






论文来源:Liu H M , Yang Y H . Lead Sheet Generation and Arrangement by Conditional Generative Adversarial Network[C]// 2018 17th IEEE International Conference on Machine Learning and Applications (ICMLA). IEEE, 2018.
这是一篇利用GAN网络进行音乐创作的论文
摘要
随着深度神经网络的发展,自动生成音乐的研究取得了很大的进展。然而,任意音乐类型的多乐器的音乐生成仍然是一个挑战。现有的研究要么是基于功能谱(Lead Sheet)要么是基于MIDI的多音轨钢琴卷(pianoroll),但这两种音乐记录方式都有其局限性。在这项工作中,我们提出了一个新的任务,称为功能谱编排(Lead Sheet Arrangement),以避免这种限制。提出了一种新的卷积生成模型,并结合三种符号域的和谐特征来促进不配对的Lead Sheet和MIDI文件之间的学习。我们的模型可以生成Lead Sheet和八个小节的编排(Arrangement)。
导言
近年来,由于深度神经网络的发展,机器(或人工智能)的自动音乐生成技术重新引起了学术界和公众的极大关注。尽管这种技术还不是很成熟,但是研究人员经常假设,只要有足够的条件,机器可以学习人们用来创作音乐的规则,甚至可以创造新的规则训练数据量(即现有音乐)和适当的神经网络结构。由于研究界的不断努力,深层神经网络已经成功地生成了单音旋律或某些音乐类型的复音音乐,如巴赫合唱团和钢琴独奏。
剩下的主要挑战之一是产生任意体裁的复调音乐。根据目标的音乐记录形式,现有作品可分为两种。第一种研究的目的是创建由旋律走向与和弦组成的lead sheet,示例见图1(a)。lead sheet可以看作是音乐的中间产物。在这种形式中,旋律是明确规定的,但伴奏部分仅由和弦标签组成。它没有描述 chord voicings, voice leading, bass line or other aspects of the accompaniment.。(译者注:这几种都是音乐术语,可以上维基百科上查查。不影响论文阅读,只要知道lead sheet有缺陷就好)。演奏和弦的方式留给了演奏者自己去理解。总得来说,和弦的节奏丢失了。
另一组研究旨在生成能够包含voicing和不同乐器之间编排信息的MIDI格式音乐。一个MIDI文件可以被数个pianoroll来表示每个时间内每个乐器的音符。例如,一首表示有4种乐器的乐队的歌曲的MIDI文件,将有4张pianoroll,一张代表一个乐器:旋律吉他、节奏吉他、贝斯和鼓。一个MIDI文件包含每个乐器要弹奏的细节信息。但是它有个很大的问题在于,MIDI文件不指明哪个乐器弹奏旋律哪个乐器弹奏和弦。
一个有趣但却很少被研究的话题是在上述两种形式中间产生某种东西。我们称之为功能谱编排(Lead Sheet Arrangement)。编排(Arrangement)是一种赋予现有旋律音乐多样性的艺术。这可以理解为根据功能谱上的和弦标签,将旋律或独奏与其他乐器合奏的过程。例如,图1(b)显示了流行福音歌曲《Amazing Grace》的功能谱。我们看到它显示了和弦是如何演奏的。在不同音乐类型中都可以看到编排。在古典音乐中,编排是用在奏鸣曲、弦乐四重奏等基本类型中,也用在交响乐等更为复杂的类型中。在爵士乐中,编排常被用来伴奏独奏乐器。现在流行音乐也有很多的编排设置,以增加音乐的多样性和丰富性。
 计算上,我们将功能谱编排定义为“将一个lead sheet 输入并生成一个有数个乐器与旋律合奏的pianoroll”的过程。换句话说,在生成过程种,功能谱是作为一个“条件(condition)”参与其中。例如,在生成完成时,我们想生成包含弦乐、钢琴、吉他、鼓点和贝斯的pianoroll。和MIDI文件对比,由于旋律走向更为清晰,这种通过功能谱编排产生的结果在音乐层面上包含更多信息。
计算上,我们将功能谱编排定义为“将一个lead sheet 输入并生成一个有数个乐器与旋律合奏的pianoroll”的过程。换句话说,在生成过程种,功能谱是作为一个“条件(condition)”参与其中。例如,在生成完成时,我们想生成包含弦乐、钢琴、吉他、鼓点和贝斯的pianoroll。和MIDI文件对比,由于旋律走向更为清晰,这种通过功能谱编排产生的结果在音乐层面上包含更多信息。
就我们所知,之前并没有相关的功能谱编排的工作,很大可能是因为缺少同一首曲子即含有功能谱又有MIDI版本的数据集。我们的论文对目前的状况提出三种贡献:
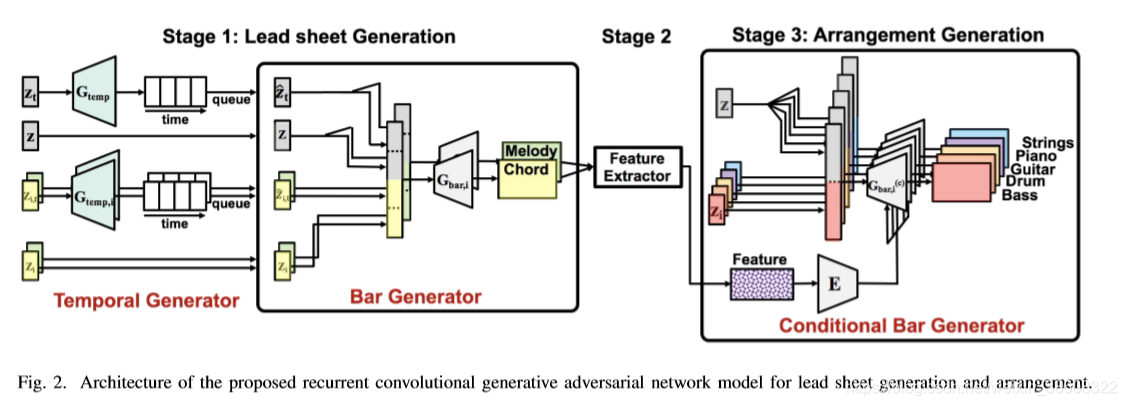
第一,我们提出了一种新的条件对抗生成网络来学习不成对的功能谱和MIDI数据集。如图2所示,这个过程有三个阶段:功能谱生成、特征提取、编排生成。中间那一步在从给定的功能谱去调整编排的生成时中提取符号域里的特征(harmonic features)的过程中起到很重要的作用。为了让条件生成变为可能,我们使用的特征是既能从功能谱又能从MIDI文件中提取的特征。
第二,我们提出并证实了这三种特征(harmonic features)可以在功能谱编排中连接功能谱和MIDI文件。他们分别是:chroma piano-roll features, chroma beats features, and chord piano-roll features(这三个实在不知道怎么翻译)。
第三,我们将CGAN模型(曾应用到多音轨的pianoroll的生成)应用到功能谱和编排的生成中去,因为功能谱可以看成是双音轨的pianoroll生成,编排生成可以看成有条件的五音轨pianorll的生成。为了更好的提取特征,我们稍微修改了下模型,在时序生成器(图2中表示为G(temp)和G(temp,i))中用循环层(recurrent layers)替换了卷积层(convolutional layers)。
在我们的实验中,我们分别通过主观指标和客观指标评估了生成的功能谱的组成和编排模型的综合性能。基于开源的想法,我们会设立一个GitHub仓库分享我们的代码和生成的音乐。
相关工作
很多深度学习的模型都提出了功能谱的生成,大概是因为功能谱经常用于流行音乐。功能谱生成可以通过三种方式完成:给定和弦生成旋律、给定旋律生成和弦、从噪音中生成旋律与和弦。一些最近的模型不仅生成了旋律与和弦,还有鼓点。但是,模型的最终目标还是只能生成一系列的和弦标签,而没有chord voicing和comping。
为了生成多音轨/乐器的音乐,Dong提出了MuseGAN,一种卷积GAN模型,可以从MIDI中学习并生成多音轨的pianoroll。MuseGAN创作的音乐有5个音轨(弦乐、钢琴、吉他、鼓、贝斯);紧接着MuseGAN又引入二值化的概念,生成了八音轨的音乐。**(然后这里说了很多别人的工作,不翻译了)**总而言之,他们不能区别哪个音轨演奏哪个旋律。
这里还有其他的模型生成了多音轨的音乐。**(这里也是说了很多别人的工作,不翻译了)**然而,这些模型都是基于RNN。对比利用CNN的模型,这些方法在学习时序结构上很好,但缺少了音乐本身的特征。
提出模型
提出的模型有三个阶段:lead sheet generation, feature extraction, and arrangement generation,如图2所示。
A. 数据表示
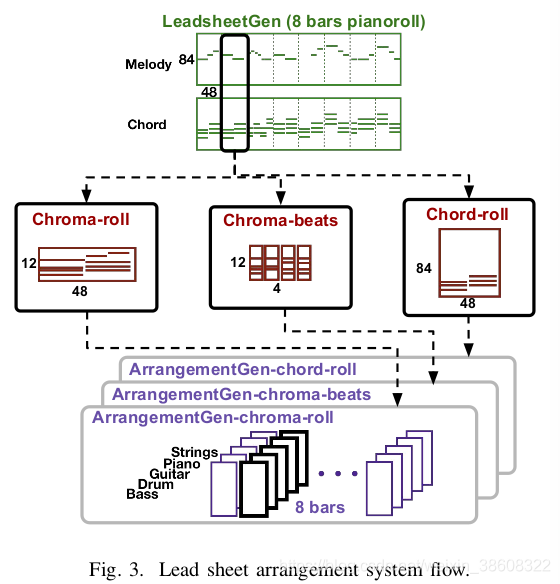
为了处理多音轨音乐,我们采用pianoroll作为我们数据的格式。一个pianoroll被表示为一个二值乐谱式的矩阵。它的x轴和y轴分别记录时间步长和音高。一个N音轨一小节(bar)的pianoroll被表示为张量X∈{0,1}T×P×N,其中T表示一个小节中的时间步长,P表示音高种类(84种)。功能谱和MIDI文件都可以转化为pianoroll。例如,如图3上部分所示,一个功能谱可以看成是双音轨的pianoroll。
B. 功能谱生成
我们这个模型的目的是从噪音中生成八个小节的功能谱。如图2左边所示,它包含里两个生成模型:时序生成模型Gtemp和小节生成模型Gbar。时序生成模型负责小节之间的时序关系,并且它的输出是小节生成模型输入的一部分。小节生成器一次生成音乐的一小节。因为功能谱每一小节的pianoroll都有两张和图片类似的矩阵(一个是旋律,一个是和弦),我们可以在Gbar使用基于CNN的模型。
为了生成真实的音乐,我们遵循GAN的原理,通过对抗的方式训练生成器。在训练时,我们特别训练里一个基于CNN的鉴别器D(图2中没有显示)来辨别真实功能谱和Gbar的输出。当训练D时,Gtemp和Gbar同时修正,并且训练目标是最小化D的分类损失(classification loss)。另一方面,当训练Gtemp和Gbar时,我们修正D并且训练目标是最大化D的分类损失。这个对抗训练的结果是,Gtemp和Gbar会学会生成像真实功能谱的结果。
基于MuseGAN,我们用四种随机噪声 z 作为我们的输入,来捕捉时间依赖/不依赖和音轨间依赖/不依赖四种特征。然而,不像MuseGAN,我们用两层的RNN模型来代替Gtemp的CNN层。经验上来说,RNN能更好捕捉功能谱中重复性的特征。虽然这个综合循环-卷积的网络模型并不新,但就我们所知是第一个用RCNN模型生成功能谱的。
C. 编排的生成
编排生成模型的目标,在图2中表示为右边的条件小节生成器Gbar( c ),是在从功能谱提取出的特征上生成一小节长5音轨的pianoroll。这个过程也被表示在图3中。我们一次生成一个小节的编排,直到八个小节的编排都被生成且连接到一起。我们也利用GAN的原理来训练Gbar( c )和D( c )。两者都是基于CNN模型。
在图2的右下角,我们随着Gbar( c )训练了一个基于CNN的编码器E,来将从中间那个特征提取器提取出的特征,嵌入到Gbar( c )和D( c )的中间层的输出中相对应的位置。
D. 特征提取
给定功能谱,有人认为我们可以直接用旋律走向或和弦序列来控制编排的生成。但是实际操作中并没有这么容易,因为训练集中几乎没有MIDI文件有旋律音轨和和弦音轨。我们有的MIDI一般是多音轨pianoroll。(吐槽一下,诺丁汗数据集不就是旋律+音轨吗?)。我们需要调整gnp和MIDI文件到同样的特征空间来,条件生成才有可能。
我们通过从功能谱和MIDI中提取和谐特征(harmonic features)来解决这个问题。在这个方法中,编排是在功能谱和谐部分的条件下生成的。我们提出下面三种符号域的和谐特征。(如图3所示)。
- chroma-roll
这个特征的想法是通过忽略音高的八度压缩音高的范围到12种,生成一个小节12×48的矩阵。这个特征被用过了(大概这两句就这意思)。对于功能谱,我们从旋律与和弦的pianoroll计算chroma。对于MIDI,我们对N音轨pianoroll进行同样操作。 - chroma-beats
对chroma-roll,我们通过从取每个beat(一个beat12个时间步长)的平均值,进一步减小维度,生成一个小节12×4的矩阵。这个特征可以减少占用特征空间,但缺点是会丢失很多时序上的细节信息。 - chord-roll
不用chroma特征,我们从功能谱和MIDI里评估和弦标签来增加和声的信息。这是通过首先分析功能谱或MIDI的音频文件,然后将一个音频域的和弦识别模型应用到上面来进行和弦评测。我们使用Madmom库中的DeepChroma模型,来识别每个用pianoroll表示的beat中12种主要的和弦与12种次要的和弦,这个beat是没有经过压缩成chroma的。这个结果每个beat产生84×84的矩阵。我们不使用功能谱中的和弦标签,因为我们希望功能谱和MIDI可以统一特征。
实施
这部分展示了用在我们实验中的数据集和一些技术细节。
A.数据集
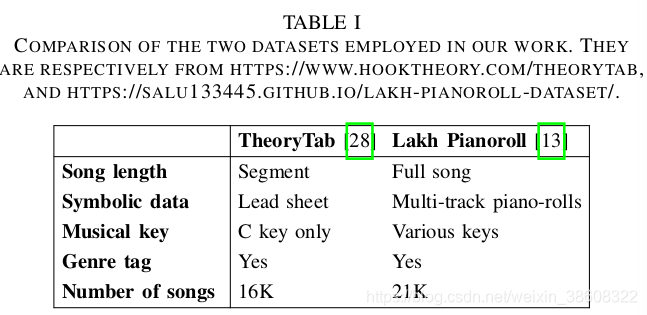
我们使用TheoryTab数据集作为功能谱,Lakh piano-roll数据集作为多音轨pianoroll数据来源。我们在表1中总结里两个数据集并在下面展示我们怎么处理这些数据。
- TheoryTab Dataset(TTD)包含16K个保存为XML格式的功能谱片段。因为它用音级(scale degree)来表示和弦标签,我们将所有曲目都看作C调的。我们解析每一个XML文件并将旋律与和弦转化为两个pianoroll。对每一个小节,我们设定高度为84(表示音高C1到B7),宽度(时间跨度)为48。因为我们想生成八小节的功能谱,所以目标输出的张量的形状(shape)应该是8(bar)×48(time steps)×84(notes)×2(tracks)。我们使用TTD中所有的歌曲。因为TTD中歌曲的片段比8小节长,我们取8小节的最大倍数。(加入TTD片段长度为65,就取64)。
- Lakh Piano-roll Dataset (LPD)是从Lakh MIDI dataset变化而来。我们使用lpd-5-cleaned子集,其中包括211425个5音轨pianoroll,这些都是摇滚乐且4/4拍的。这5个音轨分别是:弦乐、钢琴、吉他、鼓、贝斯。因为这些歌曲都是不同调的,我们用pretty_midi库将所有歌曲转换到C调上。因为编排生成的目标是一次生成一小节,所以数据集处理为1(bar)×48(time steps)×84(notes)×5(tracks)
B. 模型参数设定
功能谱生成模型中的Gtemp使用两层的RNN,有4个输出和32个隐藏层单元。Gbar、Gbar( c )、D和D( c )都是使用CNN。Gbar和Gbar( c )的随机噪声输入向量z都设定为128。编排生成中的编码器E,我们应用跳跃连接(skip connect)和拓扑结构来编码上述《提出模型-D》中的三个特征。我们使用WGAN-gp来训练模型。每个模型都用Tesla K80m显卡训练少于24小时,batchsize=64。
实验和结论
这部分就是分析实验的结果和最后总结,没啥好翻译的

















 5156
5156

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









