






- SQL优化
- 查询SQL尽量不要使用select *,而是具体字段
- 字段多时,大表能达到100多个字段甚至达200多个字段
- 只取需要的字段,节省资源、减少网络开销
- select * 进行查询时,很可能不会用到索引,就会造成全表扫描
- 避免在where子句中使用or来连接条件
- 分开两条sql写
- 使用or可能会使索引失效,从而全表扫描
- 对于or没有索引的字段,假设它走主键的索引,但是走到字段查询条件时,它还得全表扫描。
- 也就是说整个过程需要三步:全表扫描+索引扫描+合并。如果它一开始就走全表扫描,直接一遍扫描就搞定。虽然mysql是有优化器的,处于效率与成本考虑,遇到or条件,索引还是可能失效的
- 使用varchar代替char
- 其次对于查询来说,在一个相对较小的字段内搜索,效率更高
- varchar变长字段按数据内容实际长度存储,存储空间小,可以节省存储空间
- char按声明大小存储,不足补空格
- 其次对于查询来说,在一个相对较小的字段内搜索,效率更高
- 其次对于查询来说,在一个相对较小的字段内搜索,效率更高
- 尽量使用数值替代字符串类型
- 查询尽量避免返回大量数据
- 如果查询返回数据量很大,就会造成查询时间过长,网络传输时间过长。同时,大量数据返回也可能没有实际意义。
- 通常采用分页,一页习惯10/20/50/100条。
- 如果查询返回数据量很大,就会造成查询时间过长,网络传输时间过长。同时,大量数据返回也可能没有实际意义。
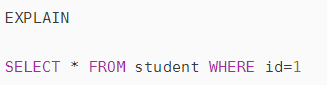
- 使用explain分析你SQL执行计划
- SQL提供了explain关键字,它可以分析你的SQL执行计划,看它是否最佳。Explain主要看SQL是否使用了索引。
-
- SQL提供了explain关键字,它可以分析你的SQL执行计划,看它是否最佳。Explain主要看SQL是否使用了索引。
- 是否使用了索引及其扫描类型
- type:
- ALL 全表扫描,没有优化,最慢的方式
- index 索引全扫描
- range 索引范围扫描,常用语<,<=,>=,between等操作
- ref 使用非唯一索引扫描或唯一索引前缀扫描,返回单条记录,常出现在关联查询中
- eq_ref 类似ref,区别在于使用的是唯一索引,使用主键的关联查询
- const/system 单条记录,系统会把匹配行中的其他列作为常数处理,如主键或唯一索引查询
- null MySQL不访问任何表或索引,直接返回结果
- key:
- 真正使用的索引方式
- type:
- 创建name字段的索引
- ALTER TABLE student ADD INDEX index_name (NAME)
- 优化like语句
- ike很可能让你的索引失效 尽量只用匹配首字母,其他两种可能失效
-
- ike很可能让你的索引失效 尽量只用匹配首字母,其他两种可能失效
- 字符串怪现象(索引失效)
- 这是因为不加单引号时,是字符串跟数字的比较,它们类型不匹配,MySQL会做隐式的类型转换,把它们转换为数值类型再做比较
- 索引不宜太多,一般5个以内
- 索引并不是越多越好,虽其提高了查询的效率,但却会降低插入和更新的效率
- 索引可以理解为一个就是一张表,其可以存储数据,其数据就要占空间
- 索引表的一个特点,其数据是排序的,排序要花费时间
- insert或update时有可能会重建索引,如果数据量巨大,重建将进行记录的重新排序,所以建索引需要慎重考虑,视具体情况来定
- 一个表的索引数最好不要超过5个,若太多需要考虑一些索引是否有存在的必要
- 索引不适合建在有大量重复数据的字段上
- SQL优化器是根据表中数据量来进行查询优化的,如果索引列有大量重复数据,Mysql查询优化器推算发现不走索引的成本更低,很可能就放弃索引了。
- where限定查询的数据
- 反例:
- SELECT id,NAME FROM student WHERE sex='男'
- 正例:
- SELECT id,NAME FROM student WHERE id=1 AND sex='男'
- 需要什么数据,就去查什么数据,避免返回不必要的数据,节省开销
- 反例:
- 避免在where中对字段进行表达式操作
- 反例:
- SELECT * FROM student WHERE id+1-1=+1
- 正例:
- SELECT * FROM student WHERE id=+1-1+1
- SELECT * FROM student WHERE id=1
- 理由:
- SQL解析时,如果字段相关的是表达式就进行全表扫描
- 避免在where子句中使用!=或<>操作符
- 应尽量避免在where子句中使用!=或<>操作符,否则引擎将放弃使用索引而进行全表扫描。但应该以业务优先
- 使用!=和<>很可能会让索引失效
- 去重distinct过滤字段要少
- 带distinct的语句占用cpu时间高于不带distinct的语句。因为当查询很多字段时,如果使用distinct,数据库引擎就会对数据进行比较,过滤掉重复数据,然而这个比较、过滤的过程会占用系统资源,如cpu时间
- 应尽量避免在where子句中使用!=或<>操作符,否则引擎将放弃使用索引而进行全表扫描。但应该以业务优先
- 反例:
- where中使用默认值代替null
- 数量大时批量插入性能提升
- 多条提交:
- NSERT INTO student (id,NAME) VALUES(4,'齐雷');
- INSERT INTO student (id,NAME) VALUES(5,'刘昱江');
- 批量提交:
- INSERT INTO student (id,NAME) VALUES(4,'齐雷'),(5,'刘昱江');
- 默认新增SQL有事务控制,导致每条都需要事务开启和事务提交;而批量处理是一次事务开启和提交。
- 数据量小体现不出来
- 多条提交:
- 批量删除优化
- 避免同时修改或删除过多数据,因为会造成cpu利用率过高,会造成锁表操作,从而影响别人对数据库的访问。
- #采用单一循环操作,效率低,时间漫长
- //分批进行删除
- 一次性删除太多数据,可能造成锁表,会有lock wait timeout exceed的错误,所以建议分批操作
- **百万级别或以上的数据如何删除 **
- 关于索引:由于索引需要额外的维护成本,因为索引文件是单独存在的文件,所以当我们对数据的增加,修改,删除,都会产生额外的对索引文件的操作,这些操作需要消耗额外的IO,会降低增/改/删的执行效率。
- 所以,在我们删除数据库百万级别数据的时候,删除数据的速度和创建的索引数量是成正比的。
- 所以我们想要删除百万数据的时候可以先删除索引(此时大概耗时三分多钟)
- 然后删除其中无用数据(此过程需要不到两分钟)
- 删除完成后重新创建索引(此时数据较少了)创建索引也非常快,约十分钟左右。
- 与之前的直接删除绝对是要快速很多,更别说万一删除中断,一切删除会回滚。那更是坑了
- 所以,在我们删除数据库百万级别数据的时候,删除数据的速度和创建的索引数量是成正比的。
- 关于索引:由于索引需要额外的维护成本,因为索引文件是单独存在的文件,所以当我们对数据的增加,修改,删除,都会产生额外的对索引文件的操作,这些操作需要消耗额外的IO,会降低增/改/删的执行效率。
- 避免同时修改或删除过多数据,因为会造成cpu利用率过高,会造成锁表操作,从而影响别人对数据库的访问。
- 伪删除设计
- 商品状态(state):1-上架、2-下架、3-删除
- 这里的删除只是一个标识,并没有从数据库表中真正删除,可以作为历史记录备查
- 同时,一个大型系统中,表关系是非常复杂的,如电商系统中,商品作废了,但如果直接删除商品,其它商品详情,物流信息中可能都有其引用。
- 通过where state=1或者where state=2过滤掉数据,这样伪删除的数据用户就看不到了,从而不影响用户的使用
- 操作速度快,特别数据量很大情况下
- 商品状态(state):1-上架、2-下架、3-删除
- 提高group by语句的效率
- 可以在执行到该语句前,把不需要的记录过滤掉
- 反例:先分组,再过滤
-
- 正例:先过滤,后分组
-
- 反例:先分组,再过滤
- 可以在执行到该语句前,把不需要的记录过滤掉
- 复合索引最左特性
- 复合索引也称为联合索引
- 当我们创建一个联合索引的时候,如(k1,k2,k3),相当于创建了(k1)、(k1,k2)和(k1,k2,k3)三个索引,这就是最左匹配原则
- 联合索引不满足最左原则,索引一般会失效,但是这个还跟Mysql优化器有关的
- 什么是最左前缀原则?什么是最左匹配原则
- 顾名思义,就是最左优先,在创建多列索引时,要根据业务需求,where子句中使用最频繁的一列放在最左边。
- 最左前缀匹配原则,非常重要的原则,mysql会一直从左向右匹配直到遇到范围查询(>、<、between、like)就停止匹配,比如a = 1 and b = 2 and c > 3 and d = 4 如果建立(a,b,c,d)顺序的索引,d是建立不到索引的,如果建立(a,b,d,c)的索引则都可以用到,a,b,d的顺序可以任意调整。
- =和in可以乱序,比如a = 1 and b = 2 and c = 3 建立(a,b,c)索引可以任意顺序,mysql的查询优化器会帮你优化成索引可以识别的形式
- 排序字段创建索引
- 什么样的字段才需要创建索引呢?原则就是where和order by中常出现的字段就创建索引。
- 删除冗余和重复的索引
- 不要有超过5个以上的表连接
- 关联的表个数越多,编译的时间和开销也就越大
- 每次关联内存中都生成一个临时表
- 应该把连接表拆开成较小的几个执行,可读性更高
- 如果一定需要连接很多表才能得到数据,那么意味着这是个糟糕的设计了
- 阿里规范中,建议多表联查三张表以下
- inner join 、left join、right join,优先使用inner join
- 三种连接如果结果相同,优先使用inner join,如果使用left join左边表尽量小
- 如果inner join是等值连接,返回的行数比较少,所以性能相对会好一点
- 同理,使用了左连接,左边表数据结果尽量小,条件尽量放到左边处理,意味着返回的行数可能比较少。这是mysql优化原则,就是小表驱动大表,小的数据集驱动大的数据集,从而让性能更优
- inner join 内连接,只保留两张表中完全匹配的结果集
- left join会返回左表所有的行,即使在右表中没有匹配的记录
- right join会返回右表所有的行,即使在左表中没有匹配的记录
- 三种连接如果结果相同,优先使用inner join,如果使用left join左边表尽量小
- in子查询的优化
- 日常开发实现业务需求可以有两种方式实现:
- 一种使用数据库SQL脚本实现
- 一种使用程序实现
- 数据库最费劲的就是程序链接的释放。假设链接了两次,每次做上百万次的数据集查询,查完就结束,这样就只做了两次;相反建立了上百万次链接,申请链接释放反复重复,就会额外花费很多实际,这样系统就受不了了,慢,卡顿
- 日常开发实现业务需求可以有两种方式实现:
- 查询SQL尽量不要使用select *,而是具体字段
sql优化
最新推荐文章于 2024-07-12 07:13:33 发布



















 1172
1172











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









