






1.JDK环境配置
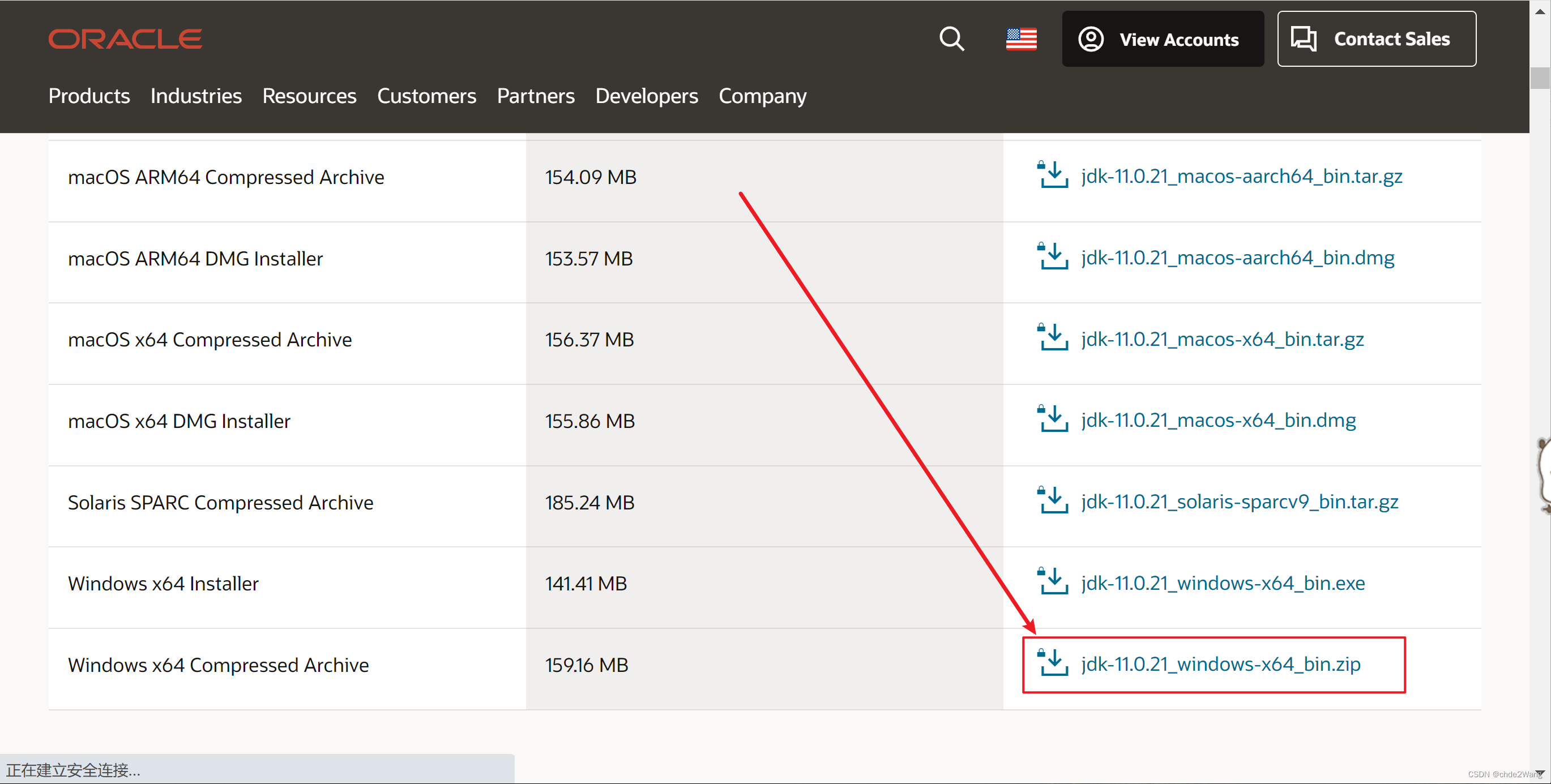
1.1下载jdk安装包https://www.oracle.com/java/technologies/javase/jdk11-archive-downloads.html
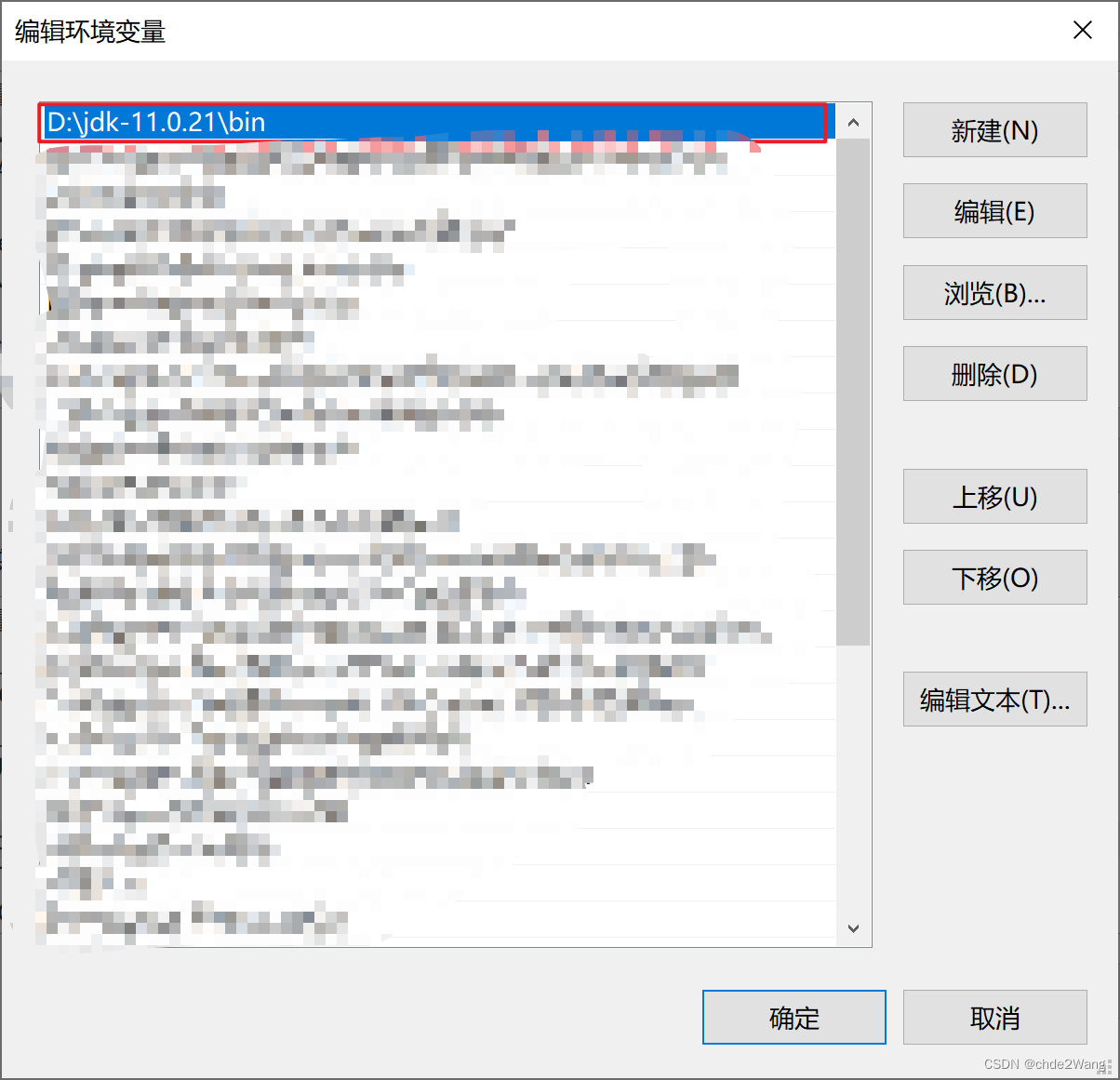
1.2配置环境变量,路径中不要有空格,否则hadoop可能会出错。
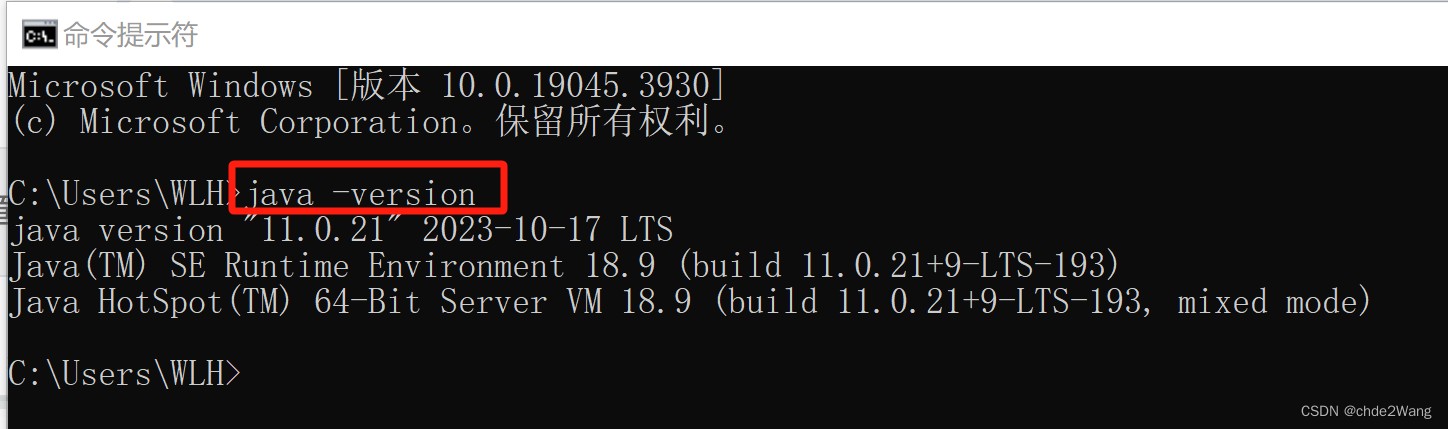
1.3配置成功测试
2.hadoop环境安装
2.1 hadoop安装包下载并解压
(1)镜像链接:https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/core/hadoop-3.3.2/
选择hadoop-3.3.2.tar.gz
(2)下载winutils.exe和hadoop.dll,Windows安装Hadoop需要这部分文件
链接:https://github.com/cdarlint/winutils
找到对应的版本对应bin目录中的文件,放入Hadoop下的bin 文件夹中
2.2 配置Hadoop环境变量
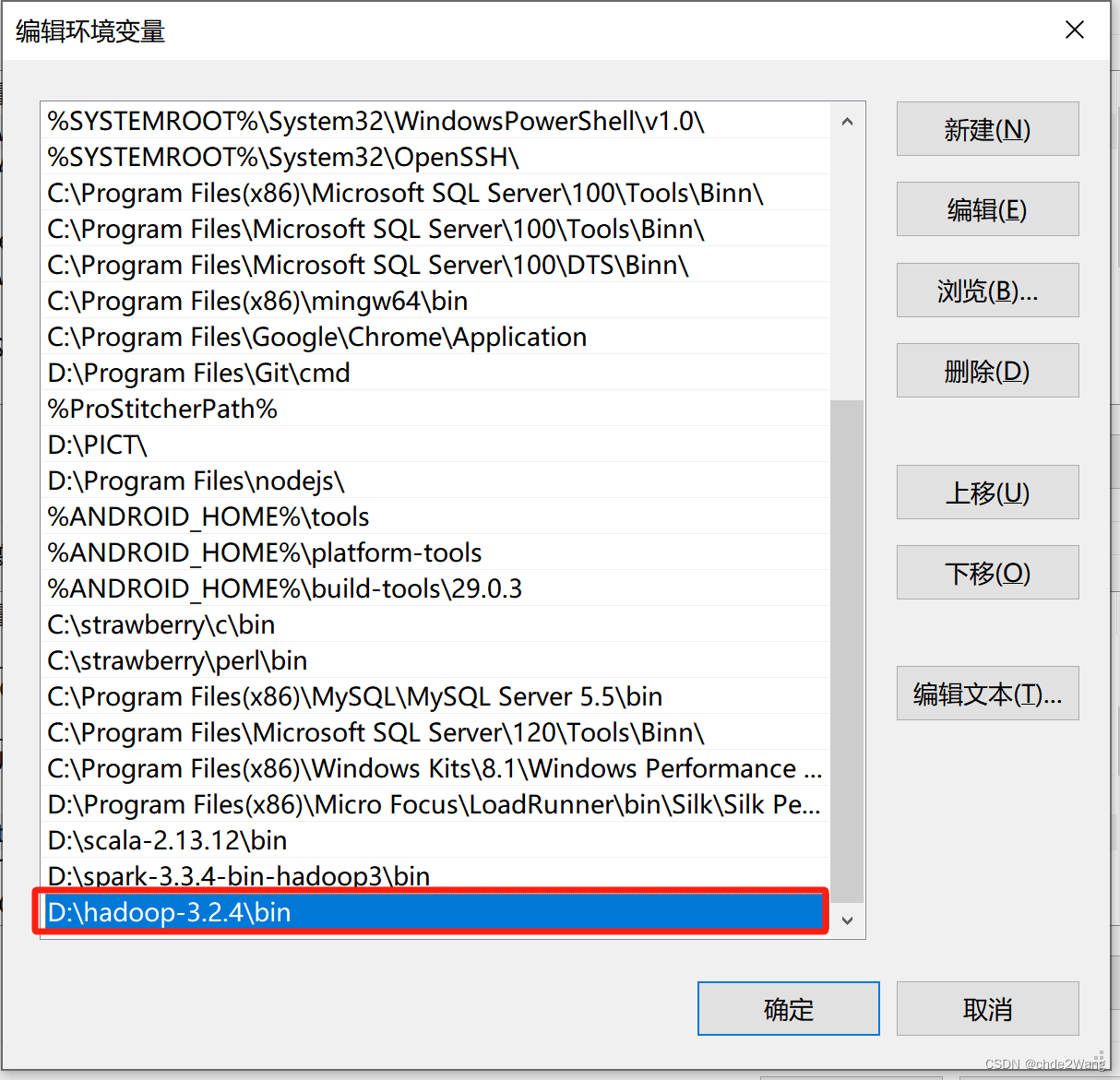
2.3配置Hadoop启动文档和脚本
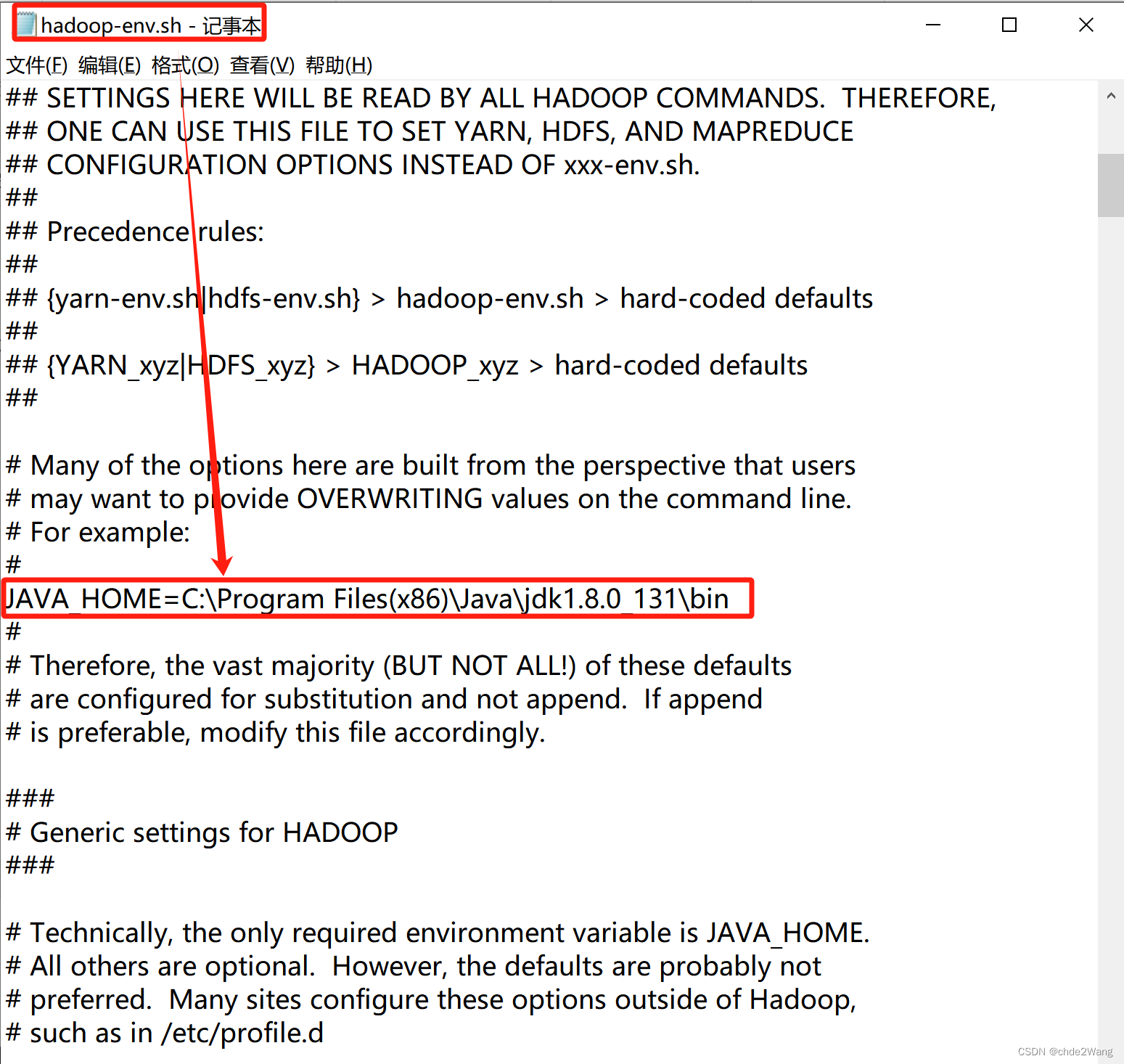
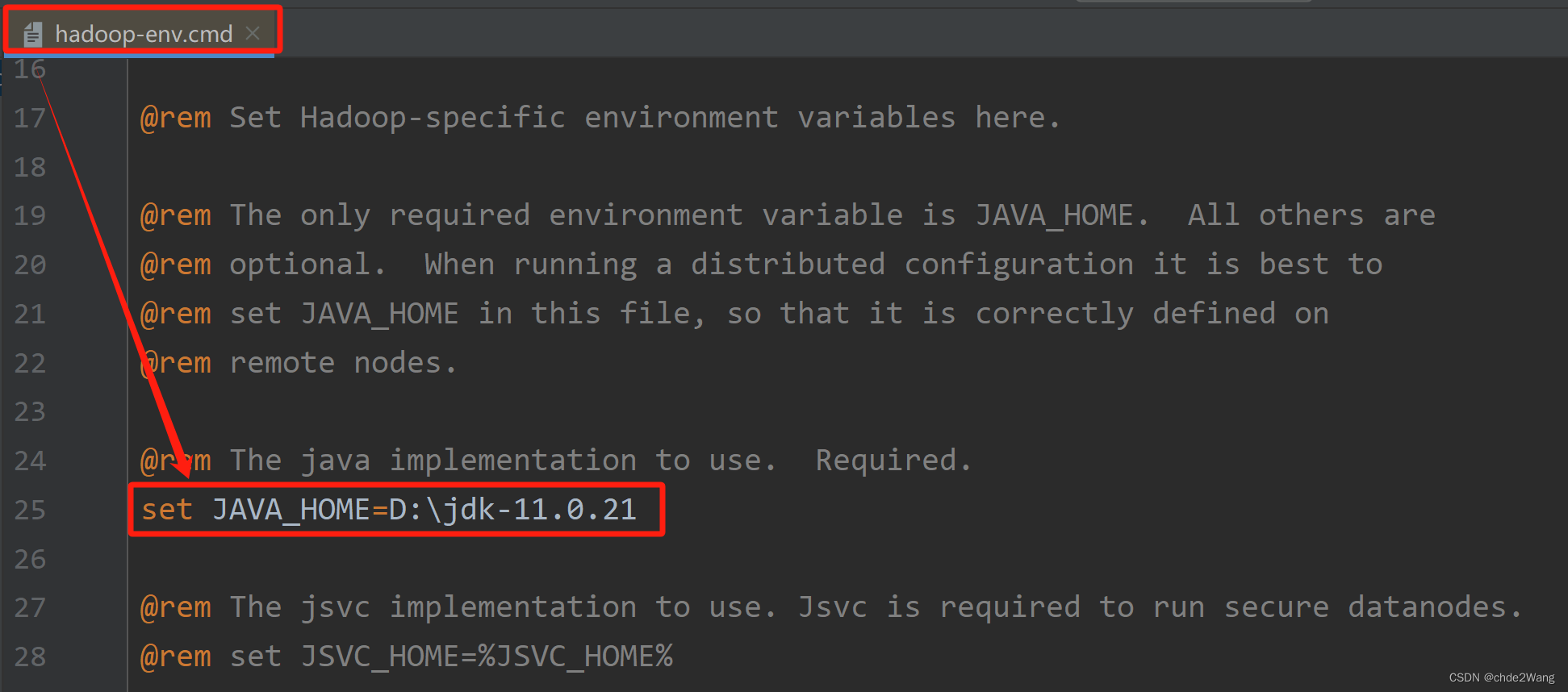
配置\etc\hadoop\下hadoop-env.sh,hadoop-env.cmd中的JAVA_HOME路径。
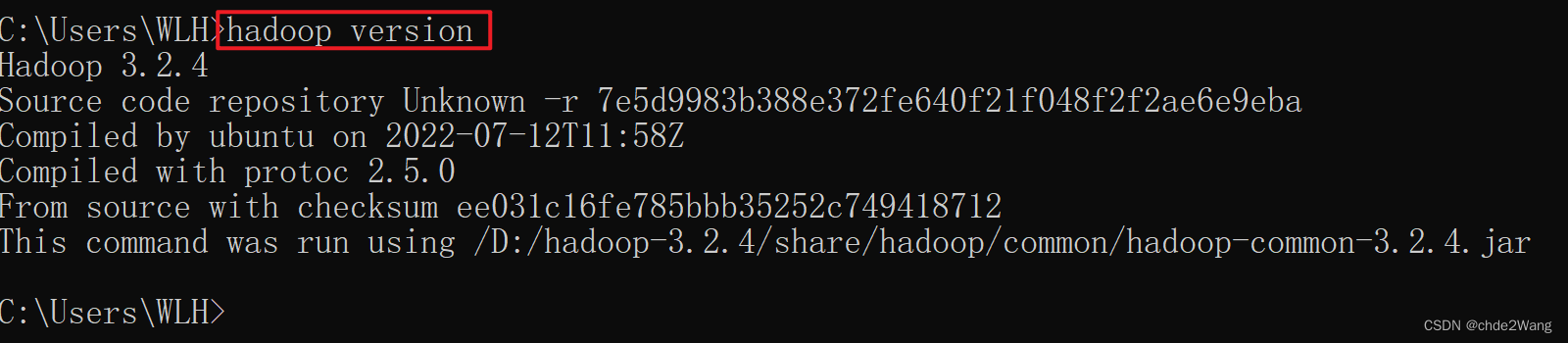
2.4配置成功测试
3 Spark配置
3.1 下载解压安装包
https://archive.apache.org/dist/spark/spark-2.1.2/
https://mirrors.tuna.tsinghua.edu.cn/apache/spark/spark-3.3.4/
3.2 配置环境变量
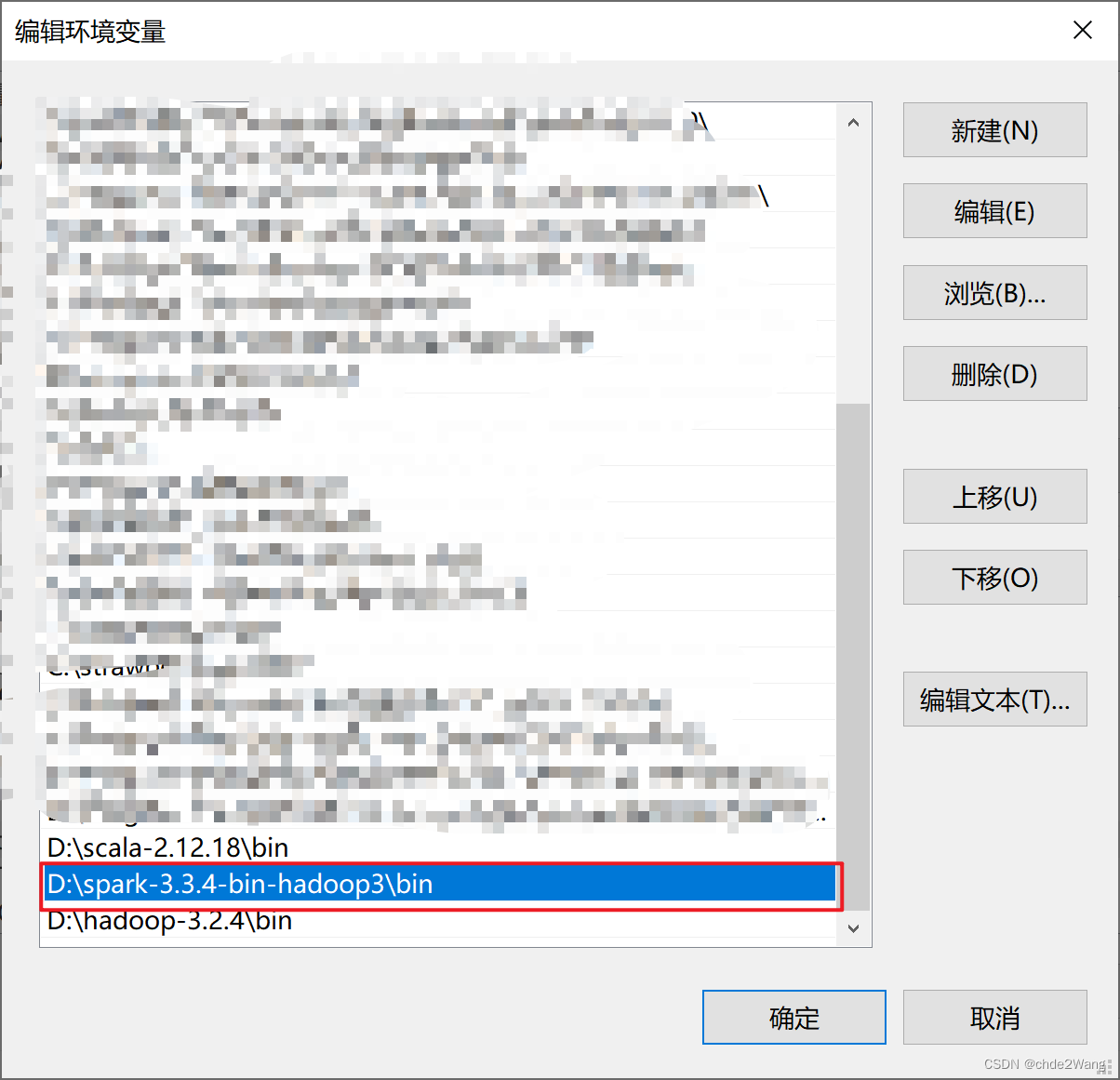
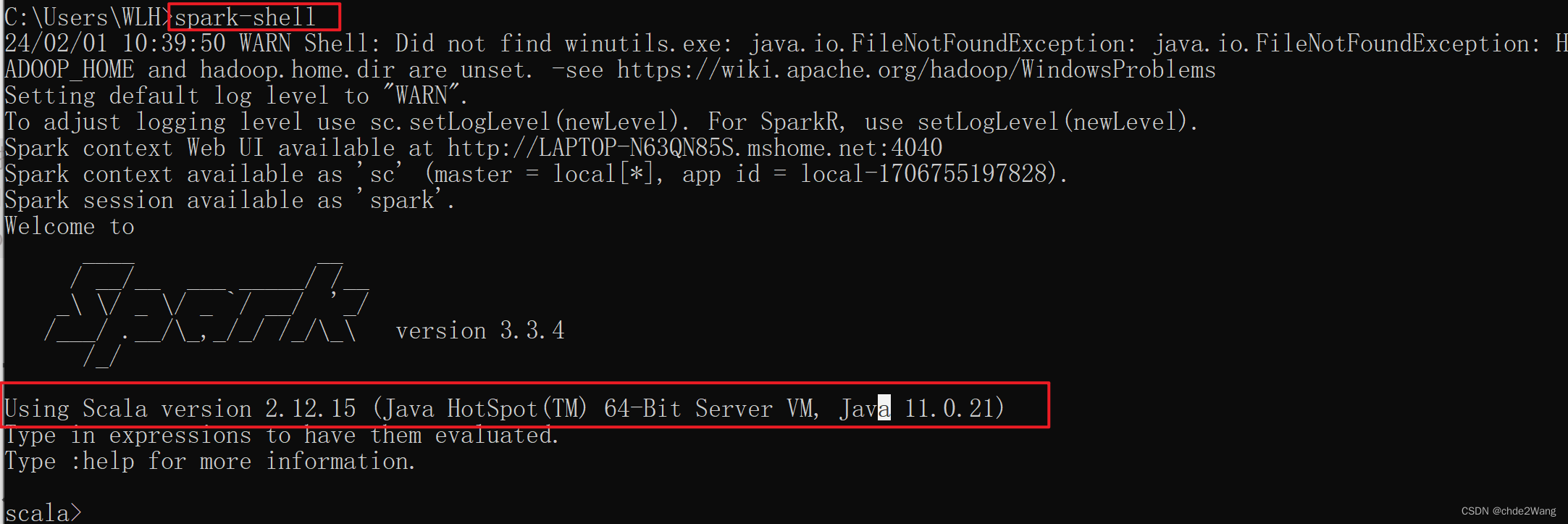
3.3 测试是否安装成功
4 Scala配置
4.1 下载scala版本(应于spark内置的scala版本一致)
下载scala安装包并解压
https://www.scala-lang.org/download/2.12.18.html
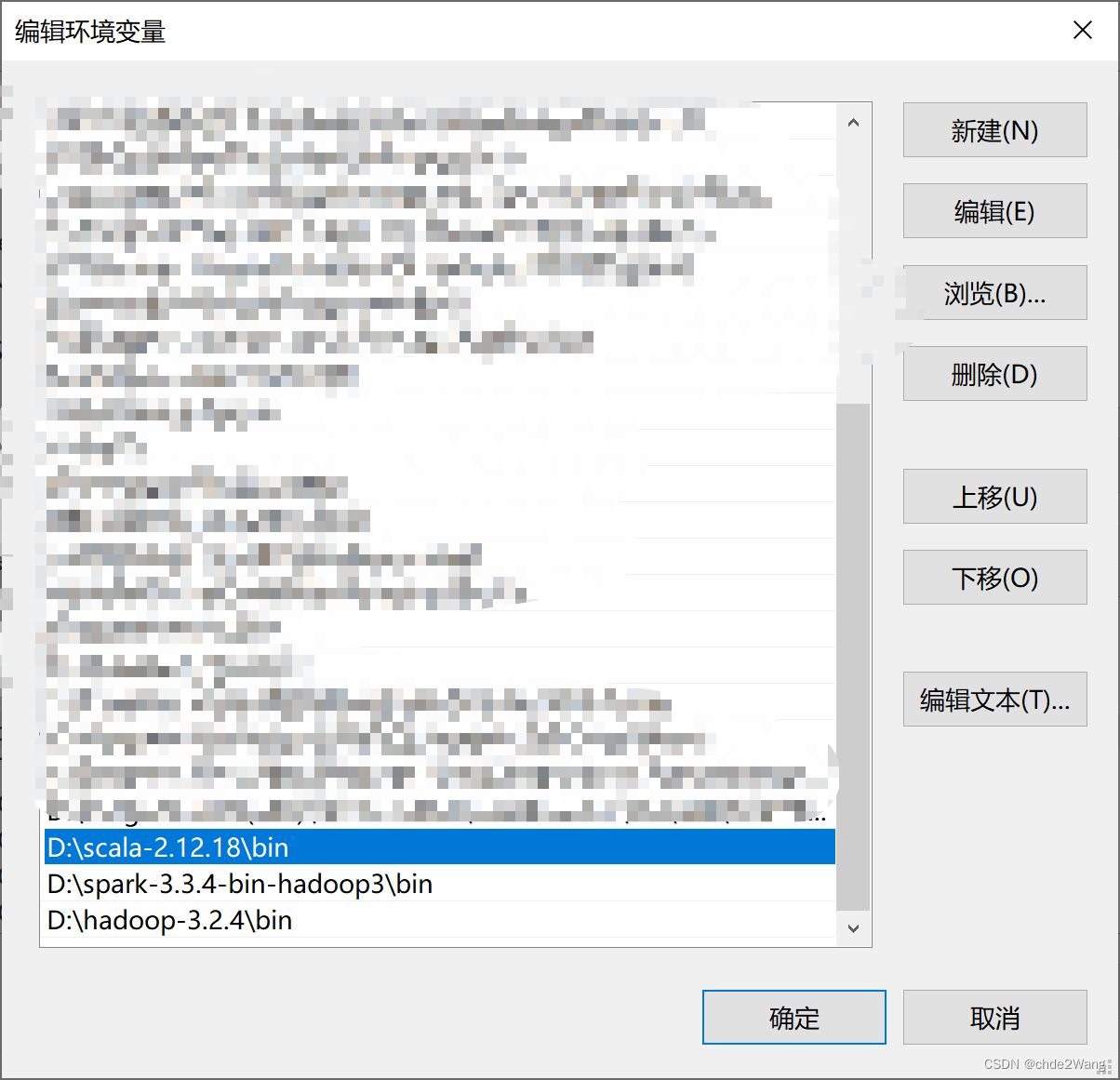
4.2 配置scala环境变量
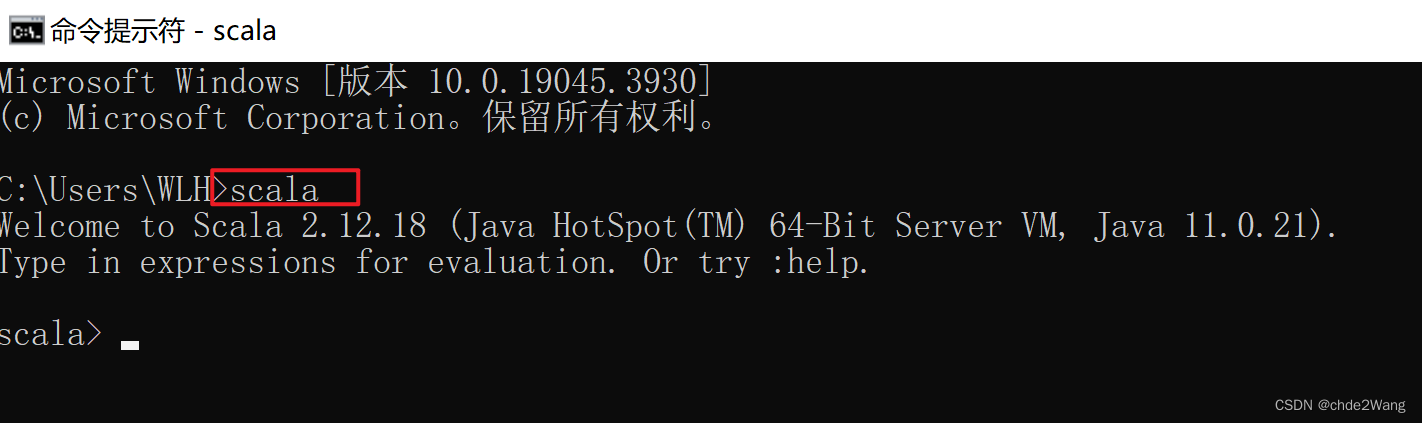
4.3安装成功验证
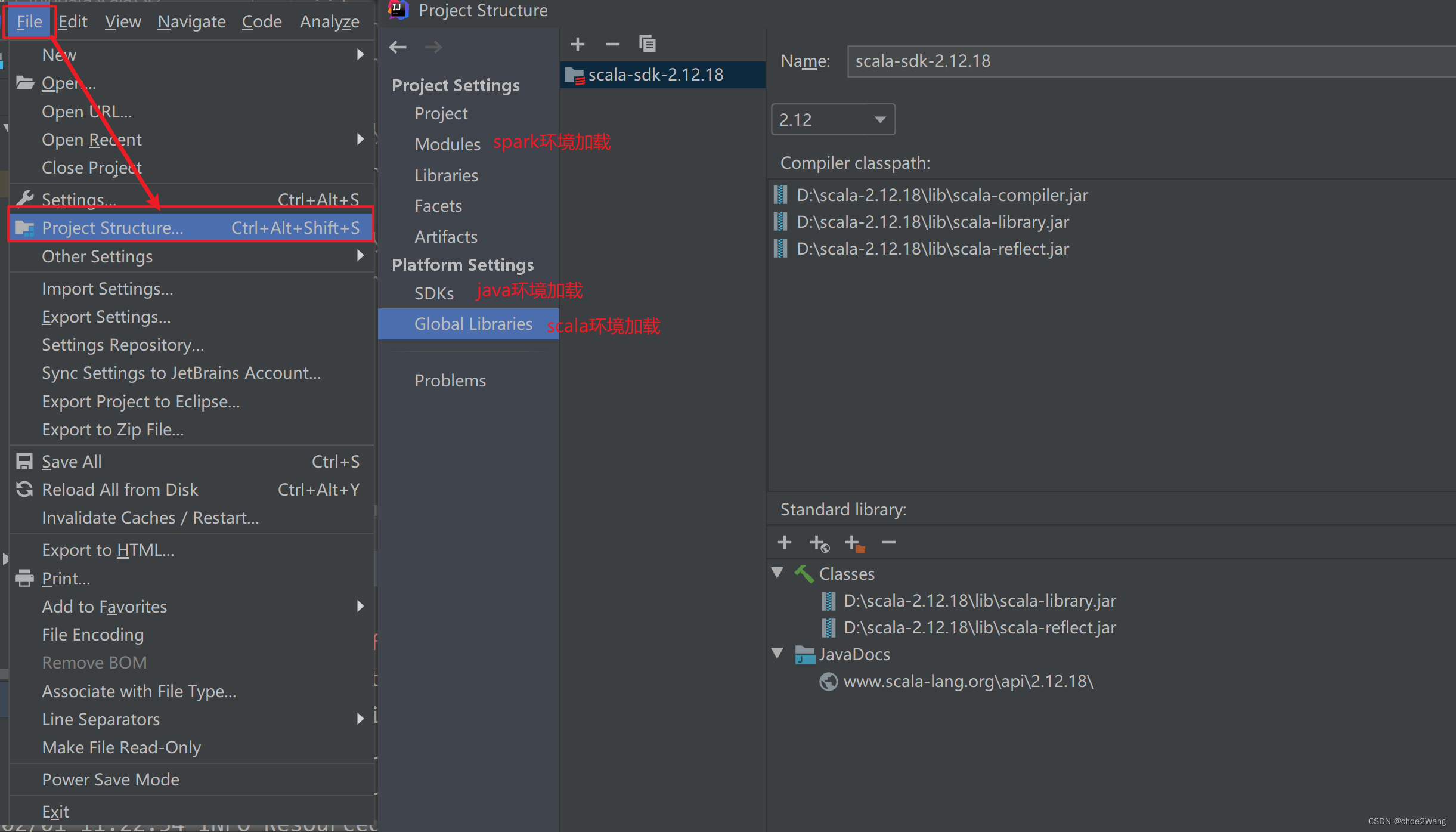
5、新建Scala项目
参考https://blog.csdn.net/weixin_38383877/article/details/135894760
5.1、项目中引入spark的jar文件
第一步: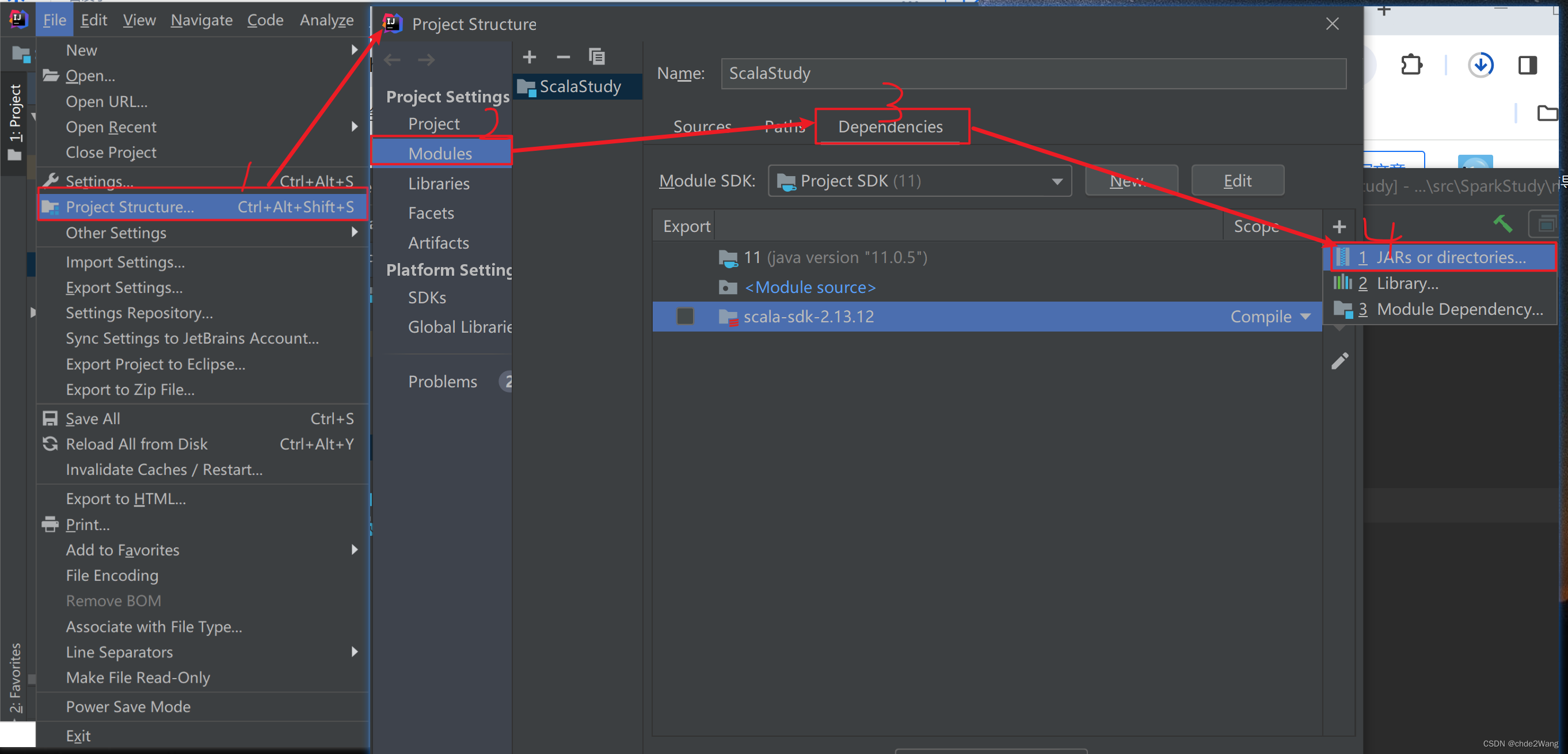
第二步: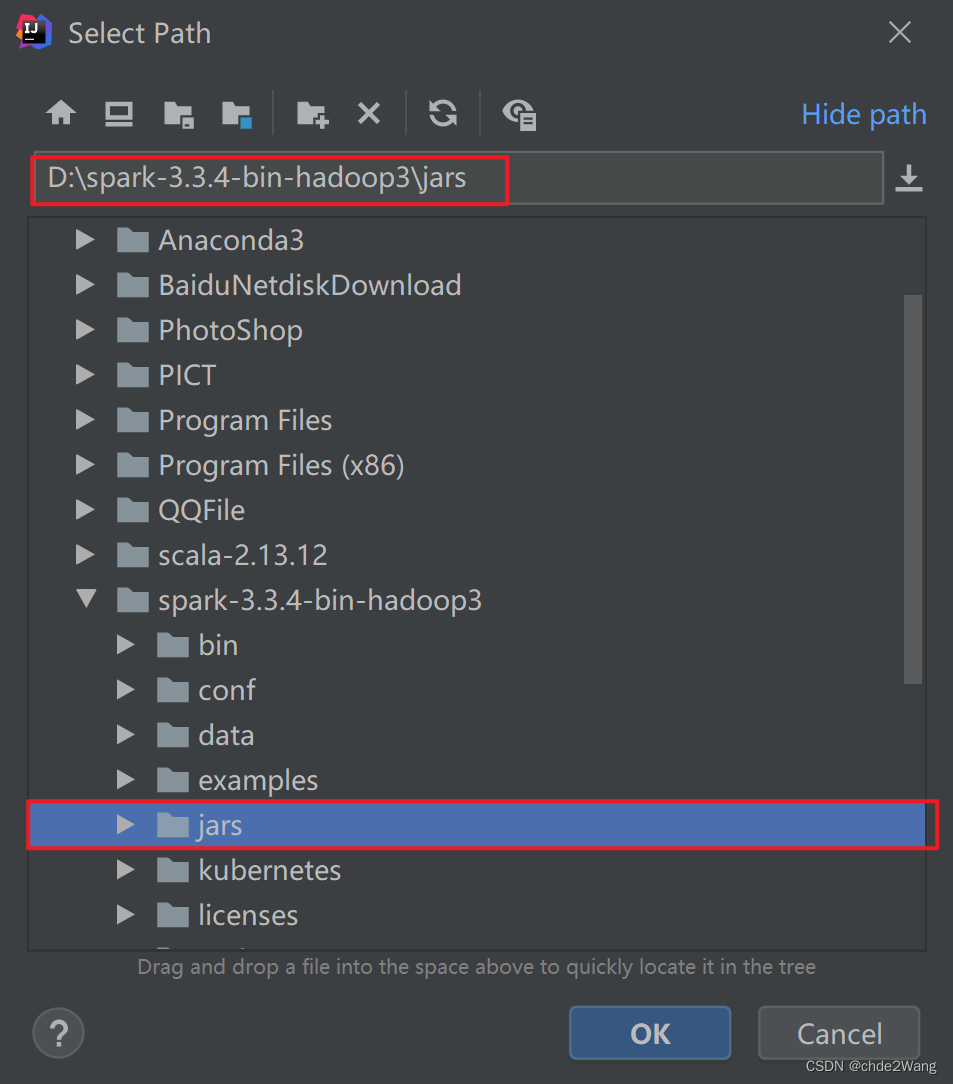
5.2 源码包下载
安装包下载链接中以tgz结尾的文件,并解压
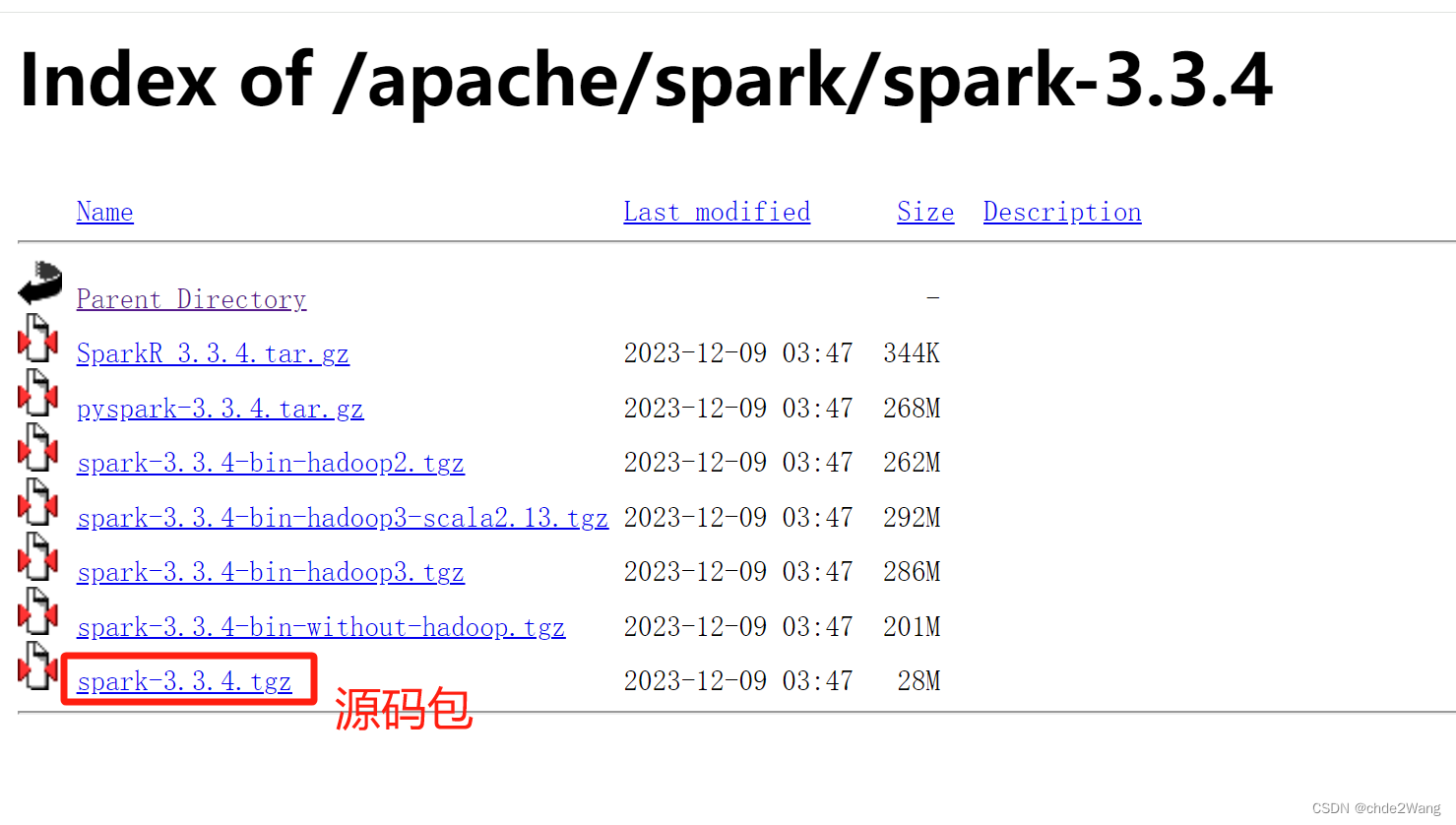
解压: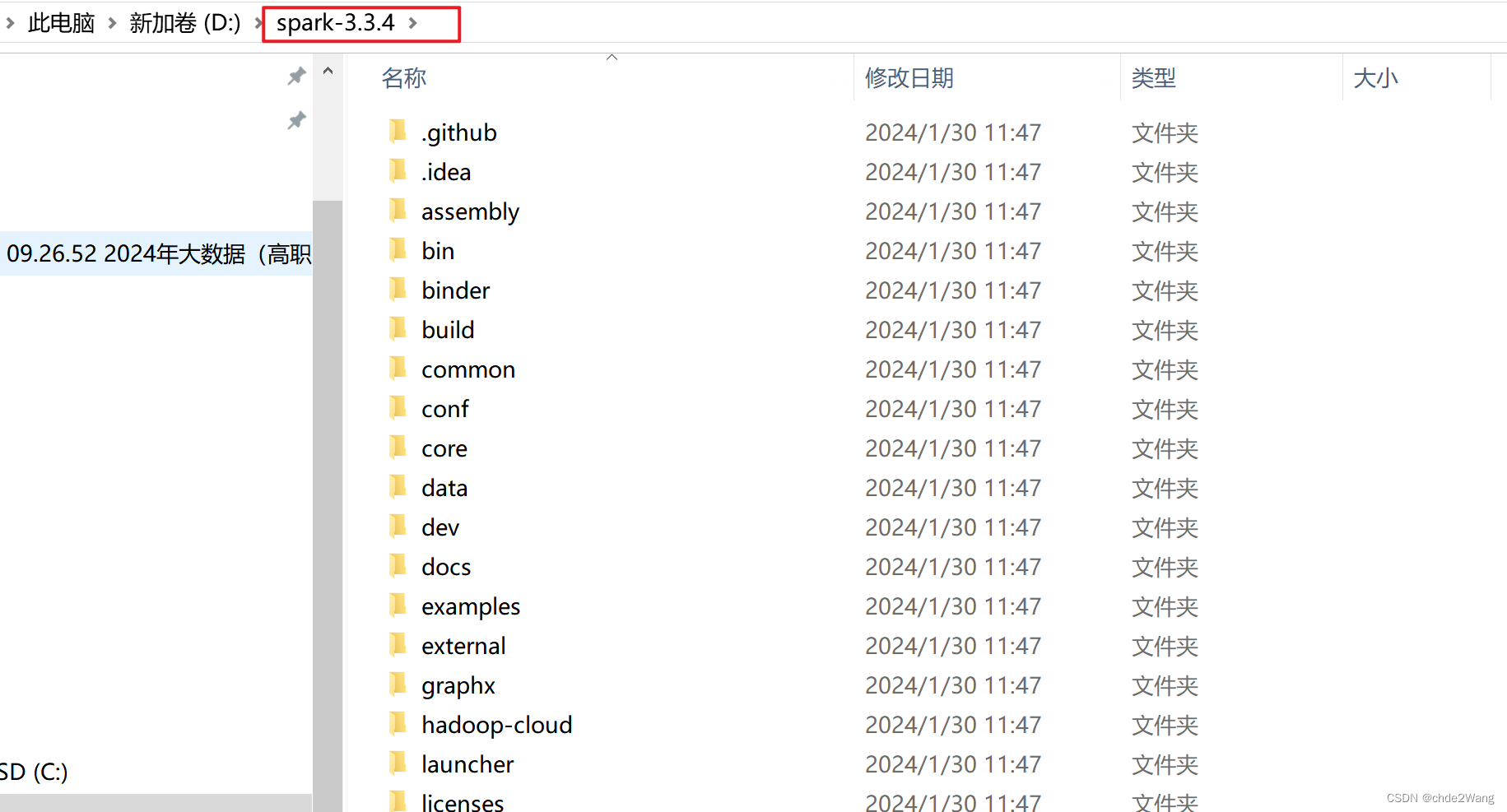
5.3 源码包导入
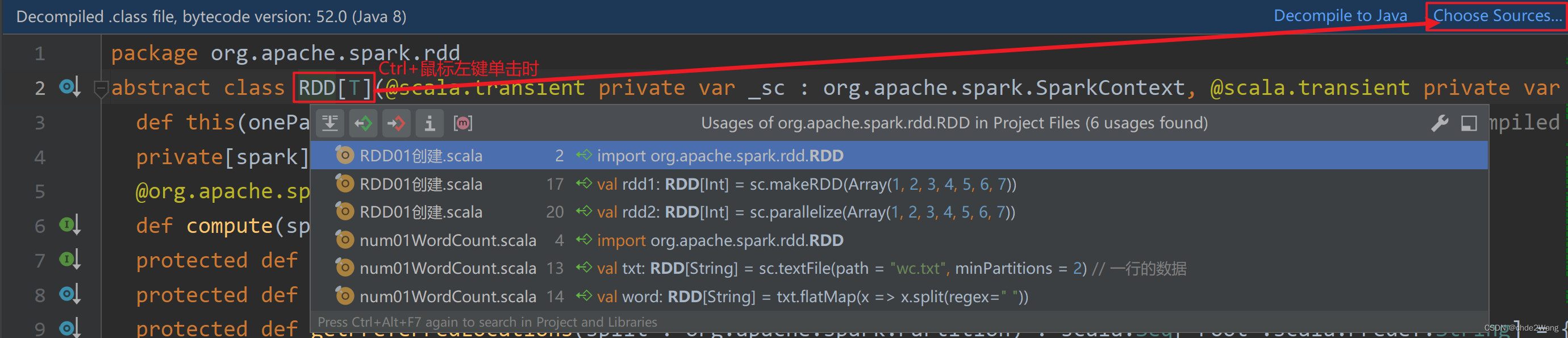
选择源码包,导入结束后即可查看源码。
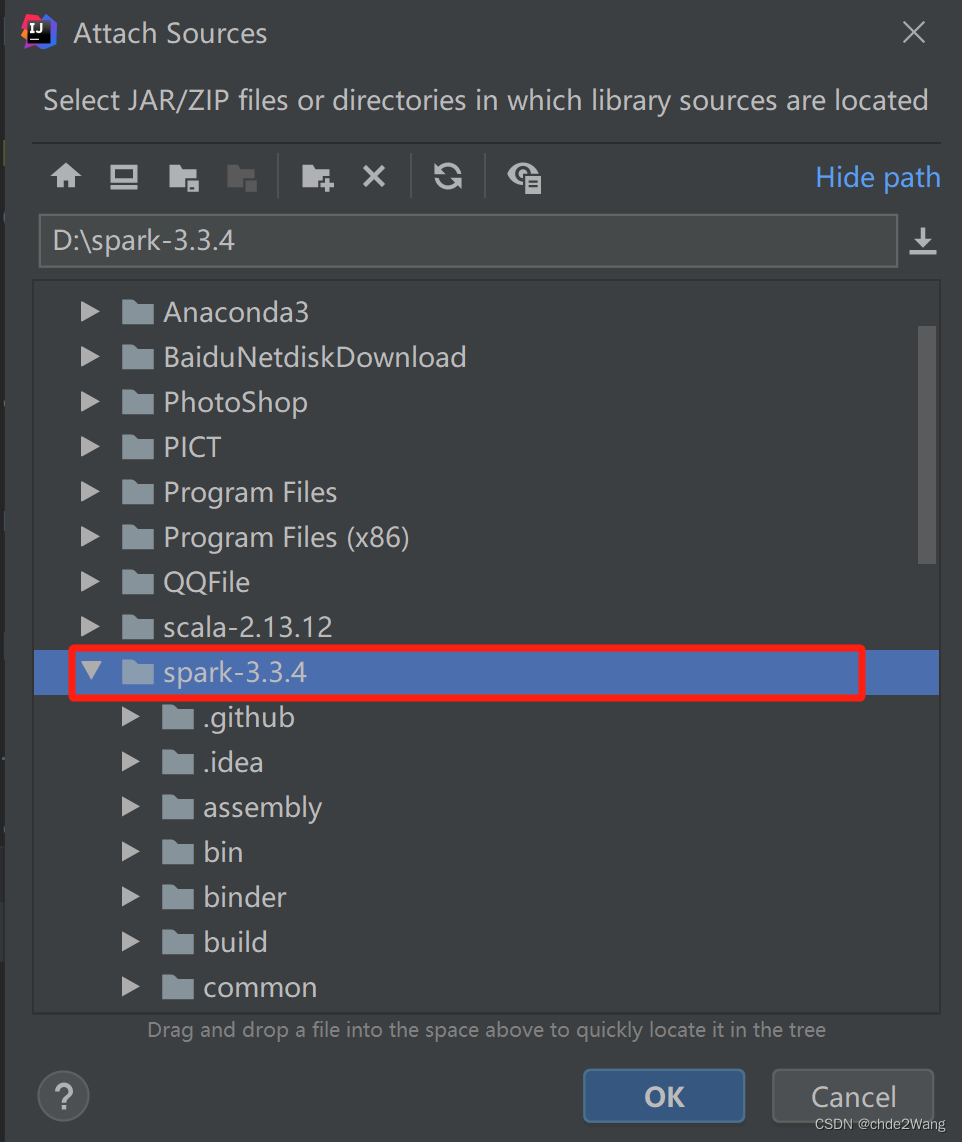
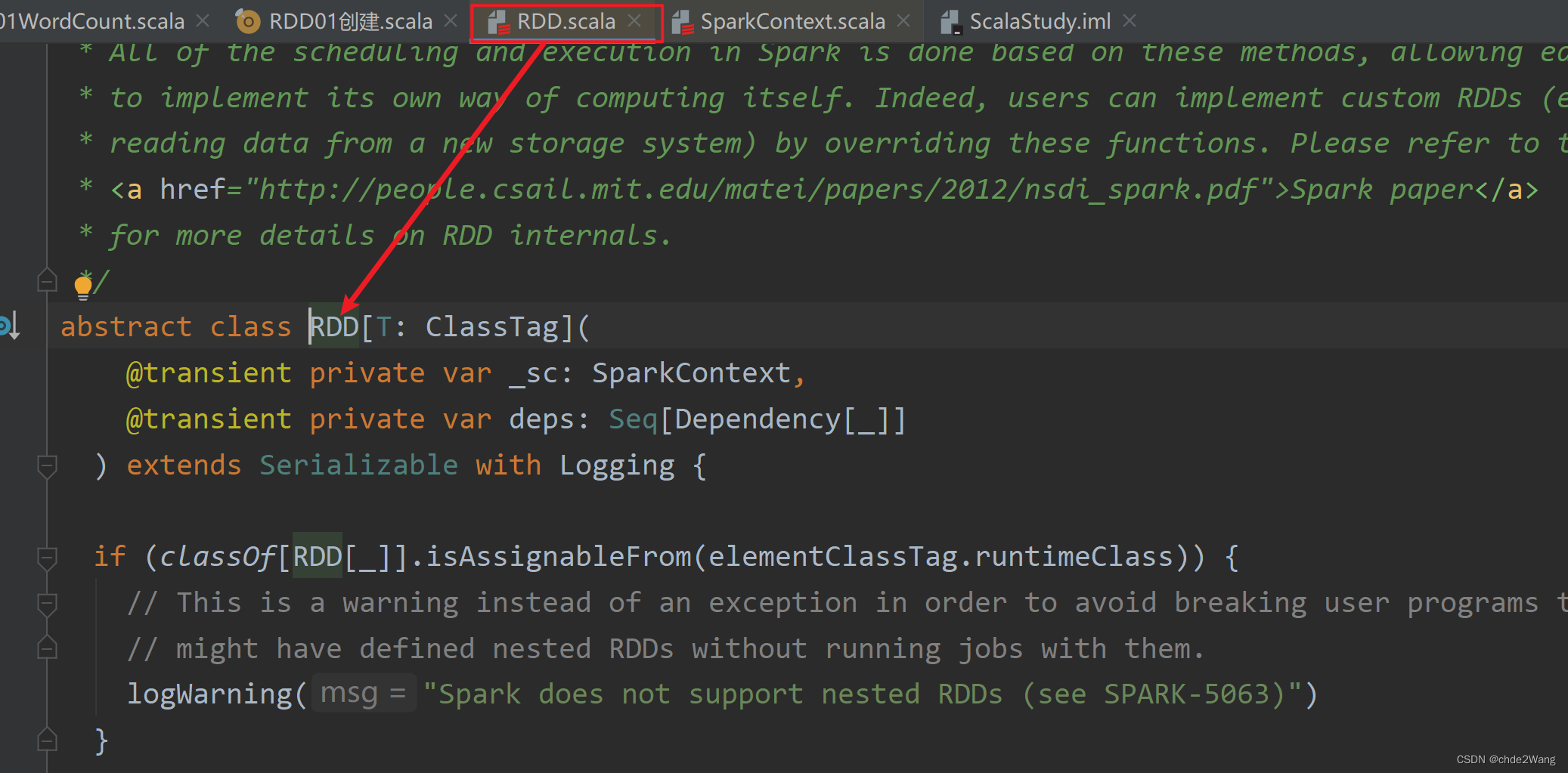
可以看到源码:
所有环境变量设置如下图
















 632
632

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











