







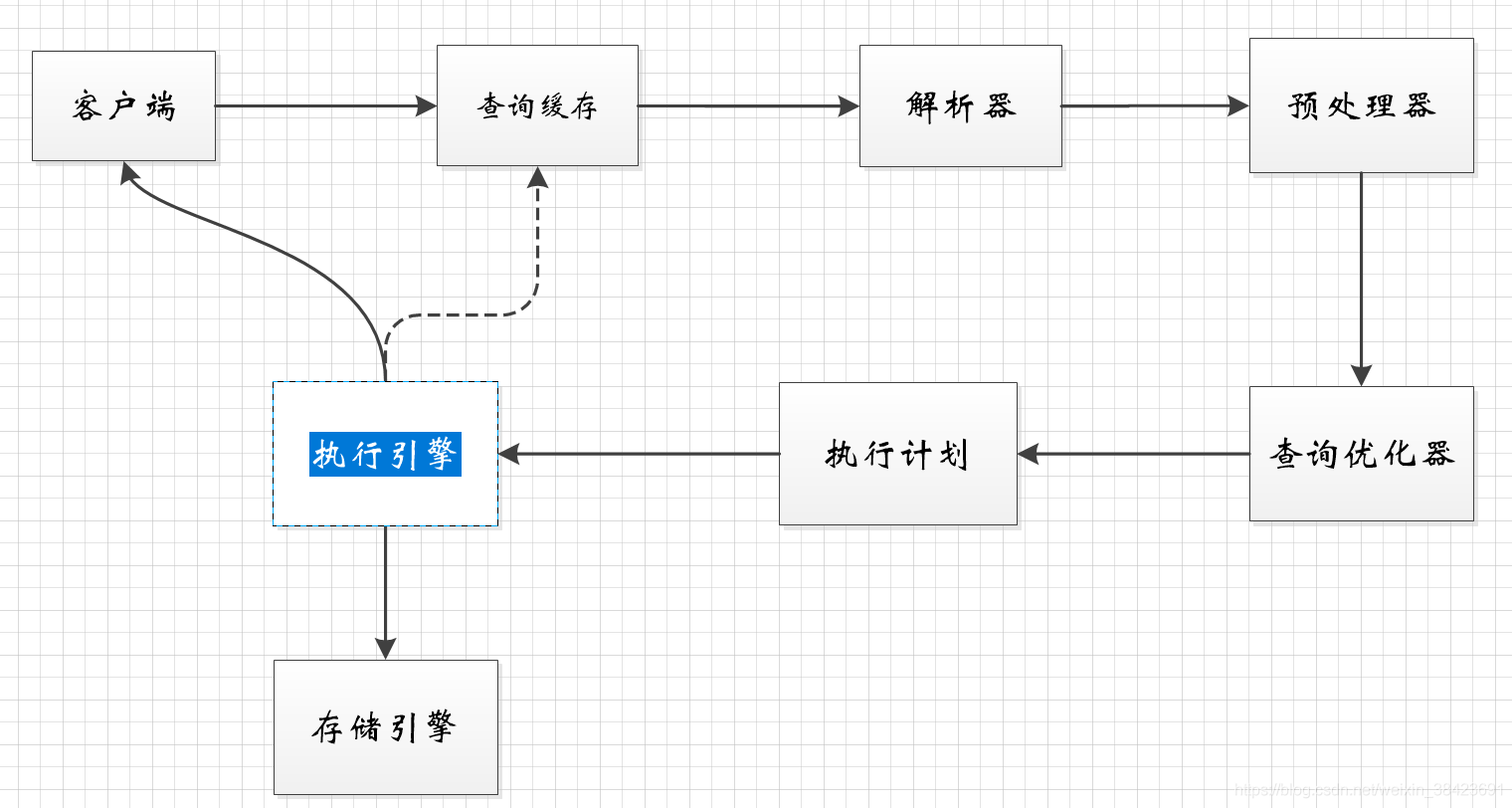
一、一条查询SQL语句是如何执行的(流程图)
- 客户端发送一条查询给服务器;
- 服务器先检查查询缓存,如果命中了缓存,则立刻返回存储在缓存中的结果。否则进入下一阶段;
- 服务器段进行SQL解析、预处理,在优化器生成对应的执行计划;
- mysql根据优化器生成的执行计划,调用存储引擎的API来执行查询;
- 将结果返回给客户端。
二、通信协议
1.通信类型:同步或者异步。
一般来说客户端连接数据库都是同步连接的。
2.连接方式:长连接或者短连接。
MySQL即支持短连接、也支持长连接。一般来说都是长连接,而且会把这个连接放到客户端的连接池。
3.简单命令操作。
可以通过Show status 命令查看MySQL当前有多少个连接。
show GLOBAL status LIKE 'Thread%'每产生一个连接或者一个会话,在服务端就会创建一个线程来处理,看看参数的含义。
| 字段 | 含义 |
| Threads_cached | 缓存中的线程连接数 |
| Threads_connected | 当前打开的连接数 |
| Threads_created | 为处理连接创建的线程数 |
| Threads_running | 非睡眠状态的连接数,通常指并发连接数 |
注:保持长连接会消耗内存。长时间不活动的连接,MySQL服务器会断开。
三、通信方式
1. 单工
在两台计算机通信的时候,数据的传输是单向的。 比如:遥控器
2. 半双工
在两台计算机之间,数据传输是双向的,你可以给我发送,我也可以给你发送,但是在这个通讯连接里面,同一时间只能有一台服务器在发送数据,也就是你要给我发的话,也必须等我发给你完了之后才能给我发。 比如:对讲机
3. 全双工
数据的传输是双向的,并且可以同时传输。 比如:打电话
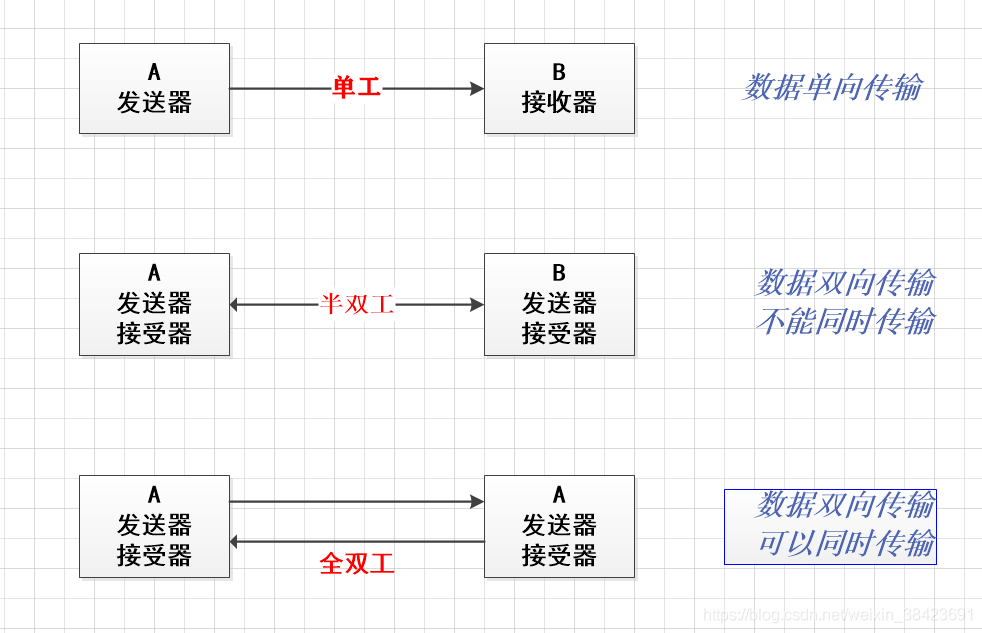
结论
MySQL使用了半双工的通信方式。
在一个连接中,要么时客户端向服务端发送数据,要么时服务端向客户端发送数据,这两个动作不能同时发送。所以客户端发送SQL语句给服务端的时候(在一次连接里)数据是不能分成小块发送的,不管你的SQL语句有多大,都是一次性发送。
比如使用MyBatis 动态SQL生成了一个批量插入的语句,插入10万条数据,values后面跟了一长串的内容,或者where条件in里面的值太多,会出现问题。
四、语法解析和预处理(Parser & Preprocessor)
来我们来看一个例子,随便执行了一个SQL 语句,服务器报了一个1064错误。

那么问题来了,它是怎么知道输入的内容是错误的?这个就是MySQL的Parser解析器和Preprocessor预处理模块。
4.1、词法解析
词法分析就是把一个完整的SQL语句打碎成一个个的单词。如下
select * from ent_i_shift where id = ?上面的SQL语句,它会打碎成 8 个字符select 、 * 、from 、ent_i_shift 、where、 id、 = 、 ? 每个符号是什么类型,从哪里开始到哪里结束的。
4.3、语法解析
第二步就是语法分析,语法分析会对SQL做一些语法检查,比如单引号有没有闭合,然后根据MySQL定义的语法规则,根据SQL语句生成一个数据结构。
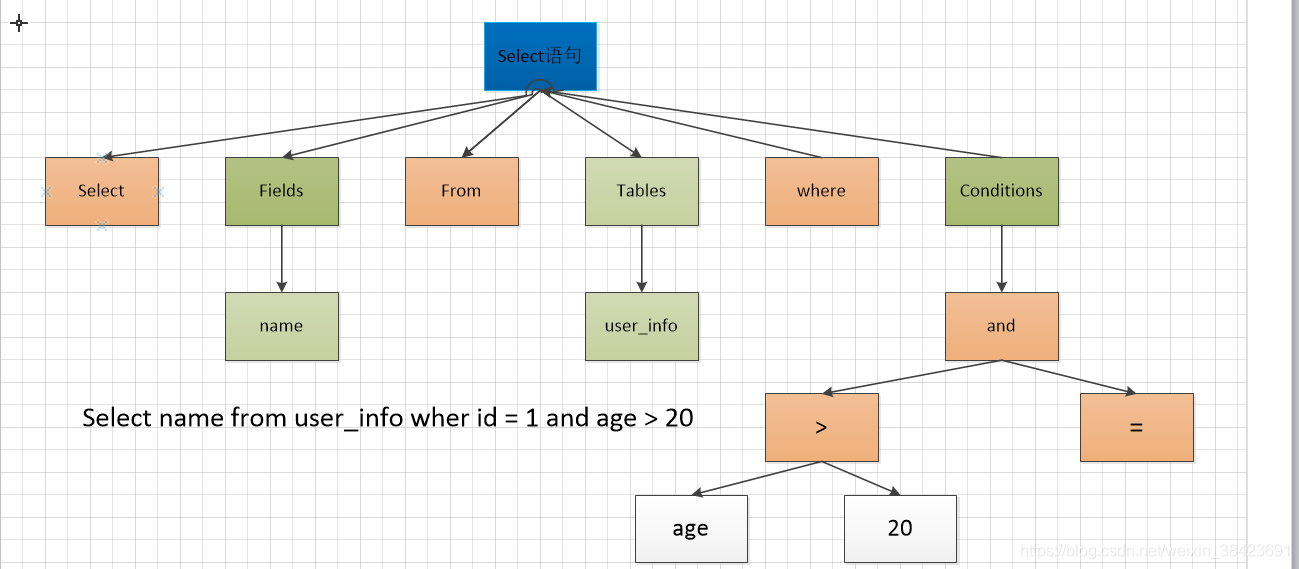
词法语法分析是一个非常基础的功能,编译器、搜索引擎如果要识别语句,必须也要有词法语法分析功能。
4.3 预处理器
如果写了一个词法和语法都正确的SQL,但是表名或者字段都不存在,会在哪里报错? 是解析的时候报错还是执行的时候报错?
SELECT * FROM abcd WHERE dd = 1 实际上还是解析的时候报错,解析SQL的环节里面有个预处理器。
它会检查生成的解析树,解决解析器无法解析的语义。比如,它会检查表和列名是否存在,检查名字和别名,保证没有歧义。预处理之后得到一个新的解析树。
五、索引是什么
5.1:什么是索引?
- 索引是帮助高效获取数据的数据结构。
- 索引是一个文件。
5.2:磁盘
图一:
- 一个磁盘由大小相同且同轴的圆形盘片组成,磁盘可以转动(各个磁盘必须同步转动)
- 磁盘的一侧有磁头支架,磁头支架固定了一组磁头,每一个磁头负责存取一个磁盘的内容。
-
- 磁头不能转动,但是可以沿磁盘半径方向运动,实际是斜切向运动。
图一: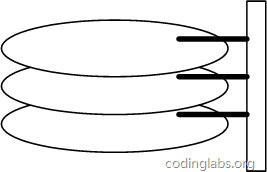 图二:
图二: 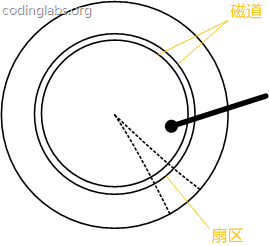
图二:
- 磁道:盘片被划分成一系列同心环,圆心是盘片中心,每一个同心环叫做一个磁道。
- 柱面:所有半径相同的磁道组成一个柱面。
- 扇区:磁道被沿半径线划分成一个个小的段,每一个段叫做一个扇区。
磁盘是怎么读取数据
- 数据逻辑地址-->磁盘-->磁盘的控制电路按照寻址逻辑地址翻译成物理地址,所谓的物料地址(数据在哪个磁道,哪个扇区)。
- 磁头需要移动到对应磁道,这个过程叫做寻道。
索引的简单理解:快速定位到数据的物理地址,快速查询出数据。
5.3:索引类型
- 普通(Normal):也叫非唯一索引,是最普通的索引,没有任何的限制。
- 唯一(Unique): 唯一索引要求键值不能重复。另外需要注意的是主键索引是一种特殊的唯一索引,它还多了一个限制条件,要求键值不能为空。主键索引引用primay key 创建。
- 全文(Fulltext): 针对比较大的数据,比如我们存放的是消息内容,有几KB的数据的这种情况,如果要解决like查询效率低的问题,可以创建全文索引。只有文本类型的字段才可以创建全文索引,比如char、varchar、text。
六、索引存储模型推演
https://www.cs.usfca.edu/~galles/visualization/AVLtree.html
6.1:二叉查找树(BST Binary Search Tree)如下图
- 左子树节点< 父节点 如下图,节点 6 ,父节点 13, 6 < 13
- 右子树节点 > 父节点 如下图,节点17,父节点 13, 17 >13
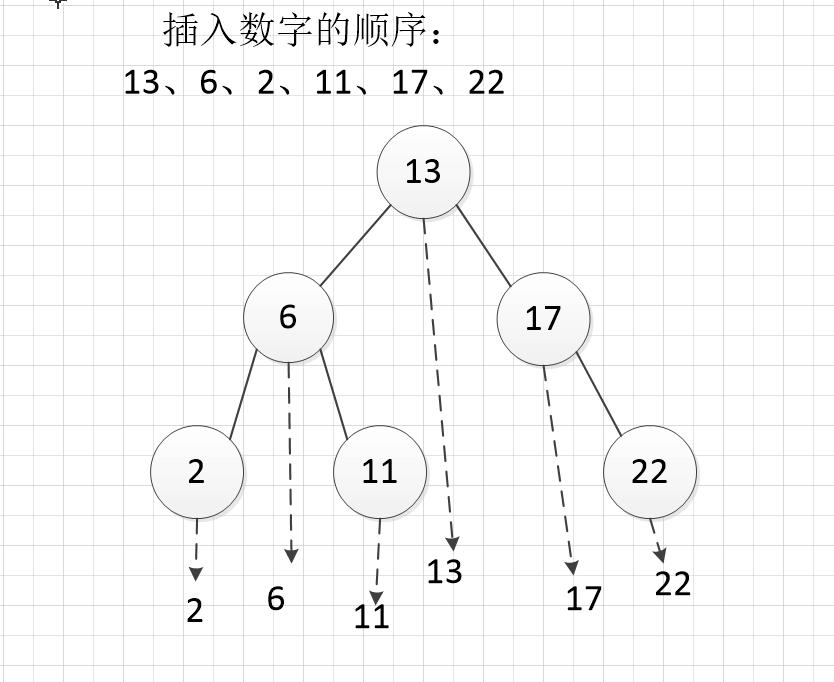
投入到平面,就成一个有顺序的线性
二叉查找树既能够实现快速查找,又能够实现快速插入。
二叉树查找树的一个问题:
查找耗时是和这颗树的深度相关的,在最坏的情况下时间复杂度会退化成O(n),看看最坏的情况吧
如果插入的数据刚好是有序的, 2、6、11、13、17、22。
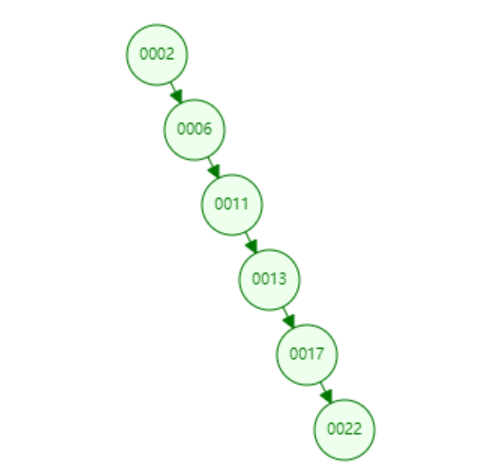
看似就是一个链表,也称“斜树”,这种情况下不能达到加快检索数据的目的,和顺序查找效率是没有什么区别,左右子树深度差太大,这颗树的左子树根本没有节点,也就是它不够平衡。
6.2:平衡二叉树(AVL Tree)(左旋、右旋)
左右子树深度差绝对值不能超过1 ,比如顺序插入:1、2、3、4、5、6
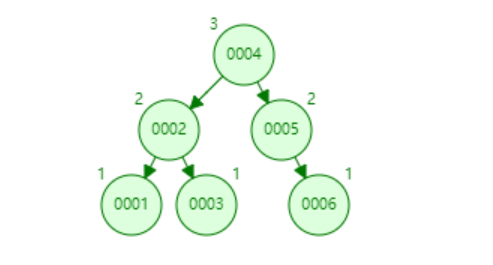
为了保持平衡,保证左右子树的深度差不能超过1的,AVL树在插入和更新数据的时候执行了一系列的计算和调整操作,涉及到左旋、右旋操作。
平衡二叉树中,一个节点,它的大小是一个固定的单位,作为索引应该存储什么内容。
- 索引的键值。比如id创建了索引,where id =1 的条件查询的时候就会找到索引里面的id的这个键值。
- 数据的磁盘地址,索引的作用就是去查找数据的存放地址。
- 左子节点和右子节点的引用。
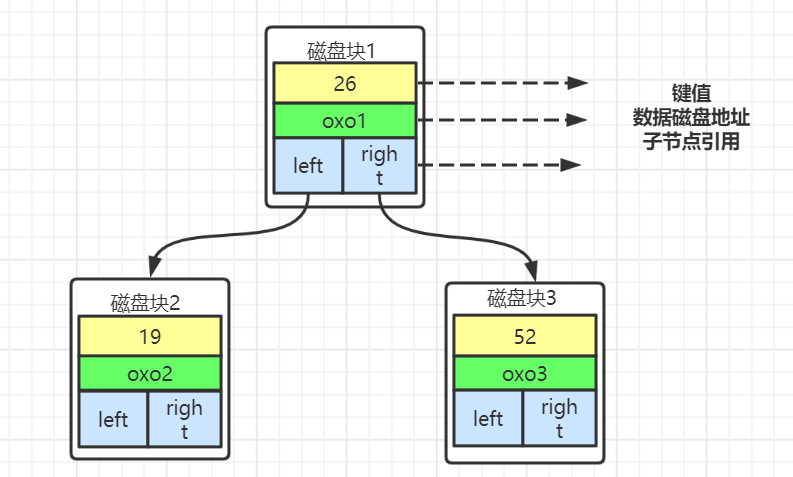
这样存储数据的话,会有什么问题
InnoDB操作磁盘的最小单位是一页(或者叫一个磁盘块),大小是16k(16384字节),一个树的节点就是16K大小。如果一个节点只存一个键值+数据+引用,例如整形的字段,可能只用了十几个字节,远远不到16K容量。
节点存储数据太小---->从索引查询数据---->访问更多节点--->磁盘读取数据交互次数越多---->消耗时间越多。
解决方案
- 每个节点存储更多的数据。
- 节点上关键字的数量越多,我们指针也越多,意味着可以有更多的分叉,树的深度就会减少。
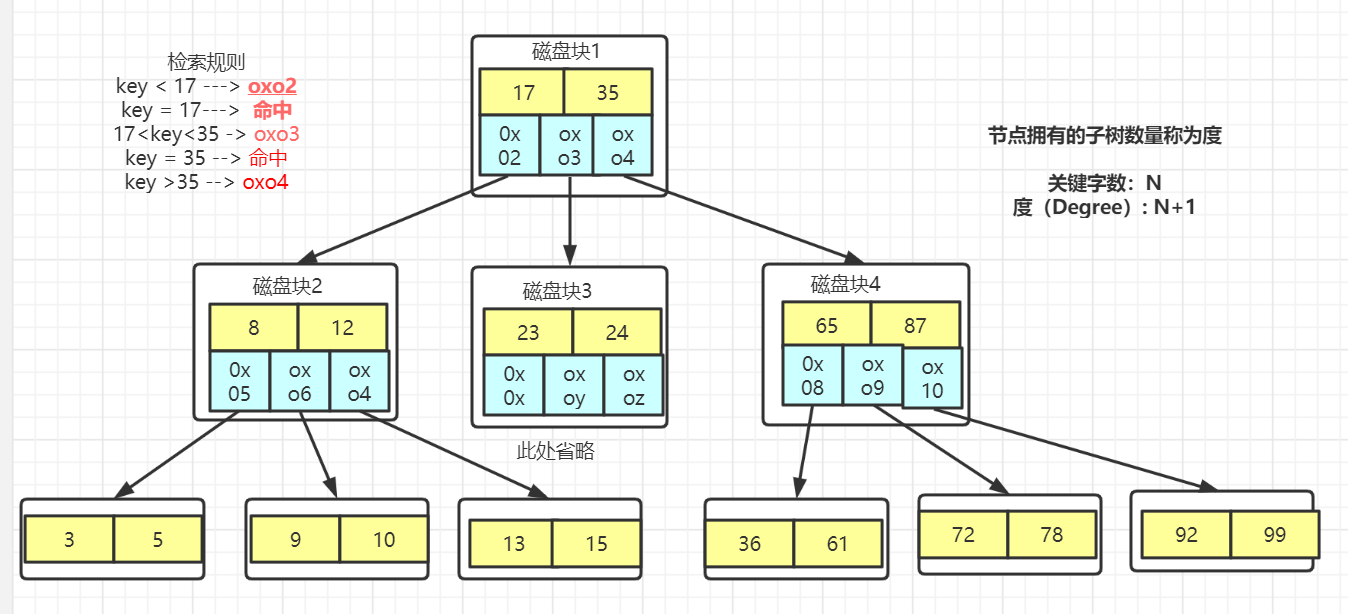
6.3:多路平衡查找树(B Tree)(分裂、合并)
跟AVL树一样,B树在枝节点和叶子节点存储键值、数据地址、节点引用。但是有一个特点:分叉数(路数)永远比关键字多1。如下图:这颗树,每个节点存储两个关键字,那么就会有三个指针指向三个子节点。
6.4:B +Tree(加强版多路平衡查找树)
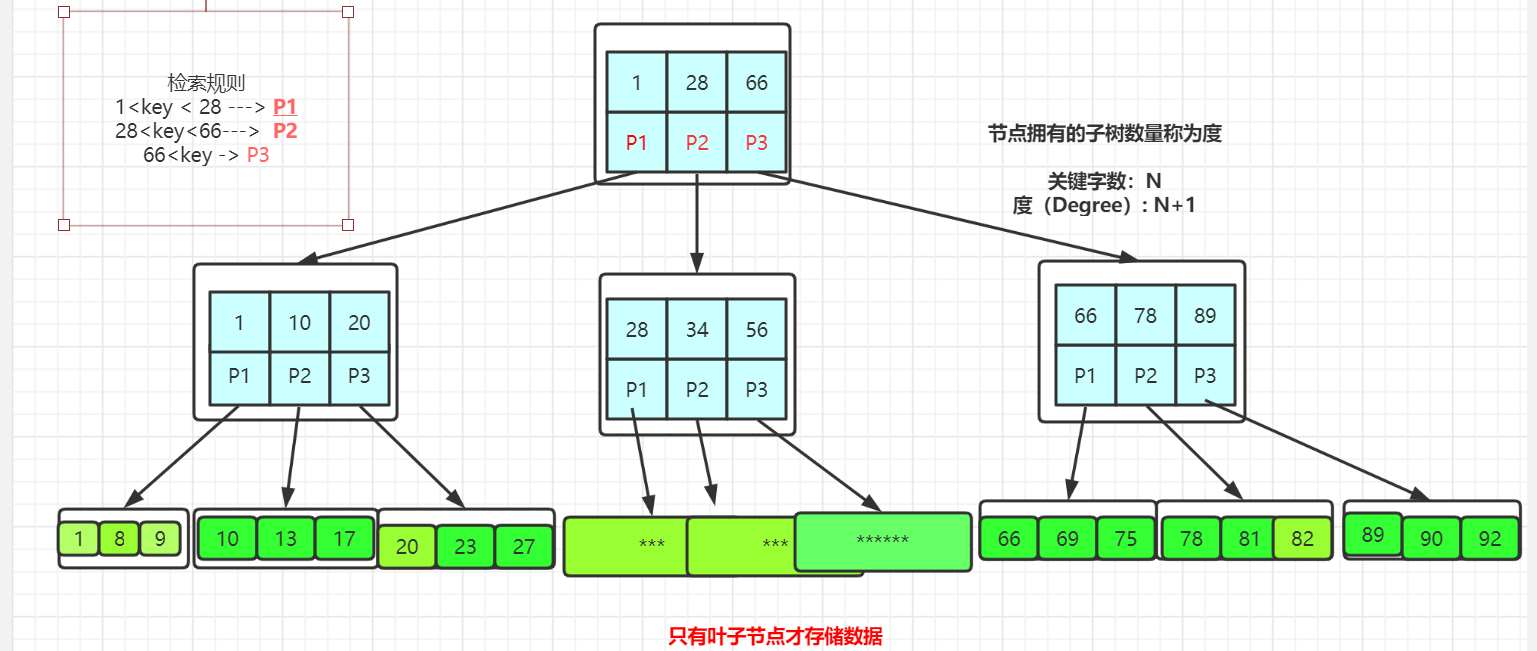
6.5 B+Tree在 B Tree 进行改良,有几个特点
- 它的关键字的数量是跟路数相等的;
- B+Tree 的根节点和枝节点中都不会存储数据,只有叶子节点才存储数据。
-
- 搜索到关键字不会直接返回,会到最后一层的叶子节点。比如搜索id = 28,第一层就直接命中了,但是数据地址在叶子节点上面,还要继续往下搜索,直到叶子节点。
- B+Tree 的每个叶子节点增加了一个指向相邻叶子节点的指针,它的最后一个数据会指向下一个叶子节点的第一个数据,形成了一个有序链表的结构。
6.6 B+Tree在 B Tree 进行改良,带来的优势
- 它是B Tree的变种,B Tree 能解决的问题,它都能解决。
- 扫库、扫表能力更强(对表进行全表扫描,只需要遍历叶子节点就可以了,不需要遍历整颗B+Tree拿到所有的数据)
- B+Tree 的磁盘读写能力相对于B Tree来说更强(跟节点和枝节点不保存数据区,所以一个节点可以保存更多的关键字,一次磁盘加载的关键字更多)
- 排序能力更强(因为叶子节点上有下一个数据区的指针,数据形成了链表)
- 效率更加稳定(B+Tree 永远是在叶子节点拿到数据,所以IO次数是稳定的)
7:索引怎么检索数据的
7.1 主键索引检索数据
表一旦设置了主键,MySQL会自动为这个主键来创建一个索引。特殊情况,中间表,没有主键,innodb引擎会从该表找出适合做索引的,一般是长整形的;或者最糟糕的情况,此表没有长整形的,那么Innodb会默认生成一个隐形的_id。
图形(略)
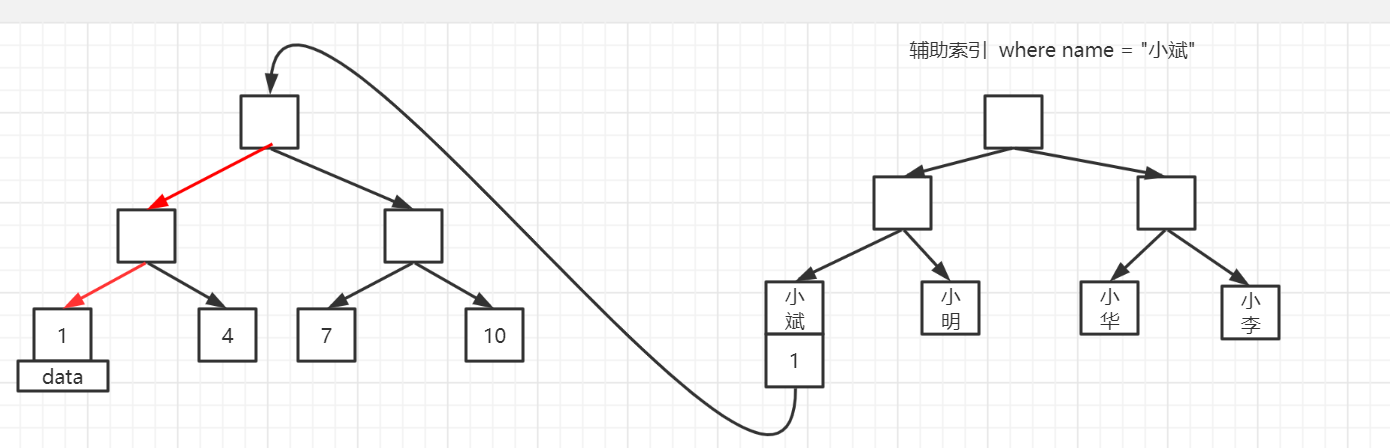
7.2 普通索引检索数据
叶子节点找到主键值,再到主键索引的叶子节点拿到数据。
八、索引使用原则
实践才是检验真理的唯一标准,看看测试报告吧!















 3965
3965











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









