







一、前言
最近在看DeepLearning这本书,看到了正则化这一章做一个知识梳理。首先用一张思维导图做个总结。
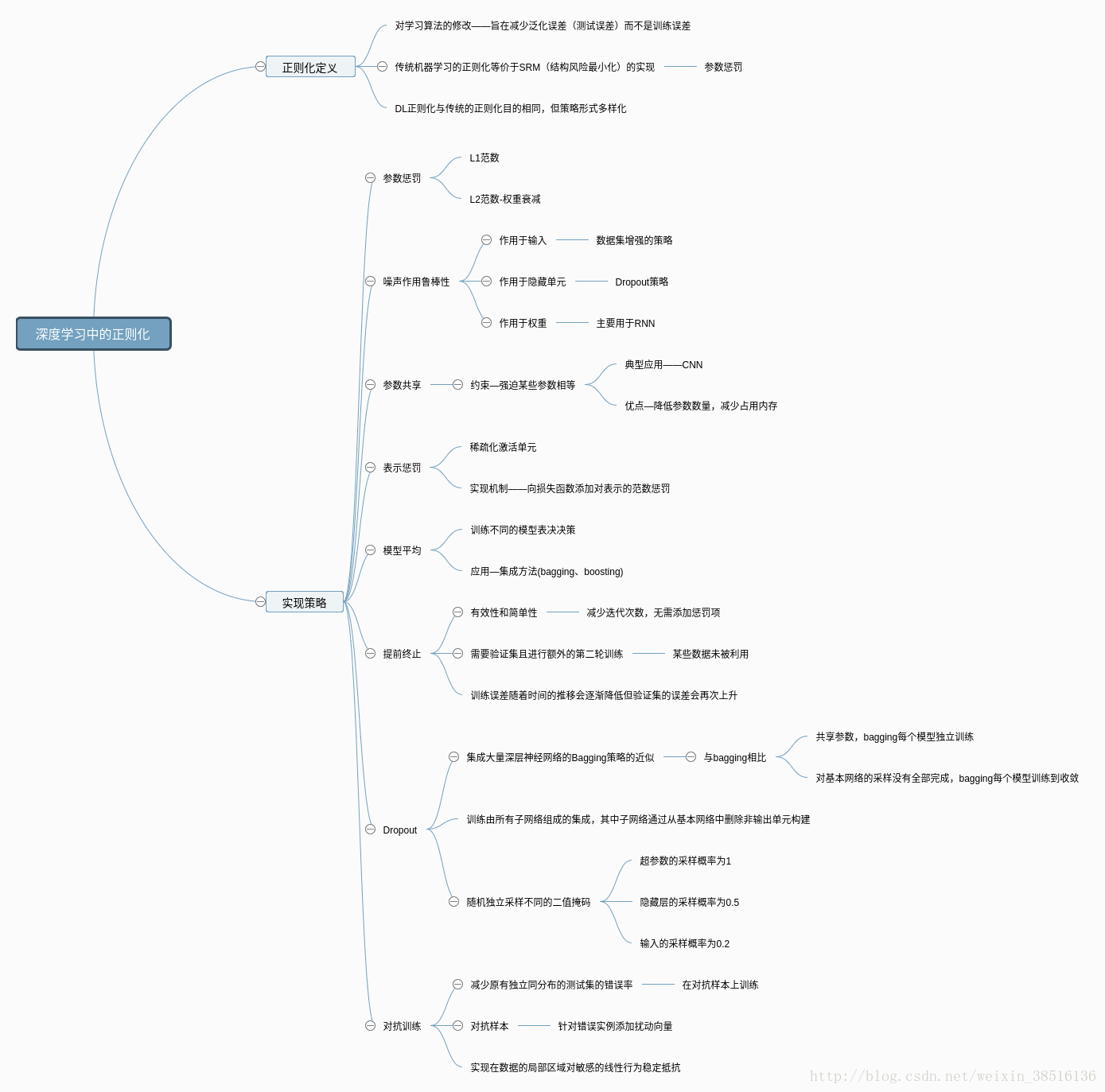
二、传统机器学习中的正则化及相关概念
- 泛化
学习方法对未知数据的预测能力。
- 决定机器学习算法效果(泛化能力)的因素:
1.降低训练误差——解决欠拟合问题
2.缩小训练误差和测试误差的差距——解决过拟合问题
3.一个好的机器学习算法是避免了过拟合同时也避免了欠拟合… - 机器学习和纯优化不同的地方在于也希望泛化误差(测试误差)较小。
- 决定机器学习算法效果(泛化能力)的因素:
- 过拟合

- 表现:对已知数据预测的很好,对未知数据预测的很差,测试误差和训练误差之间的差距太大。
- 原因:一味追求提高对训练数据的预测能力,所选模型的复杂度往往会比真模型更高。
- 正则化
- ERM与SRM(经验风险最小化和结构风险最小化)
模型关于训练集的平均损失称为经验风险-ER(EL-经验损失)。
样本容量过小,ERM—>过拟合。
SRM——>防止过拟合——>SRM等价于ERM+正则化。 - 正则化是结构风险最小化策略的实现,是在经验风险上加一个正则化项(regularizer)或惩罚项(penalty term)。regularizer一般是模型复杂度的单调递增函数,模型越复杂,regularizer越大。
- ERM与SRM(经验风险最小化和结构风险最小化)
三、深度学习中的正则化
1.参数范数惩罚
- L2 参数正则化
即传统机器学习里的权重衰减(weight decay),也被称为L2 参数范数惩罚,正则项Ω(θ) = 12∥w∥∥2 1 2 ∥ w ∥ 2 。
主要目的是解决过拟合,具体的实现是让权值往更小的方向缩减(这样说比较笼统,后续用泰勒展开说明L1、L2背后的数学原理)。 - L1 参数正则化
正则项Ω(θ) =∥w∥1=∑||wi|| =∥ w ∥ 1 = ∑ | | w i | | 。
L1正则化最主要的作用是模型稀疏化(即它的权值矩阵有很多0),从而可以用来做特征选择。
2.噪声作用鲁棒性
- 作用于输入——数据集增强的策略
有时候添加方差极小的噪声等价于对权重施加范数惩罚。 - 作用于隐藏单元——Dropout
- 作用于权重——主要用于RNN
- 作用于输出目标——显示对标签上的噪声进行建模。
其中标签平滑的优势是能够防止模型追求确切概率而不影响模型学习正确分类。
3.提前终止
- 基本思路
训练误差随着时间的推移会逐渐降低但验证集的误差会再次上升。从而只要返回使验证集误差最低的参数设置,可以获得验证集误差更低的模型(有希望获得更好的测试误差)。
深度学习中最常用的正则化形式——有效性和简单性,减少计算成本(减少迭代次数,无需添加惩罚项)。 - 提前终止需要验证集,结果是某些训练数据未被利用。
为了利用额外的数据,进行额外的第二轮训练。两种策略:
1.再次初始化模型,使用第一轮提前终止训练确定的最佳步数。
2.保持第一轮训练获得的参数,使用全部的数据继续训练
4.参数共享
- 基本概念
参数范数惩罚是正则化参数使其彼此接近。而使用约束—强迫某些参数相等更为流行。这种正则化方法被称为参数共享。一个显著优点:降低参数数量,减少模型占用的内存。 - CNN是参数共享的典型应用,将领域知识有效整合到网络架构。
- RNNs中的权值共享(循环结构)也是这个策略的实现。
5.稀疏表示
- 惩罚神经网络中的激活单元,稀疏化激活单元,这种策略间接对模型参数施加了复杂惩罚。
- 表示的正则化可以使用参数正则化同种类型的机制实现。向损失函数添加对表示的范数惩罚。
6.模型平均
- 主要想法-Voting
训练几个不同的模型,让所有模型表决决策。奏效的原因是不同的模型通常不会在测试集产生完全相同的误差。 - 采用模型平均策略的技术被称为集成方法(bagging和 boosting)。
- 模型平均是一个减少泛化误差的非常强大可靠的方法。
7.Dropout
- 基本概念
Dropout训练由所有子网络组成的集成,其中子网络通过从基本网络中删除非输出单元构建。一般构建的子网络个数为2的指数级。 - 在第一种近似下,Dropout可以被认为是集成大量深层神经网络的实用Bagging方法。与Bagging不同的是:
- Bagging所有模型独立,而Dropout所有模型共享参数,每个模型参数是父神经网络参数的不同子集。
- Bagging每一个模型都训练到收敛,而Dropout实际训练时,对基本网络(父神经网络)的采样基本不可能全部完成,取而代之,单步训练小部分的子网络,利用参数共享设定剩余子网络的参数。
- 具体来说,训练中实用Dropout时,使用基于小批量产生较小步长的学习算法(SGD等)。随机抽样(独立采样)应用 于网络中所有输入和隐藏单元的不同二值(0,1)掩码。通常超参数的采样概率为 1,隐藏层的采样概率通常为 0.5,输入的采样概率通常为 0.8。
Dropout做预测时,因为指数级子网络的原因,通常采用的方法:
1.平均许多掩码的输出(10-20个掩码)。
2.集成成员的几何平均代替算术平均。
- 更近一步的观点
Dropout不仅仅是训练一个Bagging的集成模型,并且是共享隐藏单元的集成模型。
Dropout强大的大部分原因是作用于隐藏单元的掩码噪声。可以看做是对输入内容的信息高度智能化、自适应破坏的一种形式,而不是对输入原始值的破坏。另一方面,噪声是乘性的。
8.对抗训练
- 基本概念
通过对抗训练减少原有独立同分布的测试集的错误率—在对抗扰动的训练集样本上训练网络。实现在数据的局部区域对敏感的线性行为稳定(引入局部恒定先验)。 - 对抗训练有助于体现积极正则化与大型函数族结合的力量。
- 对抗样本—添加扰动的向量(针对错误实例)。
- 过度线性。
- 提供了一种实现半监督学习的方法。















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









