Children):入边均来自于同一个节点的若干节点,称为这个节点的子节点。
- 父节点(Parent):一个节点是其所有出边所连接节点的父节点。
- 兄弟节点(Sibling):具有同一个父节点的节点之间称为兄弟节点。
- 子树(Subtree):一个节点和其所有子孙节点以及相关边的集合。
- 叶节点(Leaf):没有子节点的节点称为叶节点。
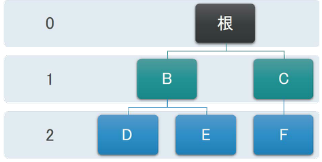
- 层级(Level):从根节点开始到达一个节点的路径,所包含的边的数量称为这个节点的层级。如D的层级为2,根节点的层级为0。
- 高度:树中所有节点的最大层级称为树的高度。
如下图树的高度为2
5.树的定义
5.1 树的定义1
树由若干节点以及两两连接节点的边组成,并有如下性质:
- 其中一个节点被设定为根;
- 每个节点n(除根节点),都恰连接一条来自节点p的边,p是n的父节点;
- 每个节点从根开始的路径是唯一的。如果每个节点最多有两个子节点,这样的树称为“二叉树”
5.2 树的定义2(递归定义)
树是空集,或者由根节点及0或多个子树构成(其中子树也是树),每个子树的根到根节点具有边相连。
6.实现树:嵌套列表法
利用Python List实现二叉树数据结构
递归的嵌套列表实现二叉树,由具有三个元素的列表实现:[root,left,right]
第1个元素为根节点的值;
第2个元素是左子树(所以也是一个列表);
第3个元素是右子树(所以也是一个列表)。
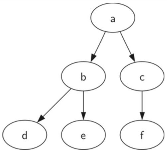
以下图为例,一个6节点的二叉树根是myTree[0],左子树myTree[1],右子树myTree[2]
myTree=[‘a’,#树根[‘b’,#左子树[‘d’,[ ],[ ]],[‘e’,[ ],[ ]]],[‘c’,#右子树[‘f’,[ ],[ ]],[ ]]]
嵌套列表法的优点:子树的结构与树相同,是一种递归数据结构,很容易扩展到多叉树,仅需要增加列表元素即可
我们通过定义一系列函数来辅助操作嵌套列表
- BinaryTree创建仅有根节点的二叉树
- insertLeft/insertRight将新节点插入树中作为其直接的左/右子节点
- get/setRootVal取得或返回根节点
- getLeft/RightChild返回左/右子树
#创建仅有节点的二叉树
def BinaryTree(r):
return [r,[],[]]
def insertLeft(root,newBranch):
t=root.pop(1)
if len(t)>1:
root.insert(1,[newBranch,t,[]])
else:
root.insert(1,[newBranch,[],[]])
return root
def insertRight(root,newBranch):
t=root.pop(2)
if len(t)>1:
root.insert(2,[newBranch,[],t])
else:
root.insert(2,[newBranch,[],[]])
return root
#返回根节点
def getRootVal(root):
return root[0]
#设置根节点
def setRootVal(root,newVal):
root[0]=newVal
#返回左子树
def getLeftChild(root):
return root[1]
#返回右子树
def getRightChild(root):
return root[2]
#举例
r=BinaryTree(3)#根节点的值为3
insertLeft(r,4)
insertLeft(r,5)
insertRight(r,6)
insertRight(r,7)
l=getLeftChild(r)#返回左子树
print(l)
setRootVal(l,9)#根节点设置为9
print(r)
insertLeft(l,11)
print(r)
print(getRightChild(getRightChild(r)))
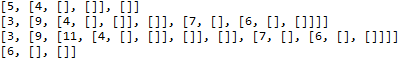
7.实现树:节点链表法
同样可以用节点链接法来实现树,每个节点保存根节点的数据项,以及指向左右子树的链接。
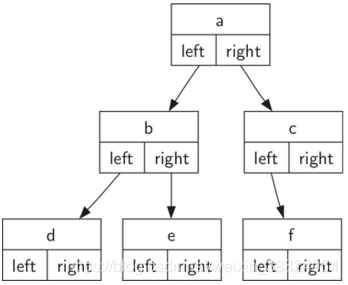
定义一个BinaryTree类
成员key保存根节点数据项,成员left/rightChild则保存向左/右子树的引用(同样是BinaryTree对象)
#节点链表法实现树
class BinaryTree:
def __init__(self,rootObj):
self.key=rootObj
self.leftChild=None
self.rightChild=None
def insertLeft(self,newNode):
if self.leftChild==None:
self.leftChild=BinaryTree(newNode)
else:
t=BinaryTree(newNode)
t.leftChild=self.leftChild
self.leftChild=t
def insertRight(self,newNode):
if self.rightChild==None:
self.rightChild=BinaryTree(newNode)
else:
t=BinaryTree(newNode)
t.rightChild=self.rightChild
self.rightChild=t
#返回根节点
def getRootVal(self):
return self.key
#设置根节点
def setRootVal(self,obj):
self.key=obj
#返回左子树
def getLeftChild(self):
return self.leftChild
#返回右子树
def getRightChild(self):
return self.rightChild
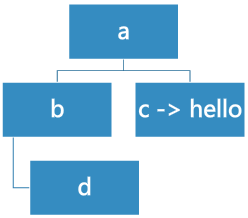
r=BinaryTree('a')
r.insertLeft('b')
r.insertRight('c')
r.getRightChild().setRootVal('hello')
r.getLeftChild().insertRight('d')
代码得到的树结构如下图所示:
8.树的应用
8.1解析树(语法树)
将树用于表示语言中句子,可以分析句子的各种语法成分,对句子的各种成分进行处理。
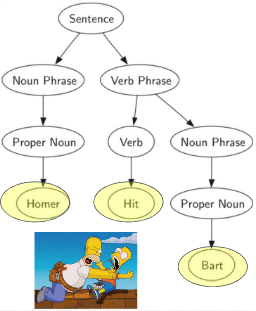
- 语法分析树:主谓宾,定状补
- 程序设计语言的编译:语法、语法检查;从语法树生成目标代码
- 自然语言处理:机器翻译、语义理解
8.2 表达式解析
我们可以将表达式表示为树结构,叶节点保存操作数,内部节点保存操作符。
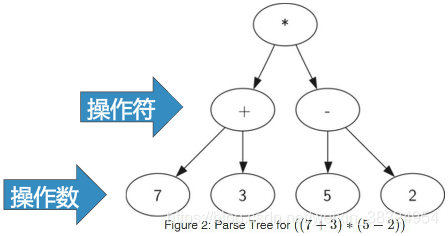
全括号表达式((7+3)*(5-2))
由于括号的存在,需要计算*的话,就必须先计算7+3和5-2,表达式层次决定计算的优先级,越底层的表达式优先级越高。
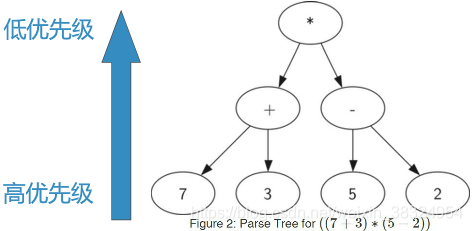
树中每个子树都表示一个子表达式。将子树替换为子表达式值的节点即可实现求值。
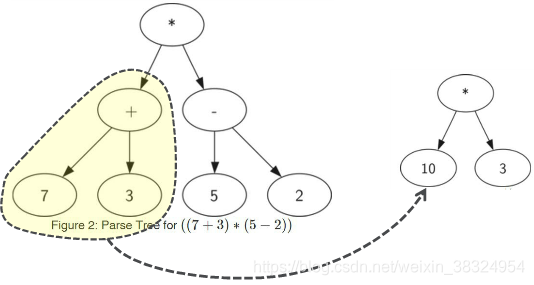
8.2.1从全括号表达式构建表达式解析树
(1)全括号表达式要分解为单词(Token)列表
其单词分为括号“()”、操作符“±/”和操作数“0~9”这几类。左括号就是表达式的开始,而右括号是表达式的结束。

(2)创建表达式解析树过程
创建空树,当前节点为根节点
读入‘(’,创建左子节点,当前节点下降
读入‘3’,当前节点设置为3,上升到父节点
读入‘+’,当前节点设置为+,创建右子节点,当前节点下降
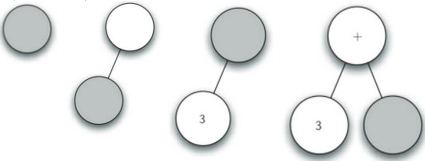
读入‘(’,创建左子节点,当前节点下降
读入‘4’,当前节点设置为4,上升到父节点
读入‘’,当前节点设置为*,创建右子节点,当前节点下降
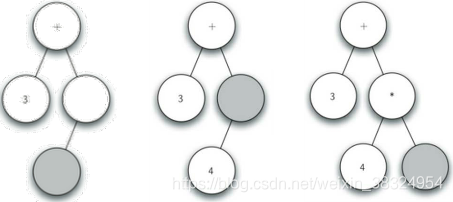
读入‘5’,当前节点设置为5,上升到父节点
读入‘)’,上升到父节点
读入‘)’,再上升到父节点
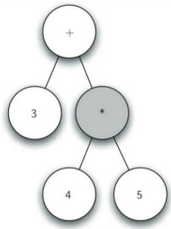
建立表达式解析树的规则:
从左到右扫描全括号表达式的每个单词,依据规则建立解析树
如果当前单词是‘(’:为当前节点添加一个新节点作为其左子节点,当前节点下降为这个新节点。
如果当前单词是操作符‘+,-,*,/’:当前节点设置为次符号,为当前节点添加一个新节点作为其右子节点,当前节点下降为这个新节点。
如果当前单词是操作数:将当前节点的值设为此数,当前节点提升到父节点。
建立表达式解析树的思路:
从图示过程中我们看到,创建树过程中关键的是对当前节点的跟踪。
创建左右子树可调用insertLeft/Right
当前节点设置值可以调用setRootVal
下降到左右子树可调用getLeft/RightChild
用栈来记录跟踪父节点。当前节点下降时,将下降前的节点push入栈;当前节点需要上升到父节点时,上升到pop出栈的节点即可。
python代码实现
#栈
class Stack:
def __init__(self):
self.items=[]#产生一个空栈
def isEmpty(self):
return self.items ==[]#判断栈是否为空
def push(self,item):
self.items.append(item)#将数据项加入栈顶
def pop(self):
return self.items.pop()#将栈顶数据移除
def peek(self):
return self.items[len(self.items)-1]#返回栈顶的数据项
def size(self):
return len(self.items)#返回栈的大小
#节点链表法实现树
class BinaryTree:
def __init__(self,rootObj):
self.key=rootObj
self.leftChild=None
self.rightChild=None
def insertLeft(self,newNode):
if self.leftChild==None:
self.leftChild=BinaryTree(newNode)
else:
t=BinaryTree(newNode)
t.leftChild=self.leftChild
self.leftChild=t
def insertRight(self,newNode):
if self.rightChild==None:
self.rightChild=BinaryTree(newNode)
else:
t=BinaryTree(newNode)
t.rightChild=self.rightChild
self.rightChild=t
#返回根节点
def getRootVal(self):
return self.key
#设置根节点
def setRootVal(self,obj):
self.key=obj
#返回左子树
def getLeftChild(self):
return self.leftChild
#返回右子树
def getRightChild(self):
return self.rightChild
#建立表达式解析树
def buildParseTree(fpexp):
fplist=fpexp.split()#将表达式分成一个个token
pStack=Stack()#创建一个空栈
eTree=BinaryTree('')#创建一个空树
pStack.push(eTree)#入栈下降
currentTree=eTree
for i in fplist:
#表达式开始
if i=='(':
currentTree.insertLeft('')
pStack.push(currentTree)#入栈下降
currentTree=currentTree.getLeftChild()
elif i not in ['+','-','*','/',')']:#操作数
currentTree.setRootVal(int(i))
parent=pStack.pop()#出栈上升
currentTree=parent
elif i in ['+','-','*','/',')']:#操作符
currentTree.setRootVal(i)
currentTree.insertRight('')
pStack.push(currentTree)#入栈下降
currentTree=currentTree.getRightChild()
elif i==')':#表达式结束
currentTree=pStack.pop()#出栈上升
else:
raise ValueError
return eTree
8.2.2利用表达式解析树对表达式求值
**思路:**由于二叉树是一个递归数据结构,自然可以用递归算法来处理。
求值递归函数evalute:由前述对于子表达式的描述,可以从树的底层子树开始,逐步向上层求值,最终得到整个表达式的值。
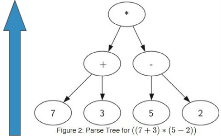
求值函数evalute的递归三要素:
- 基本结束条件:叶节点是最简单的子树,没有左右子节点,其根节点的数据项即为子表达式树的值
- 缩小规模:将表达式树分为左子树、右子树即为缩小规模
- 调用自身:分别调用evalute计算左子树和右子树的值,然后将左右子树的值依根节点的操作符进行计算,从而得到表达式的值。
一个增加程序可读性的技巧:函数引用
import operator
op=operator.add
n=op(1,2)
print(n)
import operator
def evalute(parseTree):
opers={'+':operator.add,'-':operator.sub,'*':operator.mul,'/':operator.truediv}#用字典定义操作
#减小规模
leftC=parseTree.getLeftChild()#左子树
rightC=parseTree.getRightChild()#右子树
if leftC and rightC:
fn=opers[parseTree.getRootVal()]
return fn(evalute(leftC),evalute(rightC))#递归调用
else:
return parseTree.getRootVal()#基本结束条件
9.树的遍历(Tree Traversals)
对一个数据集中的所有数据项进行访问的操作称为“遍历”
线性结构中,对其所有数据项的访问比较简单直接,按照顺序依次进行即可。树的非线性特点,使得遍历操作较为复杂。
按照对节点访问次序的不同来区分三种遍历
前序遍历(preorder):先访问根节点,再递归地前序访问左子树、最后前序访问右子树;
中序遍历(inorder):先递归地中序访问左子树,再访问根节点,最后中序访问右子树;
后序遍历(postorder):先递归地后续访问左子树,再后续访问右子树,最后访问根节点。
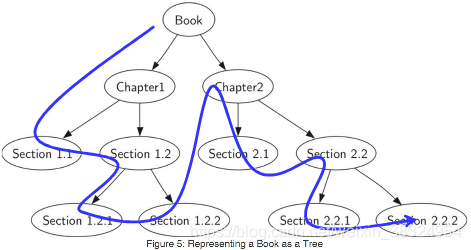
前序遍历的例子:一本书的章节阅读,阅读顺序如蓝色线所示。
Book—>ch1—>s1.1—>s1.2—>s1.2.1—>s1.2.2—>ch2—>s2.1—>s2.2.1—>s2.2.2
树的遍历:递归算法代码实现
#前序遍历
def preporder(tree):
if tree:
#先访问根节点
print(tree.getRootVal())
#前序遍历左子树
preporder(tree.getLeftChild())
#前序遍历右子树
preporder(tree.getrightChild())
#中序遍历
def inorder(tree):
if tree!=None:
inorder(tree.getLeftChild())
print(tree.getRootVal())
inorder(tree.getRightChild())
#后序遍历
def postorder(tree):
if tree!=None:
postorder(tree.getLeftChild())
postorder(tree.getRightChild())
print(tree.getRootVal())
也可以在BinaryTree类中实现前序遍历的方法:需要加入子树是否为空的判断
class BinaryTree:
def __init__(self,rootObj):
self.key=rootObj
self.leftChild=None
self.rightChild=None
#前序遍历
def preorder(self):
print(self.key)
if self.leftChild:
self.leftChild.preorder()
if self.rightChild:
self.rightChild.preorder()
采用后序遍历法重写表达式求值代码
#利用后序遍历法重写表达式的求值代码
def postordereval(tree):
opers={'+':operator.add,'-':operator.sub,'*':operator.mul,'/':operator.truediv}#用字典定义操作
res1=None
res2=None
if tree:
res1=postordereval(tree.getLeftChild())#左子树
res2=postordereval(tree.getRightChild())#右子树
if res1 and res2:
return opers[tree.getRootVal()](res1,res2)#根节点
else:
return tree.getRootVal()














 1457
1457











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









