







 本文综述了基于语义和社会经济特征的城市场景理解,强调从高分辨率遥感到多源地理数据集的转变,特别是朱祺祺和钟燕飞团队的研究。介绍了多模态遥感数据集在土地覆盖分类中的应用,以及利用注意力融合网络进行超高分辨率遥感图像语义分割的方法。此外,涵盖了摄影测量和遥感中的多模态学习,关注信息传输与多模态场景分析的基石。
本文综述了基于语义和社会经济特征的城市场景理解,强调从高分辨率遥感到多源地理数据集的转变,特别是朱祺祺和钟燕飞团队的研究。介绍了多模态遥感数据集在土地覆盖分类中的应用,以及利用注意力融合网络进行超高分辨率遥感图像语义分割的方法。此外,涵盖了摄影测量和遥感中的多模态学习,关注信息传输与多模态场景分析的基石。
ISPRS Journal 期刊论文2021年6月-9月
- Urban scene understanding based on semantic and socioeconomic features: From high-resolution remote sensing imagery to multi-source geographic datasets 基于语义和社会经济特征的城市场景理解:从高分辨率遥感影像到多源地理数据集
- Multimodal remote sensing benchmark datasets for land cover classification with a shared and specific feature learning model 具有共享和特定特征学习模型的用于土地覆盖分类的多模态遥感基准数据集
- An attention-fused network for semantic segmentation of very-high-resolution remote sensing imagery用于超高分辨率遥感图像语义分割的注意力融合网络
- Muti-modal learning in photogrammetry and remote sensing 摄影测量和遥感中的多模态学习
- Juggling with representations: On the information transfer between imagery, point clouds, and meshes for multi-modal semantics处理表示:关于多模态语义的图像、点云和网格之间的信息传输
Urban scene understanding based on semantic and socioeconomic features: From high-resolution remote sensing imagery to multi-source geographic datasets 基于语义和社会经济特征的城市场景理解:从高分辨率遥感影像到多源地理数据集
地大武汉朱祺祺老师团队,钟燕飞老师
1.关键点
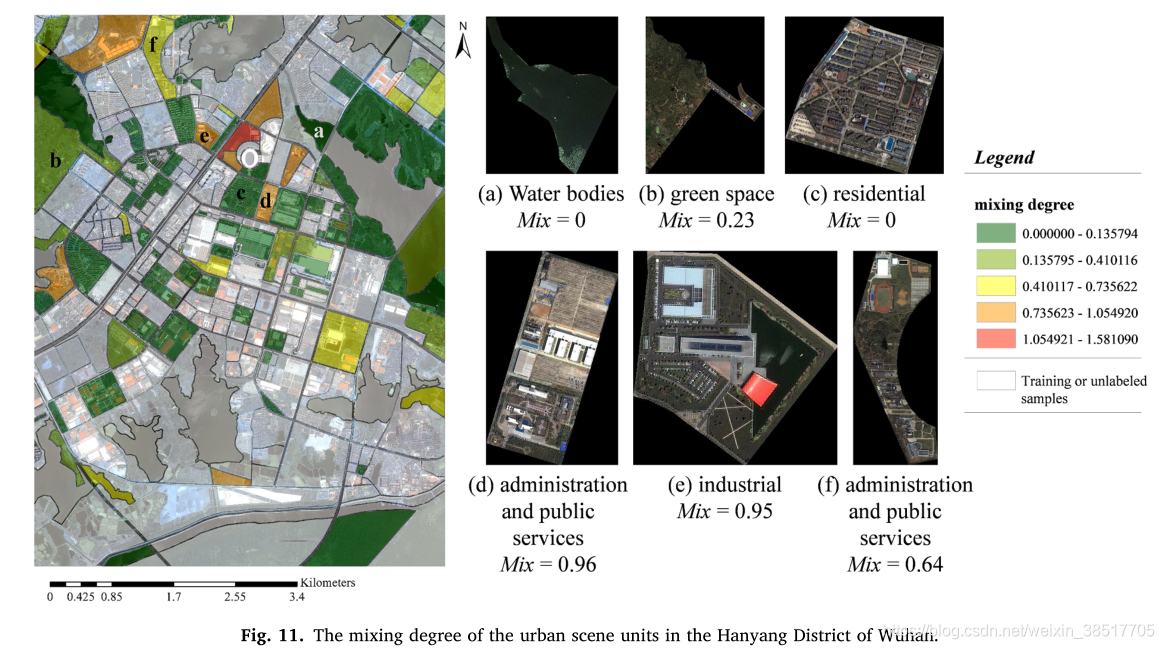
城市场景理解,其实有点像是在做功能区了。所谓社会经济数据是指POI数据,语义来自于遥感影像,基本分析单元则是来自路网和水道划分的网格。在做功能区划分上都算是一些比较传统的做法了,这里做的更细致的部分其实在我标黄的摘要里,大致思路是迭代更新分析单元的采样点/候选点。
里面的制图都很漂亮
2.摘要
场景分类是一种解释高分辨率遥感(HRS)图像,获取高层语义信息的手段,可为城市规划和监测提供可靠的参考。传统的基于 HRS 影像的场景分类方法以均匀的网格单元为场景单元,从而遗漏了地理边界并导致镶嵌效果。因此,在本文中,城市场景被定义为以道路网络为边界的地理单元。城市场景理解的任务是识别城市场景的社会经济或自然语义。然而,由于城市环境的复杂性,传统的场景分类方法在应用于城市场景时存在三个问题,其有效性受到限制:1)HRS图像中缺乏社会经济信息,难以区分具有相似外观的不同城市场景。 2)城市地块大小和形状差异较大,影响场景特征提取和表示。 3)可以嵌入各种场景分类模型的城市场景理解框架很少被研究。针对这些问题,本文提出了一种基于多源地理数据(USUMG)的通用城市场景理解框架。在 USUMG 框架中,来自 OpenStreetMap (OSM) 的道路网络和水道数据用于生成城市场景单元。对于每个不规则单元,采用基于形态骨架的场景分解方法,通过统一处理的补丁来表示城市场景单元。为了整合不同的数据源,融合了从 HRS 图像中提取的高级语义特征和从兴趣点 (POI) 数据中提取的社会经济特征来确定城市场景类别。最后,在中国武汉和澳门市区对具有多种场景分类方法的 USUMG 框架进行了测试,以验证所提出框架的通用性和可行性。本文提供的实验性能作为基于多源地理数据的城市场景理解的基准。
3.网络结构
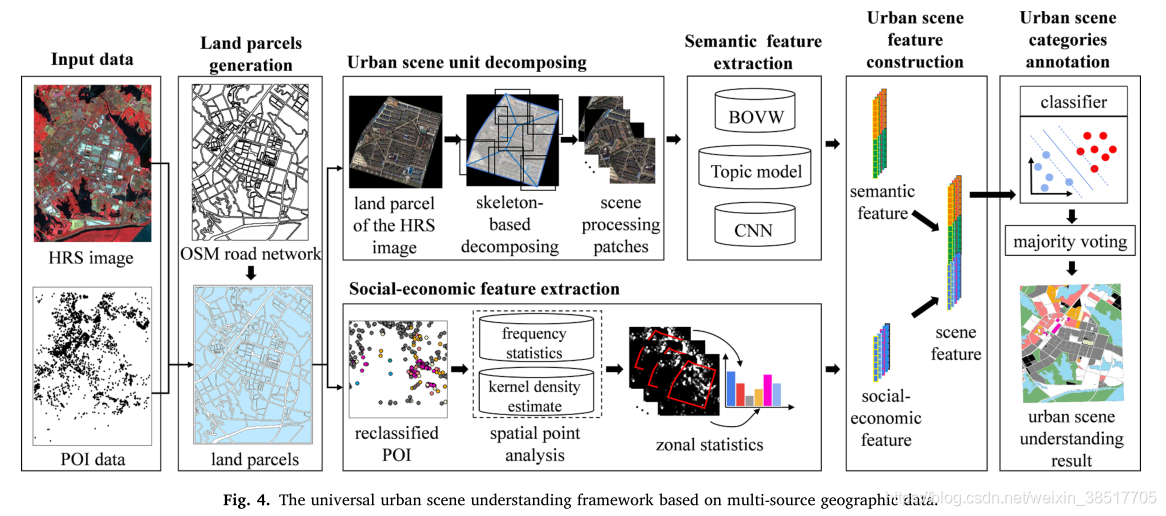
3.制图很好看,值得参考
Multimodal remote sensing benchmark datasets for land cover classification with a shared and specific feature learning model 具有共享和特定特征学习模型的用于土地覆盖分类的多模态遥感基准数据集
1.关键点
提出了一个新的数据集,方法也很值得借鉴,多模态用的很不错。
代码开源: https://github.com/danfenghong/ISPRS_S2FL
多模态的精髓主要在不同模态数据的特征提取、特征对齐、特征融合(互补)、特征协同等。
2. 摘要
随着从不同传感器获得的遥感 (RS) 数据大量公开可用,多模态数据处理和分析技术在 RS 和地球科学界引起了越来越大的兴趣。然而,由于不同模式在成像传感器、分辨率和内容方面的差距,将它们的互补信息嵌入到一致、紧凑、准确和有区别的表示中在很大程度上仍然具有挑战性。为此,我们提出了一个共享和特定的特征学习(S2FL)模型。 S2FL 能够将多模态 RS 数据分解为模态共享和模态特定的组件,从而更有效地实现多模态的信息融合,特别是对于异构数据源。此外,为了更好地评估多模态基线和新提出的 S2FL 模型,三个多模态 RS 基准数据集,即 Houston2013 – 高光谱和多光谱数据,Berlin – 高光谱和合成孔径雷达 (SAR) 数据,Augsburg – 高光谱、SAR 和数字表面模型 (DSM) 数据被发布并用于土地覆盖分类。在三个数据集上进行的大量实验证明了我们的 S2FL 模型在土地覆盖分类任务中的优越性和进步性,与之前提出的最先进的基线相比…
3.方法架构
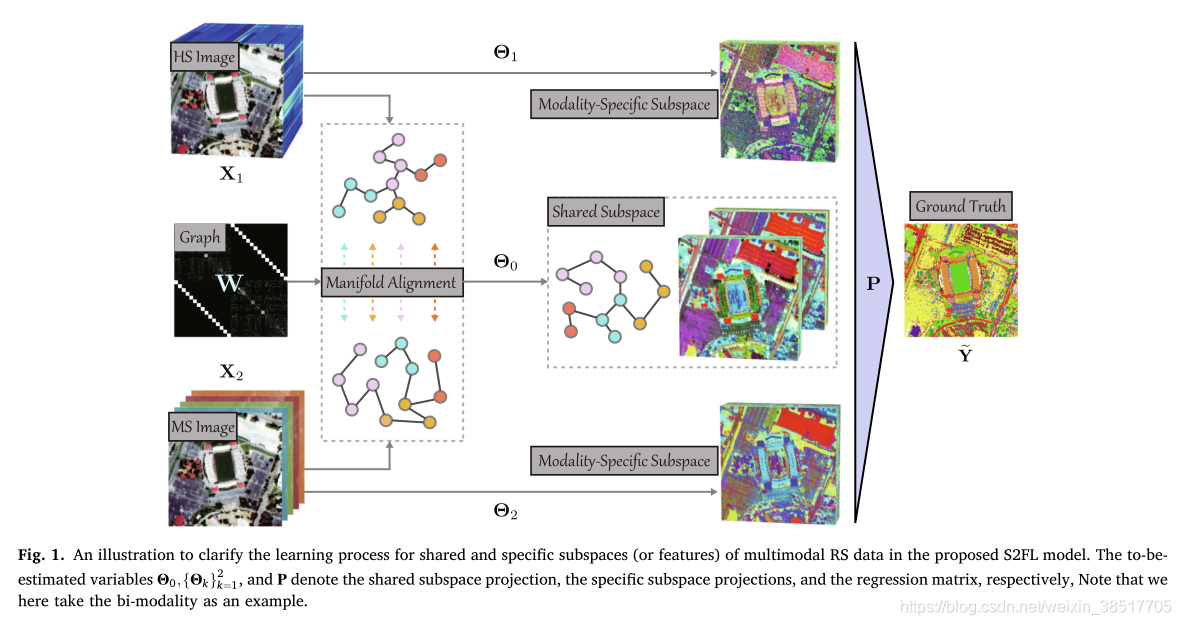
共享特征也就是不同模态共享/对齐的特征,然后互补使用。
An attention-fused network for semantic segmentation of very-high-resolution remote sensing imagery用于超高分辨率遥感图像语义分割的注意力融合网络
好像是空天院张兵老师那边的文章,不太熟悉那边
1.关键点
看第三部分网络结构,使用了DSM辅助数据
2.摘要
义分割是深度学习的重要组成部分。近年来,随着遥感大数据的发展,语义分割越来越多地应用于遥感中。深度卷积神经网络(DCNNs)面临特征融合的挑战:超高分辨率遥感图像多源数据融合可以增加网络的可学习信息,有利于DCNNs正确分类目标对象;同时,高级抽象特征和低级空间特征的融合可以提高目标对象边界处的分类精度。在本文中,我们提出了一个多路径编码器结构来提取多路径输入的特征,一个多路径注意力融合块模块来融合多路径特征,以及一个细化注意力融合块模块来融合高级抽象特征和低级空间特征。 .此外,我们提出了一种新颖的卷积神经网络架构,称为注意力融合网络(AFNet)。基于我们的 AFNet,我们在 ISPRS Vaihingen 2D 数据集上以 91.7% 的整体准确度和 90.96% 的平均 F1 分数以及 92.1% 的整体准确度和 93.44 的平均 F1 分数实现了最先进的性能% 在 ISPRS Potsdam 2D 数据集上。
3. 网络结构
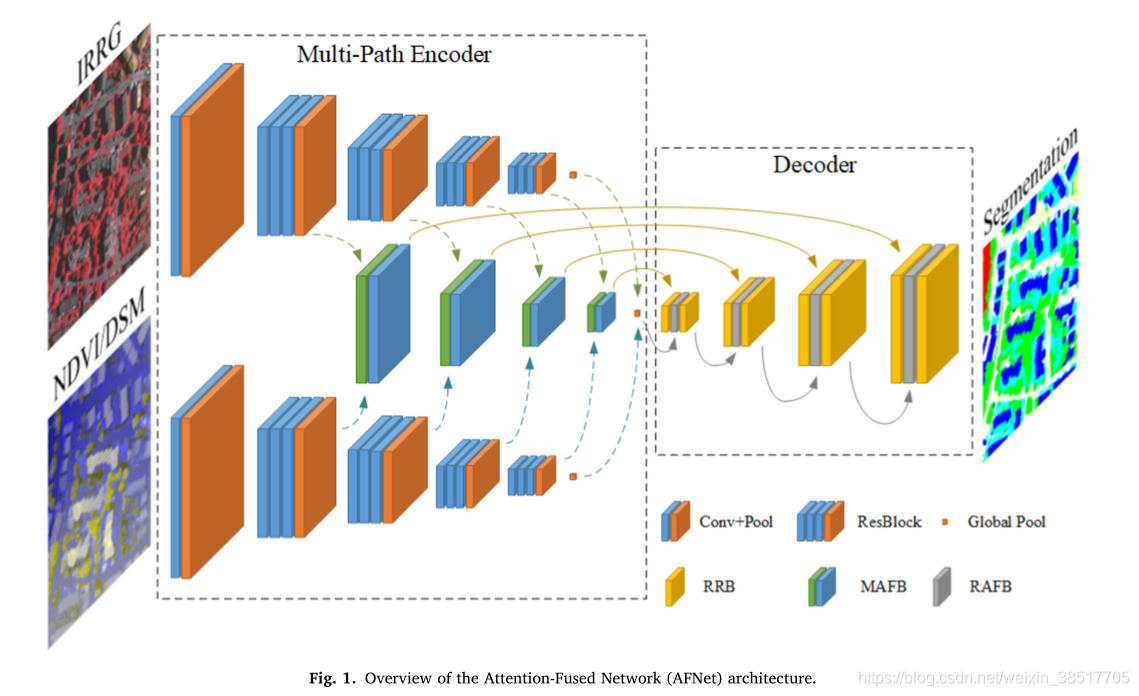
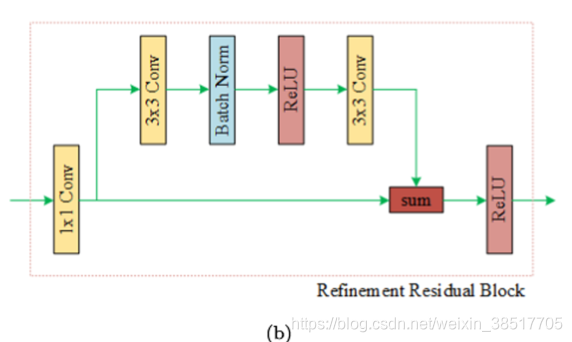
PRB模块,细化残差模块。
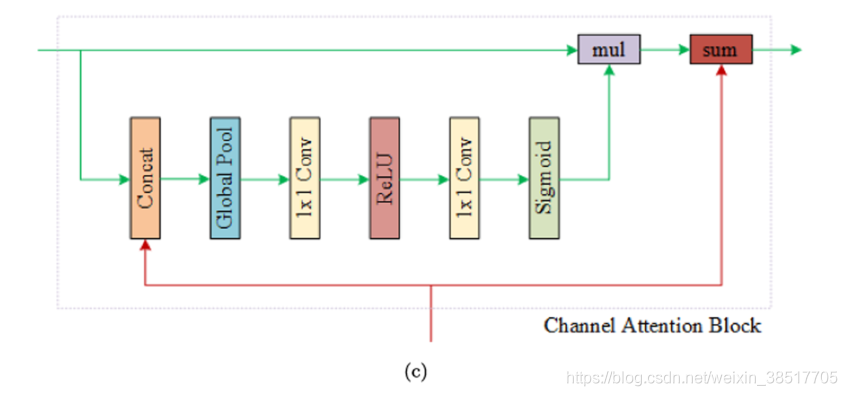
CAB模块,通道注意力模块
Muti-modal learning in photogrammetry and remote sensing 摄影测量和遥感中的多模态学习
一篇简单的社论。
1.全文
摄影测量和遥感界对多模态数据越来越感兴趣,即。例如,通过不同的传感器(例如雷达、光学、激光雷达)从各种平台(包括卫星、飞机、UAS/UGS、自动驾驶汽车等)同时获取数据。由于它们不同的空间、光谱或时间分辨率,互补数据源的使用导致更丰富和更强大的信息提取。我们预计未来多种模式的使用将迅速成为一种标准方法。联合处理多模态数据的主要困难在于模态之间的结构差异。另一个问题是跨模态可用的标记样本数量不平衡,导致单独训练模型时性能存在显着差异。显然,摄影测量和遥感界尚未充分利用多模态数据的潜力。神经网络似乎非常适合适应不同的数据源,这要归功于它们以端到端的方式学习适应每个任务的表示的能力。在这种情况下,迫切需要研究和开发地理空间领域内的多传感器和多模态深度学习方法。本主题刊收录了九篇论文,报告了摄影测量和遥感中多模态深度学习领域的最新进展和趋势。多模态深度学习方法的优势在超分辨率(Zhang et al., 2020; Zhang and Ma, 2021)、场景补全(Xia et al., 2021; Zheng et al., 2021)等应用中得到展示、语义分割(Hong 等人,2020 年;Laupheimer 和 Haala,2021 年)、大气校正(Sun 等人,2021 年)、图像匹配(Hughes 等人,2020 年)和 3D 重建(Xiang 等人,2020 年) )。所提出的方法还推广了多种方法,例如神经网络剪枝(Xiang 等人,2020)、注意力机制(Zhang 等人,2020 年)、残差学习网络(Zhang 和 Ma,2021 年)以及交叉模态学习网络(Hong 等人,2020 年)。该论文集还证实了摄影测量和遥感界近期趋势的流行:从多传感器数据中理解场景、多模态数据生成、源联合注册以及联合定位异构数据集的开发。我们希望这个主题问题将鼓励 ISPRS 社区在多模态深度学习方面的进一步工作。特别是,我们指出了未来研究的两个令人鼓舞的方向:(1)开发多样化的学习方案,例如跨模态学习和半/自监督学习,以及(2)创建大规模多传感器数据集以定量评估新方法。
2.引用

Juggling with representations: On the information transfer between imagery, point clouds, and meshes for multi-modal semantics处理表示:关于多模态语义的图像、点云和网格之间的信息传输
1.关键点
正如题目中所说的,主要研究的是图像、点云和格网数据的信息传输问题。3D语义分割问题。
做的工作非常有意义,也很深入。特别是对3D标签的转移也很值得参考。
2.摘要
近十年来,对获取的海量遥感数据进行自动语义分割已成为一项重要任务。图像和点云(PC)是基本的数据表示,特别是在城市制图应用中。带纹理的3D网格通过连接PC和使用可用图像对表面元素进行纹理处理,以几何方式集成了这两种数据表示形式。我们提出了一种以网格为中心的整体几何驱动方法,显式地集成了图像、PC和网格实体。由于网格的综合性,我们选择网格作为核心表示,这也有助于解决图像中点的可见性问题。利用所提出的多模态融合作为主干,并考虑到已建立的实体关系,我们能够以两种方式在模态图像、PC和Mesh之间共享信息:(I)特征转移和(Ii)标签转移。通过这些方法,我们实现了将每个表示的特征向量丰富为多模态特征向量。同时,我们实现了对所有表示进行一致的标记,同时将手动标记的工作量减少到单个表示。因此,我们便于训练机器学习算法,并在语义上分割这些数据表示中的任何一个-无论是在多模态意义上还是在单模态意义上。本文介绍了多模态场景分析的关联机制和后续的信息传递,认为这是多模态场景分析的基石。此外,我们还详细讨论了该方法的前提条件和局限性。我们在ISPRS 3D语义标签竞赛(Vaihingen 3D)和专有数据集(Hessigheim 3D)上展示了我们的方法的有效性。
3.结论
了联合利用图像和 ALS 数据进行语义场景分析,我们提出了一种新颖的整体方法,通过作为核心表示的网格显式地集成图像和 PC 数据。多模态数据融合建立了点、面和像素的显式连接,并实现了跨模态的任意信息的后续共享。信息传输通过聚合合并已建立的一对多关系。因此,表示特定的特征和(手动)注释可以在所有模态中一次性共享(参见表 2)。因此,所提出的关联机制可以看作是一个集成器,兼具标记工具和特征共享工具的功能。通过这些方式,这种新颖的方法可以作为一个强大的集成主干来促进多模态学习。特别是,该方法强调了其在像素级 GT 生成中的实用性。任何标记的 3D 数据(PC 或网格)都可以投影到图像空间中,以便在执行可见性检查时同时注释多个图像。因此,它最大限度地减少了手动标记工作。因此,信息传输的通用性促进了特定模态和多模态语义分割。链接机制旨在通过自适应阈值来克服现实世界数据的缺陷。分块并行处理旨在在内存和速度之间进行权衡。我们通过部署两个不同分辨率和尺度的机载数据集,定性和定量地证明了其对基础数据的有效性和适应性。 V3D 是典型的大规模全国制图,具有几厘米的中等 GSD,ALS 和图像数据收集之间有相当大的时间偏移。 H3D 提供极高分辨率的数据,主要是从混合传感器系统同步捕获数据,代表了小规模复杂建筑区域的数据收集。由于缺乏多模态 GT,对所提出的方法进行严格的定量分析很困难。作为替代方案,我们通过标签在不同模态实体之间的前向后向传递来分析 PC 上的标签一致性。定量分析表明,已建立的连接几乎 100% 是一致的。但是,链接到公共面的不同类的点可能对后续语义驱动的重新网格化很有用。由于结构差异,实体之间的完全关联是不可能的。我们详细讨论了先决条件和局限性,突出了高质量联合注册和高质量重建的好处。我们方法的优势在于其简单性和灵活性,可立即从数据采集、联合配准和网格划分方面的进步中获益。未来,我们的目标是利用混合条带调整(Glira 等人,2019 年)对 ALS 数据和图像进行像素精确的联合配准。我们声称改进的联合注册改进了几何重建和语义分析。为了证明我们的假设,我们通过分析 ML 分类器的性能,计划对不同表示上的多模态特征进行消融研究。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









