







文章目录
Linux内存管理第二章 – Describing Physical Memory
首先来描述几个名词:
- NUMA:Non-Uniform Memory Access即内存非一致性访问.在很多巨星机上内存被分成了多个区域,CPU访问不同的内存区域耗费的时间是不同的.但在同一区域内,CPU访问这些内存的时间是一致的。
- UMA:Uniform Memory Access即内存一致性访问,即所CPU访问所有内存的耗时都是一致的。
- node:NUMA架构下的每一个内存区域称作是node,node用struct pglist_data来描述。所有的node在Linux内核中用一个全局链表pgdat_list关联起来,pg_data_t->pgdat_next指向下一个区域。
- zone:每一个node下面的内存又被划分为多个小区域,每个区域称作是zone.zone一般分为三个:ZONE_DMA,ZONE_NORMAL,ZONE_HIGHMEM.Linux中使用struct zone来描述一个zone。
- page:Linux内核对每一个物理内存页框的描述。
node和zone的关系如下图:
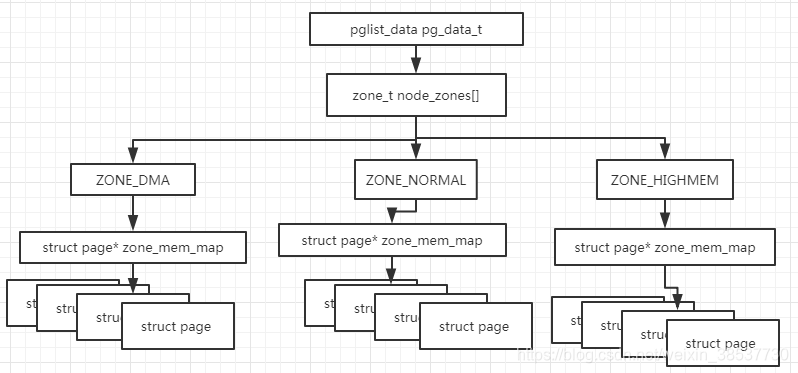
Nodes
Linux内核中每一个node由struct pglist_data来进行描述。其定义如下<include/linux/mmzone.h>,下面来介绍下主要成员的作用。
typedef struct pglist_data {
struct zone node_zones[MAX_NR_ZONES];
struct zonelist node_zonelists[GFP_ZONETYPES];
int nr_zones;
struct page *node_mem_map;
struct bootmem_data *bdata;
unsigned long node_start_pfn;
unsigned long node_present_pages; /* total number of physical pages */
unsigned long node_spanned_pages; /* total size of physical page range, including holes */
int node_id;
struct pglist_data *pgdat_next;
wait_queue_head_t kswapd_wait;
struct task_struct *kswapd;
} pg_data_t;
- node_zones:当前node中的zones:ZONE_DMA,ZONE_NORMAL,ZONE_HIGHMEM
- node_zonelists:该数组决定了当前node中分配物理内存时,选择zone的顺序.该数组的初始化由mm/page_alloc.c中的build_zonelists()来完成。build_zonelists()由free_area_init_core()调用触发。一般状况下当从ZONE_HIGHMEM中分配内存失败时,会再尝试从ZONE_NORMAL或者ZONE_DMA中分配。
- node_mem_map:该指针表示当前node中的物理页框数字中的第一个页框描述符struct page的地址。在内核中有些地方也可以直接使用全局数组mem_map来访问获取node的第一个page地址,实现node_mem_map相同的功能。
- node_start_paddr:当前node的物理地址的起始地址。该字段类型是一个unsigned long型,有的时候可能会超长,一个比较好的颁发是在此字段中中记录物理页框号(Page Frame Number,PFN)。PFN = page_phys_addr >> PAGE_SHIFT
- node_start_mapnr:当前node中起始物理地址在全局数组mem_map中的偏移。
- node_size:当前node中page的总数。
系统中维护的所有node都在一个全局列表pgdat_list中。该list由init_bootmem_core()函数初始化。
Zones
Linux内核中每一个zone由struct zone结构来描述。该结构主要使用来统计page的使用和释放信息。其定义如下,接下来再看下重点成员:
struct zone {
spinlock_t lock;
unsigned long free_pages;
unsigned long pages_min, pages_low, pages_high;
unsigned long protection[MAX_NR_ZONES];
ZONE_PADDING(_pad1_)
spinlock_t lru_lock;
struct list_head active_list;
struct list_head inactive_list;
unsigned long nr_scan_active;
unsigned long nr_scan_inactive;
unsigned long nr_active;
unsigned long nr_inactive;
int all_unreclaimable; /* All pages pinned */
unsigned long pages_scanned; /* since last reclaim */
ZONE_PADDING(_pad2_)
int temp_priority;
int prev_priority;
struct free_area free_area[MAX_ORDER];
wait_queue_head_t * wait_table;
unsigned long wait_table_size;
unsigned long wait_table_bits;
ZONE_PADDING(_pad3_)
struct per_cpu_pageset pageset[NR_CPUS];
struct pglist_data *zone_pgdat;
struct page *zone_mem_map;
/* zone_start_pfn == zone_start_paddr >> PAGE_SHIFT */
unsigned long zone_start_pfn;
char *name;
unsigned long spanned_pages; /* total size, including holes */
unsigned long present_pages; /* amount of memory (excluding holes) */
};
- free_pages:当前zone中free page的总个数
- pages_min,pages_low,page_high:该zone中的水位线,具体在下一小节进行说明。
- free_area:buddy allocator使用的free area bitmaps
- wait_table:等待某个page被释放的进程的等待队列链表。这个队列对于wait_on_page()和unlock_page()函数来说非常重要。
- wait_table_size:wait_table中等待队列的个数。
- wait_table_bits:wait_table_size == (1 << wait_table_bits)
- zone_pgdat:指向当前zone所属的node
- zone_mem_map:当前zone中的第一个page的地址,该page输入全局数组mem_map
- size:当前zone中pages 的个数
Zone初始化
当内核的页表有page_init()建立好之后,就开会初始化zone。每种硬件架构执行zone初始化的时候可能稍有不同,但是最终目标是相同的。每种架构初始化zone的流程中的最终目标是决定传入什么参数值到UMA架构的初始化函数free_area_init()或者NUMA架构的初始化函数free_area_init_node()中。下面来看下参数的含义:
void __init free_area_init_node(int nid, struct pglist_data *pgdat,
unsigned long *zones_size, unsigned long node_start_pfn,
unsigned long *zholes_size)
{
............
}
- nid:要被初始化的zone所属的node的逻辑标识符。
- pgdat:要被初始化成zone的node
- zones_size:包含每个zone的page的个数的数组
- node_start_pfn:当前node的起始PFN
- zholes_size:包含每个zone中memory holes的个数的数组。
无论是free_area_init()还是free_area_init_node()都会调用free_area_init_core()来真正初始化每个struct zone中的成员。在做zone初始化的时候,系统无法知道每个zone中有多少可用的page,这些信息知道boot memory allocator退休之后才会知道。
mem_map初始化
mem_map是在系统启动阶段被创建。在NUMA系统中,全局数组mem_map被当做是一个虚拟的数组其起始位置为PAGE_OFFSET(一般就是指虚拟地址3G的位置)。系统中的每个node初始化的过程中调用free_area_init_node()来为这个虚拟数组分配填充mem_map的一部分内容。而在UMA系统中,因为只有一个node,所以其node为全局变量contig_page_data,而全局变量mem_map就是这个contig_page_data中的ode_mem_map。
对于UMA架构来说,核心函数free_area_core()将为当前初始化的node分配一个本地的lmem_map,lmem_map是从boot memory allocator中使用alloc_bootmem_node()来进行分配。该新分配的lmem_map将会成为全局的mem_map。但NUMA系统中与此有稍微不同。
对于NUMA架构来说,核心函数free_area_core()将从node节点自己的内存中分配lmem_map,而全部变量mem_map不会显式的分配,而是将其设定为PAGE_OFFSET的虚拟地址上,其被当做是一个虚拟的数组。而lmem_map被存储在node中的node_mem_map,pg_data_t->node_mem_map,其在虚拟数组mem_map的某个位置上。当node和zone被初始化完整之后,mem_map将会被当成一个真正的数组了。
Pages
page定义
系统中的每一个物理页框都有一个相应地struct page,其用来持续跟踪物理页框的状态。其定义如下:
struct page {
page_flags_t flags; /* Atomic flags, some possibly updated asynchronously */
atomic_t _count; /* Usage count, see below. */
atomic_t _mapcount; /* Count of ptes mapped in mms,to show when page is mapped & limit reverse map searches.
unsigned long private; /* Mapping-private opaque data:usually used for buffer_heads if PagePrivate set;
/* used for swp_entry_t if PageSwapCache */
struct address_space *mapping; /* If low bit clear, points to inode address_space, or NULL.
* If page mapped as anonymous memory, low bit is set, and it points to anon_vma object:
* see PAGE_MAPPING_ANON below.*/
pgoff_t index; /* Our offset within mapping. */
struct list_head lru;/* Pageout list, eg. active_list protected by zone->lru_lock !*/
/* On machines where all RAM is mapped into kernel address space,
* we can simply calculate the virtual address. On machines with
* highmem some memory is mapped into kernel virtual memory
* dynamically, so we need a place to store that address.
* Note that this field could be 16 bits on x86 ... ;)
*
* Architectures with slow multiplication can define
* WANT_PAGE_VIRTUAL in asm/page.h
*/
#if defined(WANT_PAGE_VIRTUAL)
void *virtual; /* Kernel virtual address (NULL if not kmapped, ie. highmem) */
#endif /* WANT_PAGE_VIRTUAL */
};
- mapping:当文件或者设备有内存映射,那么文件的inode中有一个成员address_space,如果该page属于这个文件那么mapping字段将指向这个address_space。
- lru:根据page的替换策略,active_list或者inactive_list中的pages都可能被换出。该字段是active_list或者inacvtive_list的头。
- virtual:通常来讲只有ZONE_NORMAL中的物理内存才会被内核直接映射到虚拟地址空间,而ZONE_HIGHMEM中的物理内存需要调用kmap()来讲物理地址转成虚拟地址,通常只有固定数目的pages被kmap()转换,如果当前page被kmap映射了,则virtual字段记录它的虚拟地址。
- index:mapping中偏移。
- flags:该字段表示描述page状态的标志位
- count:当前page正在被使用的次数。当count为0时,该page可能被释放。只要大于0,那么当前被一个或者多个进程或者内核在使用中。
| bit名称 | 描述 |
|---|---|
| PG_active | 当一个page在avtive_list LRU中时,该bit被置位。从active_list LRU中被删除时,该bit被清零。该bit标记page当前的热度 |
| PG_arch_1 | 该bit位依据不同的架构而不同的page状态位。通常当一个page第一次整体进入page cache的时候该位被清零 |
| PG_checked | 仅仅被Ext2文件系统使用 |
| PG_dirty | 该标记位1时表示该page需要被刷新到磁盘上。磁盘文件对应的page被写后不会立即刷新到磁盘,该bit为来保证dirty page在刷新之前不被释放 |
| PG_error | 在磁盘IO过程中发生错误,该bit为被置位 |
| PG_fs_1 | 该bit位保留给文件系统自己用。当前只有NFS用该bit位来表示当前page是否同远端server同步 |
| PG_highmem | 高端内存的pages不能被kernel直接映射,因此在mem_init()的时候high memory page该bit位被置位 |
| PG_launder | 系统一般会先将该bit置位然后再调用writepage()函数,当系统想换出一个page,在扫描时如果发现一个page的该bit为被置位且PG_locked被置位,则系统会等待IO完成。 |
| PG_locked | 当进行磁盘IO时该bit为必须置位,IO完成,该bit为清零 |
| PG_lru | 如果一个page在active_list或者inactive_list中时,该bit为置位 |
| PG_referenced | 当一个page被映射并且通过映射或者哈希表有访问,则该bit为置位,其主要用作LRU list更新过程中。 |
| PG_slab | 如果page正在被slab allocator使用,该bit为置位 |
| PG_skip | 某些架构中用该bit为来标记跳过虚拟地址空间中没有对应物理内存的部分 |
| PG_unused | 该标记位目前没有使用 |
| PG_uptodate | 当一个page从磁盘中读入内容时没有报错,该bit为置位 |
映射 Pages 到 Zones
在kernel2.4中,struct page中有个struct zone的指针,用来表示page输入哪个zone,这是一种相当浪费的行为。因为当有几千个page的时候,这一个小小的指针也会耗费很多的memory。在kernel2.6中,struct page中的zone字段被删除了,取而代之的是使用page->flags中的高ZONE_SHIFT(x86下是8)位来决定page属于哪个zone。
首先创建一个zone_table,mm/page_alloc.c:
/*
* Used by page_zone() to look up the address of the struct zone whose
* id is encoded in the upper bits of page->flags
*/
struct zone *zone_table[1 << (ZONES_SHIFT + NODES_SHIFT)];
EXPORT_SYMBOL(zone_table);
然后调用set_page_zone设置zone的ID。
static inline void set_page_zone(struct page *page, unsigned long nodezone_num)
{
page->flags &= ~(~0UL << NODEZONE_SHIFT);
page->flags |= nodezone_num << NODEZONE_SHIFT;
}
高端内存–High Memory
为什么要支持高端内存?
因为kernel所能使用的虚拟地址空间是有限的(一般只ZONE_NORMAL)。所以kernel需要支持High Memory的概念。在x86 32位系统中,对于高端内存来说有两个阈值:4GB,64GB
4GB:因为物理地址是32位,最大4GB。所以虚拟地址也是32位即虚拟地址空间是0 ~~ 4GB。由于内核只能使用虚拟地址3G ~ 4G这一个G的虚拟地址,而这一个G的虚拟地址大部分被kernel从ZONE_NORMAL和ZONE_DMA直接线性映射所占用,如果系统想要访问更多的物理内存就得从ZONE_HIGMEM中获取物理页框再调用kmap()将其映射到虚拟地址空间,从而让高端物理内存可以。
64GB:Intel发明了PAE技术(Page Address Extension)让32位系统可以使用更多的物理内存。即
2
36
2^{36}
236 = 64GB
PAE理论上让处理器可以访问64GB物理内存,但是实际上32位Linux系统中的进程无法访问那么多物理内存因为虚拟地址空间仍然是4GB。
再者来说,PAE不允许内核自己使用如此多的内存。一个struct page占用44字节,而struct page所占用的的虚拟内从空间是在内核可用的虚拟地址空间内。因此描述1GB的物理内存,所需要的struct page就要占用11MB的虚拟地址空间,16GB的物理内存描述就要占用176MB的虚拟地址空间,这会使得内核所使用的虚拟地址空间更加紧张。
因此在32位系统中要访问更多的物理内存,就得内核就得支持高端内存的概念。
所谓高端内存就是指将内核现行映射完成之后还有多余的物理内存,通过动态映射的方式将物理地址转换为虚拟地址,从而使得这部分物理地址可用。这也仅仅是临时可用,一个进程也不能一次malloc 3G以上的内存使用。
高端内存具体如何使用?
例如socket中的buffer就是使用高端内存,比如网络上来了大量数据,内核先调用kmap()将一些page映射成虚拟地址,然后将网络数据copy到物理内存,然后调用kunmap()解除这段虚拟地址到物理地址的映射,此时内核记录的是struct page的地址来描述这些buff在哪里。
当上层应用要读取socket的数据的时候,kernel再次调用kmap()将之前存放网络数据的page再次映射成虚拟地址,让上层应用将这些数据copy出去。














 4851
4851











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









