







转自:https://morvanzhou.github.io/tutorials/machine-learning/tensorflow/
感谢莫烦!爱你
处理结构
计算图纸
Tensorflow 首先要定义神经网络的结构, 然后再把数据放入结构当中去运算和 training.
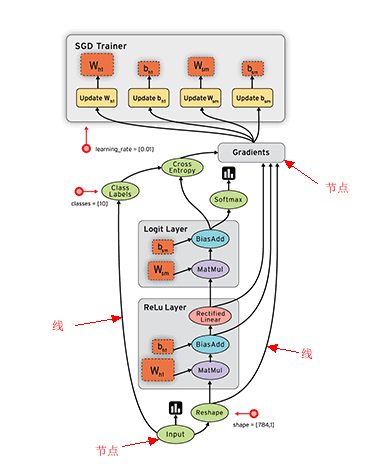
因为TensorFlow是采用数据流图(data flow graphs)来计算, 所以首先我们得创建一个数据流流图, 然后再将我们的数据(数据以张量(tensor)的形式存在)放在数据流图中计算. 节点(Nodes)在图中表示数学操作,图中的线(edges)则表示在节点间相互联系的多维数据数组, 即张量(tensor). 训练模型时tensor会不断的从数据流图中的一个节点flow到另一节点, 这就是TensorFlow名字的由来.
Tensor 张量意义
张量(Tensor):
- 张量有多种. 零阶张量为 纯量或标量 (scalar) 也就是一个数值. 比如 [1]
- 一阶张量为 向量 (vector), 比如 一维的 [1, 2, 3]
- 二阶张量为 矩阵 (matrix), 比如 二维的 [[1, 2, 3],[4, 5, 6],[7, 8, 9]]
- 以此类推, 还有 三阶 三维的 …
例子2
创建数据
首先, 我们这次需要加载 tensorflow 和 numpy 两个模块, 并且使用 numpy 来创建我们的数据.
import tensorflow as tf
import numpy as np
# create data
x_data = np.random.rand(100).astype(np.float32)
y_data = x_data*0.1 + 0.3接着, 我们用 tf.Variable 来创建描述 y 的参数. 我们可以把 y_data = x_data*0.1 + 0.3 想象成 y=Weights * x + biases, 然后神经网络也就是学着把 Weights 变成 0.1, biases 变成 0.3.
搭建模型
Weights = tf.Variable(tf.random_uniform([1], -1.0, 1.0))
biases = tf.Variable(tf.zeros([1]))
y = Weights*x_data + biases计算误差
接着就是计算 y 和 y_data 的误差:
loss = tf.reduce_mean(tf.square(y-y_data))传播误差
反向传递误差的工作就教给optimizer了, 我们使用的误差传递方法是梯度下降法: Gradient Descent 让后我们使用 optimizer 来进行参数的更新.
optimizer = tf.train.GradientDescentOptimizer(0.5)
train = optimizer.minimize(loss)训练
到目前为止, 我们只是建立了神经网络的结构, 还没有使用这个结构. 在使用这个结构之前, 我们必须先初始化所有之前定义的Variable, 所以这一步是很重要的!
# init = tf.initialize_all_variables() # tf 马上就要废弃这种写法
init = tf.global_variables_initializer() # 替换成这样就好接着,我们再创建会话 Session. 我们会在下一节中详细讲解 Session. 我们用 Session 来执行 init 初始化步骤. 并且, 用 Session 来 run 每一次 training 的数据. 逐步提升神经网络的预测准确性.
sess = tf.Session()
sess.run(init) # Very important
for step in range(201):
sess.run(train)
if step % 20 == 0:
print(step, sess.run(Weights), sess.run(biases))Session 会话控制
简单运用
欢迎回来!这一次我们会讲到 Tensorflow 中的 Session, Session 是 Tensorflow 为了控制,和输出文件的执行的语句. 运行 session.run() 可以获得你要得知的运算结果, 或者是你所要运算的部分.
首先,我们这次需要加载 Tensorflow ,然后建立两个 matrix ,输出两个 matrix 矩阵相乘的结果。
import tensorflow as tf
# create two matrixes
matrix1 = tf.constant([[3,3]])
matrix2 = tf.constant([[2],
[2]])
product = tf.matmul(matrix1,matrix2)因为 product 不是直接计算的步骤, 所以我们会要使用 Session 来激活 product 并得到计算结果. 有两种形式使用会话控制 Session 。
# method 1
sess = tf.Session()
result = sess.run(product)
print(result)
sess.close()
# [[12]]
# method 2
with tf.Session() as sess:
result2 = sess.run(product)
print(result2)
# [[12]]Variable变量
简单运用
这节课我们学习如何在 Tensorflow 中使用 Variable .
在 Tensorflow 中,定义了某字符串是变量,它才是变量,这一点是与 Python 所不同的。
定义语法: state = tf.Variable()
import tensorflow as tf
state = tf.Variable(0, name='counter')
# 定义常量 one
one = tf.constant(1)
# 定义加法步骤 (注: 此步并没有直接计算)
new_value = tf.add(state, one)
# 将 State 更新成 new_value
update = tf.assign(state, new_value)如果你在 Tensorflow 中设定了变量,那么初始化变量是最重要的!!所以定义了变量以后, 一定要定义 init = tf.initialize_all_variables() .
到这里变量还是没有被激活,需要再在 sess 里, sess.run(init) , 激活 init 这一步.
# 如果定义 Variable, 就一定要 initialize
# init = tf.initialize_all_variables() # tf 马上就要废弃这种写法
init = tf.global_variables_initializer() # 替换成这样就好
# 使用 Session
with tf.Session() as sess:
sess.run(init)
for _ in range(3):
sess.run(update)
print(sess.run(state))注意:直接 print(state) 不起作用!!
一定要把 sess 的指针指向 state 再进行 print 才能得到想要的结果!
Placeholder传入值
简单运用
这一次我们会讲到 Tensorflow 中的 placeholder , placeholder 是 Tensorflow 中的占位符,暂时储存变量.
Tensorflow 如果想要从外部传入data, 那就需要用到 tf.placeholder(), 然后以这种形式传输数据 sess.run(*, feed_dict={input: }).
示例:
import tensorflow as tf
#在 Tensorflow 中需要定义 placeholder 的 type ,一般为 float32 形式
input1 = tf.placeholder(tf.float32)
input2 = tf.placeholder(tf.float32)
# mul = multiply 是将input1和input2 做乘法运算,并输出为 output
ouput = tf.multiply(input1, input2)接下来, 传值的工作交给了 sess.run() , 需要传入的值放在了feed_dict={} 并一一对应每一个 input. placeholder 与 feed_dict={} 是绑定在一起出现的。
with tf.Session() as sess:
print(sess.run(ouput, feed_dict={input1: [7.], input2: [2.]}))
# [ 14.]什么是激励函数
非线性方程
我们为什么要使用激励函数? 用简单的语句来概括. 就是因为, 现实并没有我们想象的那么美好, 它是残酷多变的. 哈哈, 开个玩笑, 不过激励函数也就是为了解决我们日常生活中 不能用线性方程所概括的问题. 好了,我知道你的问题来了. 什么是线性方程 (linear function)?
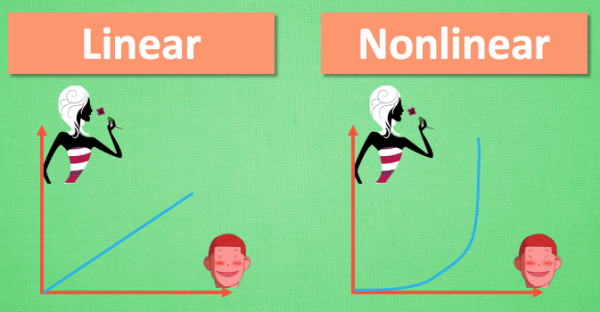
说到线性方程, 我们不得不提到另外一种方程, 非线性方程 (nonlinear function). 我们假设, 女生长得越漂亮, 越多男生爱. 这就可以被当做一个线性问题. 但是如果我们假设这个场景是发生在校园里. 校园里的男生数是有限的, 女生再漂亮, 也不可能会有无穷多的男生喜欢她. 所以这就变成了一个非线性问题.再说..女生也不可能是无穷漂亮的. 这个问题我们以后有时间私下讨论.
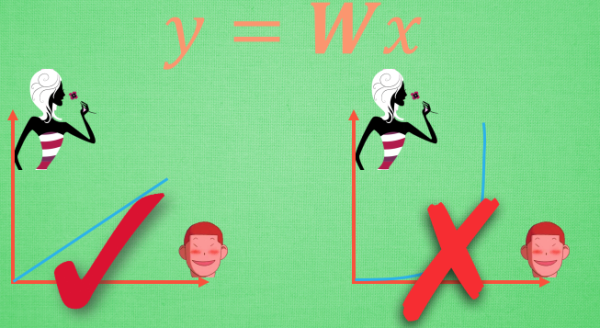
然后我们就可以来讨论如何在神经网络中达成我们描述非线性的任务了. 我们可以把整个网络简化成这样一个式子. Y = Wx, W 就是我们要求的参数, y 是预测值, x 是输入值. 用这个式子, 我们很容易就能描述刚刚的那个线性问题, 因为 W 求出来可以是一个固定的数. 不过这似乎并不能让这条直线变得扭起来 , 激励函数见状, 拔刀相助, 站出来说道: “让我来掰弯它!”.
激励函数
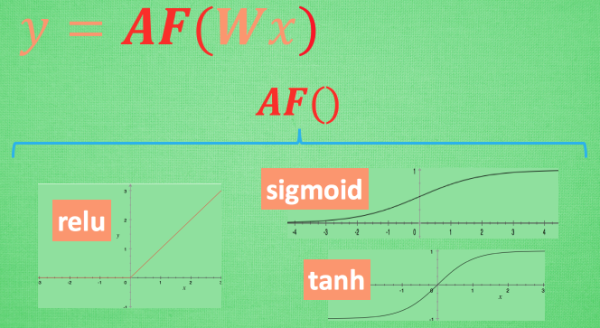
这里的 AF 就是指的激励函数. 激励函数拿出自己最擅长的”掰弯利器”, 套在了原函数上 用力一扭, 原来的 Wx 结果就被扭弯了.
其实这个 AF, 掰弯利器, 也不是什么触不可及的东西. 它其实就是另外一个非线性函数. 比如说relu, sigmoid, tanh. 将这些掰弯利器嵌套在原有的结果之上, 强行把原有的线性结果给扭曲了. 使得输出结果 y 也有了非线性的特征. 举个例子, 比如我使用了 relu 这个掰弯利器, 如果此时 Wx 的结果是1, y 还将是1, 不过 Wx 为-1的时候, y 不再是-1, 而会是0.
你甚至可以创造自己的激励函数来处理自己的问题, 不过要确保的是这些激励函数必须是可以微分的, 因为在 backpropagation 误差反向传递的时候, 只有这些可微分的激励函数才能把误差传递回去.
常用选择
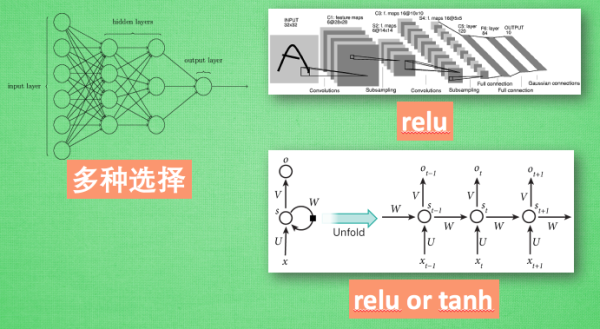
想要恰当使用这些激励函数, 还是有窍门的. 比如当你的神经网络层只有两三层, 不是很多的时候, 对于隐藏层, 使用任意的激励函数, 随便掰弯是可以的, 不会有特别大的影响. 不过, 当你使用特别多层的神经网络, 在掰弯的时候, 玩玩不得随意选择利器. 因为这会涉及到梯度爆炸, 梯度消失的问题. 因为时间的关系, 我们可能会在以后来具体谈谈这个问题.
最后我们说说, 在具体的例子中, 我们默认首选的激励函数是哪些. 在少量层结构中, 我们可以尝试很多种不同的激励函数. 在卷积神经网络 Convolutional neural networks 的卷积层中, 推荐的激励函数是 relu. 在循环神经网络中 recurrent neural networks, 推荐的是 tanh 或者是 relu (这个具体怎么选, 我会在以后 循环神经网络的介绍中在详细讲解).
激励函数
激励函数运行时激活神经网络中某一部分神经元,将激活信息向后传入下一层的神经系统。激励函数的实质是非线性方程。 Tensorflow 的神经网络 里面处理较为复杂的问题时都会需要运用激励函数 activation function 。 详细介绍请前往 “机器学习-简介系列” 激励函数















 985
985

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









