









TFLite系列的前几篇文章中,我们介绍了TFLite和创建模型的过程。在这篇文章中,我们将更深入地研究模型优化。我们将探索TensorFlow模型优化工具包(TF MOT)支持的不同模型优化技术。最后对优化后的模型进行了详细的性能比较。

这是TensorFlow Lite系列的第三篇文章,前两篇文章如下:
1. TensorFlow模型优化工具包
TensorFlow Model Optimization Toolkit是一套用于优化ML模型的工具,用于部署和执行。在许多用途中,该工具包支持的技术有如下使用:
- 降低云和边缘设备(如移动、物联网)的延迟和t推理成本。
- 将模型部署到对处理、内存、功耗、网络使用和模型存储空间有限制的边缘设备。
- 支持对现有的硬件或加速器运行和优化。
2. Fine-tuning Base Model
我们将要讨论的所有优化技术都需要对模型进行训练。为了对优化模型的性能进行benchmark the performance ,我们将微调我们在前一篇博客文章中训练的base model。
3.代码的解释
用以下命令安装TensorFlow模型优化工具包,可以使用Google Colab或jupyter notebook来执行代码。请使用下载的代码中的requirements.txt文件来设置本地环境。
# For google colab.!pip install -q tensorflow-model-optimization
# For a local environment.
!pip install -r requirements.txt
在jupyter notebook 环境中,执行按照不需要加!
3.1导入库
# Importing necessary libraries and packages.
import os
import numpy as np
import tensorflow as tf
from tensorflow import keras
import tensorflow_datasets as tfds
from tensorflow.keras.models import Model
import tensorflow_model_optimization as tfmot
from tensorflow.keras.layers import Dropout, Dense, BatchNormalization
%load_ext tensorboard
3.2 加载数据集
数据集可以直接从TensorFlow dataset (tfds)加载。我们正在导入猫对狗的数据集。数据集以0.7:0.2:0.1的分割比例分为Training、Validation和Testing集。as_supervised参数设置为True,因为我们需要图像的标签进行分类。
# Loading the cat vs dog dataset.
(train_ds, val_ds, test_ds), info = tfds.load('cats_vs_dogs', split=['train[:70%]', 'train[70%:90%]', 'train[90%:]'], shuffle_files=True, as_supervised=True, with_info=True)
看看tfds.info()中提供的数据集信息。数据集有两个类,分别标记为“猫”和“狗”,包含16283、4653、2326张训练、验证和测试图像。
# Printing dataset information.
print("Number of Classes: " + str(info.features['label'].num_classes))
print("Classes : " + str(info.features['label'].names))
NUM_TRAIN_IMAGES = tf.data.experimental.cardinality(train_ds).numpy()
print("Training Images: " + str(NUM_TRAIN_IMAGES))
NUM_VAL_IMAGES = tf.data.experimental.cardinality(val_ds).numpy()
print("Validation Images: " + str(NUM_VAL_IMAGES))
NUM_TEST_IMAGES = tf.data.experimental.cardinality(test_ds).numpy()
print("Testing Images: " + str(NUM_TEST_IMAGES))
3.3 Resize数据集
我们以16作为批大小,224×224作为图像大小,以便能够有效地处理数据集。
# Defining batch size and input image size.
batch_size = 16
img_size = [224, 224]
# Resizing images in the dataset.
train_ds = train_ds.map(lambda x, y: (tf.image.resize(x, img_size), y))
val_ds = val_ds.map(lambda x, y: (tf.image.resize(x, img_size), y))
test_ds = test_ds.map(lambda x, y: (tf.image.resize(x, img_size), y))
让我们确保使用buffered prefetching从磁盘生成数据。Prefetching 与数据预处理、训练步骤同时执行。这样做可以减少训练的步骤时间和提取数据所需的时间。
train_ds = train_ds.cache().batch(batch_size).prefetch(buffer_size=10)
val_ds = val_ds.cache().batch(batch_size).prefetch(buffer_size=10)
test_ds = test_ds.cache().batch(batch_size).prefetch(buffer_size=10)
3.4 导入Keras模型
在,我们将导入keras模型,然后编译它,以查看最终模型的summary。我们使用初始学习率为0.0001的Adam Optimizer,以sparse categorical cross-entropy 作为损失函数,准确性作为度量标准。
# Importing the keras model.
model = tf.keras.models.load_model('/content/drive/MyDrive/TFLiteBlog/models/model.h5')
# Compiling the model.
model.compile( optimizer=tf.keras.optimizers.Adam(0.0001), loss =tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False), metrics = ["accuracy"])
model.summary()
输出
====================================================================
Total params: 4,740,453
Trainable params: 4,697,406
Non-trainable params: 43,047
____________________________________________________________________
我们将使用Model Saving Callback和Reduce LR Callback ,类似于之前的博客文章。
Model Saving Callback以最佳的验证精度保存模型。Reduce LR Callback如果validation loss 连续3个epoch保持相同,则Reduce LR Callback将学习率调整为原来的0.1倍。
# Defining file path.
filepath = '/content/model.h5'
# Defining Model Save Callback and Reduce Learning Rate Callback for achieving better results.
model_save = tf.keras.callbacks.ModelCheckpoint(
filepath,
monitor="val_accuracy",
verbose=0,
save_best_only=True,
save_weights_only=False,
mode="max",
save_freq="epoch")
reduce_lr = tf.keras.callbacks.ReduceLROnPlateau(monitor='loss', factor=0.1, patience=3, verbose=1, min_delta = 5*1e-3,min_lr = 5*1e-9,)
callback = [model_save, reduce_lr]
3.5 训练模型
现在,我们将使用model.fit()方法训练模型。我们将通过训练数据集和验证数据集,对模型进行2个epoch的训练。
# Training the model for 2 epochs.
model.fit(train_ds, epochs=2, steps_per_epoch = (len(train_ds)//batch_size), validation_data=val_ds, validation_steps = (len(val_ds)//batch_size), shuffle = False, callbacks=callback)
让我们检查模型在测试集中的性能。
# Evaluating the model on the test dataset.
_, baseline_model_accuracy = model.evaluate(test_ds, verbose=0)
print(Baseline Keras Model Test Accuracy:', baseline_model_accuracy*100)
输出:
Baseline Keras Model Test Accuracy : 98.49 %
3.6 剪枝
模型的剪枝包括去除模型中对其预测影响最小的参数。在权值剪枝中,消除了权张量中不必要的值。将神经网络某些参数值设为零,以消除神经网络各层之间不必要的连接。这是在训练过程中完成的,以使神经网络适应变化。有效的剪枝可以显著减小模型的尺寸。它不会影响运行时延迟。
这里,我们将只修剪最后的全连接层。我们将克隆基本模型,并对其最终的全连接层进行修剪。
# Dense layers train with pruning.
def apply_pruning_to_dense(layer):
if isinstance(layer, tf.keras.layers.Dense):
return tfmot.sparsity.keras.prune_low_magnitude(layer)
return layer
# Using `tf.keras.models.clone_model` to apply `apply_pruning_to_dense` to the layers of the model.
model_for_pruning = tf.keras.models.clone_model(model, clone_function = apply_pruning_to_dense)
Model Summary.
# Printing model summary.
model_for_pruning.summary()
输出
=====================================================================
Total params: 5,428,715
Trainable params: 4,697,406
Non-trainable params: 731,309
我们可以观察到这里的模型参数有所增加。这是因为tfmot为网络中的每个权值添加了不可训练的掩码,以表示是否应该对给定的权值进行修剪。掩码不是0就是1。
现在,让我们编译具有与基本模型相同的损失函数和指标的模型。
# Compiling model for pruning.
model_for_pruning.compile(
optimizer=tf.keras.optimizers.Adam(0.0001),
loss =tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False), metrics = ["accuracy"])
在这里 tfmot.sparsity.keras.UpdatePruningStep是在训练过程中需要的,因为它用优化器逐步更新修剪包装器,而tfmot.sparsity.keras. PruningSummaries 提供了跟踪进度和调试的日志。
# Defining the Callbacks and assigning the log directory.
logdir = 'content/logs'
callbacks = [
tfmot.sparsity.keras.UpdatePruningStep(),
tfmot.sparsity.keras.PruningSummaries(log_dir=logdir),
]
现在,我们将在训练数据集上对该模型进行两个epoch的微调。
# Fine tuning the model.
model_for_pruning.fit(train_ds, batch_size=batch_size, epochs=2, validation_data=val_ds, callbacks=callbacks)
让我们来评估这个修剪后的模型。
# Evaluating pruned Keras model on the test dataset._, model_for_pruning_accuracy = model_for_pruning.evaluate(test_ds, verbose=0)
print('Baseline Keras Model Test Accuracy:', baseline_model_accuracy*100)
print('Pruned Keras Model Test Accuracy:', model_for_pruning_accuracy*100)
输出
Baseline Keras Model Test Accuracy: 98.49 %
Pruned Keras Model Test Accuracy: 99.14 %
logs曲线显示了每一层的稀疏程度。
# Tensorboard logs.
%tensorboard --logdir={logdir}
该模型被导出并保存为Keras的.h5格式。strip_pruning()是必要的,因为它会删除tf.Variablen仅在训练时进行修剪,否则在推断时将增加模型大小。进一步,修剪使大部分权值为零,增加了冗余,标准压缩算法可以利用它进一步压缩模型。
# Exporting pruned Keras model
model_for_export = tfmot.sparsity.keras.strip_pruning(model_for_pruning)
tf.keras.models.save_model(model_for_export, '/content/pruned_keras_model.h5', include_optimizer=False)
现在让我们打印导出模型的模型summary。在这里,我们可以看到导出的修剪后的Keras模型参数与基线模型相同。这是因为返回的权重指标的大小与基本模型相同,但大多数权重为零。
输出:
pruned_keras_model.summary()
=====================================================================
Total params: 4,740,453
Trainable params: 4,697,406
Non-trainable params: 43,047
_____________________________________________________________________
3.7 权重聚类

聚类的工作原理是将模型中每一层的权值分组到一个预定义数量的簇中,然后共享属于每个单独簇的权值的质心值。这减少了模型中唯一权重值的数量,从而降低了模型的复杂性。因此,可以更有效地压缩集群模型,提供类似于修剪的部署好处。为了对模型权重进行聚类,在将模型传递给聚类API之前,需要首先对其进行充分的训练。由于我们已经训练了我们的基线模型,现在我们可以继续对模型进行聚类。
让我们使用TFMOT定义聚类权值和质心初始化。
# Defining clustered weights using TFMOT.
cluster_weights = tfmot.clustering.keras.cluster_weights
CentroidInitialization =tfmot.clustering.keras.CentroidInitialization
number_of_clusters参数是在对一层或一个模型聚类时要形成的簇质心的数量。这里,我们将number_of_clusters设置为16。这将确保每个权值张量不超过16个惟一值。cluster_centroids_init参数决定如何初始化集群质心。
- 在
RANDOM初始化质心: 在给定的层使用均匀分布,在最小和最大权重值之间进行采样。 - 在
DENSITY_BASED初始化中,将进行基于密度的采样。 - 在
LINEAR初始化聚类中,质心均匀地间隔在给定权重的最小值和最大值之间。
# Setting clustering parameters.
clustering_params = { 'number_of_clusters': 16, 'cluster_centroids_init': CentroidInitialization.LINEAR}
# Cluster a whole model.
clustered_model = cluster_weights(model, **clustering_params)
编译权重聚类模型
# Compiling clustered model.
clustered_model.compile(optimizer=tf.keras.optimizers.Adam(0.0001), loss =tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False), metrics = ["accuracy"])
打印clustered model 的summary。
输出:
=====================================================================
Total params: 9,203,973
Trainable params: 4,698,494
Non-trainable params: 4,505,479
这里我们还可以注意到模型参数几乎翻倍。原因与修剪的情况类似。为了对模型进行微调,TF MOT向每个权重添加掩码,从而使参数数量增加了一倍
现在我们将fine-tune权值聚类的模型。我们将对模型进行两个epoch的fine-tune。
# Fine-tune model.
clustered_model.fit(train_ds, batch_size= batch_size, epochs=2, validation_data = val_ds)
让我们在测试机中评估权值聚类模型。
# Evaluating the Fine-tuned clustered model.
_, clustered_model_accuracy = clustered_model.evaluate(test_ds, verbose=0)
print('Baseline Keras Model Test Accuracy:', baseline_model_accuracy*100)
print('Pruned Keras Model Test Accuracy:', model_for_pruning_accuracy*100)
print('Clustered Keras Model Test Accuracy:', clustered_model_accuracy*100)
输出
Baseline Keras Model Test Accuracy: 97.76 %
Pruned Keras Model Test Accuracy: 99.35 %
Clustered Keras Model Test Accuracy: 70.16 %
导出权值聚类后的模型并保存为Keras的.h5格式。在这里,我们将使用strip_clustering()来删除在训练期间添加的掩码,并返回与基本模型相似大小的权重特征。
# Saving the clustered model.
final_model = tfmot.clustering.keras.strip_clustering(clustered_model)
clustered_keras_file = '/content/weight_clustered_keras_model.h5'
tf.keras.models.save_model(final_model, clustered_keras_file, include_optimizer=False)
现在,打印已保存的权重聚类后的模型的模型摘summary,以检查模型中参数的数量。这里我们可以看到strip_clustering 后,聚类模型的参数与基模型的参数相同。
# Printing clustered model summary.
clustered_model.summary()
=====================================================================
Total params: 4,740,453
Trainable params: 4,697,406
Non-trainable params: 43,047
_____________________________________________________________________
3.8 量化感知训练
当我们从float转移到较低的精度时,我们通常会注意到一个显著的精度下降,因为这是一个有损的过程。这种损失最小化可以通过量化感知训练来达到。量化感知训练在向前传播时模拟低精度行为,而向后传播保持不变。这就导致了一些量化误差累积在模型的总损失中,因此优化器试图通过相应的参数调整来减少它。这使得我们的参数对量化更稳健,使我们的过程几乎无损。
这是我们也只量化最后的全连接层
# Only the dense layers are quantized.
def apply_quantization_to_dense(layer):
if isinstance(layer, tf.keras.layers.Dense):
return tfmot.quantization.keras.quantize_annotate_layer(layer)
return layer
# Cloning base model and applying quantization on dense layers.
annotated_model = tf.keras.models.clone_model(
model,
clone_function=apply_quantization_to_dense,
)
quant_aware_model = tfmot.quantization.keras.quantize_apply(annotated_model)
quant_aware_model.summary()
输出
=====================================================================
Total params: 4,740,470
Trainable params: 4,697,406
Non-trainable params: 43,064
这里,不可训练参数的数量增加了。这是因为TF MOT给layers添加了一些掩码来指定它们是否应该量化。让我们编译这个模型。
# Compiling the quant aware model.quant_aware_model.compile(
optimizer=tf.keras.optimizers.Adam(0.0001), loss =tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False), metrics = ["accuracy"]
)
现在我们将对模型进行fine-tune
# Fine-tuning quantization aware trained model.
quant_aware_model.fit(train_ds, batch_size=batch_size, epochs=2, validation_data=val_ds)
让我们在测试集中评估这个新训练的模型。
# Evaluating quantization aware trained model on test dataset.
_, quant_aware_model_accuracy = quant_aware_model.evaluate(test_ds, verbose=0)
print('Baseline Keras Model Test Accuracy:', baseline_model_accuracy*100)
print('Pruned Keras Model Test Accuracy:', model_for_pruning_accuracy*100)
print('Clustered Keras Model Test Accuracy:', clustered_model_accuracy*100)
print('Quantization Aware Trained Model Test accuracy:', quant_aware_model_accuracy*100)
输出:
Baseline Keras Model Test Accuracy: 98.49%
Pruned Keras Model Test Accuracy: 99.14%
Clustered Keras Model Test Accuracy: 70.16%
Quantization Aware Trained Model Test accuracy: 99.35%
让我们将这个模型保存为Keras格式
# Saving quantization aware trained Keras model.
quant_aware_model.save('/content/quant_aware_keras_model.h5')
进一步,为了加载量化感知训练过的Keras模型,它需要反序列化。quantize_scope()反序列化要加载的Keras模型。现在,让我们加载量化感知训练过的Keras模型,并查看其模型summary。
quant_aware_model.summary()
=====================================================================
Total params: 4,740,470
Trainable params: 4,697,406
Non-trainable params: 43,064
_____________________________________________________________________
我们可以看到,在对Keras模型进行反序列化之后,参数的数量与基线模型相同。
4. 优化模型的比较
4.1 Test Accuracy
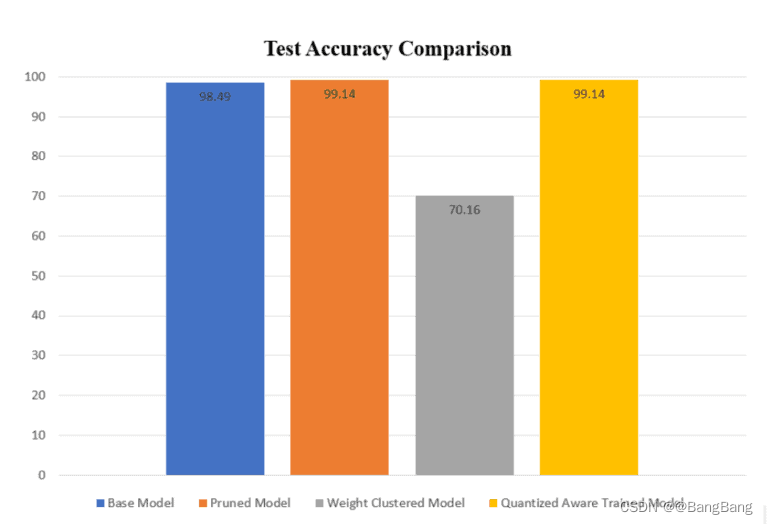
剪枝模型和量化的感知训练模型具有相似的测试精度,在测试集上的性能优于基础模型。权重聚类模型的检验精度明显低于基线模型。
4.2 模型的大小
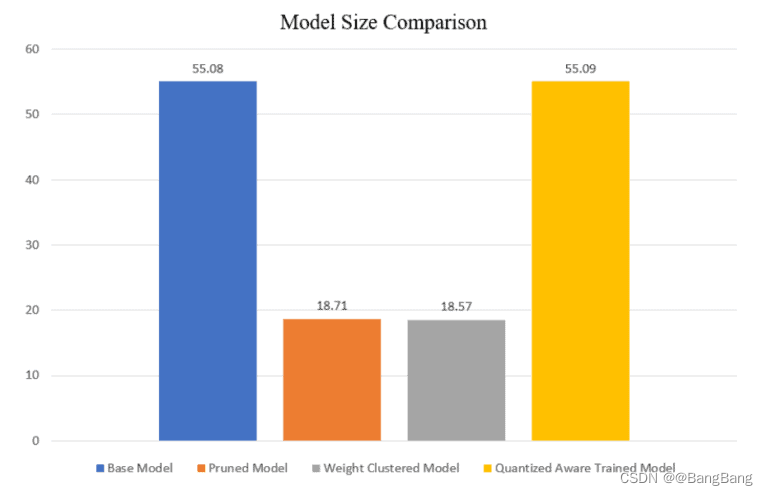
我们可以看到,在修剪和权重聚类模型中,模型大小减少了3倍。量化的感知模型的大小与基线模型相似



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











