







0. 前导内容
ASCII,GBK和UTF-8各种编码区别 (htmonster.xyz)
1. 官网定义区别
Strings, bytes, runes and characters in Go - The Go Programming Language
1.1 byte 字节
字节大家肯定都熟悉。
字节是计算机的存储单位,1byte=8bits, 1byte 可以表示 2^8=256种情况。
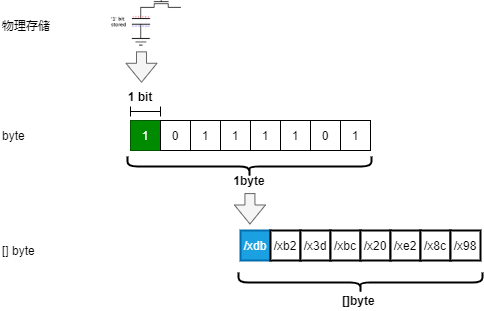
而[]byte 可以理解这样一个个byte组合起来的数组。
1.2 string 字符串
In Go, a string is in effect a **read-only **slice of bytes.
Go中的string是一个只读的字节切片。
It’s important to state right up front that a string holds arbitrary bytes. It is not required to hold Unicode text, UTF-8 text, or any other predefined format. As far as the content of a string is concerned, it is exactly equivalent to a slice of bytes.
string包含着任意字节,不需要预定义任何格式,内容上完全等价于一个字节的切片。
- string=[存储]=>任意长度[]byte
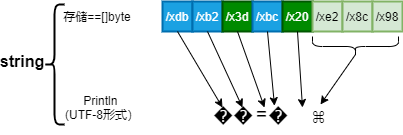
Because some of the bytes in our sample string are not valid ASCII, not even valid UTF-8, printing the string directly will produce ugly output. The simple print statement
由于string存储的字节不是UTF-8(ascill是UTF-8子集),所以直接通过指定byte形式存储的string打印会很奇怪
const sample = "\xbd\xb2\x3d\xbc\x20\xe2\x8c\x98" //通过 byte形式直接定义string
fmt.Println(sample) //��=� ⌘
In short, Go source code is UTF-8, so the source code for the string literal is UTF-8 text. If that string literal contains no escape sequences, which a raw string cannot, the constructed string will hold exactly the source text between the quotes. Thus by definition and by construction the raw string will always contain a valid UTF-8 representation of its contents. Similarly, unless it contains UTF-8-breaking escapes like those from the previous section, a regular string literal will also always contain valid UTF-8.
由于Go源码是以UTF-8形式存储的,所以没有特意地转义去定义一个字符串时,它是以UTF-8形式存储的。
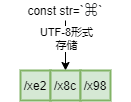
const placeOfInterest = `⌘`
fmt.Printf("plain string: ")
fmt.Printf("%s", placeOfInterest) //⌘
fmt.Printf("quoted string: ")
fmt.Printf("%+q", placeOfInterest) //\u2318
fmt.Printf("hex bytes: ")
for i := 0; i < len(placeOfInterest); i++ {
fmt.Printf("%x ", placeOfInterest[i])
}// e2 8c 98
1.3 rune 符文
“Code point” is a bit of a mouthful, so Go introduces a shorter term for the concept: rune. The term appears in the libraries and source code, and means exactly the same as “code point”, with one interesting addition.
rune其实是Code point的别称 ( Unicode是编码集,UTF-8是编码集合,码点是代码空间的值。
The Go language defines the word
runeas an alias for the typeint32, so programs can be clear when an integer value represents a code point. Moreover, what you might think of as a character constant is called a rune constant in Go. The type and value of the expression
rune其实就是int32的别名。
2. 总结

- byte,rune是存储上的概念
- byte=1字节,等价于
uint8 - rune=4字节,等价于
int32
- byte=1字节,等价于
- string实际上就是一个任意长度和只读的
[]byte- 一个字符串字面,如果没有字节级的转义,是以
UTF-8形式编码存储和表示。
- 一个字符串字面,如果没有字节级的转义,是以
三者之间转换
str := "test"
//string => []byte
b := []byte(str)
//[]byte => string
str = string(b)
//string => rune
r := []rune(str)
//rune => string
str = string(r)















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









