







大家好,我是后来,我会分享我在学习和工作中遇到的点滴,希望有机会我的某篇文章能够对你有所帮助,所有的文章都会在公众号首发,欢迎大家关注我的公众号" 后来X大数据 ",感谢你的支持与认可。
前几天写的计算机网络的网络层在csdn阅读量快破5000了,也给我带来了不少的粉丝,还是非常开心的,给了我写文很大的动力。在这里看一下:
警察叔叔顺着网线是怎么找到你的?计算机网络(四)之网络层未完待续
最近公司越来越多的业务要用到Flink,我也正好把知识点再复习下,做到学以致用,哈哈,而且前几天看到Flink1.11版本都开始支持hive流处理了,还是比较兴奋的。因为自己关于Flink的经验也不是很多,所以我就再以小白的身份写个Flink学习专栏。各位大佬不喜勿喷。
写完基本知识,也会夹杂着工作实例,算是给自己做个笔记。希望某篇文章能对你有所帮助。
强烈建议:阅读官网!
我学习一个新技术的步骤大概是这样的:
- 先了解这个技术要解决什么问题
- 简单上手体验一下,找找自信心
- 学习架构,知晓原理
- 学习API,体验高级玩法
- 搞个小项目上手,学以致用。
1、Flink大致介绍
关于实时处理与离线处理,一个很大的不同就在于,数据是不是有界的。
- 有界流:数据有终点,比如要对一个txt文本做wordCount。
- 无界流:数据有起点,没有终点,比如说是从socket 端口拿数据计算wordCount,可以无休止的产生数据。
而在实时处理方面,又有Flink和Spark Streaming,那么他俩最大的区别就是Flink是真正的流处理,而spark Streaming是微批次处理。
- Flink可以以事件为单位,来一条数据就处理一条(可以,不是只能,flink也可以 以时间窗口为单位进行计算,大家不要误解)
- Spark Streaming是以一个窗口为单位,一次处理一批
当然flink也可以擅长做批处理,只不过现在flink代表的更多的是实时处理。
1.1 Flink的组件栈有哪些?

这些组件可以先大概知道有这么回事,然后后续的学习中一点点理解就记住了。
图中也能知道:
- 运行模式大致分为3种,本地、集群、云
- DataStream API流处理
- DataSet API批处理
- 上层还支持CEP、SQL、机器学习ML、图计算。
2、Flink初体验
还是先在IDE中来一个WordCount吧。这个先直接复制了,跑起来我们再来分析其中的东西。
这个代码是scala代码写的,关于建项目和导入scala框架这个大家百度吧。
import org.apache.Flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment}
import org.apache.Flink.streaming.api.scala._
/**
* @description: WordCount小入门
* @author: Liu Jun Jun
* @create: 2020-06-04 10:10
**/
object WordCount {
def main(args: Array[String]): Unit = {
//获取环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//从客户端获取流式数据
val wordDS: DataStream[String] = env.socketTextStream("bigdata101",3456)
//对数据进行转换,按照单词分组,最后求和
val resultDS = wordDS.map((_,1)).keyBy(_._1).sum(1)
//对结果进行打印
resultDS.print("ceshi:")
//真正的执行命令,前面这些都是懒加载的,只有在遇到execute才会触发执行
env.execute("wordCount")
}
}
测试——在linux系统中用netcat命令进行发送测试。没有nc 的可以安装一下
(yum -y install nc)
nc -lk 3456
然后自己写点单词,控制台看输出结果:
结果展示:

在这个测试案例中,我们已经体验到了Flink的流式处理。
结果展示中,前面的数字代表的当前这个任务跑在我的哪个cpu上,我这个电脑是4个cpu,默认使用全部资源,所以它自己选择执行。当然你会发现later这个单词总在cpu4上。
好了,那就继续往下走,我们刚只是在IDE中体验了一把,但是我们实际生产中还是要打包放在集群上跑的。
那么接下里我们在集群上部署一下Flink
3、Flink安装
说到Flink的集群安装,就有几种模式。本地模式一般也就是自学用,所以这里就暂时不安装了。来看看集群部署。
- Standalone模式:这种模式下的Flink使用自己的资源管理及任务调度,不依赖于hadoop,目前使用的不是很多。
- yarn模式:这种模式的话,Flink更像是一个客户端,做了一个计算引擎,把任务提交到yarn,由yarn来进行资源的分配以及任务的调度。但计算使用的是Flink引擎。使用的比较多。
以上两种方式,根据公司需求不同选择不同。我在这里主要讲一下yarn模式
根据官网介绍:
如果你计划将 Apache Flink 与 Apache Hadoop 一起使用(在 YARN 上运行 Flink ,连接到 HDFS ,连接到 HBase 等),则需要下载好Flink后,把hadoop组件放在Flink的lib目录下,这个在官网有说明,如果官网没提供你的hadoop版本,那就需要自己编译了。

我这里直接提供一个Flink1.7.2版本集成好hadoop依赖的包,直接解压部署就可以了。
解压值需要配置web页面地址,当然不配置跑任务也没有问题。 链接在我的微信公众号【后来X大数据】,回复”flink“就可以直接下载。
yarn模式也有2种类型:
- Session-Cluster
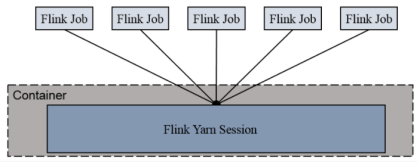
这种模式就是在启动hadoop集群后,先申请一块空间,也就是启动yarn-session,以后所有提交的任务都在这块空间内执行。相当于是承包商。不如下面的方式灵活。 - Per-Job-Cluster
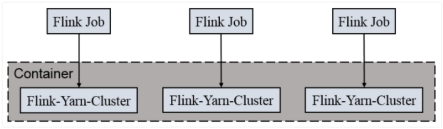
这个则是每次提交一个Flink任务,都会单独的只申请自己所需要的空间,组成flink集群,任务执行完就注销掉。任务之间互相独立,互不影响,方便管理。
很明显,第二种方式对资源的利用更加灵活。
那么接下来我们提交个任务看看。我们就用官方的WordCount测试包吧。自己写个文件,里面随便写点单词。
bin/flink run -m yarn-cluster -yn 7 -ys 2 -p 14 -ytm 2048m -yjm 2048m -yqu Flink ./examples/batch/WordCount.jar --input /opt/wc.txt --output /opt/output4/
bin/Flink 后面其实可以指定很多参数,大家可以bin/Flink --help查看一下
-m 指定任务运行模式
-yqu 指定提交任务的队列
-n(–container):TaskManager的数量。
-s(–slots): 每个TaskManager的slot数量,默认一个slot一个core,默认每个taskmanager的slot的个数为1,有时可以多一些taskmanager,做冗余。
-jm:JobManager的内存(单位MB)。
-tm:每个taskmanager的内存(单位MB)。
-nm:yarn 的appName(现在yarn的ui上的名字)。
-d:后台执行。
那一看命令这么多参数,那我们平时怎么提交任务就会方便一些呢?一般情况下我们写成脚本执行。
提交任务后可以在yarn上看到这个任务,通过Application,可以进入webUI页面,我们可以看到这个任务的流程图。(这个图我完了补上,写文的电脑上没装集群)
4、Flink架构
通过上述的介绍,其实对Flink已经有了初步的认识。那我们来初步理解一下Flink的架构,前期只需要大致理解就可以了,更多的理解还是要基于使用,毕竟实践出真知!
4.1 Flink在运行时会包含这几种主要的角色:
- Job Managers:提交的这个任务的老大,管理Flink集群中从节点TaskManager
- Task Managers:单个任务的管理者,负责管理其所在节点上的资源信息,如内存、磁盘、网络,在启动的时候将资源的状态向JobManager汇报
- Resource Manager:集群资源的管理者
- Clients:提交作业的机器
上面提到的是任务在运行中有哪些具体的角色,那么广义上来说,Flink在这里充当的角色更多的是一个客户端,用来提交job。
4.2Flink on yarn时,提交任务的流程就如下图所示:

- Flink提交后,Client向HDFS上传Flink的Jar包和配置
- Client给RM提交任务
- RM分配资源并通知选中的对应的NodeManager,启动ApplicationMaster来作为这个任务所有资源的老大,进行管理。
- ApplicationMaster启动后加载Flink的Jar包和配置构建环境,然后启动JobManager
- AM向RM申请资源启动TaskManager,AM分配资源以后,AM就通知资源所在的节点的NodeManager启动TaskManager
- NodeManager加载Flink的Jar包和配置构建环境并启动TaskManager,TaskManager启动后向JobManager发送心跳包,并等待JobManager向其分配任务。
4.3那么Flink任务是怎么资源调度的?
我们来跟着官网的思路走一下:
- 我们的每一个TaskManager都是一个JVM进程,这么理解吧,TaskManager启动在NodeManager所在的节点,就等于说是一个节点一个TaskManager。
- 这个JVM进程可以在不同的线程中执行一个或多个 subtasks(子任务),那肯定啊,一个节点同时执行很多个子任务。但是同时执行的子任务过多,是不是会抢占资源比较严重,那么几个会比较合理呢?
- 在Flink中有个插槽的概念,slot: TaskManager 的一份固定资源子集。目前仅仅用来隔离task的内存,例如,具有三个 slots 的 TaskManager 会将其管理的内存资源分成三等份给每个 slot。这样做的好处就是划分到不同slot的子任务集不会再抢占别的slot资源。
- 但是问题是:这样也不公平,比如2个需要资源相差很大的子任务划分到了不同的slot中,会出现需要资源小的任务早就跑完了,而另一个需要资源多的任务却迟迟跑不完。所以,Flink 允许 subtasks 共享 slots,即使它们是不同 tasks 的 subtasks,只要它们来自同一个 job。这样的好处是:
(1)需要资源少的子任务可以划分到一个slot,而需要资源多的可以单独划分到一个slot,可以充分利用slot资源,同时确保繁重的 subtask 在 TaskManagers 之间公平地获取资源。
(2)Flink 的并行度只要控制好合理的slot数就可以了,因为每个slot都是一个线程。这样不需要计算作业总共包含多少个 tasks。

根据经验,合理的 slots 数量应该和 CPU 核数相同。这个在实际的工作中,应在是看给自己分到的队列的资源一共是多少,而自己预估这个任务大概需要多少资源,然后合理的设置slots数,也就是合理的设置并行度。
4.4 Flink的Slot和parallelism有什么区别?
注意:
- Task Slot是静态的概念,是指TaskManager 具有的并发执行能力 ,可以通过参数taskmanager.numberOfTaskSlots进行配置;
- 而并行度parallelism是动态概念,即TaskManager运行程序时实际使用的并发能力,可以通过参数parallelism.default进行配置。
这么举例子吧,我们提交一个job,就有了一个JobManger,那么通过资源的分配,假如现在在3个节点上执行任务,那就等于说有3个TaskManager,假如每一个TaskManager都包含了一定数量的插槽(slots)。插槽的数量限制了TaskManager能够执行的任务数量。这里假设每个TaskManager可以接收3个task,一共9个TaskSlot,如果我们设置parallelism.default=1,即运行程序默认的并行度为1,9个TaskSlot只用了1个,有8个空闲,因此,设置合适的并行度才能提高效率。
4.5 Flink的并行度是什么?怎么设置才算是合理呢?
算子的并行度: 一个特定算子的子任务(subtask)的个数被称之为其并行度(parallelism)。一个程序中,不同的算子可能具有不同的并行度。
那么具体的每个算子的并行度是多少这个我们后面具体说算子的时候再来讲,这里先大致介绍一下:
- One-to-one,类似于spark的窄依赖,比如map、filter等
- 一对多,类似于spark的宽依赖。
相同并行度的one to one操作,Flink这样相连的算子链接在一起形成一个task,原来的算子成为里面的一部分。将算子链接成task是非常有效的优化:它能减少线程之间的切换和基于缓存区的数据交换,在减少时延的同时提升吞吐量。
任务链必须满足两个条件:one-to-one的数据传输并且并行度相同
**job的并行度:**任务被分为多个并行任务来执行,其中每个并行的实例处理一部分数据。这些并行实例的数量被称为并行度。
我们在实际生产环境中可以从四个不同层面设置并行度:(具体代码体现在后续写)
操作算子层面(Operator Level)
执行环境层面(Execution Environment Level)
客户端层面(Client Level)
系统层面(System Level)
需要注意的优先级:算子层面>环境层面>客户端层面>系统层面。
4.6 Flink的基础编程模型
我们在上述wordCount的代码中,就发现数据流由3部分组成,数据源source,数据转换,数据最后的流出sink 3部分组成。那么这其实也是我们代码的主要构成,通过合适的转换算子将数据源的数据进行处理,最后把结果通过sink的方式输出到别的地方。
每一个dataflow以一个或多个sources开始以一个或多个sinks结束。

Flink 将算子的子任务链接成 task。每个 task 由一个线程执行。把算子链接成 tasks 能够减少线程间切换和缓冲的开销,在降低延迟的同时提高了整体吞吐量。
4.7 Flink的流程图有哪些?
那么上述的数据流直接映射成的数据流图是StreamGraph,也被称为逻辑流图,因为它们表示的是计算逻辑的高级视图。为了执行一个流处理程序,Flink需要将逻辑流图转换为物理数据流图(也叫执行图),详细说明程序的执行方式。
Flink 中的执行图可以分成四层:StreamGraph -> JobGraph -> ExecutionGraph -> 物理执行图。
- StreamGraph:是根据用户通过 Stream API 编写的代码生成的最初的图。用来表示程序的拓扑结构。
- JobGraph:StreamGraph经过优化后生成了 JobGraph,提交给 JobManager 的数据结构。主要的优化为,将多个符合条件的节点 chain 在一起作为一个节点,这样可以减少数据在节点之间流动所需要的序列化/反序列化/传输消耗。
- ExecutionGraph:JobManager 根据 JobGraph 生成ExecutionGraph。ExecutionGraph是JobGraph的并行化版本,是调度层最核心的数据结构。
- 物理执行图:JobManager 根据 ExecutionGraph 对 Job 进行调度后,在各个TaskManager 上部署 Task 后形成的“图”,并不是一个具体的数据结构。
这几个类在源码中也能找到。
关于Flink比较基础的框架概念已经了解的差不多了,部分内容也来源于官网中文翻译。
可能有些概念还没理解透彻,不过没关系,在接下来的应用中,使用的多了就会有不一样的收获,期望通过一篇文章或者只看官网的介绍理解透彻是不存在的,毕竟这框架是众多大牛聚集在一起搞了很多年才搞出来的,我们只不过是个框架的使用者,约等于搬砖工。
所以我写的内容也欢迎大家前来讨论。
那么下一篇Flink的文章我来继续学习关于Flink的API。期待能和你一起学习!
扫码关注”后来X大数据“,回复【电子书】,领取【超多本pdf java及大数据 电子书】
















 2155
2155











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









