







Fibonacci Heaps
motivation
A Fibonacci heap can be viewed as an extension of Binomial heaps which supports DECREASE-KEY and DELETE operations efficiently.
我们为什么需要更高效的 decreaseKey?
设想在 Dijkstra单源点最短路径问题上,G=(V,E), |V| = n, |E| = m,我们使用优先队列,算法实现可看为 n 次 insert,n 次 extractMin 和 m 次decreaseKey 的 sequnce. 用 amortized cost = O ( n ⋅ T i n s e r t + n ⋅ T e x t r a c t M i n + m ⋅ T d e c r e a s e K e y ) O(n\cdot T_{insert} + n\cdot T_{extractMin} +m\cdot T_{decreaseKey}) O(n⋅Tinsert+n⋅TextractMin+m⋅TdecreaseKey). 我们知道无论如何优化 n 次 insert 和n 次 extractMin 是无法优于 O ( n log n ) O(n\log n) O(nlogn)的。那么就只能考虑在其他不变的情况下,优化 decreaseKey.
Fibonacci Heaps
已知 binary 和 binomial heaps 的 decreaseKey 都取决于树的高度,O(log n). 对于斐波那契堆我们希望把decreaseKey的复杂度降到O(1) —— decreaseKey 直接将该 node 从它的 parent 取下来,再加入到 set 里,其余操作均与 lazy binomial heap相同,详见lazy binomial heap.
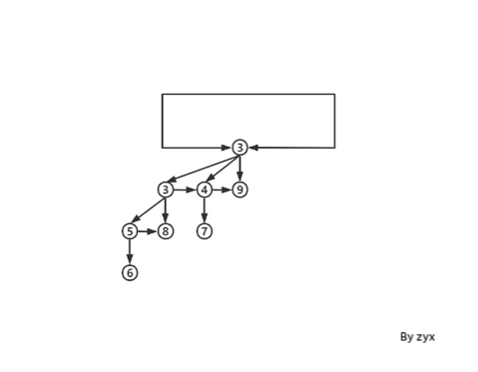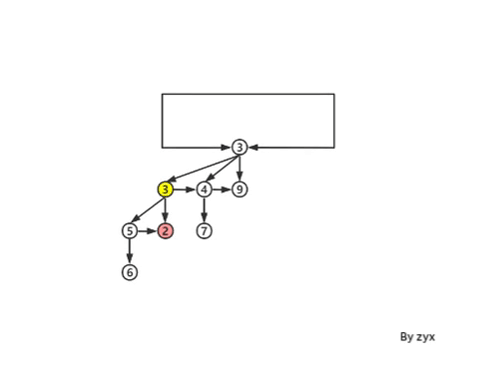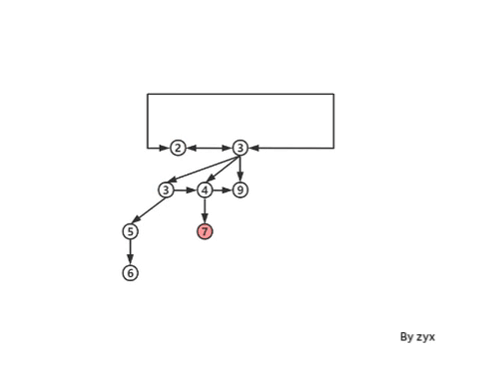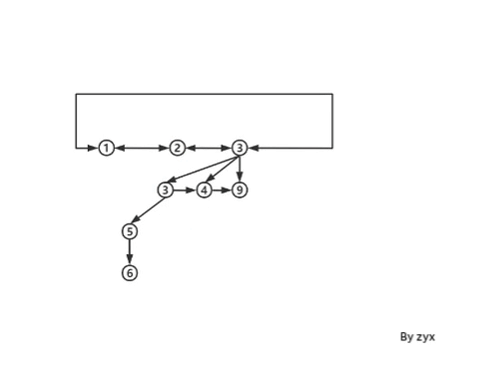
但是这样会有一些问题,因为我们无法同时保持下面三种性质:
- decrease-key takes time O(1).
- Our trees are heap-ordered.
Our trees are binomial tree.
那就放弃第三条好了,这样可以随心所欲地 cut (decreaseKey).
extractMin 变慢了?
但是这样仍然会有一些问题,插入依然是 lazy meld,但如何去extractMin 呢?像之前的情况,case (a),参照 lazy binomial heap extractMin 时 coalesce step 的方式去合并。
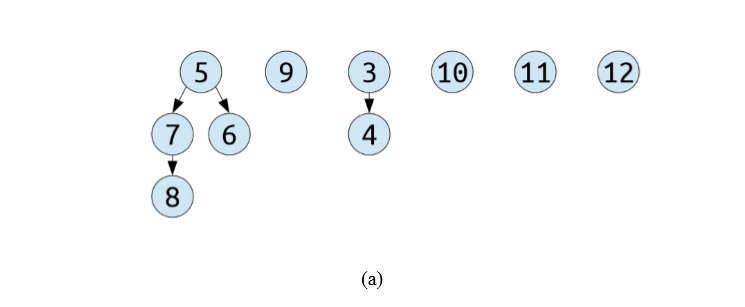
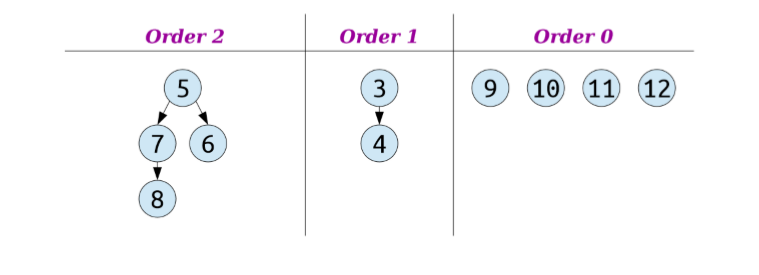
但现在 set 里面的 tree 不再是 binomial tree了,每一棵树 nodes 个数不再是 2 k 2^k 2k,order 如何再去标记?类似下面这种情况,case (b),怎么合并?
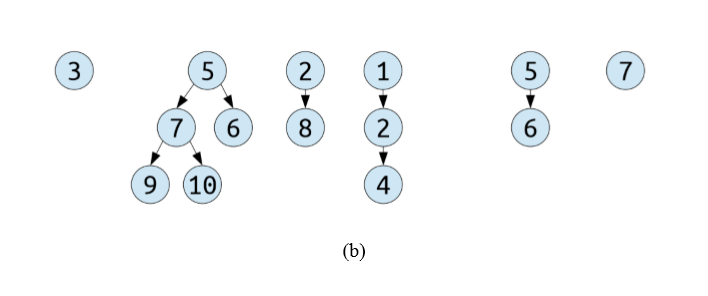
一种解决办法是令一棵树的 order 等于 其 root 的 rank,即 root 有几个孩子。然后同 coalesce step 中按 order 分配再从低到高合并。
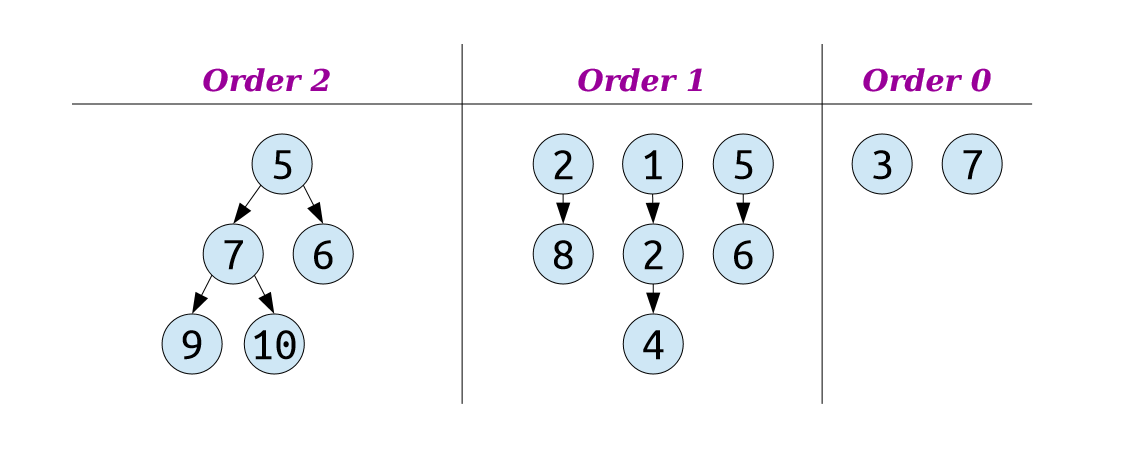
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1Mwe5QXG-1592380015145)(https://upload-images.jianshu.io/upload_images/23517192-dfaddb3f929caf8e.gif?imageMogr2/auto-orient/strip)]
**但是其实这样的做法会出现很严重的问题。就是我们的树的形状不再 well-constrained. Nodes 个数 不再与这棵树的 order 成 exponential 关系。**heap 里可能会出现这样形状的树:

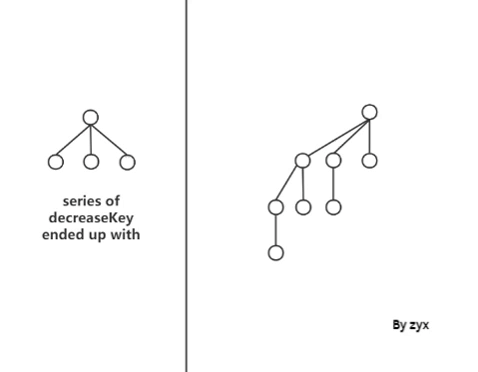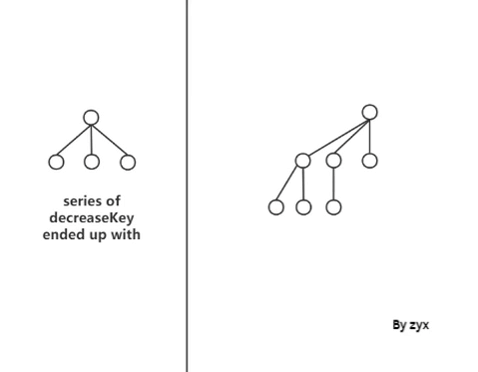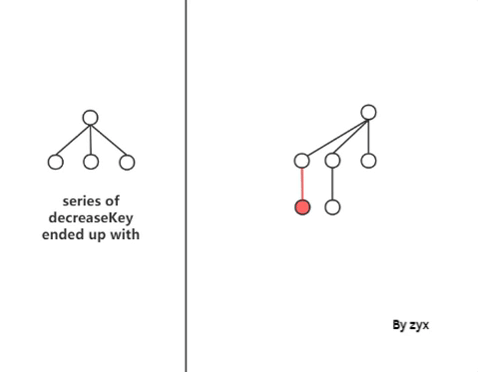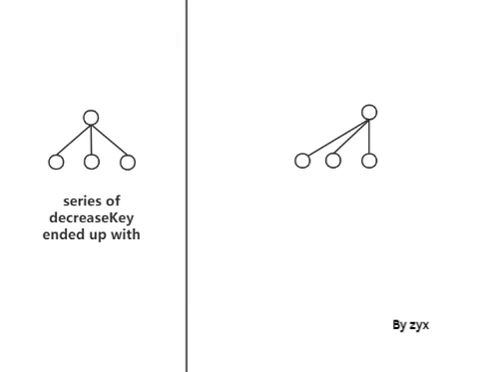
因为我们知道在对于 lazy binomial heap 的 extractMin 时进行 均摊复杂度分析时, O ( log n ) O(\log n) O(logn)是依赖于最终合并后 binomial tree n 个 nodes 最多有 O ( log n ) O(\log n) O(logn)棵树的。而此时,树的个数变成了 O ( n 1 2 ) O(n^{\frac{1} {2}}) O(n21). 这就很让人头大… O ( 1 ) O(1) O(1)的decreaseKey 是牺牲了 extractMin, O ( n 1 2 ) O(n^{\frac{1} {2}}) O(n21)为代价的。
Solution
解决的思路是增加限制重新使 nodes exponential 于 tree 的 rank.
Solution: Limit #cuts among the children of any node to 2.
依然用 root 的孩子数作为 rank,但同时限制任何一个 node 最多只能失去 一个孩子。当其失去第二个孩子时,它也同时被从它的父节点取下来,从而可能造成一连串的级联切割——cascading cut. 实现时,所有节点初始均未标记。当一节点失去一个孩子时,将其标记。当其失去第二个孩子时,同时将该节点取下,并解除其标记加回到 set 里。
下面用两种方法证明这种方法构造的树 nodes exponential 于 tree 的 rank.
数理证明
整体思路是证明上面 solution 所构造 order 为 k 的 tree,所包含的节点数为斐波那契数
f
k
+
2
f_{k+2}
fk+2.
首先回顾 Fibonacci 数列:
f
n
=
{
0
n
=
0
,
1
n
=
1
,
f
n
−
1
+
f
n
−
2
n
≥
2.
f_n=\begin{cases} 0& n=0,\\ 1 & n=1,\\ f_{n-1}+f_{n-2} & n\geq2. \end{cases}
fn=⎩⎪⎨⎪⎧01fn−1+fn−2n=0,n=1,n≥2.
其特征方程 z 2 − z − 1 = 0 z^2-z-1 = 0 z2−z−1=0 有两特征根 ϕ = 1 + 5 2 \phi = \frac{1+\sqrt{5}} {2} ϕ=21+5 和 ϕ ^ = 1 − 5 2 \hat{\phi} = \frac{1-\sqrt{5}} {2} ϕ^=21−5. 通项公式 f n = 1 5 ( ϕ n + ϕ ^ n ) f_n = \frac{1}{\sqrt{5}}(\phi^n+\hat{\phi}^n) fn=51(ϕn+ϕ^n)
Lemma 1. For all integers $ n \geq0$,
f
n
+
2
=
1
+
∑
i
=
0
n
f
i
f_{n+2} = 1+ \sum_{i=0}^{n}{f_i}
fn+2=1+∑i=0nfi
Proof by induction on
n
n
n.
Base case.
n
=
0
n = 0
n=0,
f
2
=
f
1
+
f
0
=
1
f_2 = f_1+f_0 = 1
f2=f1+f0=1 成立。
Induction Hypothesis:
f
k
+
2
=
1
+
∑
i
=
0
k
f
i
f_{k+2} = 1+\sum_{i=0}^k{f_i}
fk+2=1+∑i=0kfi for
0
≤
k
≤
n
−
1
0\leq k\leq n-1
0≤k≤n−1
To prove it holds for
k
=
n
k = n
k=n.
f
n
+
2
=
f
n
+
1
+
f
n
=
1
+
∑
i
=
0
n
−
1
f
i
+
f
n
=
1
+
∑
i
=
0
n
f
i
f_{n+2} = f_{n+1}+f_{n} =1+\sum_{i=0}^{n-1}{f_i} + f_n=1+\sum_{i=0}^{n}{f_i}
fn+2=fn+1+fn=1+∑i=0n−1fi+fn=1+∑i=0nfi, 成立。
然后是尝试建立指数关系。
Lemma 2. For all integers $ n \geq0$,
f
n
+
2
≥
ϕ
n
f_{n+2}\geq \phi^n
fn+2≥ϕn
Proof by induction on
n
n
n.
Base case.
f
2
=
1
=
ϕ
0
f_2 = 1 = \phi^0
f2=1=ϕ0,
f
3
=
2
≥
ϕ
1
f_3 = 2 \geq \phi^1
f3=2≥ϕ1
Induction Hypothesis:
f
k
+
2
≥
ϕ
k
f_{k+2} \geq \phi^k
fk+2≥ϕk for
0
≤
k
≤
n
−
1
0\leq k\leq n-1
0≤k≤n−1
To prove it holds for
k
=
n
k = n
k=n.
f
n
+
2
=
f
n
+
1
+
f
n
≥
ϕ
n
−
1
+
ϕ
n
−
2
=
(
ϕ
+
1
)
⋅
ϕ
n
−
2
=
ϕ
2
⋅
ϕ
n
−
2
=
ϕ
n
f_{n+2} = f_{n+1}+f_{n} \geq \phi^{n-1}+\phi^{n-2} = (\phi+1)\cdot \phi^{n-2} = \phi^2\cdot \phi^{n-2} = \phi^n
fn+2=fn+1+fn≥ϕn−1+ϕn−2=(ϕ+1)⋅ϕn−2=ϕ2⋅ϕn−2=ϕn, 成立。
然后是任何一个树内 node 的 rank 的限制。
Lemma 3. :Let
x
x
x be any node in a Fibonacci heap, and suppose that $ k = rank(x)$. Let
y
1
,
y
2
,
.
.
.
,
y
k
y_1, y_2,..., y_k
y1,y2,...,yk be the children of
x
x
x in the order in which they were linked to
x
x
x, from the earliest to the latest. Then
r
a
n
k
(
y
i
)
≥
max
(
0
,
i
−
2
)
rank(y_i) \geq \max(0,i-2)
rank(yi)≥max(0,i−2).
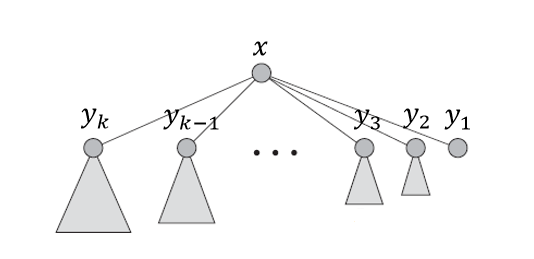
Proof. 显然
r
a
n
k
(
y
1
)
=
0
rank(y_1)=0
rank(y1)=0 成立。
对于
i
>
1
i>1
i>1的情况,当
y
i
y_i
yi 被 linked 到
x
x
x时(与
x
x
x合并),
y
1
,
y
2
,
.
.
.
,
y
i
−
1
y_1, y_2,..., y_{i-1}
y1,y2,...,yi−1已经 linked 到
x
x
x了,所以此时
r
a
n
k
(
x
)
=
i
−
1
rank(x) = i-1
rank(x)=i−1。那么因为只有对于同秩的 tree 才会合并,所以此时
r
a
n
k
(
y
i
)
=
r
a
n
k
(
x
)
=
i
−
1
rank(y_i) = rank(x) = i-1
rank(yi)=rank(x)=i−1.
因为此后
y
i
y_i
yi仍属于
x
x
x的孩子,所以其最多损失一个孩子,
r
a
n
k
(
y
i
)
≥
i
−
2
rank(y_i)\geq i-2
rank(yi)≥i−2, 证毕。
最后用前面的引理1, 2 和 3结合来证明 rank 与 节点数的关系。
Lemma 4. Let
z
z
z be any node in a Fibonacci heap with
n
=
s
i
z
e
(
z
)
n = size(z)
n=size(z) and
r
=
r
a
n
k
(
z
)
r = rank(z)
r=rank(z). Then
r
=
log
ϕ
n
r = \log_\phi n
r=logϕn.
Proof.
假设
S
k
S_k
Sk是斐波那契堆里任意 rank 为
k
k
k的节点,以其为根的树所包含的节点个数(size).
显然
S
0
=
1
,
S
1
=
2
S_0 = 1, S_1 = 2
S0=1,S1=2. 它们都不能失去任何孩子。
且对二者增加孩子,以构成
S
2
,
S
3
.
.
.
S_2, S_3...
S2,S3...只会使 nodes 个数增加,size 随 order 增加不会减少。
令
x
x
x是斐波那契堆里任意一点,其秩
r
=
r
a
n
k
(
x
)
r = rank(x)
r=rank(x), 节点个数
S
r
=
s
i
z
e
(
x
)
S_r = size(x)
Sr=size(x)
使用Lemma 3的假设和结论。令
x
x
x的孩子,按被 linked 的顺序为
y
1
,
y
2
,
.
.
.
,
y
k
y_1, y_2,..., y_k
y1,y2,...,yk.
那么就有
S
r
≥
1
+
∑
i
=
1
r
S
r
a
n
k
(
y
i
)
≥
1
+
∑
i
=
1
r
S
max
(
0
,
i
−
2
)
=
2
+
∑
i
=
2
r
S
i
−
2
S_r \geq 1+\sum_{i=1}^rS_{rank(y_i)} \geq 1+\sum_{i=1}^rS_{\max(0,i-2)} = 2 + \sum_{i=2}^rS_{i-2}
Sr≥1+∑i=1rSrank(yi)≥1+∑i=1rSmax(0,i−2)=2+∑i=2rSi−2
接下来证明 S r ≥ f r + 2 S_r \geq f_{r+2} Sr≥fr+2,对于所有 r ≥ 0 r\geq 0 r≥0。即 rank = r 的 tree 的 size, S r S_r Sr 大于等于斐波那契数, f r + 2 f_{r+2} fr+2。然后依据Lemma 2,由于 f r + 2 ≥ ϕ r f_{r+2}\geq \phi^r fr+2≥ϕr,所以 size 和 order(rank) 呈指数关系。
Proof by induction on
n
n
n.
Base case.
S
0
=
1
=
f
2
S_0 = 1 = f_2
S0=1=f2,
S
1
=
2
=
f
3
S_1 = 2 = f_3
S1=2=f3,成立。
Induction Hypothesis. It holds for
0
≤
k
≤
r
−
1
0\leq k \leq r-1
0≤k≤r−1 that
S
k
≥
f
k
+
2
S_k \geq f_{k+2}
Sk≥fk+2.
To prove it holds for
k
=
r
k = r
k=r. 使用
S
r
≥
2
+
∑
i
=
2
r
S
i
−
2
S_r \geq 2 + \sum_{i=2}^rS_{i-2}
Sr≥2+∑i=2rSi−2就可以用 Induction Hypothesis 了。
S
r
≥
2
+
∑
i
=
2
r
S
i
−
2
≥
2
+
∑
i
=
2
r
f
i
=
1
+
∑
i
=
1
r
f
i
=
f
r
+
2
S_r \geq 2+\sum_{i=2}^rS_{i-2} \geq 2+\sum_{i=2}^rf_i = 1+\sum_{i=1}^rf_i = f_{r+2}
Sr≥2+∑i=2rSi−2≥2+∑i=2rfi=1+∑i=1rfi=fr+2.
由此,我们推出了 n ≥ S r ≥ f r + 2 ≥ ϕ r n \geq S_r \geq f_{r+2} \geq \phi^r n≥Sr≥fr+2≥ϕr, ⟹ r = log ϕ n \implies r = \log_\phi n ⟹r=logϕn,nodes exponential 于 rank。
Maximally-Damaged Trees
上面那是石溪教材上的数理证明,下面是大S给出的更直观的证明。
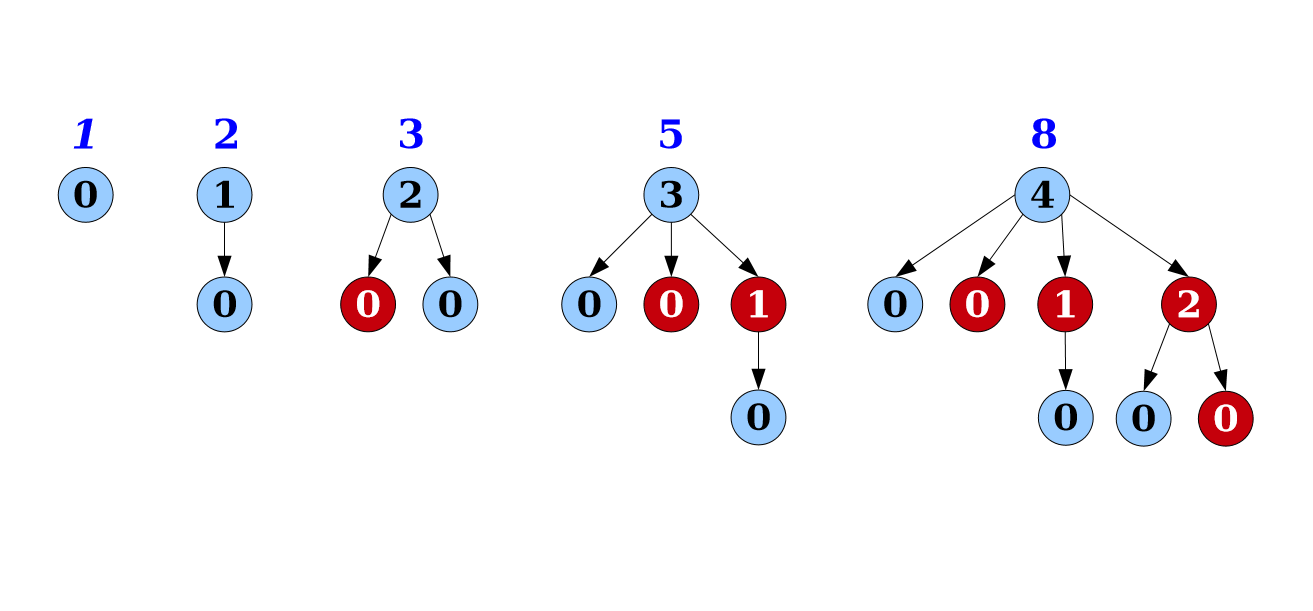
就是说我们对于一个 full 的 rank = k 的 binomial tree 去尝试截掉它所有不影响其 rank 的节点。这样就得到了斐波那契堆里 rank 为 k 的树的最少节点数——此时 tree 是 maximally damaged.
然后我们通过观察发现,这这些 minimum number 是 斐波那契数列—— order + 1 的 maximally damaged tree 就是 order - 2 的 tree 被 linked 到 order -1 的 tree上。而由数理归纳可知斐波那契数的增长是指数级的,所以 ↓ \downarrow ↓
claim: The minimum number of nodes in a tree of order k k k is F k + 2 F_{k+2} Fk+2. 殊途同归。
Proof by induction on rank.
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gBo0elkT-1592380015150)(https://upload-images.jianshu.io/upload_images/23517192-099ea0483b94eb70.png?imageMogr2/auto-orient/strip%7CimageView2/2/w/1240)]
Induction Hypothesis. for
0
≤
k
≤
n
0\leq k \leq n
0≤k≤n, order 为
k
k
k的树最少含有节点
F
k
+
2
.
F_{k+2}.
Fk+2.
To prove it holds for
k
=
n
k=n
k=n.
order =
k
k
k 的树的孩子的 order 为
0
,
0
,
1
,
.
.
.
,
k
−
2
0,0,1,...,k-2
0,0,1,...,k−2,这是由 maximally damaged trees 而来性质而来,它合并了 order =
k
−
1
k-1
k−1 和
k
−
2
k-2
k−2 的maximally damaged tree.
而 order =
k
+
1
k+1
k+1 的树,则由 order =
k
k
k 和
k
−
1
k-1
k−1 合并,如图。
根据 IH, order = k − 1 k-1 k−1 的树节点数 ≥ F k + 1 \geq F_{k+1} ≥Fk+1, order = k k k树节点数 ≥ F k + 2 \geq F_{k+2} ≥Fk+2,则二者合并 order = k + 1 k+1 k+1 的树节点数 = F k + 1 + F k + 2 = F k + 3 =F_{k+1}+F_{k+2} = F_{k+3} =Fk+1+Fk+2=Fk+3, it holds for k + 1 k+1 k+1.
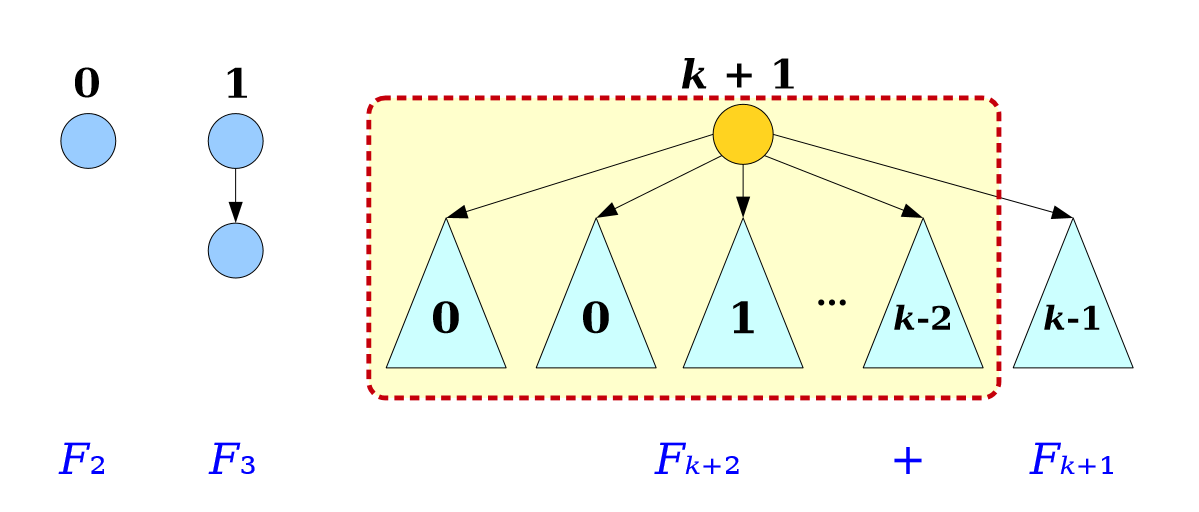
Amortized analysis
decreaseKey
**首先是 decreaseKey 的复杂度。**尽管我们希望能把它优化到
O
(
1
)
O(1)
O(1),可以自从限制了 cut 次数以后,就可能出现级联 cut 的情况。如图:
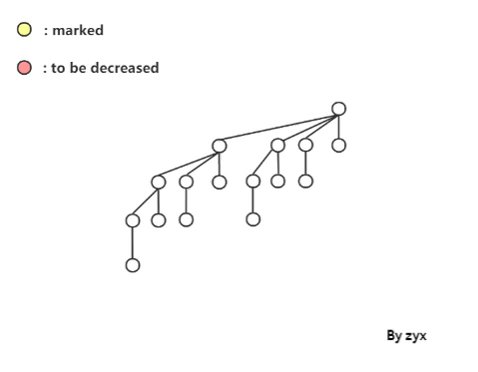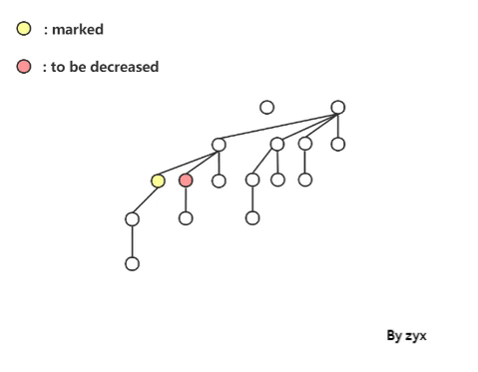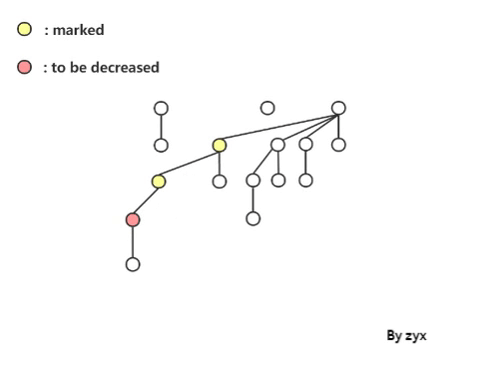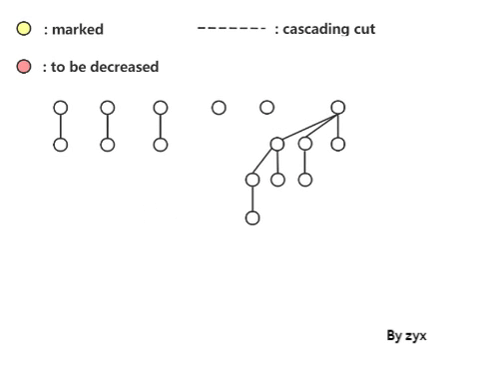
这样worst-case 的复杂度就变成了 O ( log n ) O(\log n) O(logn),一串 cut 取决于树高。 下面使用 potential method 来看一下 decreaseKey 的均摊复杂度。
先观察,对于 k k k次级联 cut 的 decreaseKey 会使 tree 的个数增加 k k k,不能再令 Φ = \Phi = Φ= # of trees。而在 trees 增加的同时,每一次级联 cut 都会还原一个 marked node。不妨令 Φ = t + 2 m \Phi = t + 2m Φ=t+2m, t t t是 trees 的个数, m m m是 marked nodes 的个数。
这里之所以采用 t + 2 m t+2m t+2m,是考虑 t + m t+m t+m的话,减少的 mark nodes 知识 刚刚好抵消掉 tree的增加,而还要对 actual cost 进行抵消,所以考虑用 Φ = t + 2 m \Phi = t+2m Φ=t+2m.
假设某次 decreaseKey 开始前,# of mark nodes =
m
m
m,# of trees =
t
t
t.
Φ
b
e
f
o
r
e
=
t
+
2
m
\Phi_{before} = t+2m
Φbefore=t+2m
操作进行了
k
k
k次级联 cut。actual cost =
1
+
k
1+k
1+k
新增 trees
1
+
k
1+k
1+k, mark nodes
1
−
k
1-k
1−k. 因为
k
k
k次级联 cut 后,必新增 1 mark node.
Δ
Φ
=
3
−
k
\Delta \Phi = 3-k
ΔΦ=3−k,
T
a
m
o
r
t
i
z
e
d
(
d
e
c
r
e
a
s
e
K
e
y
)
=
1
+
k
+
C
⋅
(
3
−
k
)
=
O
(
1
)
T_{amortized}(decreaseKey) = 1+k + C\cdot (3-k) = O(1)
Tamortized(decreaseKey)=1+k+C⋅(3−k)=O(1)
由此可知我们确实把 decreaseKey 的均摊复杂度降到了 O ( 1 ) . O(1). O(1). 期待 Dijkstra的更好性能吧!
extractMin
**extractMin的复杂度。**只分析均摊复杂度就够了,worst-case 如 lazy binomial heap。
extractMin 之前,# of mark nodes = m m m,# of trees = t t t. Φ b e f o r e = t + 2 m \Phi_{before} = t+2m Φbefore=t+2m
- 通过***min***指针找到 min, remove min 新增 trees O ( log n ) O(\log n) O(logn),再 add back 的 actual cost O ( log n ) O(\log n) O(logn)。
- coalesce step: trees 变为
O
(
log
n
)
O(\log n)
O(logn), actual cost =
O
(
t
+
log
n
)
O(t+\log n)
O(t+logn)
- 先创建 order box, actual cost = O ( log n ) O(\log n) O(logn)
- 再按 order 分配并合并。trees 变为 O ( log n ) O(\log n) O(logn), actual cost = O ( t ) O(t) O(t)
- update min 指针, O ( log n ) O(\log n) O(logn).
自始至终 mark nodes 个数都不会改变。
Δ
Φ
=
−
t
+
log
n
\Delta \Phi = -t + \log n
ΔΦ=−t+logn, actual cost =
O
(
t
+
log
n
)
O(t+\log n)
O(t+logn),
T
a
m
o
r
t
i
z
e
d
(
e
x
t
r
a
c
t
M
i
n
)
=
−
t
+
log
n
+
O
(
t
+
log
n
)
=
O
(
log
n
)
T_{amortized}(extractMin) = -t + \log n + O(t+\log n) = O(\log n)
Tamortized(extractMin)=−t+logn+O(t+logn)=O(logn)
分析跟 lazy binomial heap 的 extractMin 完全一致(依赖于 exponential 关系)。
delete
**delete 的复杂度。**前面说斐波那契堆支持更高效的 decreaseKey 和 delete,delete的复杂度?
d
e
l
e
t
e
(
H
,
x
)
delete(H,x)
delete(H,x) 可以看作是 首先
d
e
c
r
e
a
s
e
K
e
y
(
H
,
x
,
−
∞
)
decreaseKey(H,x,-\infty)
decreaseKey(H,x,−∞), 再去
e
x
t
r
a
c
t
M
i
n
(
H
)
extractMin(H)
extractMin(H).
所以其均摊复杂度,
T
a
m
o
r
t
i
z
e
d
(
d
e
l
e
t
e
)
=
O
(
1
)
+
O
(
log
n
)
=
O
(
log
n
)
T_{amortized}(delete) = O(1)+O(\log n) = O(\log n)
Tamortized(delete)=O(1)+O(logn)=O(logn)
其实没什么提升,lazy binomial heap 中 delete 也是 O ( log n ) O(\log n) O(logn) 的均摊复杂度。
where are we now
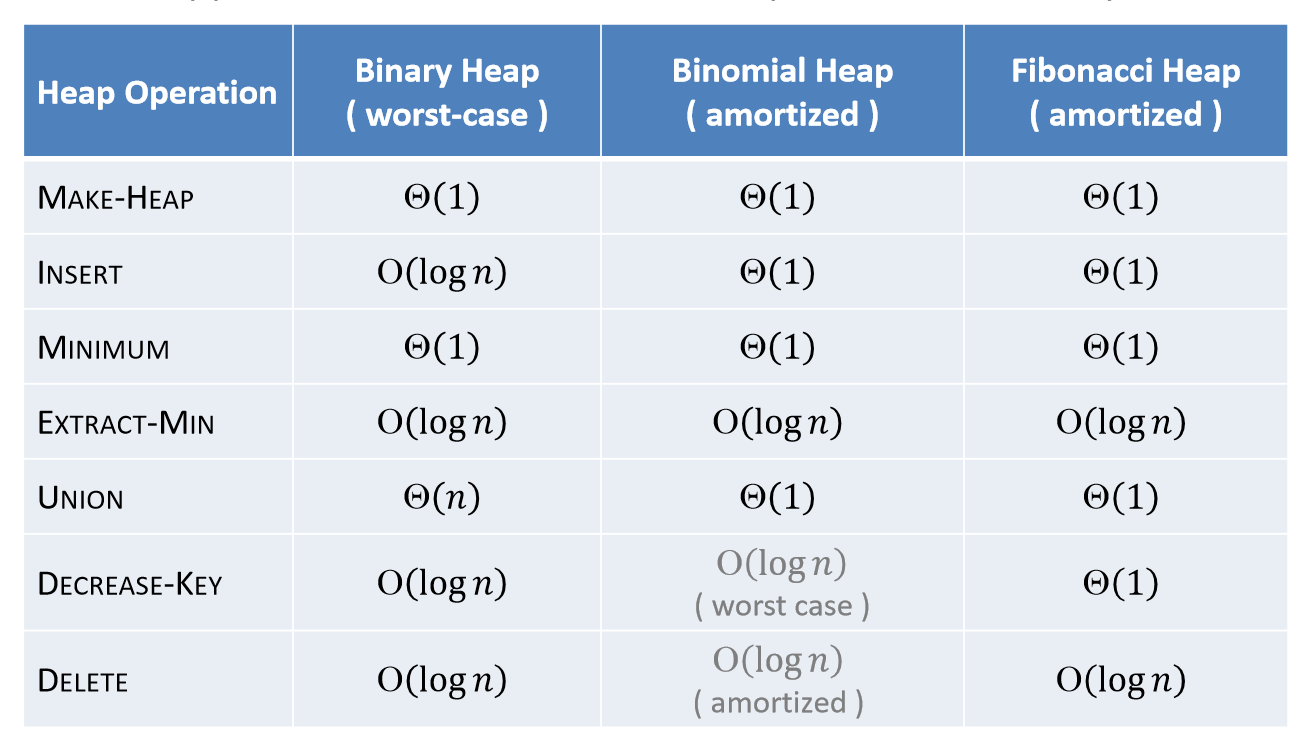
拿到了这样的“神器”,Fibonacci heap 实现的优先队列来解决单源点最短路径问题能否起飞呢?
representation problem
回顾开局那张 decreaseKey 的图,其实细节上有些错误。因为要把 一个节点从其父节点的link中取下来,必然得找到父节点。那 parent 和 child 之间就必须得是双向的 link。如图:

但是这样仍会有问题。试想上图中 decrease D 的 key。
- 拿到 D 就找到了 A。找到 A 后,就先抹掉 D 指向 A 的 link, O ( 1 ) O(1) O(1).
- 剩下只需要把 A 指向 D 的 link 删掉,D 就彻底被移除了,然而找到 A-D link O ( log n ) . O(\log n). O(logn).
这就很尴尬,因为我们想要 O ( 1 ) O(1) O(1)来解决这其中的所有 link.
tricky solution:

一个 node 的所有 children (即 siblings 之间),形成一个双向循环链表,并且这些 children 都存一个 指向其 parent 的指针。parent 随便存一个 “代表”孩子。
现在来试一下 decrease D 的 key。
首先 D 找到 A,发现 D 不是“代表”孩子,既然不代表那就该死死去。nothing changes.
D 顾左右,C-D link
→
\rightarrow
→E,E-D link
→
\rightarrow
→C. 把自己扣出来,铁锅炖自己,放到 A 旁边,
O
(
1
)
O(1)
O(1)。
而如果要 decreaseKey 的是“代表”孩子,那 只需 A 的指针随便指向“代表”孩子的兄弟就好了。
小节
至此所有堆知识的进阶(graduate)都讲完了。Binary 本身已经是非常简洁高效的数据结构了。后面的 binomial heap 及其他都是在一定应用场景下诞生的更为高效的数据结构。
看起来 Fibonacci heap 无限美好。但回答之前能否起飞的问题——很大概率不能。
因为一个node 存了太多东西了:
- A pointer to its parent.
- A pointer to the next sibling.
- A pointer to the previous sibling.
- A pointer to an arbitrary child.
- A bit for whether it’s marked.
- Its order.
- Its key.
- Its element
这些 constant factors 让斐波那契堆实现的优先队列在实际过程中速度不及其它的堆。除非,在一些非常非常大的图上,或者在需要 "tons of d e c r e a s e K e y decreaseKey decreaseKey操作"的网络流问题上。
但理论上 Fibonacci heaps 还是值得去了解的:
- 首先是分析时使用了 two-tiered potential method——老千层饼了。
- 再一个是这种 decreaseKey 的思路值得去借鉴。
- 最后是给 dijkstra 单源点最短路径 和 prim 最小生成树问题给出了理论上的 optimal 边界。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









