




文章目录
-
- 1. 为什么需要做特征归一化、标准化?
- 2. 常用常用的归一化和标准化的方法有哪些?
- 3. 介绍一下空洞卷积的原理和作用
- 4. 怎么判断模型是否过拟合,有哪些防止过拟合的策略?
- 5. 除了SGD和Adam之外,你还知道哪些优化算法?
- 6. 阐述一下感受野的概念,并说一下在CNN中如何计算
- 7. 训练神经网络有哪些调参技巧
- 8. 神经网络的深度和宽度分别指的是什么?
- 9. 上采样的原理和常用方式
- 10. 下采样的作用是什么?通常有哪些方式?
- 11. 模型的参数量指的是什么?怎么计算
- 12. 模型的FLOPs(计算量)指的是什么?怎么计算?
- 13. 有哪些经典的卷积类型?
- 14. 深度可分离卷积的概念和作用
- 15. 神经网络中Addition / Concatenate区别是什么?
- 16. 激活函数是什么?你知道哪些常用的激活函数?
- 17. 神经网络中1×1卷积有什么作用?
- 18. 随机梯度下降相比全局梯度下降好处是什么?
- 19. 如果在网络初始化时给网络赋予0的权重,这个网络能正常训练嘛?
- 20. 为什么要对网络进行初始化,有哪些初始化的方法?
- 21. 增大感受野的方法?
- 22. 神经网络的正则化方法?过拟合的解决方法?
- 23. 梯度消失和梯度爆炸的原因是什么?
- 24. 深度学习为什么在计算机视觉领域这么好?
- 25. 为什么神经网络种常用relu作为激活函数?
- 26. 卷积层和全连接层的区别是什么?
- 27. 什么是正则化?L1正则化和L2正则化有什么区别?
- 28. 常见的损失函数有哪些?你用过哪些?
- 29. dropout为什么能解决过拟合?
- 30. 深度学习中的batch的大小对学习效果有何影响?
- 31. PyTorch和TensorFlow的特点分别是什么?
- 32. Pytorch 多卡并行的时候怎么实现参数共享,通信梯度是指平均梯度,还是最大梯度,还是梯度总和?
- 33. 数据不平衡的解决方法
- 34. ReLU函数在0处不可导,为什么还能用?
- 35. Pooling层的作用以及如何进行反向传播
- 36. 为什么max pooling 要更常用?什么场景下 average pooling 比 max pooling 更合适?
- 37. 为什么要反向传播?手推反向传播公式展示一下
- 38. CV中的卷积操作和数学上的严格定义的卷积的关系?
- 39. 简述CNN分类网络的演变脉络及各自的贡献与特点
- 40. 神经网络的优缺点?
- 41. Softmax+Cross Entropy如何反向求导?
- 42. 有什么数据增强的方式?
- 43. 为什么在模型训练开始会有warm up?
- 44. VGG使用3*3卷积核的优势是什么?
- 45. 什么是Group Convolution
- 46. 训练过程中,若一个模型不收敛,那么是否说明这个模型无效?导致模型不收敛的原因有哪些?
- 47. Relu比Sigmoid的效果好在哪里?
- 48. Batch Normalization的作用
- 49. GAN网络的思想
- 50. Attention机制的作用
- 51. 怎么提升网络的泛化能力
- 52. CNN为什么比DNN在图像识别上更好
- 53. DNN的梯度是如何更新的?
- 54. Depthwise 卷积实际速度与理论速度差距较大,解释原因。
- 31. 常用的模型压缩方式有哪些?
- 32. 如何处理样本不平衡?
- 33.什么是知识蒸馏?
- 56 阐述一下感受野的概念
- 57. 转置卷积的原理
- 58 深度可分离卷积的概念和作用
- 59 随机梯度下降相比全局梯度下降好处是什么?
1. 为什么需要做特征归一化、标准化?
使不同量纲的特征处于同一数值量级,减少方差大的特征的影响,使模型更准确。
加快学习算法的收敛速度。
2. 常用常用的归一化和标准化的方法有哪些?
线性归一化(min-max标准化)
x’ = (x-min(x)) / (max(x)-min(x)),其中max是样本数据的最大值,min是样本数据的最小值 适用于数值比较集中的情况,可使用经验值常量来来代替max,min标准差归一化(z-score 0均值标准化) x’=(x-μ) / σ,其中μ为所有样本的均值,σ为所有样本的标准差 经过处理后符合标准正态分布,即均值为0,标准差为1非线性归一化使用非线性函数log、指数、正切等,如y = 1-e^(-x),在x∈[0, 6]变化较明显, 用在数据分化比较大的场景
3. 介绍一下空洞卷积的原理和作用
-
空洞卷积(Atrous Convolution)也叫做膨胀卷积、扩张卷积,
最初的提出是为了解决图像分割在用下采样(池化、卷积)增加感受野时带来的特征图缩小,后再上采样回去时造成的精度上的损失。空洞卷积通过引入了一个扩张率的超参数,该参数定义了卷积核处理数据时各值的间距。 -
可以在增加感受野的同时保持特征图的尺寸不变,从而代替下采样和上采样,通过调整扩张率得到不同的感受野不大小:- a. 是普通的卷积过程(dilation rate = 1),卷积后的感受野为3
- b. 是dilation rate = 2的空洞卷积,卷积后的感受野为5
- c. 是dilation rate = 3的空洞卷积,卷积后的感受野为8
可以这么说,普通卷积是空洞卷积的一种特殊情况
「参考资料」: 吃透空洞卷积(Dilated Convolutions)、『计算机视觉』空洞卷积
4. 怎么判断模型是否过拟合,有哪些防止过拟合的策略?
在构建模型的过程中,通常会划分训练集、测试集。 当模型在训练集上精度很高,在测试集上精度很差时,模型过拟合;当模型在训练集和测试集上精度都很差时,模型欠拟合。
预防过拟合策略:
- 增加训练数据:获取更多数据,也可以使用图像增强、增样等;
- 使用合适的模型:适当减少网络的层数、降低网络参数量;
- Dropout:随机抑制网络中一部分神经元,使的每次训练都有一批神经元不参与模型训练;
- L1、L2正则化:训练时限制权值的大小,增加惩罚机制,使得网络更稀疏;
- 数据清洗:去除问题数据、错误标签和噪声数据;
- 限制网络训练时间:在训练时将训练集和验证集损失分别输出,当训练集损失持续下降,而验证集损失不再下降时,网络就开始出现过拟合现象,此时就可以停止训练了;
- 在网络中使用BN层(Batch Normalization)也可以一定程度上防止过拟合。
「参考资料」:N,LN,IN,GN都是什么?不同归一化方法的比较、深度学习中的五种归一化(BN、LN、IN、GN和SN)方法简介、层归一化,循环批归一化(2016)和批归一化RNN(2015)有什么区别?
5. 除了SGD和Adam之外,你还知道哪些优化算法?
主要有三大类:
- a. 基本梯度下降法,包括 GD,BGD,SGD;
- b. 动量优化法,包括 Momentum,NAG 等;
- c. 自适应学习率优化法,包括 Adam,AdaGrad,RMSProp 等。
「参考资料」: 从SGD到NadaMax,十种优化算法原理及实现
6. 阐述一下感受野的概念,并说一下在CNN中如何计算
- 感受野指的是卷积神经网络每一层输出的
特征图上每个像素点映射回输入图像上的区域的大小,神经元感受野的范围越大表示其接触到的原始图像范围就越大,也就意味着它能学习更为全局,语义层次更高的特征信息,相反,范围越小则表示其所包含的特征越趋向局部和细节。因此感受野的范围可以用来大致判断每一层的抽象层次,并且我们可以很明显地知道网络越深,神经元的感受野越大。 - 卷积层的感受野大小与其之前层的卷积核尺寸和步长有关,与padding无关。 计算CNN的感受野
7. 训练神经网络有哪些调参技巧
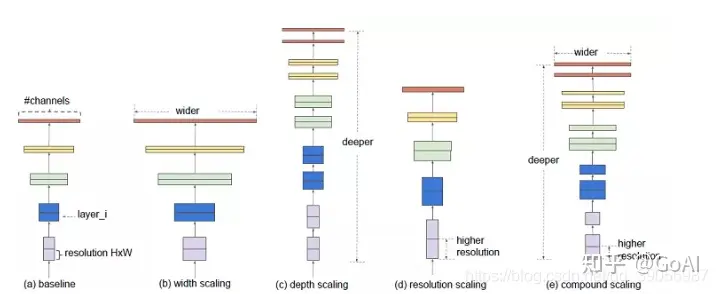
8. 神经网络的深度和宽度分别指的是什么?
神经网络的深度决定了网络的表达能力,早期的backbone设计都是直接堆叠卷积层,它的深度指的是神经网络的层数;后来的backbone设计采用了更高效的module(或block)堆叠的方式,每个module是由多个卷积层组成,这时深度指的是module的个数。
神经网络的宽度决定了网络在某一层学习到的信息量,指的是卷积神经网络中最大的通道数,由卷积核数量最多的层决定。通常的结构设计中卷积核的数量随着层数越来越多的,直到最后一层feature map达到最大,这是因为越到深层,feature map的分辨率越小,所包含的信息越高级,所以需要更多的卷积核来进行学习。通道越多效果越好,但带来的计算量也会大大增加,所以具体设定也是一个调参的过程,并且各层通道数会按照8×的倍数来确定,这样有利于GPU的并行计算。
9. 上采样的原理和常用方式
在卷积神经网络中,由于输入图像通过卷积神经网络(CNN)提取特征后,输出的尺寸往往会变小,而有时我们需要将图像恢复到原来的尺寸以便进行进一步的计算(如图像的语义分割),这个使图像由小分辨率映射到大分辨率的操作,叫做上采样,它的实现一般有三种方式:
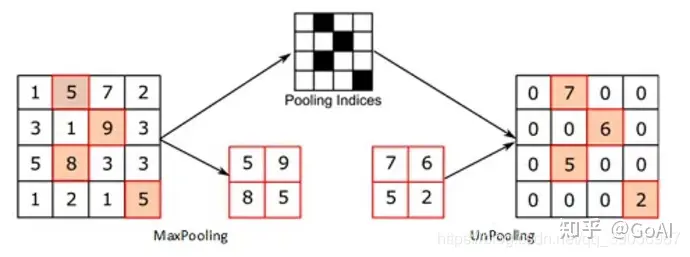
a. 插值,一般使用的是双线性插值,因为效果最好,虽然计算上比其他插值方式复杂,但是相对于卷积计算可以说不值一提,其他插值方式还有最近邻插值、三线性插值等;b. 转置卷积又或是说反卷积,通过对输入feature map间隔填充0,再进行标准的卷积计算,可以使得输出feature map的尺寸比输入更大;c. Max Unpooling,在对称的max pooling位置记录最大值的索引位置,然后在unpooling阶段时将对应的值放置到原先最大值位置,其余位置补0;
「参考资料」:深度卷积网络中如何进行上采样?、三种上采样方法 | Three up sampling methods、上采样(upsampling)
10. 下采样的作用是什么?通常有哪些方式?
下采样层有两个作用,一是减少计算量,防止过拟合;二是增大感受野,使得后面的卷积核能够学到更加全局的信息。
- 下采样的方式主要有两种:
- a. 采用stride为2的池化层,如Max-pooling和Average-pooling,目前通常使用Max-pooling,因为他计算简单而且能够更好的保留纹理特征;
- b. 采用stride为2的卷积层,下采样的过程是一个信息损失的过程,而池化层是不可学习的,用stride为2的可学习卷积层来代替pooling可以得到更好的效果,当然同时也增加了一定的计算量。
「参考资料」:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











