







 本文介绍了人体行为识别和视频分类的概念,探讨了基于传感器数据的传统方法和使用计算机视觉的视频分类方法。视频分类的基本策略包括对单帧进行分类并使用移动平均来消除波动。文章还列举了多种视频分类算法,如单帧CNN、后期融合、早期融合、CNN与LSTM结合等。同时,提出了视频分类中面临的行为识别问题,如简单行为识别、时间行为识别和时空域检测。最后,文章提出使用Keras创建视频分类系统,包括数据预处理、模型构建和训练等步骤。
本文介绍了人体行为识别和视频分类的概念,探讨了基于传感器数据的传统方法和使用计算机视觉的视频分类方法。视频分类的基本策略包括对单帧进行分类并使用移动平均来消除波动。文章还列举了多种视频分类算法,如单帧CNN、后期融合、早期融合、CNN与LSTM结合等。同时,提出了视频分类中面临的行为识别问题,如简单行为识别、时间行为识别和时空域检测。最后,文章提出使用Keras创建视频分类系统,包括数据预处理、模型构建和训练等步骤。

在这篇文章中,我们将介绍一些方法来制作用于人体行为识别的视频分类器。
1人体行为识别介绍
在我们讨论视频分类之前,让我们先了解一下什么是人体行为识别。
简单地说,对某人正在执行的活动/动作进行分类或预测的任务称为活动识别。我们可能会有一个问题:这与普通的分类任务有什么不同?这里的问题是,在人体行为识别中,你实际上需要一系列的数据来预测正确执行的动作。
看看这个人做的这个后空翻动作,我们只有看完整的视频才能判断这是一个后空翻。
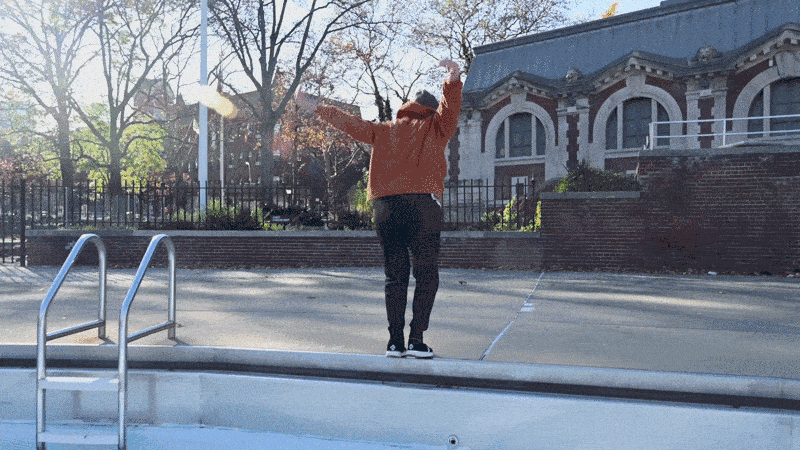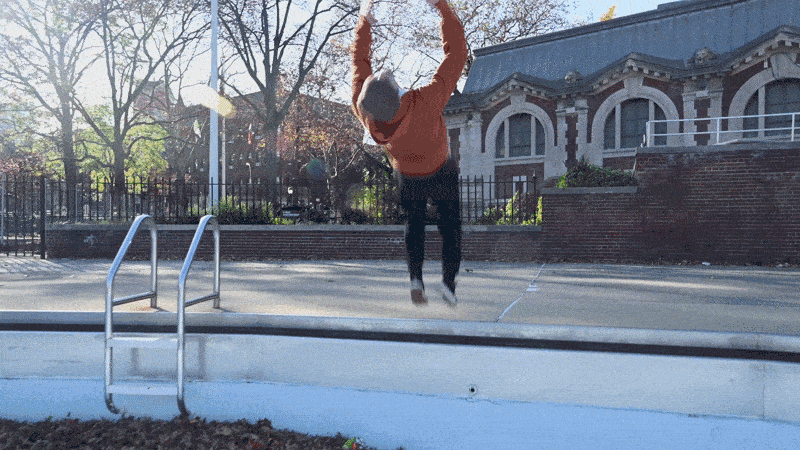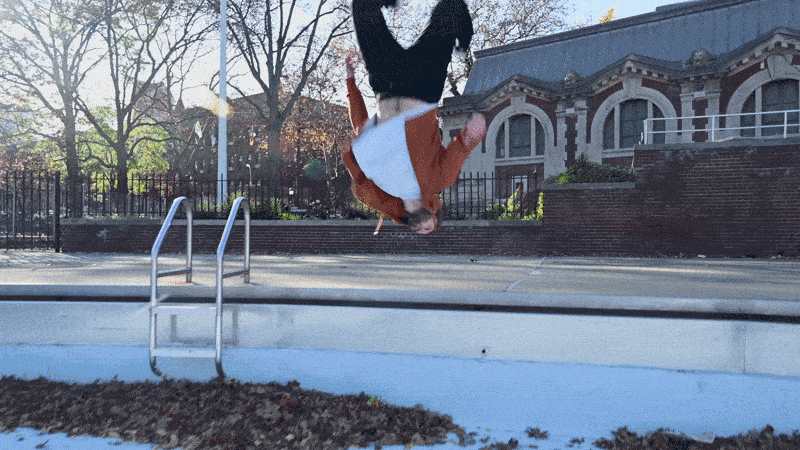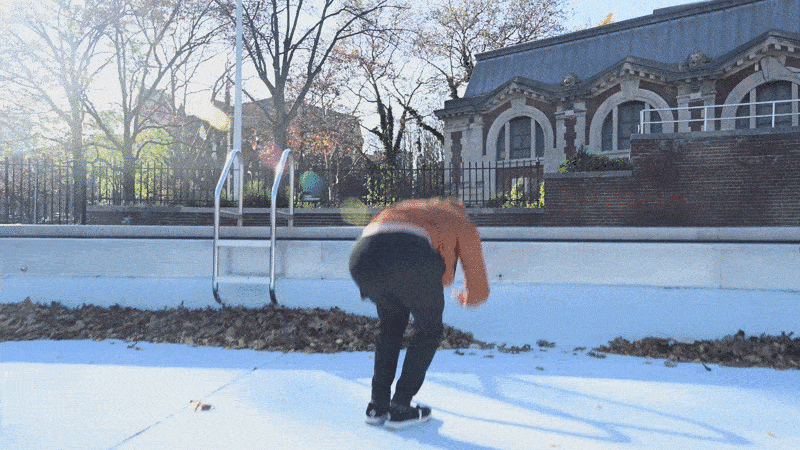
如果我们提供的模型只是来自视频片段的随机快照(如下图),那么它可能会错误地预测动作。

如果一个模型只看到上面的图像,那么它看起来有点像这个人正在下降,所以它预测会下降。
因此,人体行为是一种时间序列分类问题,您需要来自一系列时间序列的数据来正确地对正在执行的行为进行分类。
那么行为识别传统上是如何解决的呢?
最常见和最有效的技术是将可穿戴传感器(例如智能手机)连接到一个人身上,然后在传感器数据的输出上训练一个类似LSTM的时间模型。
在这里,人在x y z方向的方向运动,他的角速度被加速度计和智能手机中的陀螺仪传感器记录下来。
然后根据这些传感器数据训练一个模型来输出这六个类。
- 走
- 走上楼
- 走下楼
- 坐着
- 站
- 躺
可以在这里下载数据集这种活动识别方法非常有效。这个视频实际上是名为“基于智能手机的行为识别”数据集的一部分。它是由意大利热那亚大学的Davide Anguita等人准备和提供的。详情可以在他们2013年的论文《基于智能手机的人体行为识别公开数据集》中找到。
但在本文中,我们不会根据传感器数据训练模型,原因有二::
- 在大多数实际场景中,您无法访问传感器数据。例如,如果你想检测一个地方的非法活动,那么你可能只能依靠闭路电视摄像头的视频馈送。
- 我最感兴趣的是用计算机视觉来解决这个问题,所以我们将使用视频分类的方法来实现活动识别。
2. 视频分类与人体行为识别介绍
既然我们已经建立了视频分类模型来解决人体行为识别问题,让我们来讨论视频分类最基本和最简单的方法。
- 这里有一个好消息,如果你有一些建立基本图像分类模型的经验,那么你已经可以创建一个视频分类系统。
- 考虑一下这个演示,我们正在使用一个正常的分类模型来预测视频的每一帧,结果令人惊讶地好。
这怎么可能?
但就在前面展示了后空翻的例子对于行为识别,不能依赖于单一的帧,那么为什么一个简单的分类模型表现得这么好呢?
事情是这样的:模型也在学习环境背景。考虑下面的例子。
通常情况下,以下两幅图像都将被图像分类器分类为跑步。

但是如果有足够的样本。

该模型学习通过使用环境上下文来区分两个相似的动作。

有了足够多的样本,这个模型就知道一个人在足球场上摆着跑步的姿势很可能是在踢足球,如果这个人在跑道上或公路上,那么他很可能是在跑步。
这种方法有一个缺点。
问题是,该模型并不总是对每个视频帧的预测完全有信心,因此预测会迅速变化和波动。
这是因为该模型并不是着眼于整个视频序列,而是对每一帧进行独立分类。
这个问题的一个简单的解决方案是,与其对单个帧的结果进行分类和显示,为什么不平均5帧、10帧或n帧的结果呢?这样可以有效地消除闪烁。
一旦我们确定了n的值,我们就可以使用简单的移动平均/滚动平均技术来实现这一目标。
假设:
- $n $=平均帧数
- P f P_f Pf=最终预测概率
- P P P =当前帧的预测概率
- P − 1 P_{-1} P−1 =最后一帧的预测概率
- P − 2 P_{-2} P−2 =倒数第二帧的预测概率
P − n
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











