







文章目录
概要
在很久前分析过go map的源码,但在go1.24引入了swiss table来提高map性能,相较以前的map实现是完全不同的,特此记录其原理。
环境:Centos Linux 7 ,CPU AMD x86_64,Go version 1.24
一、前置知识
1:go 通过汇编分析栈布局和函数栈帧
2:x86系列CPU寄存器和汇编指令总结
3:cpu多级缓存
1.1、传统哈希表
哈希表是按关键词编址的技术,它提供了关键词key到对应value的映射。哈希表的核心是hash函数和冲突消解方法。hash函数本章不做讨论,我们一起看下冲突消解方法:拉链法和开地址法,二者各有优缺点。
| 冲突消解方法 | 优点 | 缺点 |
|---|---|---|
| 拉链法 | 1:实现,没有那么多边界条件需要考虑 2:冲突链表过长可以把单链表转化为搜索树(红黑树)避免性能退化严重 负载可以突破1,相比之下扩容次数会变少 | 1:缓存不友好,需要多存储下一个冲突节点的指针 2:链表内存不连续,是松散的,无法充分的利用CPU 多级缓存 |
| 线性探测法 | 1:缓存友好,不需要额外存储数据 2:内存连续,是紧凑的,能充分的利用CPU 多级缓存 | 1:实现复杂,需要考虑slot的状态,有元素、空、被删除 2:冲突是连锁式的,会造成后续元素的操作变慢,这一点是最难以忍受的 3:负载只能<=1,相比之下更容易发生扩容 |
理想条件下拉链法和开地址法时间复杂度都是O(1),但发生极端冲突时,拉链法退化到O(lg N),开地址法退化到O(N)。
从过上述对比就能知道为什么多数hash冲突会通过拉链法解决了,如redis的hash类型(单链表),go1.24之前的map(块状链表)都是通过拉链法来解决冲突的。
ps:扩容时会极大的降低哈希表性能。
1.2、swiss table
人们在追寻更高效哈希表的方向有两个:
- 改进hash函数,经过其计算的结果能减少甚至不出现冲突;
- 改进hash表数据结构,在发生冲突时更快的定位或对缓存更友好,在资源消耗和性能提升之间寻找更好的平衡点。
显而易见,swiss table属于后者。
Google工程师Matt Kulukundis在2017年CppCon大会上介绍了swiss table,一种在使用性能上可以远超 std::unordered_map 的哈希表,是google 在最佳工程实践中提炼出的一种优秀哈希表设计。在知名C++开源库中abseil-cpp已有实现。
1:abseil-cpp官网介绍swiss table设计方案
2:abseil-cpp swiss table源码
swiss table是从数据结构上对线性探测法的改进,原理比较简单,数据结构示意图如下:
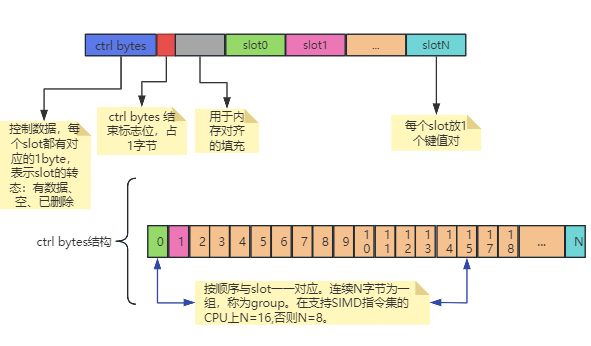
enum class ctrl_t : int8_t { //swiss table 的ctrl bytes 的slot状态
kEmpty = -128, // 0b10000000 //表示对应slot为空
kDeleted = -2, // 0b11111110 //表示对应slot为已删除状态
kSentinel = -1, // 0b11111111 //表示ctrl bytes 结束标志位
//另外ctrl byte等于 0b0??????? 时,表示对应slot有数据
};
struct HeapPtrs { //swiss table 结构体
explicit HeapPtrs(uninitialized_tag_t) {}
explicit HeapPtrs(ctrl_t* c) : control(c) {}
// The control bytes (and, also, a pointer near to the base of the backing
// array).
//
// This contains `capacity + 1 + NumClonedBytes()` entries, even
// when the table is empty (hence EmptyGroup).
//
// Note that growth_info is stored immediately before this pointer.
// May be uninitialized for SOO tables.
ctrl_t* control;
// The beginning of the slots, located at `SlotOffset()` bytes after
// `control`. May be uninitialized for empty tables.
// Note: we can't use `slots` because Qt defines "slots" as a macro.
MaybeInitializedPtr slot_array;
};
为什么当ctrl byte等于 0b0??? 时,就能表示对应slot有数据呢?这就不得不说swiss table 对hash函数计算结果的分段使用了。
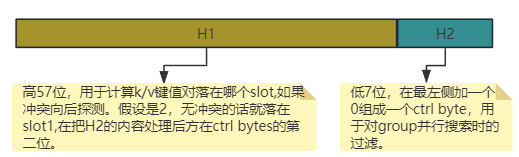
到这里,我们就对swiss table有了一个较为清晰的轮廓了。要说明的一点是,H1决定从ctrl bytes中的第几位开始搜索,然后以group大小进行并行搜索。也就是说group在swiss table只是一个逻辑上的概念,其并没有固定的起始位置,两个key(A和B)的group在某个时刻很可能会交叉,即group A 范围是[2,17],group B范围是[5,20]。
那么swiss table相比传统哈希表快,快在哪里呢(快,其实就是比较冲突时的解决方法,因为没有冲突都是O(1)了,没必要比较)?
与传统线性探测法比较:
- 所有的操作都基于ctrl bytes控制内容,在探测时一次可以比较group大小个控制字节,而传统线性探测法只能按序比较键值对;
这是swiss table高效的精髓所在,假设此时group大小是16,先通过hash函数得到key的H1和H2,从ctrl bytes的第H1字节开始,一次探测16字节,得到等于H2的有哪几个字节,再取对应slot的key进行比较,没有就比较下一个group。通过双层过滤,先一次获得多个等于H2的slot,再比较slot的key,相比传统线性探测法一个个比较高效多了。
- 每个slot用ctrl bytes里的1byte代替,使得内存更紧凑,进一步提高CPU 缓存命中率;
- 另外比较ctrl bytes group时,在支持SIMD指令集的CPU上,使用SIMD指令集进行比较,进一步提高效率;
- 进行冲突探测时,以group为单位进行探测,大大降低了传统线性探测法冲突连锁反应的影响。
通过额外增加ctrl bytes控制内容这一点内存,换取性能的巨大提升,完全是值得的。
与传统拉链法比较:
传统拉链法相比传统线性探测法的最大优势就是 没有冲突连锁反应,而swiss table 通过ctrl bytes实现以group为单位进行并行探测,大大降低了冲突连锁反应的影响,再加上内存非常友好,非极端情况下性能普遍优于拉链法。Google 在cpp中 swiss table的 实现(如flat_hash_map)在多线程高负载场景下,冲突处理吞吐量达到std::unordered_map(拉链法) 的 3~5 倍,也验证了swiss table冲突连锁控制的有效性。
二、go swiss map原理
go1.24之前map源码分析。
go1.24开始map源码位置有所调整:
go1.24之前map源码-map_noswiss.go;
go1.24及其以后map源码-map_swiss.go。
字节工程师zhangyunhao在2022年向go项目组提出使用google swiss table重新实现Go map,2025年2月go1.24正式发布,map进行了升级,引入了swiss table。字节工程师zhangyunhao的gomapbench repo提供了对map的性能基准测试代码,可以观察下其在go1.23和1.24的结果。
相比go1.24之前的map实现,其:
- 在大规模map或查询不存在元素时性能提升20%-50%;
- 插入和删除性能提升20%-50%;
- 内存上减少了0%-25%的消耗,固定大小的map不在产生额外的内存碎片。
2.1、map元数据
//https://github.com/golang/go/blob/go1.24.3/src/internal/abi/map_swiss.go
const (
// Number of bits in the group.slot count.
SwissMapGroupSlotsBits = 3
// Number of slots in a group.
SwissMapGroupSlots = 1 << SwissMapGroupSlotsBits // 一个group 存8个slot
)
type SwissMapType struct {
Type
Key *Type //map的key类型
Elem *Type //map的value类型
Group *Type // group 类型
Hasher func(unsafe.Pointer, uintptr) uintptr// function for hashing keys (ptr to key, seed) -> hash
GroupSize uintptr // group大小,等于8*SlotSize + 8bytes(ctrl bytes)
SlotSize uintptr // slot大小,即一个键值对的大小
ElemOff uintptr // offset of elem in key/elem slot
Flags uint32
}
//https://github.com/golang/go/blob/go1.24.3/src/internal/runtime/maps/group.go
const (
// Maximum load factor prior to growing.
// 7/8 is the same load factor used by Abseil, but Abseil defaults to
// 16 slots per group, so they get two empty slots vs our one empty
// slot. We may want to reevaluate if this is best for us.
maxAvgGroupLoad = 7 //负载因子7/8,表示平均每个group存储7个slot,就要进行扩容了
ctrlEmpty ctrl = 0b10000000 //表示slot为空
ctrlDeleted ctrl = 0b11111110 //表示slot为已删除状态
//下面是为了通过ctrl bytes快速计算出slot状态特殊设置的常量
bitsetLSB = 0x0101010101010101
bitsetMSB = 0x8080808080808080
bitsetEmpty = bitsetLSB * uint64(ctrlEmpty)
bitsetDeleted = bitsetLSB * uint64(ctrlDeleted)
)
type ctrl uint8 //1 ctrl byte
type ctrlGroup uint64 //每个group 的 ctrl bytes,8字节,这一点与google cpp的swiss table不同,go是每个group维护自己的ctrl bytes
// A group holds abi.SwissMapGroupSlots slots (key/elem pairs) plus their
// control word.
type groupReference struct {//用于临时处理一个group数据的结构体,里面给出了group、slot的布局
// data points to the group, which is described by typ.Group and has layout:
// type group struct { //group的真实布局
// ctrls ctrlGroup
// slots [abi.SwissMapGroupSlots]slot
// }
// type slot struct {//键值对的真实布局
// key typ.Key
// elem typ.Elem
// }
data unsafe.Pointer // data *typ.Group
}
const (
ctrlGroupsSize = unsafe.Sizeof(ctrlGroup(0)) //group 的 ctrl bytes 为8字节
groupSlotsOffset = ctrlGroupsSize //定位slot时用,向右移8字节
)
type groupsReference struct { //用于table承接group数组的一个结构体
// data points to an array of groups. See groupReference above for the
// definition of group.
data unsafe.Pointer // data *[length]typ.Group
// lengthMask is the number of groups in data minus one (note that
// length must be a power of two). This allows computing i%length quickly using bitwise AND.
lengthMask uint64 //掩码,等于len(data)-1,便于通过H1&lengthMask位运算(得到data数组索引下标)快速定位group在data中的位置,也就是找到key理论上所在的group,冲突的话要遍历其后面的group
}
//https://github.com/golang/go/blob/go1.24.3/src/internal/runtime/maps/table.go
const maxTableCapacity = 1024 //每个table包含1024个slot
type table struct {
// The number of filled slots (i.e. the number of elements in the table).
used uint16 //table中的slot(键值对)的个数
// The total number of slots (always 2^N). Equal to `(groups.lengthMask+1)*abi.SwissMapGroupSlots`.
capacity uint16 //table的容量,go table并不是初始时就申请1024个slot的容量,而是按需申请
// The number of slots we can still fill without needing to rehash.
// We rehash when used + tombstones > loadFactor*capacity, including
// tombstones so the table doesn't overfill with tombstones. This field
// counts down remaining empty slots before the next rehash.
growthLeft uint16 //表示还有多少可被插入的slot(这里考虑到了负载因子,也就是说如果有8个空的slot,那么growthLeft等于8*7/8=7)
// The number of bits used by directory lookups above this table. Note
// that this may be less then globalDepth, if the directory has grown
// but this table has not yet been split.
localDepth uint8//table扩容分裂成两个table时该值会+1,与m.globalDepth比较,判断m.dirPtr是否也需要扩容
// Index of this table in the Map directory. This is the index of the
// _first_ location in the directory. The table may occur in multiple sequential indicies.
// index is -1 if the table is stale (no longer installed in the directory).
index int //当前table第一个在map中table数组中的索引下标,扩容会使其发生变化
// groups is an array of slot groups. Each group holds abi.SwissMapGroupSlots
// key/elem slots and their control bytes. A table has a fixed size
// groups array. The table is replaced (in rehash) when more space is required.
groups groupsReference
}
//https://github.com/golang/go/blob/go1.24.3/src/internal/runtime/maps/map.go
type Map struct {
// The number of filled slots (i.e. the number of elements in all tables). Excludes deleted slots.
// Must be first (known by the compiler, for len() builtin).
used uint64//map的slot个数,即len(map)的结果
// seed is the hash seed, computed as a unique random number per map.
seed uintptr //随机种子
// The directory of tables.
//
// Normally dirPtr points to an array of table pointers
//
// dirPtr *[dirLen]*table
//
// The length (dirLen) of this array is `1 << globalDepth`. Multiple
// entries may point to the same table. See top-level comment for more
// details.
//
// Small map optimization: if the map always contained
// abi.SwissMapGroupSlots or fewer entries, it fits entirely in a
// single group. In that case dirPtr points directly to a single group.
//
// dirPtr *group
//
// In this case, dirLen is 0. used counts the number of used slots in
// the group. Note that small maps never have deleted slots (as there
// is no probe sequence to maintain).
dirPtr unsafe.Pointer //当slot个数>8时,其本质是table 数组,当slot个数<=8时,其本质是*typ.Group(即直接指向了一个group),此时dirLen=0
dirLen int //table个数
// The number of bits to use in table directory lookups.
globalDepth uint8 //表示map table数组扩容次数,会按2*dirLen进行扩容
// The number of bits to shift out of the hash for directory lookups.
globalShift uint8 //64位下等于64-globalDepth,32位下等于32-globalDepth,辅助定位key在哪个table
// writing is a flag that is toggled (XOR 1) while the map is being
// written. Normally it is set to 1 when writing, but if there are
// multiple concurrent writers, then toggling increases the probability
// that both sides will detect the race.
writing uint8 //1表示正在写
// clearSeq is a sequence counter of calls to Clear. It is used to detect map clears during iteration.
clearSeq uint64 //clear(map) 次数,迭代时用
}
通过对go swiss map 元数据的了解,我们可以得到其结构示意图:
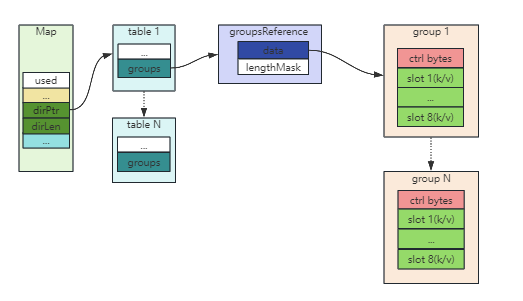
通过go map结构示意图与google cpp map结构示意图的对比,差异还是不小的:
- google cpp map就是一个swiss table,而go map是swiss table数组,每个table仅存1024个slot。go这种处理方式可以降低扩容对map性能的影响,仅影响正在扩容的table。
- google cpp map的group是一个概念,H1定位到的是某个slot,而go map的group是具体实例,H1定位到的是某个group。go这种方式通过具象化的group可以给等于H1的key预留8个slot,进一步降低线性探测法冲突连锁反应的影响,但可能多消耗些内存。
2.2、初始化
//https://github.com/golang/go/blob/master/src/internal/runtime/maps/map.go
func NewMap(mt *abi.SwissMapType, hint uintptr, m *Map, maxAlloc uintptr) *Map {
if m == nil {
m = new(Map)
}
m.seed = uintptr(rand())
if hint <= abi.SwissMapGroupSlots {
return m //初始化容量<=8时,直接返回new(Map),等插入时再初始化m.dirPtr 字段值
}
// Full size map.
// Set initial capacity to hold hint entries without growing in the average case.
targetCapacity := (hint * abi.SwissMapGroupSlots) / maxAvgGroupLoad //在负载因子是7/8的情况下,存hint个slot需要多少容量
if targetCapacity < hint { // overflow
return m // return an empty map. 理论上不会走到这里
}
dirSize := (uint64(targetCapacity) + maxTableCapacity - 1) / maxTableCapacity//每个table存1024个slot,计算申请targetCapacity个slot需要多少table
dirSize, overflow := alignUpPow2(dirSize) //table的个数一定要是2的指数
if overflow || dirSize > uint64(math.MaxUintptr) {
return m // return an empty map.
}
//hint过大,则不预先分配内容直接返回m,后面慢慢扩容
groups, overflow := math.MulUintptr(uintptr(dirSize), maxTableCapacity)
if overflow {
return m // return an empty map.
} else {
mem, overflow := math.MulUintptr(groups, mt.GroupSize)
if overflow || mem > maxAlloc {
return m // return an empty map.
}
}
m.globalDepth = uint8(sys.TrailingZeros64(dirSize))//dirSize 二进制下末尾连续为0的位数
m.globalShift = depthToShift(m.globalDepth)
directory := make([]*table, dirSize)
for i := range directory {
directory[i] = newTable(mt, uint64(targetCapacity)/dirSize, i, m.globalDepth)//初始化每个table
}
m.dirPtr = unsafe.Pointer(&directory[0])
m.dirLen = len(directory)
return m
}
//https://github.com/golang/go/blob/go1.24.3/src/internal/runtime/maps/table.go
func newTable(typ *abi.SwissMapType, capacity uint64, index int, localDepth uint8) *table {
if capacity < abi.SwissMapGroupSlots {
capacity = abi.SwissMapGroupSlots
}
t := &table{
index: index,
localDepth: localDepth,
}
if capacity > maxTableCapacity {
panic("initial table capacity too large")
}
// N.B. group count must be a power of two for probeSeq to visit every group.
capacity, overflow := alignUpPow2(capacity)
if overflow {
panic("rounded-up capacity overflows uint64")
}
t.reset(typ, uint16(capacity))
return t
}
// reset resets the table with new, empty groups with the specified new total capacity.
func (t *table) reset(typ *abi.SwissMapType, capacity uint16) {
groupCount := uint64(capacity) / abi.SwissMapGroupSlots//需要group的数量
t.groups = newGroups(typ, groupCount)//申请group
t.capacity = capacity
t.resetGrowthLeft()
for i := uint64(0); i <= t.groups.lengthMask; i++ {
g := t.groups.group(typ, i)
g.ctrls().setEmpty()//将每个group的ctrl bytes 全部置为 空状态
}
}
//https://github.com/golang/go/blob/go1.24.3/src/internal/runtime/maps/group.go
// newGroups allocates a new array of length groups.
func newGroups(typ *abi.SwissMapType, length uint64) groupsReference {
return groupsReference{
data: newarray(typ.Group, int(length)),//申请连续length个typ.Group的内存
lengthMask: length - 1,
}
}
初始化还是很简单的,就是根据预设的常量,每个table最多存1024个slot,每个group最多存8个slot,负载因为7/8等得到存hint个键值对需要多少个table,每个table多少group,并将每个group的ctrl bytes 全部置为 空状态。
2.2、查询
//https://github.com/golang/go/blob/go1.24.3/src/internal/runtime/maps/runtime_swiss.go
func runtime_mapaccess1(typ *abi.SwissMapType, m *Map, key unsafe.Pointer) unsafe.Pointer {
//...省略
if m == nil || m.Used() == 0 {//未初始化的map或没有键值对的map直接返回nil
if err := mapKeyError(typ, key); err != nil {
panic(err) // see issue 23734
}
return unsafe.Pointer(&zeroVal[0])
}
if m.writing != 0 {//正在被写的话,此时读直接panic
fatal("concurrent map read and map write")
}
hash := typ.Hasher(key, m.seed)//计算当前key的hash值
if m.dirLen <= 0 {//map 初始化 slot数<=8 或过大, 会出现m.dirLen <= 0
_, elem, ok := m.getWithKeySmall(typ, hash, key)//特殊处理,
if !ok {
return unsafe.Pointer(&zeroVal[0])
}
return elem
}
// Select table.
idx := m.directoryIndex(hash)//通过hash值计算出理论上key所在table的位置
t := m.directoryAt(idx) //通过数组下标拿到table
// Probe table. 开始探测这个swiss table
//h1(hash) 即取hash值高57位,得到H1
seq := makeProbeSeq(h1(hash), t.groups.lengthMask)//通过H1定位该从哪个group开始探测
for ; ; seq = seq.next() {
g := t.groups.group(typ, seq.offset)//取当前group,即groupReference的实例
//h2(hash) 即取hash值低7位,得到H2
match := g.ctrls().matchH2(h2(hash))//【这是精髓所在】通过该group的ctrl bytes得到哪几个slot的ctrl byte值等于H2,然后遍历这几个slot即可
for match != 0 {//这里遍历的只是该group中ctrl byte等于H2的slot,不等于的在获取match值时已经被过滤掉了
i := match.first()//取第一个ctrl byte值等于H2的slot的数组下标
slotKey := g.key(typ, i) //取该slot key
slotKeyOrig := slotKey
if typ.IndirectKey() {
slotKey = *((*unsafe.Pointer)(slotKey))
}
if typ.Key.Equal(key, slotKey) { //对比该slot key与要查询的key是否一致
slotElem := unsafe.Pointer(uintptr(slotKeyOrig) + typ.ElemOff)
if typ.IndirectElem() {
slotElem = *((*unsafe.Pointer)(slotElem))
}
return slotElem //一致直接返回该slot的value
}
match = match.removeFirst() //不一致则直接将该slot的数组下标从match中移除,这样下一个符合的slot的数组下标就成为match的头部了
}
match = g.ctrls().matchEmpty()//如果还没找到,查看该group crl bytes是否全是空状态
if match != 0 {//是,则表示所查key在map中不存在
// Finding an empty slot means we've reached the end of
// the probe sequence.
return unsafe.Pointer(&zeroVal[0])
}
}
}
- 计算所查key的hash值;
- 通过hash值定位到所在的swiss table;
- 通过hash值H1定位到所查key理论上在table的第几个group,开始遍历;
- 通过hash值H2和group ctrl bytes 快速得出该group 可能含有key的slot(这是精髓所在,直接定位哪几个slot的ctrl byte等于H2,不等于的就不用遍历了);
- 遍历这些slot,对比key,有等于则找到,没有则第6步;
- 查看group ctrl bytes是否全为空状态,否则回到第4步,是则表示key不存在。
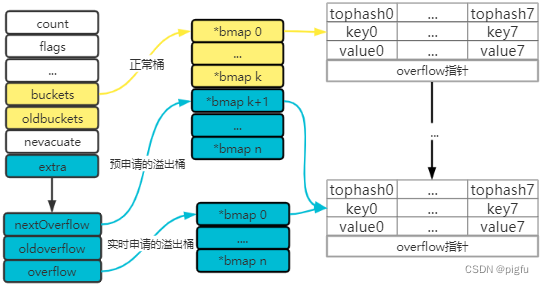
对于go1.24之前map 的查找,在冲突遍历时,先遍历单链表,再遍历链表节点的bmap中的8个slot,只能依次遍历,做不到像swiss map那样先通过tophash探测下这8个slot中是否可能包含所查key,可能的话直接给出具体哪几个slot,而不是8个都遍历,不可能就直接跳过了。
下面是go1.24之前map结构示意图:
2.3、插入和删除
插入和删除都是要先查找再插或删,所以流程与查找差不多。
本章只说一下插入的源码,删除的和查找源码高度一致,唯一不同的是找到key后,将slot中的key和value置为nil,并将slot对应ctrl byte设为已删除。
//https://github.com/golang/go/blob/master/src/internal/runtime/maps/runtime_swiss.go
func runtime_mapassign(typ *abi.SwissMapType, m *Map, key unsafe.Pointer) unsafe.Pointer {
if m == nil { //未初始化map不允许插入,否则panic
panic(errNilAssign)
}
if m.writing != 0 {//不允许并发写
fatal("concurrent map writes")
}
hash := typ.Hasher(key, m.seed)计算当前key的hash值
// Set writing after calling Hasher, since Hasher may panic, in which case we have not actually done a write.
m.writing ^= 1 // toggle, see comment on writing
if m.dirPtr == nil {//map 初始化 slot数<=8 或过大, 会出现m.dirPtr == nil
m.growToSmall(typ) //此时通过growToSmall 初始化下,初始化后m.dirPtr只是一个group
}
if m.dirLen == 0 {
if m.used < abi.SwissMapGroupSlots {//比较键值对数量<8
elem := m.putSlotSmall(typ, hash, key)//成立的时候
if m.writing == 0 {
fatal("concurrent map writes")
}
m.writing ^= 1
return elem
}
m.growToTable(typ)//否则扩容,将m.dirPtr有一个group升级为table数组
}
var slotElem unsafe.Pointer
outer:
for {
idx := m.directoryIndex(hash)//通过hash值计算出理论上key所在table的位置
t := m.directoryAt(idx)//通过数组下标拿到table
seq := makeProbeSeq(h1(hash), t.groups.lengthMask)//通过该group的ctrl bytes得到哪几个slot的ctrl byte值等于H2,然后遍历这几个slot即可
// As we look for a match, keep track of the first deleted slot we find,
// which we'll use to insert the new entry if necessary.
var firstDeletedGroup groupReference //查找key过程中,遇到的第一个存在空slot或已删除slot的group
var firstDeletedSlot uintptr//查找key过程中,遇到的第一个存在空slot或已删除slot在group中的数组下标,如果key不存在,插入的键值对就放在这个位置了
for ; ; seq = seq.next() {//这部分与查找一致,就不注释了
g := t.groups.group(typ, seq.offset)
match := g.ctrls().matchH2(h2(hash))
for match != 0 {
i := match.first()
slotKey := g.key(typ, i)
slotKeyOrig := slotKey
if typ.IndirectKey() {
slotKey = *((*unsafe.Pointer)(slotKey))
}
if typ.Key.Equal(key, slotKey) {
if typ.NeedKeyUpdate() {
typedmemmove(typ.Key, slotKey, key)
}
slotElem = unsafe.Pointer(uintptr(slotKeyOrig) + typ.ElemOff)
if typ.IndirectElem() {
slotElem = *((*unsafe.Pointer)(slotElem))//找到了就更新value的值
}
t.checkInvariants(typ, m)
break outer
}
match = match.removeFirst()
}
// No existing slot for this key in this group. Is this the end of the probe sequence?
match = g.ctrls().matchEmpty()//如果还没找到,查看该group crl bytes是否全是空状态
if match != 0 {//是,则表示所查key在map中不存在
// Finding an empty slot means we've reached the end of the probe sequence.
var i uintptr
// If we found a deleted slot along the way, we can replace it without consuming growthLeft.
if firstDeletedGroup.data != nil {//如果之前已经遇到了合适的slot,则将键值对放在该slot中
g = firstDeletedGroup
i = firstDeletedSlot
t.growthLeft++ // will be decremented below to become a no-op.
} else {//没有遇到,则从取当前group的第一个slot
i = match.first()
}
// If there is room left to grow, just insert the new entry.
if t.growthLeft > 0 {//还有可用的slot,即没达到负载因子上限,就将键值对放在这个位置了,否则要扩容
slotKey := g.key(typ, i)
slotKeyOrig := slotKey
if typ.IndirectKey() {
kmem := newobject(typ.Key)
*(*unsafe.Pointer)(slotKey) = kmem
slotKey = kmem
}
typedmemmove(typ.Key, slotKey, key)
slotElem = unsafe.Pointer(uintptr(slotKeyOrig) + typ.ElemOff)
if typ.IndirectElem() {
emem := newobject(typ.Elem)
*(*unsafe.Pointer)(slotElem) = emem
slotElem = emem
}
g.ctrls().set(i, ctrl(h2(hash)))//设置slot对应ctrl byte为H2
t.growthLeft--
t.used++ //table 键值对数量+1
m.used++ //map键值对数量+1
t.checkInvariants(typ, m)
break outer
}
t.rehash(typ, m) //扩容
continue outer//扩容完了回到outer,继续找适合key的slot
}
// No empty slots in this group. Check for a deleted slot,
// which we'll use if we don't find a match later in the probe sequence.
// We only need to remember a single deleted slot.
if firstDeletedGroup.data == nil {//判断firstDeletedGroup.data == nil
// Since we already checked for empty slots above, matches here must be deleted slots.
match = g.ctrls().matchEmptyOrDeleted()//如果还没找到,查看该group crl bytes是否有空或已删除状态
if match != 0 {//有的话则留下,以待key不存在的情况下使用
firstDeletedGroup = g
firstDeletedSlot = match.first()
}
}
}
}
if m.writing == 0 {//最后再检查下并发写
fatal("concurrent map writes")
}
m.writing ^= 1
return slotElem //有了适合插入的slot,返回value的地址,由外部赋值
}
- 计算所查key的hash值;
- 通过hash值定位到所在的swiss table;
- 通过hash值H1定位到所查key理论上在table的第几个group,开始遍历;
- 通过hash值H2和group ctrl bytes 快速得出该group 可能含有key的slot;
- 遍历这些slot,对比key,相等则找到,没有则第6步;
- 查看group ctrl bytes是否全为空状态,否则第7步,是第8步;
- 查看group ctrl bytes是否有为空或已删除的slot,有则记录group和slot,然后到第4步;
- 有通过第7步记录到group和slot,则将键值对插入到此位置,没有则判断t.growthLeft > 0,成立则取当前group第一个slot插入键值对,不成立则需要扩容,扩容后再回到第2步。
插入过程可取的就是在查找遍历过程中先记录有为空或已删除slot的group,后面确定key不存在则直接插入该位置,无需再次去找合适的slot了。
2.4、扩容
go swiss map 每个table的扩容是独立判定的,扩容过程也是独立的。扩容分为table内扩容和table级别扩容:
1:table内扩容是指table内group数量翻倍;
2:table级别扩容是指table 分裂为两个table。
//https://github.com/golang/go/blob/master/src/internal/runtime/maps/table.go
func (t *table) rehash(typ *abi.SwissMapType, m *Map) {
newCapacity := 2 * t.capacity
if newCapacity <= maxTableCapacity {
t.grow(typ, m, newCapacity) //table内group数量翻倍
return
}
t.split(typ, m)//当前table 分裂为两个table
}
table内group数量翻倍
func (t *table) grow(typ *abi.SwissMapType, m *Map, newCapacity uint16) {
newTable := newTable(typ, uint64(newCapacity), t.index, t.localDepth) //申请一个新table
if t.capacity > 0 {
for i := uint64(0); i <= t.groups.lengthMask; i++ {//遍历旧table的group
g := t.groups.group(typ, i)
for j := uintptr(0); j < abi.SwissMapGroupSlots; j++ {//遍历group的slot
if (g.ctrls().get(j) & ctrlEmpty) == ctrlEmpty {//空或已删除的slot跳过
// Empty or deleted
continue
}
key := g.key(typ, j)
if typ.IndirectKey() {
key = *((*unsafe.Pointer)(key))
}
elem := g.elem(typ, j)
if typ.IndirectElem() {
elem = *((*unsafe.Pointer)(elem))
}
hash := typ.Hasher(key, m.seed)
newTable.uncheckedPutSlot(typ, hash, key, elem)//将旧table中的键值对依次插入到新table中
}
}
}
newTable.checkInvariants(typ, m)
m.replaceTable(newTable) //新table替换旧table
t.index = -1
}
当前table 分裂为两个table
func (t *table) split(typ *abi.SwissMapType, m *Map) {
localDepth := t.localDepth
localDepth++ //扩容次数+1
// //申请两个新table
left := newTable(typ, maxTableCapacity, -1, localDepth)
right := newTable(typ, maxTableCapacity, -1, localDepth)
// Split in half at the localDepth bit from the top.
mask := localDepthMask(localDepth)
for i := uint64(0); i <= t.groups.lengthMask; i++ {
g := t.groups.group(typ, i)
for j := uintptr(0); j < abi.SwissMapGroupSlots; j++ {
if (g.ctrls().get(j) & ctrlEmpty) == ctrlEmpty {//空或已删除的slot跳过
// Empty or deleted
continue
}
key := g.key(typ, j)
if typ.IndirectKey() {
key = *((*unsafe.Pointer)(key))
}
elem := g.elem(typ, j)
if typ.IndirectElem() {
elem = *((*unsafe.Pointer)(elem))
}
hash := typ.Hasher(key, m.seed)
var newTable *table
//将旧table的键值对hash&掩码计算后插入到两个新table中
if hash&mask == 0 {
newTable = left
} else {
newTable = right
}
newTable.uncheckedPutSlot(typ, hash, key, elem)
}
}
m.installTableSplit(t, left, right)
t.index = -1
}
func (m *Map) installTableSplit(old, left, right *table) {
if old.localDepth == m.globalDepth {//相等时map table数组会进行2被扩容,
// No room for another level in the directory. Grow the directory.
newDir := make([]*table, m.dirLen*2) //
for i := range m.dirLen {
t := m.directoryAt(uintptr(i))
newDir[2*i] = t //紧邻的两个数组下标指向同一个table
newDir[2*i+1] = t
if t.index == i {//修正t.index值
t.index = 2 * i
}
}
m.globalDepth++ //map 的table数组扩容次数+1
m.globalShift--
m.dirPtr = unsafe.Pointer(&newDir[0])//m.directory = newDir
m.dirLen = len(newDir)
}
//两个新table替换掉旧table
left.index = old.index
m.replaceTable(left)
entries := 1 << (m.globalDepth - left.localDepth)
right.index = left.index + entries
m.replaceTable(right)
}
2.5、迭代
//https://github.com/golang/go/blob/go1.24.3/src/runtime/map_swiss.go
func mapIterStart(t *abi.SwissMapType, m *maps.Map, it *maps.Iter) {
it.Init(t, m)
it.Next()
}
// mapIterNext performs the next step of iteration. Afterwards, the next key/elem are in it.Key()/it.Elem().
func mapIterNext(it *maps.Iter) {
it.Next()
}
//https://github.com/golang/go/blob/master/src/internal/runtime/maps/table.go
type Iter struct {
key unsafe.Pointer //当前key,如果为nil说明迭代结束 (see cmd/compile/internal/walk/range.go).
elem unsafe.Pointer //当前value (see cmd/compile/internal/walk/range.go).
typ *abi.SwissMapType//swiss map类型信息
m *Map //当前迭代的map
// Randomize iteration order by starting iteration at a random slot offset.
entryOffset uint64 //随机偏移量,作用于group数组及其内部的slot
dirOffset uint64//遍历table数组时的随机偏移量
// Snapshot of Map.clearSeq at iteration initialization time. Used to detect clear during iteration.
clearSeq uint64//Iter初始化时Map.clearSeq的值,主要用于判断迭代过程map是否调用了Clear(),不等于说明调用了,直接结束迭代
// Value of Map.globalDepth during the last call to Next. Used to detect directory grow during iteration.
globalDepth uint8//Iter初始化时Map.globalDepth的值,识别map table数组是否发生了扩容,这时候需要重新调整当前迭代的位置
// dirIdx is the current directory index, prior to adjustment by dirOffset.
dirIdx int//当前正在的迭代的table的索引下标,结合dirOffset偏移确定table
// tab is the table at dirIdx during the previous call to Next.
tab *table//当前正在的迭代的table
// group is the group at entryIdx during the previous call to Next.
group groupReference//当前正在迭代的group
// entryIdx is the current entry index, prior to adjustment by entryOffset.
// The lower 3 bits of the index are the slot index, and the upper bits
// are the group index.
entryIdx uint64//当前正在迭代的slot位置
}
可以看到go swiss map通过对table、group、slot在迭代开始时设置随机偏移量,使得每次遍历结果的键值对顺序也是不同的。
所以在迭代间隙插入的键值对有的迭代到有的迭代不到。
三、巧妙的位运算
在第二章2.2小节我们强调如下代码是swiss map的高性能的精髓所在,一起看看吧。
match := g.ctrls().matchH2(h2(hash))
for match != 0 {
i := match.first()
//...省略
match = match.removeFirst()
}
下面是将matchH2函数摘出来做的test:
package swisstable
import (
"fmt"
"testing"
)
const (
bitsetLSB = 0x0101010101010101
bitsetMSB = 0x8080808080808080
deBruijn64 = 0x03f79d71b4ca8b09
ctrlEmpty ctrl = 0b10000000
ctrlDeleted ctrl = 0b11111110
bitsetEmpty = bitsetLSB * uint64(ctrlEmpty)
bitsetDeleted = bitsetLSB * uint64(ctrlDeleted)
)
var deBruijn64tab = [64]byte{
0, 1, 56, 2, 57, 49, 28, 3, 61, 58, 42, 50, 38, 29, 17, 4,
62, 47, 59, 36, 45, 43, 51, 22, 53, 39, 33, 30, 24, 18, 12, 5,
63, 55, 48, 27, 60, 41, 37, 16, 46, 35, 44, 21, 52, 32, 23, 11,
54, 26, 40, 15, 34, 20, 31, 10, 25, 14, 19, 9, 13, 8, 7, 6,
}
type ctrl uint8
type ctrlGroup uint64
type bitset uint64
//【g.ctrls().matchH2】
func ctrlGroupMatchH(g ctrlGroup, h uintptr) bitset {
v := bitsetLSB * uint64(h)
fmt.Printf("%x\n", v) //0x303030303030303
v = uint64(g) ^ v
oldV := v
fmt.Printf("%x\n", v) //3030300030201
v = v - bitsetLSB
fmt.Printf("%x\n", v) //ff020201ff020100
v = v &^ oldV
fmt.Printf("%x\n", v) //ff000000ff000100
v = v & bitsetMSB
fmt.Printf("%x\n", v) //8000000080000000
return bitset(v)
}
func trailingZeros64(x uint64) int { //计算x值二进制末尾(低位)多少个连续的0,比如0x8000000080000000 是31个
if x == 0 {
return 64
}
return int(deBruijn64tab[(x&-x)*deBruijn64>>(64-6)])
}
// 【match.first()】
func bitsetFirst(b bitset) uintptr {
return uintptr(trailingZeros64(uint64(b))) >> 3
}
//【match.removeFirst()】
func removeFirst(b bitset) bitset {
return b & (b - 1)
}
func TestSwissMap(t *testing.T) {
//假设一个key的H2=0x03,此时通过H1定位到的group的ctrl bytes为0x0300000003000102;
//0x0300000003000102的值表示第一个slot的ctrl byte是0x02,以此类推。
//可知第4和第8个slot可能是要找的slot。
v := ctrlGroupMatchH(ctrlGroup(0x0300000003000102), 0x03)
t.Logf("%x", v) //0x8000000080000000
t.Logf("%v", bitsetFirst(v)) //3 定位到第4个slot
v = removeFirst(v)
t.Logf("%x", v) //0x8000000000000000
t.Logf("%v", bitsetFirst(v)) //7 定位到第8个slot
}
从上述代码中可以看到swiss map通过巧妙的位运算直接定位出一个group中ctrl byte等于H2的slot,不等于的slot就无需处理了。
四、SIMD指令集优化
环境:Centos Linux 7 ,CPU AMD x86_64,Go version 1.24
package main
func main() {
swissTable()
}
func swissTable() {
m := make(map[int]int, 100)//100保证初始化时m.dirPtr是table数组
m[1] = 1 //插入时,能走到 match := g.ctrls().matchH2(h2(hash))
m[2] = 2
}
我们通过dlv可以追踪到g.ctrls().matchH2的汇编指令:
[root@kdzl gofunc]# dlv debug map.go
Type 'help' for list of commands.
(dlv) b runtime_fast64_swiss.go:252
Breakpoint 1 set at 0x4067d6 for runtime.mapassign_fast64() /usr/local/go/src/internal/runtime/maps/runtime_fast64_swiss.go:252
(dlv) c
> [Breakpoint 1] runtime.mapassign_fast64() /usr/local/go/src/internal/runtime/maps/runtime_fast64_swiss.go:252 (hits goroutine(1):1 total:1) (PC: 0x4067d6)
Warning: debugging optimized function
247: var firstDeletedGroup groupReference
248: var firstDeletedSlot uintptr
249:
250: for ; ; seq = seq.next() {
251: g := t.groups.group(typ, seq.offset)
=> 252: match := g.ctrls().matchH2(h2(hash))
253:
254: // Look for an existing slot containing this key.
255: for match != 0 {
256: i := match.first()
257:
(dlv) si
> runtime.mapassign_fast64() /usr/local/go/src/internal/runtime/maps/runtime_fast64_swiss.go:252 (PC: 0x4067de)
Warning: debugging optimized function
runtime_fast64_swiss.go:251 0x4067be 4889d9 mov rcx, rbx
runtime_fast64_swiss.go:251 0x4067c1 488b9c24b0000000 mov rbx, qword ptr [rsp+0xb0]
runtime_fast64_swiss.go:251 0x4067c9 e892d2ffff call $internal/runtime/maps.(*groupsReference).group
runtime_fast64_swiss.go:251 0x4067ce 4889842480000000 mov qword ptr [rsp+0x80], rax
runtime_fast64_swiss.go:252 0x4067d6* 488d842480000000 lea rax, ptr [rsp+0x80]
=> runtime_fast64_swiss.go:252 0x4067de 6690 data16 nop
runtime_fast64_swiss.go:252 0x4067e0 e8bbd1ffff call $internal/runtime/maps.(*groupReference).ctrls
runtime_fast64_swiss.go:252 0x4067e5 4889842498000000 mov qword ptr [rsp+0x98], rax
runtime_fast64_swiss.go:252 0x4067ed 488b442458 mov rax, qword ptr [rsp+0x58]
runtime_fast64_swiss.go:252 0x4067f2 e8a9d2ffff call $internal/runtime/maps.h2
runtime_fast64_swiss.go:252 0x4067f7 488b942498000000 mov rdx, qword ptr [rsp+0x98]
(dlv) ni
#... //省略
# 一致ni,直到runtime_fast64_swiss.go:252 0x406808 e893d0ffff call $internal/runtime/maps.ctrlGroup.matchH2位置
(dlv) si
> internal/runtime/maps.ctrlGroup.matchH2() /usr/local/go/src/internal/runtime/maps/group.go:148 (PC: 0x4038a0)
Warning: debugging optimized function
TEXT internal/runtime/maps.ctrlGroup.matchH2(SB) /usr/local/go/src/internal/runtime/maps/group.go
=> group.go:148 0x4038a0 66480f6ec3 movq xmm0, rbx
group.go:148 0x4038a5 660f60c0 punpcklbw xmm0, xmm0
group.go:148 0x4038a9 f20f70c000 pshuflw xmm0, xmm0, 0x0
group.go:148 0x4038ae 66480f6ec8 movq xmm1, rax
group.go:148 0x4038b3 660f74c1 pcmpeqb xmm0, xmm1
group.go:148 0x4038b7 660fd7c8 pmovmskb ecx, xmm0
我们就可以看到在x86-64下, g.ctrls().matchH2 函数在编译时会被替换为 :
#RBX寄存器的内容是当前key hash值的H2(假设是0x03),RAX寄存器的内容是group 的ctrl bytes(假设是0x0300000003000102)
group.go:148 0x4038a0 66480f6ec3 movq xmm0, rbx #将H2(仅8为)加载到xmm0低64位,高64位置零【0x00...0000000000000003】
group.go:148 0x4038a5 660f60c0 punpcklbw xmm0, xmm0#对低64位交错解包,执行后xmm0寄存器内容为【0x00...0000000000000303】
group.go:148 0x4038a9 f20f70c000 pshuflw xmm0, xmm0, 0x0#对xmm0低64位重排,执行后xmm0寄存器内容为【0x00...0303030303030303】
group.go:148 0x4038ae 66480f6ec8 movq xmm1, rax #将ctrl bytes加载到XMM1寄存器低64位
group.go:148 0x4038b3 660f74c1 pcmpeqb xmm0, xmm1#将xmm0和xmm1内容按字节分别比较,相等则对应字节置为1,否则0,则此时xmm0寄存器内容为【0x00...8000000080000000】,可以看到一样得到符合的slot的位置
group.go:148 0x4038b7 660fd7c8 pmovmskb ecx, xmm0#将比较结果的掩码转换为16位整数存入ecx寄存器
可以看到用的都是x86 SSE指令集的指令,其是x86下SIMD的具体实现,运算结果与ctrlGroupMatchH函数结果一致。
go源码中注释也说明在x86-64下会被SIMD instructions替换。
func (g ctrlGroup) matchH2(h uintptr) bitset {
return ctrlGroupMatchH2(g, h)
}
// Portable implementation of matchH2.
// Note: On AMD64, this is an intrinsic implemented with SIMD instructions. See
// note on bitset about the packed instrinsified return value.
func ctrlGroupMatchH2(g ctrlGroup, h uintptr) bitset {
v := uint64(g) ^ (bitsetLSB * uint64(h))
return bitset(((v - bitsetLSB) &^ v) & bitsetMSB)
}
如果不替换,对ctrlGroupMatchH2函数用dlv追踪,可以得到如下汇编内容:
(dlv) disass
TEXT main.ctrlGroupMatchH2(SB) /home/gofunc/map.go #可以看到相比SIMD指令优化后仅6行指令,不优化cpu就需要多执行这么多指令,效率就慢了
map.go:22 0x471360 55 push rbp
map.go:22 0x471361 4889e5 mov rbp, rsp
=> map.go:22 0x471364 4883ec10 sub rsp, 0x10
map.go:22 0x471368 4889442420 mov qword ptr [rsp+0x20], rax
map.go:22 0x47136d 48895c2428 mov qword ptr [rsp+0x28], rbx
map.go:22 0x471372 48c7042400000000 mov qword ptr [rsp], 0x0
map.go:23 0x47137a 48b90101010101010101 mov rcx, 0x101010101010101
map.go:23 0x471384 480fafcb imul rcx, rbx
map.go:23 0x471388 4831c8 xor rax, rcx
map.go:23 0x47138b 4889442408 mov qword ptr [rsp+0x8], rax
map.go:24 0x471390 48b9fffefefefefefefe mov rcx, 0xfefefefefefefeff
map.go:24 0x47139a 4801c1 add rcx, rax
map.go:24 0x47139d 48f7d0 not rax
map.go:24 0x4713a0 4821c8 and rax, rcx
map.go:24 0x4713a3 48b98080808080808080 mov rcx, 0x8080808080808080
map.go:24 0x4713ad 4821c8 and rax, rcx
map.go:24 0x4713b0 48890424 mov qword ptr [rsp], rax
map.go:24 0x4713b4 4883c410 add rsp, 0x10
map.go:24 0x4713b8 5d pop rbp
map.go:24 0x4713b9 c3 ret
五、参考
1]:google cpp swisstable
2]:新式哈希表 - Swiss Tables
3]:Go map使用Swiss Table重新实现
4]:Go1.24版本中map性能提升的底层奥秘解析
5]:Go1.24 新特性:map 换引擎,性能显著提高


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









