




 本文介绍Elasticsearch基础知识,包括安装配置、核心概念、API操作等内容,并提供Spring整合Elasticsearch的示例。
本文介绍Elasticsearch基础知识,包括安装配置、核心概念、API操作等内容,并提供Spring整合Elasticsearch的示例。
本文档是参考尚硅谷的文档简要总结的
链接:https://pan.baidu.com/s/1uZCxP3MDyRfTi9zvA4bZ-A
提取码:rrho
1、简介
The Elastic Stack, 包括 Elasticsearch、Kibana、Beats 和 Logstash(也称为 ELK Stack)。
能够安全可靠地获取任何来源、任何格式的数据,然后实时地对数据进行搜索、分析和可视
化。Elaticsearch,简称为 ES,ES 是一个开源的高扩展的分布式全文搜索引擎,是整个ElasticStack 技术栈的核心。它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理 PB 级别的数据。
es是基于Lucene搜索引擎库开发的
Lucene可以被认为是迄今为止最先进、性能最好的、功能最全的搜索引擎库(框 架),但是想要使用Lucene,必须使用Java来作为开发语言并将其直接集成到你的应用 中,并且Lucene的配置及使用非常复杂,你需要深入了解检索的相关知识来理解它 是如何工作的。
Lucene缺点:
- 1)只能在Java项目中使用,并且要以jar包的方式直接集成项目中.
- 2)使用非常复杂-创建索引和搜索索引代码繁杂
- 3)不支持集群环境-索引数据不同步(不支持大型项目)
- 4)索引数据如果太多就不行,索引库和应用所在同一个服务器,共同占用硬盘.共用空间少.
上述Lucene框架中的缺点,ES全部都能解决.
2、相关服务安装启动
ES安装启动
入门使用windows版本,Elasticsearch 的官方地址:https://www.elastic.co/cn/
不同版本下载地址:https://www.elastic.co/cn/downloads/past-releases#elasticsearch
https://github.com/elastic/elasticsearch
启动
当前使用版本为:elasticsearch-7.16.0
Windows 版的 Elasticsearch 的安装很简单,解压即安装完毕,解压后的 Elasticsearch 的
先修改jvm的参数,默认是4G,改小一点,config/jvm.options 配置文件

修改配置文件elasticsearch.yml:
cluster.name: xiao7
node.name: node-1
path.data: D:\env\elasticsearch-7.16.0/data
path.logs: D:\env\elasticsearch-7.16.0/logs
network.host: 0.0.0.0
http.port: 9200
discovery.seed_hosts: ["127.0.0.1"]
cluster.initial_master_nodes: ["node-1"]
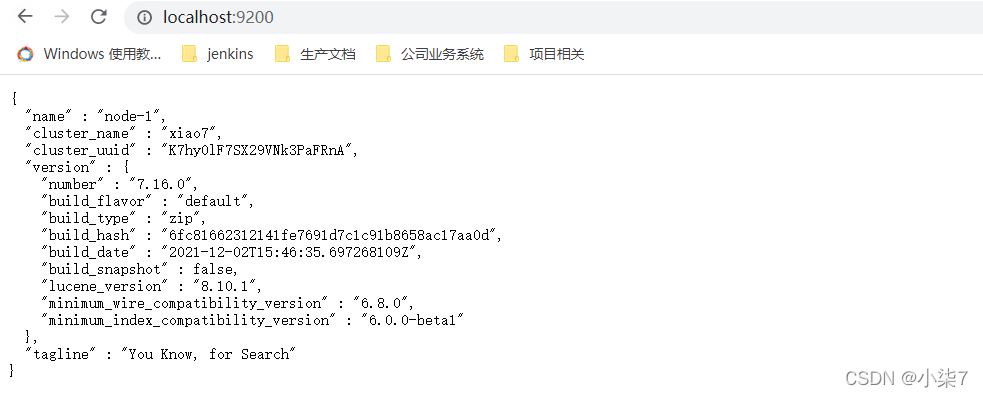
点击bin目录的elasticsearch.bat启动,输入地址:http://localhost:9200,测试结果
注意:9300 端口为 Elasticsearch 集群间组件的通信端口,9200 端口为浏览器访问的 http协议 RESTful 端口。
kibana安装启动
下载地址:https://www.elastic.co/cn/downloads/past-releases/kibana-7-16-0
修改配置文件:
elasticsearch.hosts: ["http://localhost:9200"]
server.host: "localhost"
server.port: 5601
直接启动
安装ik分词器
下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases
新建目录解压,重新启动

测试:
POST _analyze
{
"analyzer": "ik_max_word",
"text": "中华人民共和国"
}
Elasticsearch-head插件安装
添加配置:
node.master: true
node.data: true
下载地址:https://github.com/mobz/elasticsearch-head
解压到指定文件夹下,修改Gruntfile.js 在对应的位置加上hostname:'*'
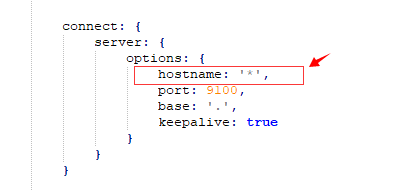
执行npm install 安装完成后执行grunt server 或者npm run start 运行head插件,如果不成功重新安装grunt。
3、核心概念
全文检索:
通过一个程序扫描文本中的每一个单词,针对单词建立索引,并保存该单词在文本中的位置、以及出现的次数。用户查询时,通过之前建立好的索引来查询,将索引中单词对应的文本位 置、出现的次数返回给用户,因为有了具体文本的位置,所以就可以将具体内容读取出来了。
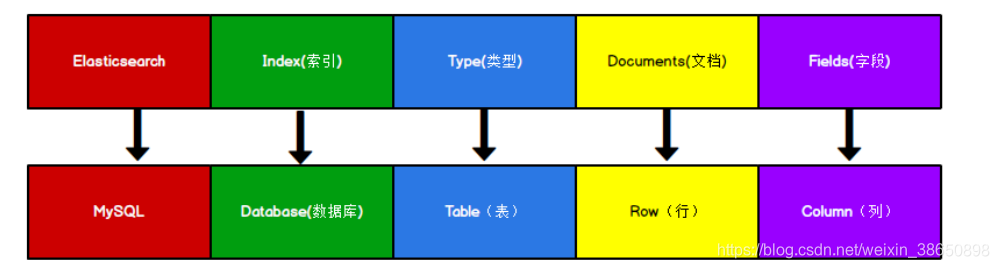
Elasticsearch 是面向文档型数据库,一条数据在这里就是一个文档。
Index可以看做一个库Types相当于表Documents则相当于表的行。
这里 Types 的概念已经被逐渐弱化,Elasticsearch 6.X 中,一个 index 下已经只能包含一个type,Elasticsearch 7.X 中, Type 的概念已经被删除了。
-
索引(Index):一个索引就是一个拥有几分相似特征的文档的集合。比如说,你可以有一个客户数据的索引,另一个产品目录的索引,还有一个订单数据的索引。一个索引由一个名字来标识(必须全部是小写字母),并且当我们要对这个索引中的文档进行索引、搜索、更新和删除的时候,都要使用到这个名字。在一个集群中,可以定义任意多的索引。能搜索的数据必须索引,这样的好处是可以提高查询速度,比如:新华字典前面的目录就是索引的意思,目录可以提高查询速度。Elasticsearch索引的精髓:一切设计都是为了提高搜索的性能。 -
文档(Document):一个文档是一个可被索引的基础信息单元,也就是一条数据,比如:你可以拥有某一个客户的文档,某一个产品的一个文档,当然,也可以拥有某个订单的一个文档。文档以JSON(Javascript Object Notation)格式来表示,而JSON是一个到处存在的互联网数据交互格式。在一个index里面,你可以存储任意多的文档。 -
映射(Mapping):mapping是处理数据的方式和规则方面做一些限制,如:某个字段的数据类型、默认值、分析器、是否被索引等等。这些都是映射里面可以设置的,其它就是处理ES里面数据的一些使用规则设置也叫做映射,按着最优规则处理数据对性能提高很大,因此才需要建立映射,并且需要思考如何建立映射才能对性能更好。 -
分片(Shards):一个索引可以存储超出单个节点硬件限制的大量数据。比如,一个具有10亿文档数据的索引占据1TB的磁盘空间,而任一节点都可能没有这样大的磁盘空间。或者单个节点处理搜索请求,响应太慢。为了解决这个问题,Elasticsearch提供了将索引划分成多份的能力,每一份就称之为分片。当你创建一个索引的时候,你可以指定你想要的分片的数量。每个分片本身也是一个功能完善并且独立的“索引”,这个索引可以被放置到集群中的任何节点上。分片很重要,主要有两方面的原因:1、允许你水平分割 / 扩展你的内容容量。
2、允许你在分片之上进行分布式的、并行的操作,进而提高性能/吞吐量。至于一个分片怎样分布,它的文档怎样聚合和搜索请求,是完全由 Elasticsearch 管理的,对于作为用户的你来说,这些都是透明的,无需过分关心。
-
副本(Replicas):在一个网络 /云的环境里,失败随时都可能发生,在某个分片/节点不知怎么的就处于离线状态,或者由于任何原因消失了,这种情况下,有一个故障转移机制是非常有用并且是强烈推荐的。为此目的,Elasticsearch允许你创建分片的一份或多份拷贝,这些拷贝叫做复制分片(副本)。 -
复制分片之所以重要,有两个主要原因:
1、在分片/节点失败的情况下,提供了高可用性。因为这个原因,注意到复制分片从不与原/主要(
original/primary)分片置于同一节点上是非常重要的。
2、扩展你的搜索量/吞吐量,因为搜索可以在所有的副本上并行运行。 -
分配(Allocation):将分片分配给某个节点的过程,包括分配主分片或者副本。如果是副本,还包含从主分片复制数据的过程。这个过程是由master节点完成的
4、api操作
官方文档:https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html
核心类型(Core datatype)
- 字符串: string,string类型包含 text 和 keyword。
text:该类型被用来索引长文本,在创建索引前会将这些文本进行分词,转化为词的组合,建立索引;允许es来检索这些词,text类型不能用来排序和聚合。keyword:该类型不能分词,可以被用来检索过滤、排序和聚合,keyword类型不 可用text进行分词模糊检索。- 数值型: long、integer、short、byte、double、float
- 日期型: date 布尔型:boolean
索引文档基本操作
-
创建索引 :
PUT /索引名称 举例: PUT /es_db)put /user { "mappings" : { "properties" : { "age" : { "type" : "long" }, "content" : { "type" : "text", "analyzer":"my_analyzer" }, "id" : { "type" : "long" }, "name" : { "type" : "text" }, "sex" : { "type" : "keyword" } } }, "settings" : { "index" : { "analysis" : { "analyzer" : { "default" : { "type" : "ik_max_word" }, "my_analyzer": { "type": "ik_max_word", //设置分词器为standard "max_token_length": 5, //设置分词最大为5 "stopwords": "" //设置过滤词 } } } } } } } -
查询索引 :
GET /索引名称 举例: GET/es_db) -
删除索引:
DELETE /索引名称 举例: DELETE /es_db) -
获取文档映射:
GET /es_db/_mapping -
添加文档 :
PUT/索引名称/类型/idPUT /es_db/_doc/1 { "name": "张三", "sex": 1, "age": 25, "address": "广州天河公园", "remark": "java developer" } -
修改文档:同添加文档一致
-
查询文档:GET /索引名称/类型/id
-
删除文档:DELETE /索引名称/类型/id
查询基本操作
-
查询当前类型中的所有文档:
GET /索引名称/类型/_search -
条件查询, 如要查询age等于28岁的:
GET /es_db/_doc/_search?q=age:28 -
范围查询, 如要查询age在25至26岁之间的:
GET /es_db/_doc/_search?q=age[25 TO 26] -
根据多个ID进行批量查询
格式: GET /索引名称/类型/_mget 举例: GET /es_db/_doc/_mget { "ids":["1","2"] } -
查询年龄小于等于28岁的:
GET /es_db/_doc/_search?q=age:<=28 -
查询年龄大于28前的 :
GET /es_db/_doc/_search?q=age:>28 -
分页查询:
GET /es_db/_doc/_search?q=age[25 TO 26]&from=0&size=1 -
对查询结果只输出某些字段:
GET /es_db/_doc/_search?_source=name,age
批量查询操作
-
批量获取文档数据:
/index/_mget、_mget、/index/type/_mgetGET _mget { "docs": [ { "_index": "es_db", // 索引 "_type": "_doc", // 文档 "_id": 1, // id "_source":"name" // 查询字段 }, { "_index": "es_db", "_type": "_doc", "_id": 2 } ] } -
批量操作文档数据:
POST _bulk,第一行参数是操作类型,第二行开始是操作数据。示操作类型,主要有create,index,delete和updatePOST _bulk {"create":{"_index":"article", "_type":"_doc", "_id":3}} // 操作类型信息 {"id":3,"title":"白起老师1","content":"白起老师666","tags":["java", "象"],"create_time":1554015482530}
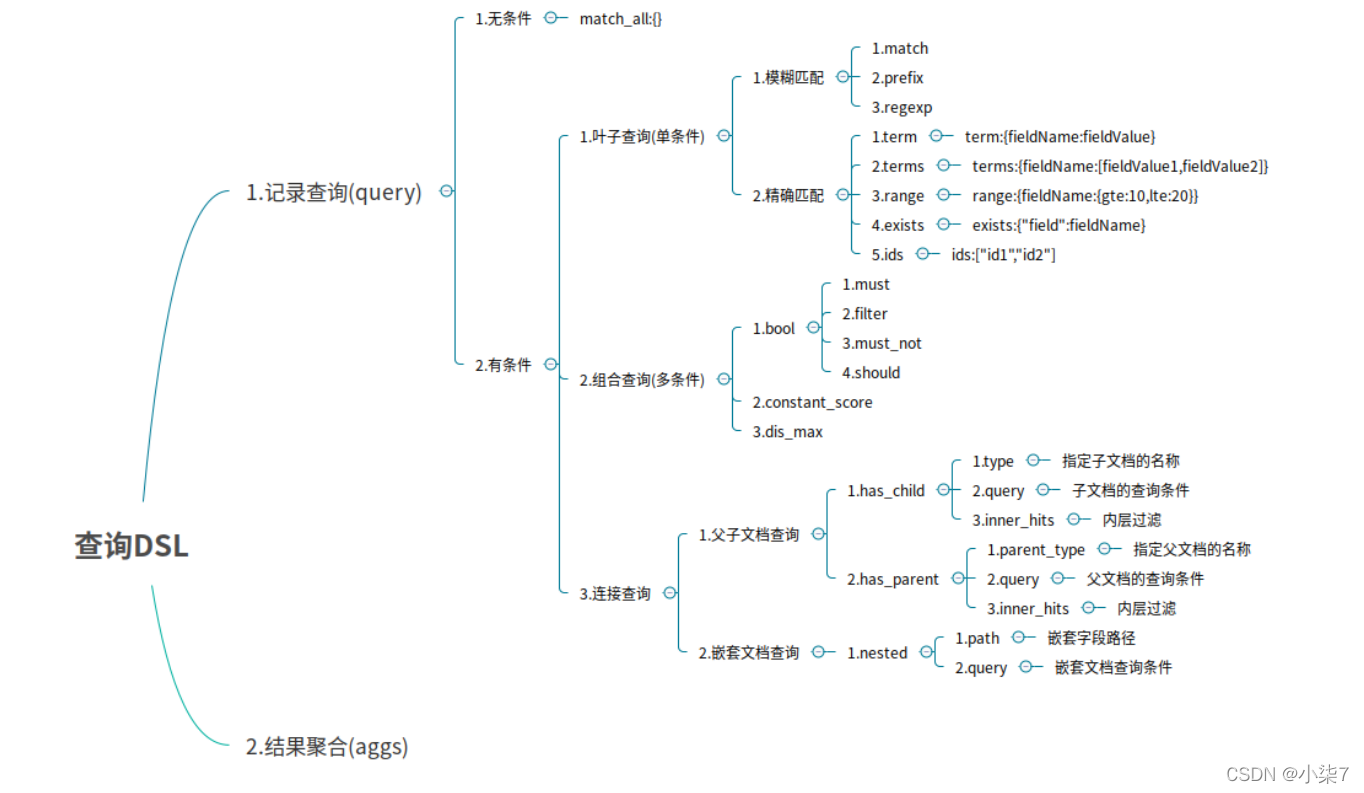
DSL语言高级查询
Domain Specific Language领域专用语言,Elasticsearch提供了基于JSON的DSL来定义查询。DSL由叶子查询子句和复合查询子句两种子句组成。
-
无条件查询: 无查询条件是查询所有,默认是查询所有的,或者使用
match_all表示所有。GET /user/_doc/_search { "query":{ "match_all":{} } } -
叶子查询模糊匹配:这三个不能同时使用
match : 通过match关键词模糊匹配条件内容
prefix : 前缀匹配
regexp : 通过正则表达式来匹配数据match条件还支持以下参数: query : 指定匹配的值 operator : 匹配条件类型 and : 条件分词后都要匹配 or : 条件分词后有一个匹配即可(默认) minmum_should_match : 指定最小匹配的数量 例子: GET /es_db/_doc/_search { "query":{ "match":{ "name":"2"}, "prefix":{} } } -
叶子查询精准匹配:
term : 单个条件相等
terms : 单个字段属于某个值数组内的值
range : 字段属于某个范围内的值
exists : 某个字段的值是否存在
ids : 通过ID批量查询GET /es_db1/_doc/_search { "query":{ "term":{ "address":"广州天河公园" } } } -
组合条件查询
bool : 各条件之间有and,or或not的关系
must : 各个条件都必须满足,即各条件是and的关系
should : 各个条件有一个满足即可,即各条件是or的关系
must_not : 不满足所有条件,即各条件是not的关系
filter : 不计算相关度评分,它不计算_score即相关度评分,效率更高POST _search { "query": { "bool" : { "must" : { "term" : { "user.id" : "kimchy" } }, "filter": { "term" : { "tags" : "production" } }, "must_not" : { "range" : { "age" : { "gte" : 10, "lte" : 20 } } }, "should" : [ { "term" : { "tags" : "env1" } }, { "term" : { "tags" : "deployed" } } ], "minimum_should_match" : 1, "boost" : 1.0 } } }
查询太多了,不一一列举,直接看官方文档…
新版本并发控制
ES新版本不使用version进行并发版本控制
if_seq_no=版本值&if_primary_term=文档位置_seq_no:文档版本号,作用同_version_primary_term:文档所在位置
POST /my_doc/_update/1/?if_seq_no=5&if_primary_term=1
{
"doc": {
"name": "xxx2"
}
}
5、Spring整合ES实现基本操作
我是用的客户端是7.6.2,es 服务是7.16,如果操作失败异常可以考虑下版本一致的问题
引入依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
添加配置
spring:
elasticsearch:
rest:
uris: http://localhost:9200
使用案例:直接注入使用或者
public static void main(String[] args) {
ConfigurableApplicationContext applicationContext = SpringApplication.run(ElasticsearchApplication.class, args);
ElasticsearchRestTemplate elasticsearchRestTemplate = applicationContext.getBean(ElasticsearchRestTemplate.class);
User user = new User();
user.setId(12243L);
user.setAge(18);
user.setContent("测试");
user.setSex("男");
user.setName("张三");
User save = elasticsearchRestTemplate.save(user);
// System.out.println(save);
NativeSearchQueryBuilder nativeSearchQueryBuilder = new NativeSearchQueryBuilder();
NativeSearchQuery searchQuery = nativeSearchQueryBuilder.withQuery(new BoolQueryBuilder()
.must(new MatchQueryBuilder("name", "张三")))
.build();
SearchHits<User> searchHits = elasticsearchRestTemplate.search(searchQuery, User.class);
for (SearchHit<User> searchHit : searchHits.getSearchHits()) {
System.out.println(searchHit.getContent());
}
}

















 1663
1663

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









