









ElasticSearch
什么是ElasticSearch?
ElasticSearch是一款非常强大的、基于Lucene的开源搜索及分析引擎;它是一个实时的分布式搜索分析引擎,它能让你以前所未有的速度和规模,去探索你的数据。
主要功能:全文检索、结构化搜索、分析
除了搜索,结合Kibana、Logstash、Beats开源产品,Elastic Stack(简称ELK)还被广泛运用在大数据近实时分析领域,包括:日志分析、指标监控、信息安全等。它可以帮助你探索海量结构化、非结构化数据,按需创建可视化报表,对监控数据设置报警阈值,通过使用机器学习,自动识别异常状况。
ElasticSearch的主要功能及应用场景
主要功能:
1)海量数据的分布式存储以及集群管理,达到了服务与数据的高可用以及水平扩展;
2)近实时搜索,性能卓越。对结构化、全文、地理位置等类型数据的处理;
3)海量数据的近实时分析(聚合功能)
应用场景:
1)网站搜索、垂直搜索、代码搜索;
2)日志管理与分析、安全指标监控、应用性能监控、Web抓取舆情分析;
ElasticSearch的基础概念
Near Realtime(NRT) 近实时。数据提交索引后,立马就可以搜索到。
Cluster 集群,一个集群由一个唯一的名字标识,默认为“elasticsearch”。集群名称非常重要,具有相同集群名的节点才会组成一个集群。集群名称可以在配置文件中指定。 **Node 节点:**存储集群的数据,参与集群的索引和搜索功能。像集群有名字,节点也有自己的名称,默认在启动时会以一个随机的UUID的前七个字符作为节点的名字,你可以为其指定任意的名字。通过集群名在网络中发现同伴组成集群。一个节点也可是集群。 Index 索引: 一个索引是一个文档的集合(等同于solr中的集合)。每个索引有唯一的名字,通过这个名字来操作它。一个集群中可以有任意多个索引。
**Type 类型:**指在一个索引中,可以索引不同类型的文档,如用户数据、博客数据。从6.0.0 版本起已废弃,一个索引中只存放一类数据。
**Document 文档:**被索引的一条数据,索引的基本信息单元,以JSON格式来表示。
**Shard 分片:**在创建一个索引时可以指定分成多少个分片来存储。每个分片本身也是一个功能完善且独立的“索引”,可以被放置在集群的任意节点上。
Replication 备份: 一个分片可以有多个备份(副本)
为了加深理解,和数据库做一个简单对比
Docker中ElasticSearch和Kibana安装
ElasticSearch安装
docker run --name elasticsearch -p 9200:9200 -p 9300:9300 \
-e "discovery.type=single-node" \
-e ES_JAVA_OPTS="-Xms64m -Xmx256m" \
-v /mydata/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \
-v /mydata/elasticsearch/data:/usr/share/elasticsearch/data \
-v /mydata/elasticsearch/plugins:/usr/share/elasticsearch/plugins \
-d elasticsearch:7.4.2
chmod -R 777 /mydata/elasticsearch/ 修改文件夹权限
echo "http.host: 0.0.0.0" >> /mydata/elasticsearch/config/elasticsearch.yml 保证任意ip可访问elasticsearch
Kibana安装
docker run --name kibana -e ELASTICSEARCH_HOSTS=http://xxx.xxx.xxx.xxx:9200 -p 5601:5601 \
-d kibana:7.4.2
基础语法
先准备一组数据https://github.com/elastic/elasticsearch/blob/v7.4.2/docs/src/test/resources/accounts.json
PUT bank/_bulk
{"index":{"_id":"1"}}
{"account_number":1,"balance":39225,"firstname":"Amber","lastname":"Duke","age":32,"gender":"M","address":"880 Holmes Lane","employer":"Pyrami","email":"amberduke@pyrami.com","city":"Brogan","state":"IL"}
.............................省略
查询所有
match_all表示查询所有的数据,sort即按照什么字段排序, from和size两个字段分页查询
GET /bank/_search
{
"query": { "match_all": {} },
"sort": [
{ "account_number": "asc" }
],
"from": 10,
"size": 10
}
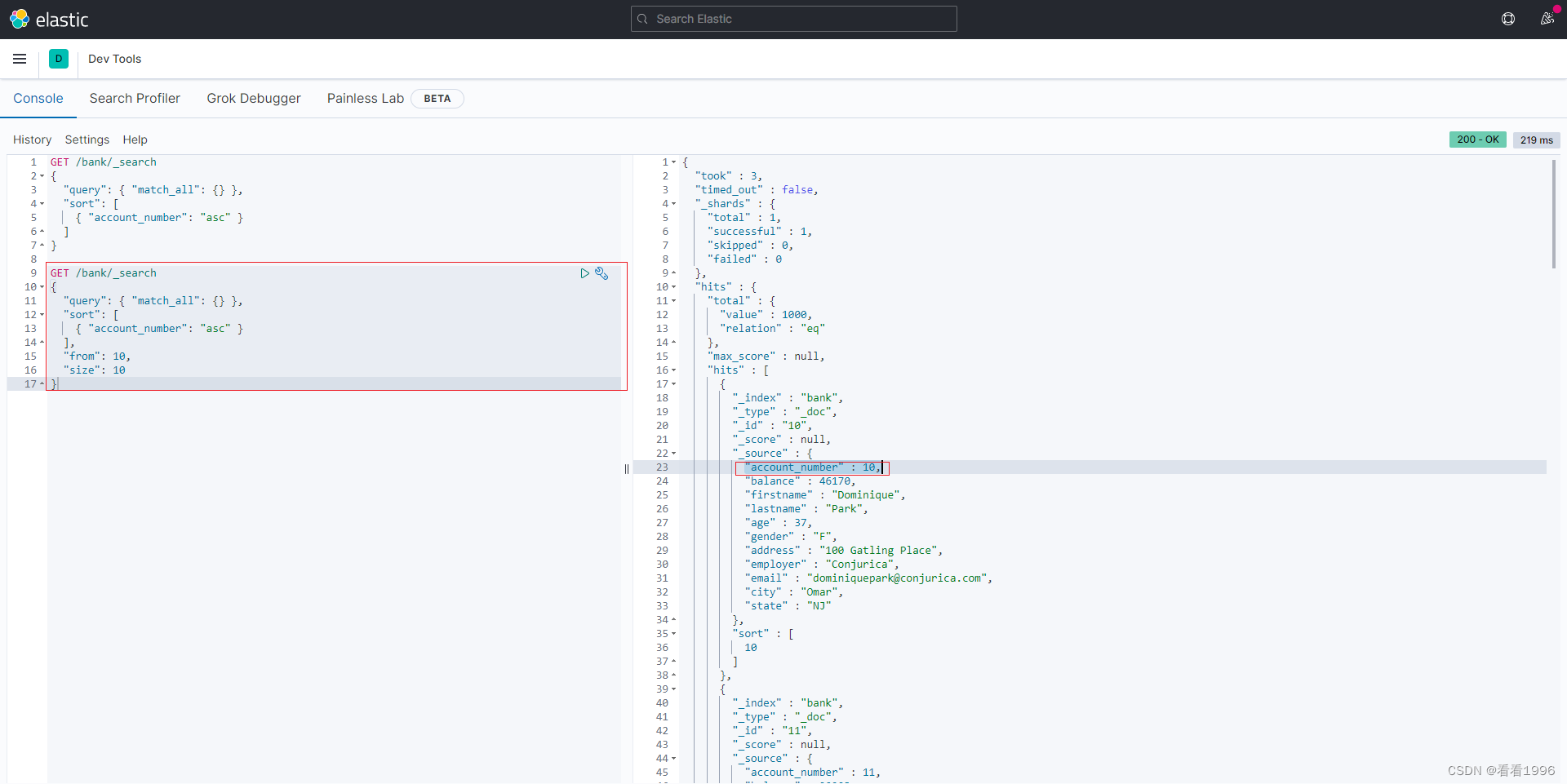
相关字段解释:
took – Elasticsearch运行查询所花费的时间(以毫秒为单位)
timed_out –搜索请求是否超时
_shards - 搜索了多少个碎片,以及成功,失败或跳过了多少个碎片的细目分类。
max_score – 找到的最相关文档的分数
hits.total.value - 找到了多少个匹配的文档
hits.sort - 文档的排序位置(不按相关性得分排序时)
hits._score - 文档的相关性得分(使用match_all时不适用)
指定字段查询:match
如果要在字段中搜索特定字词,可以使用match; 如下语句将查询address 字段中包含 mill 或者 lane的数据
GET /bank/_search
{
"query": { "match": { "address": "mill lane" } }
}
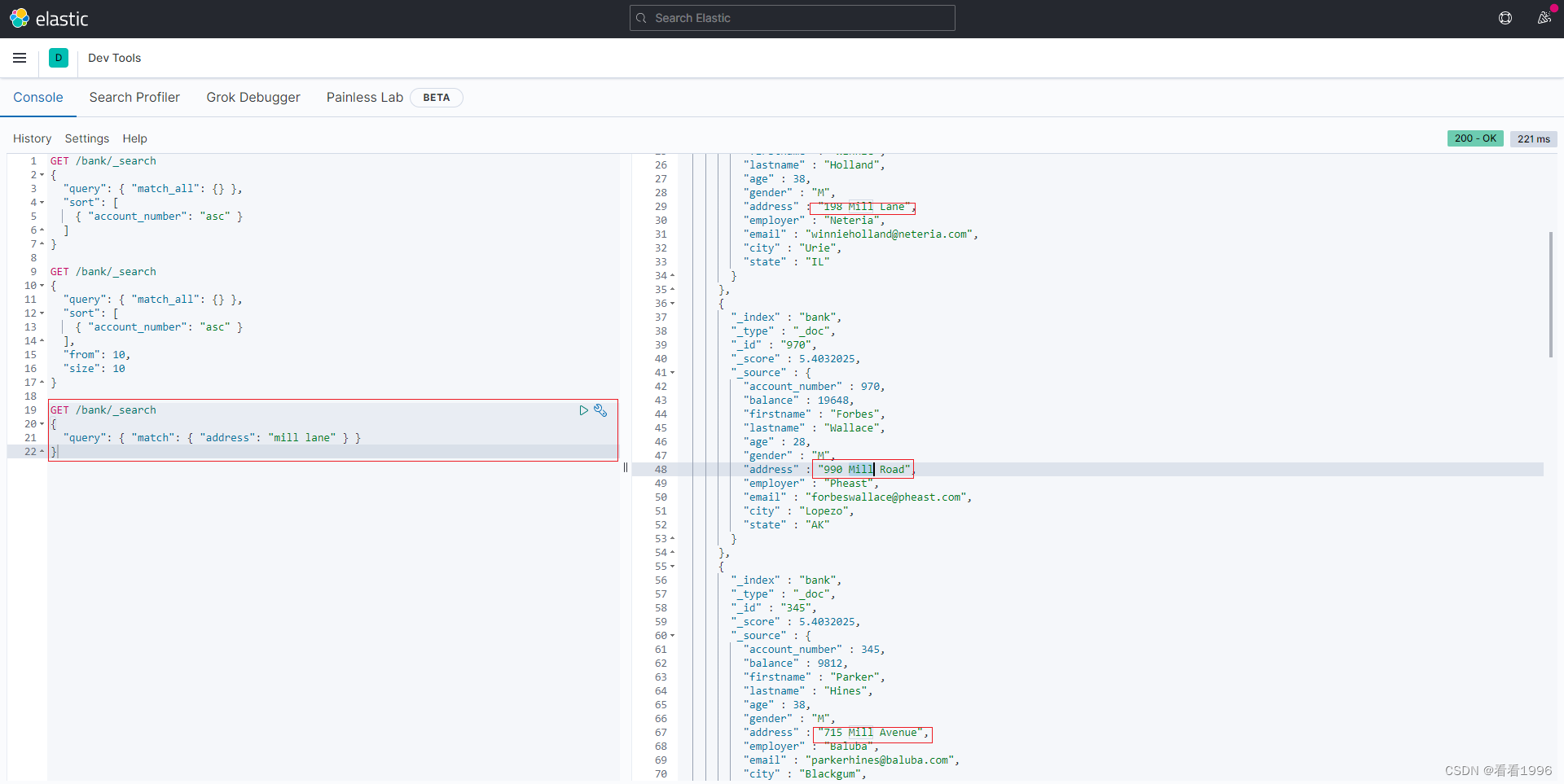
(由于ES底层是按照分词索引的,所以上述查询结果是address 字段中包含 mill 或者 lane的数据)
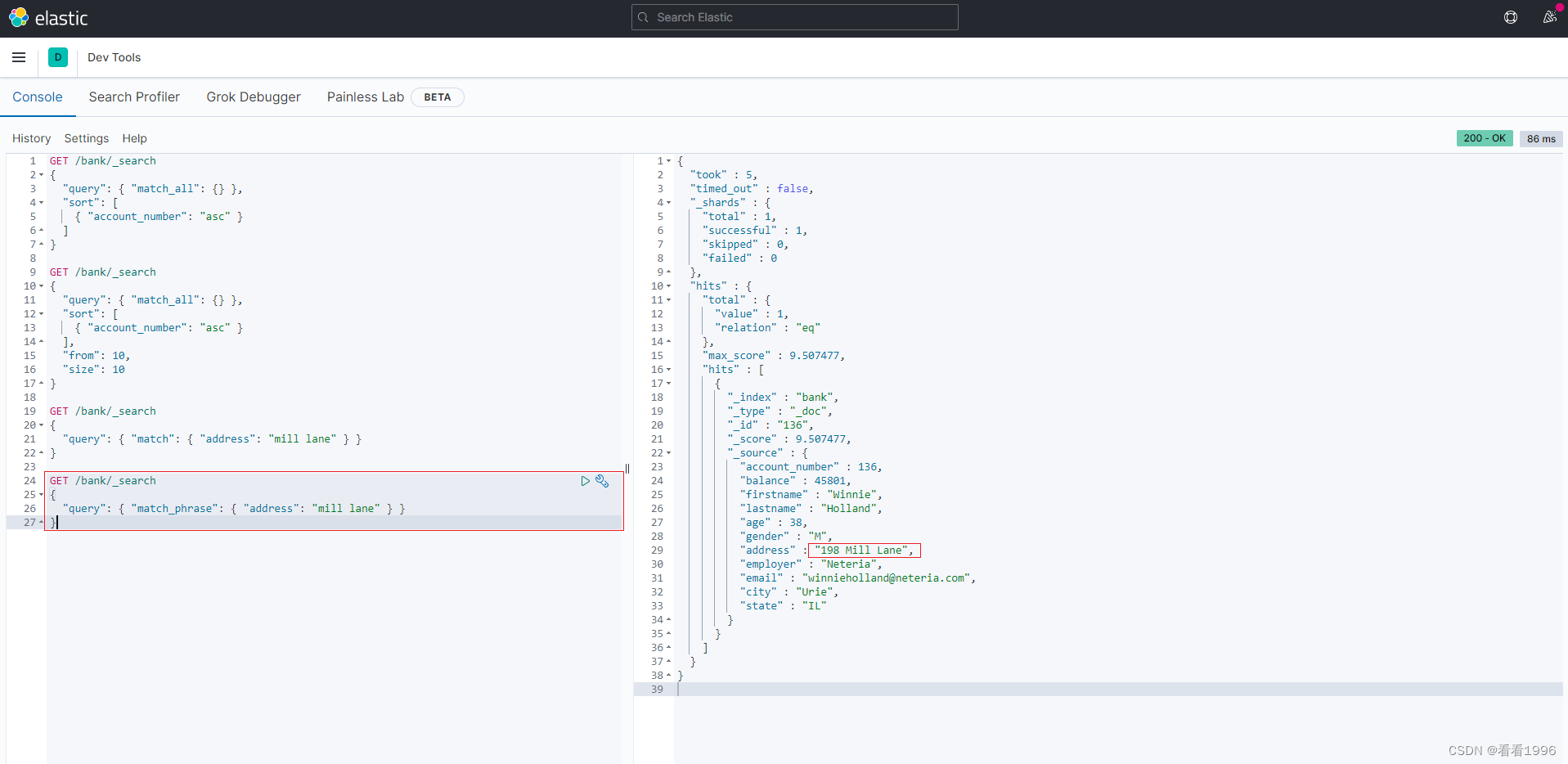
查询段落匹配:match_phrase
如果我们希望查询的条件是 address字段中包含 “mill lane”,则可以使用match_phrase
GET /bank/_search
{
"query": { "match_phrase": { "address": "mill lane" } }
}
多条件查询: bool
例如,以下请求在bank索引中搜索40岁客户的帐户,但不包括居住在爱达荷州(ID)的任何人
GET /bank/_search
{
"query": {
"bool": {
"must": [
{ "match": { "age": "40" } }
],
"must_not": [
{ "match": { "state": "ID" } }
]
}
}
}
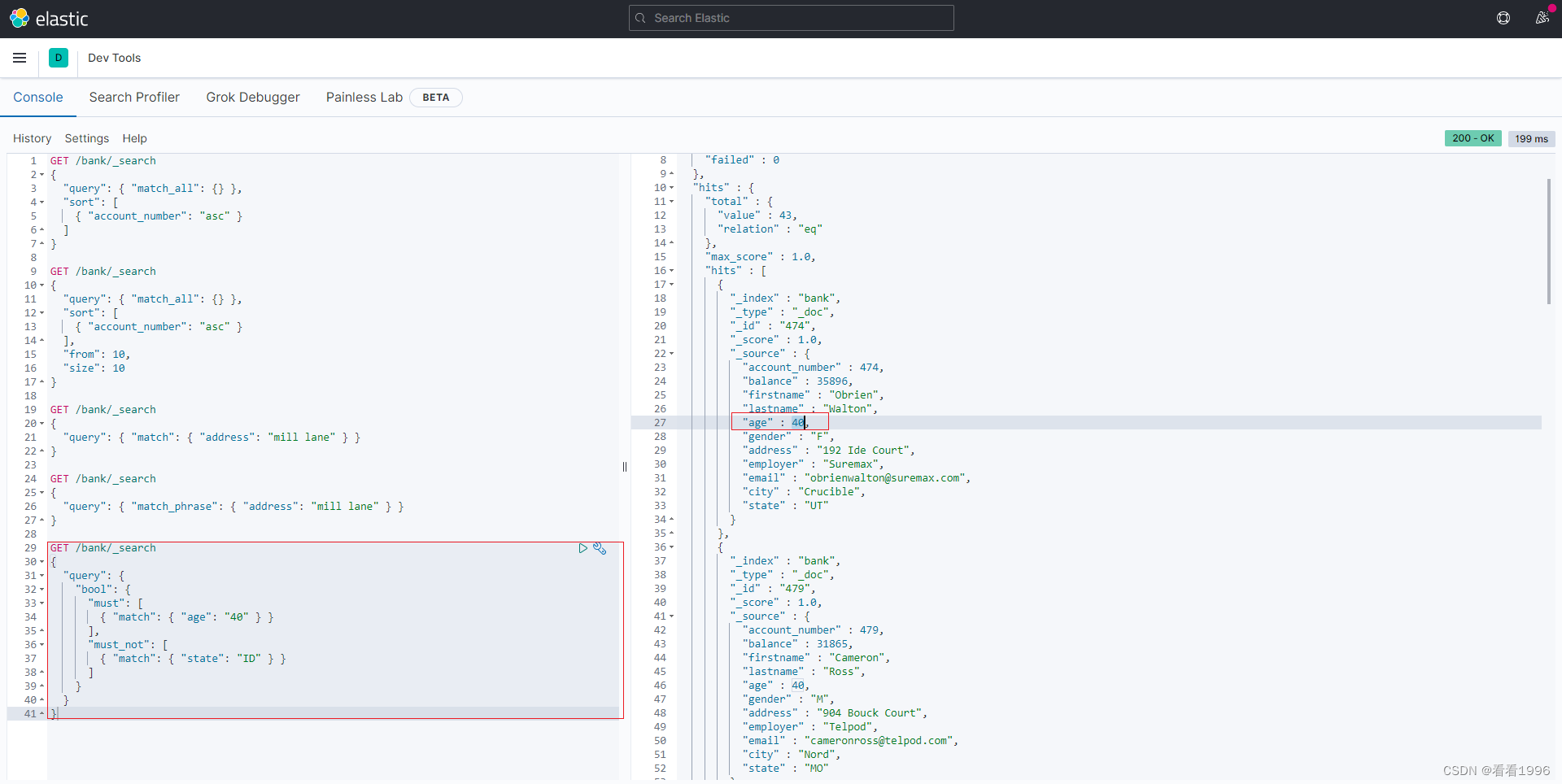
must, should, must_not 和 filter 都是bool查询的子句。那么filter和上述query子句有啥区别呢?
查询条件:query or filter
先看下如下查询, 在bool查询的子句中同时具备query/must 和 filter
GET /bank/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"state": "ND"
}
}
],
"filter": [
{
"term": {
"age": "40"
}
},
{
"range": {
"balance": {
"gte": 20000,
"lte": 30000
}
}
}
]
}
}
}
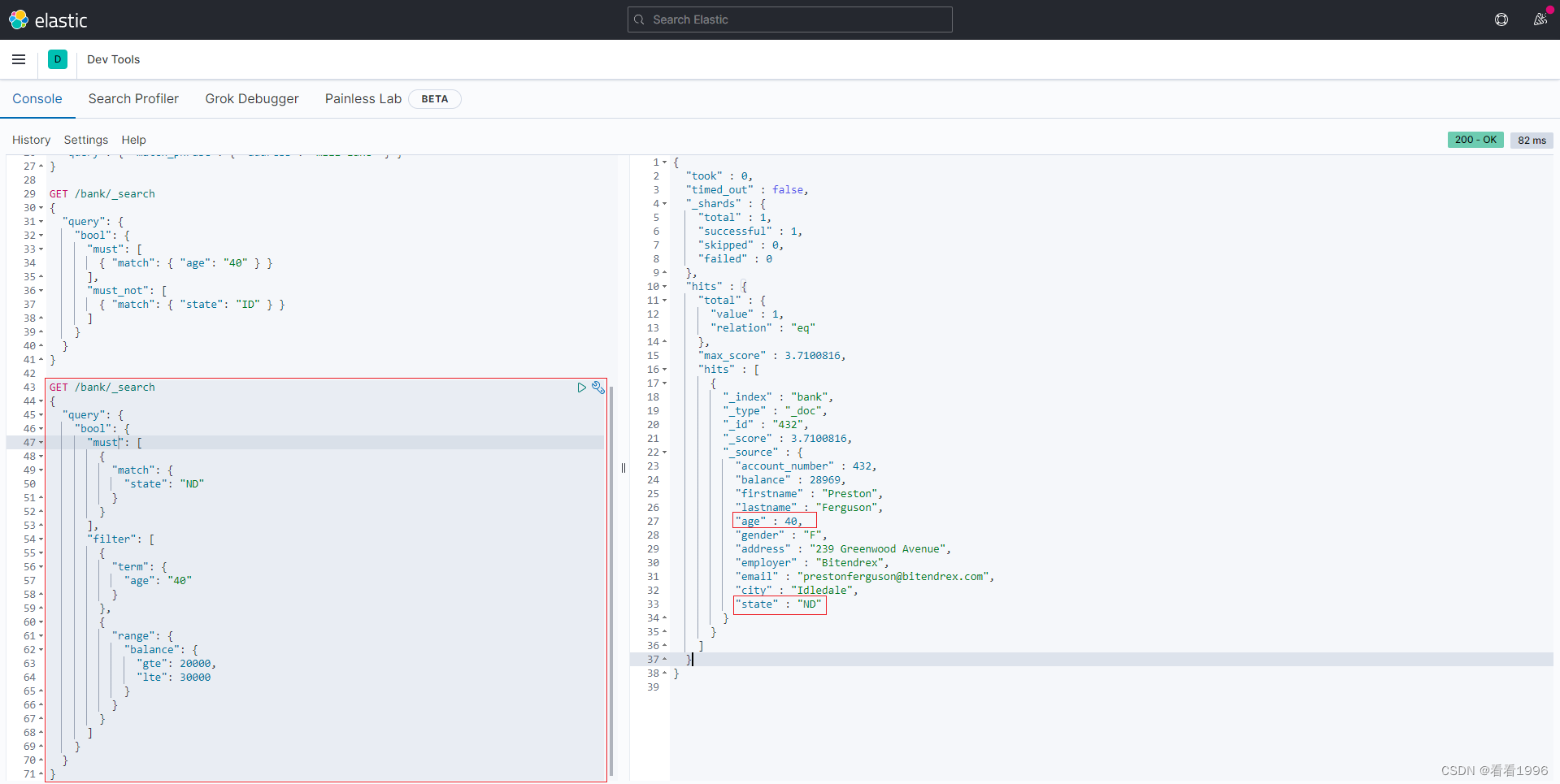
两者都可以写查询条件,而且语法也类似。区别在于,query 上下文的条件是用来给文档打分的,匹配越好 _score 越高;filter 的条件只产生两种结果:符合与不符合,后者被过滤掉。
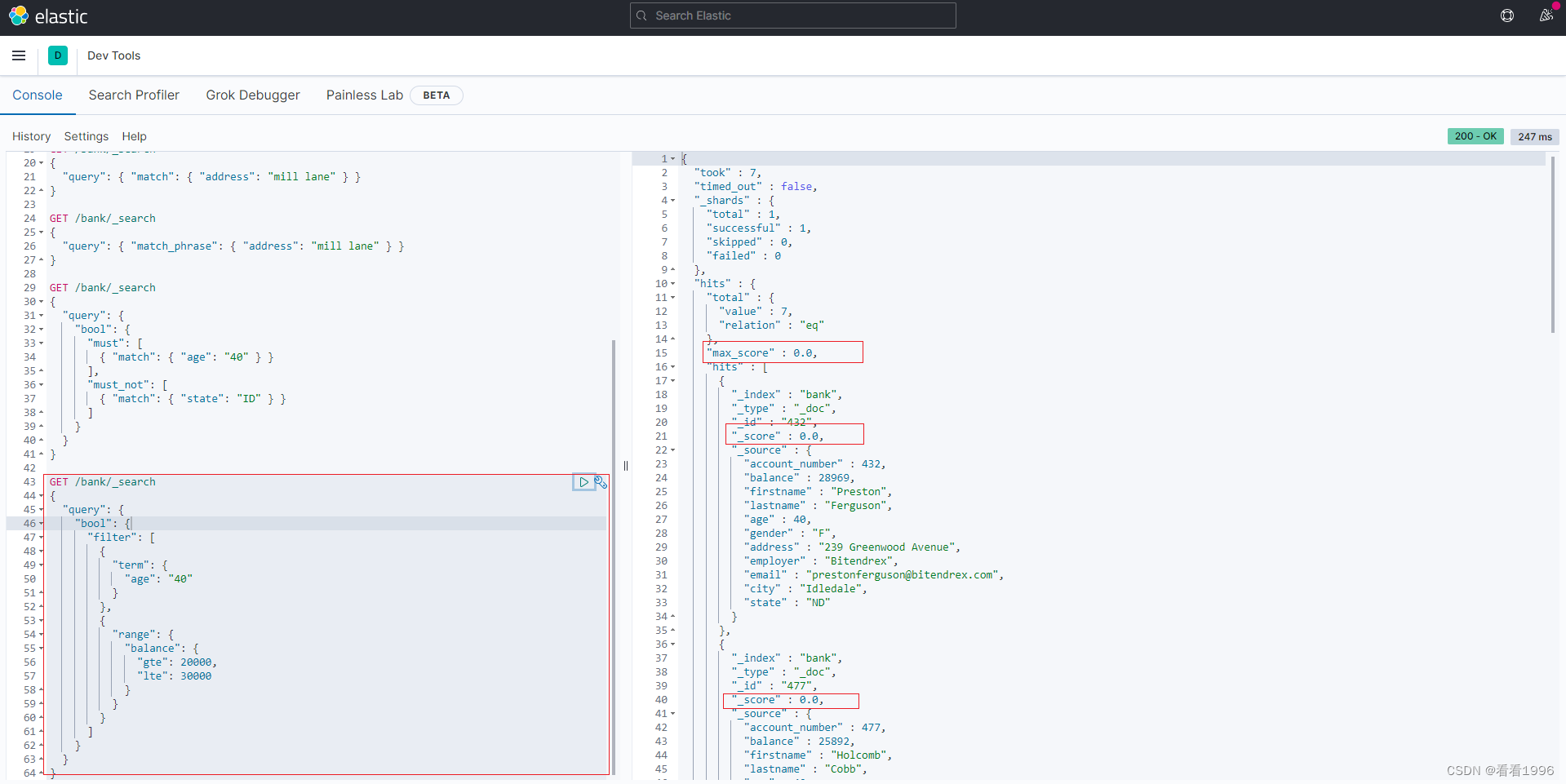
所以,我们进一步看只包含filter的查询
GET /bank/_search
{
"query": {
"bool": {
"filter": [
{
"term": {
"age": "40"
}
},
{
"range": {
"balance": {
"gte": 20000,
"lte": 30000
}
}
}
]
}
}
}
结果,显然无_score
聚合查询:Aggregation
我们知道SQL中有group by,在ES中它叫Aggregation,即聚合运算。
简单聚合
比如我们希望计算出account每个州的统计数量, 使用aggs关键字对state字段聚合,被聚合的字段无需对分词统计,所以使用state.keyword对整个字段统计
GET /bank/_search
{
"size": 0,
"aggs": {
"group_by_state": {
"terms": {
"field": "state.keyword"
}
}
}
}
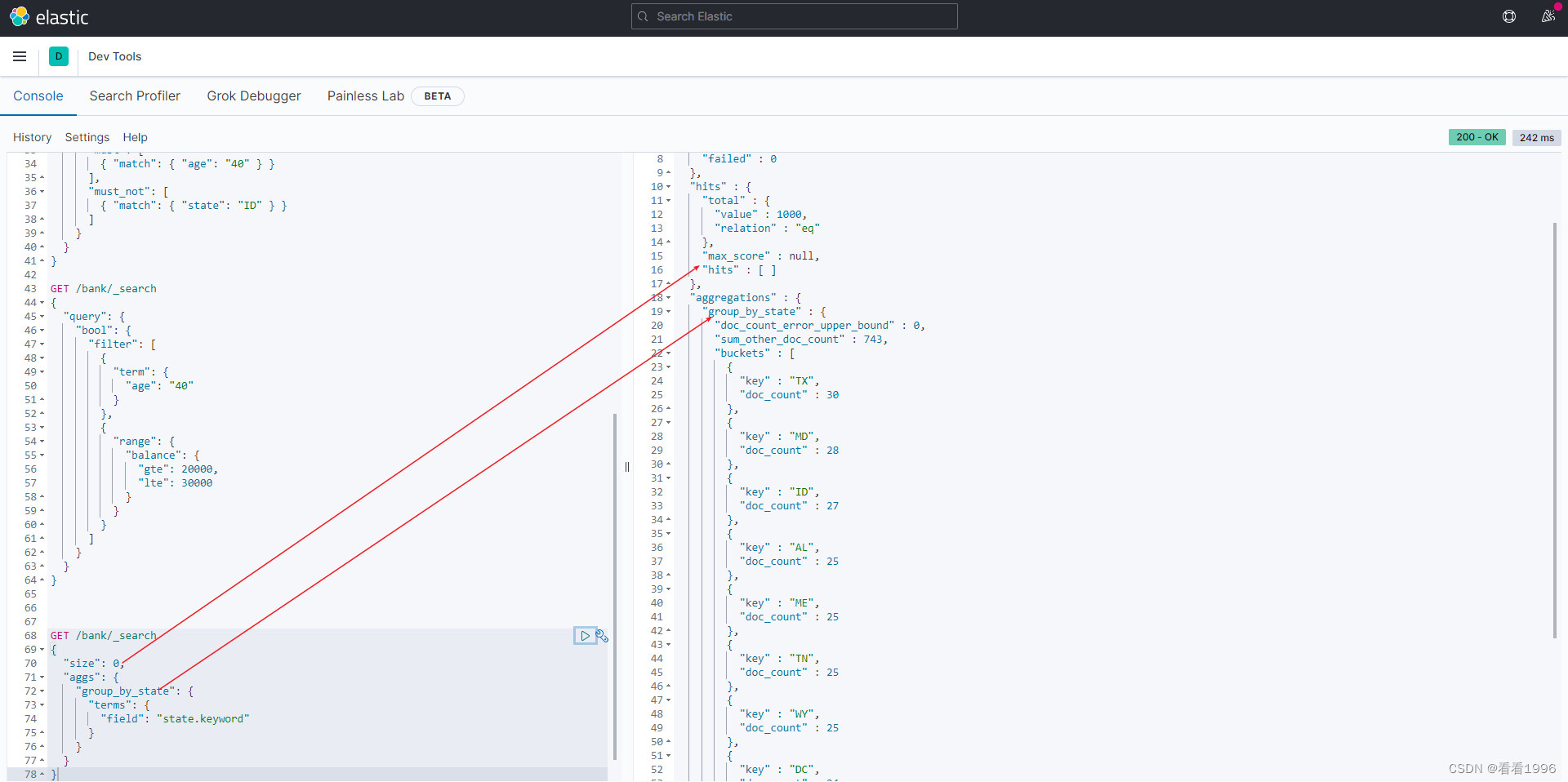
因为无需返回条件的具体数据, 所以设置size=0,返回hits为空。
doc_count表示bucket中每个州的数据条数。
嵌套聚合
ES还可以处理个聚合条件的嵌套。
比如承接上个例子, 计算每个州的平均结余。涉及到的就是在对state分组的基础上,嵌套计算avg(balance):
GET /bank/_search
{
"size": 0,
"aggs": {
"group_by_state": {
"terms": {
"field": "state.keyword"
},
"aggs": {
"average_balance": {
"avg": {
"field": "balance"
}
}
}
}
}
}
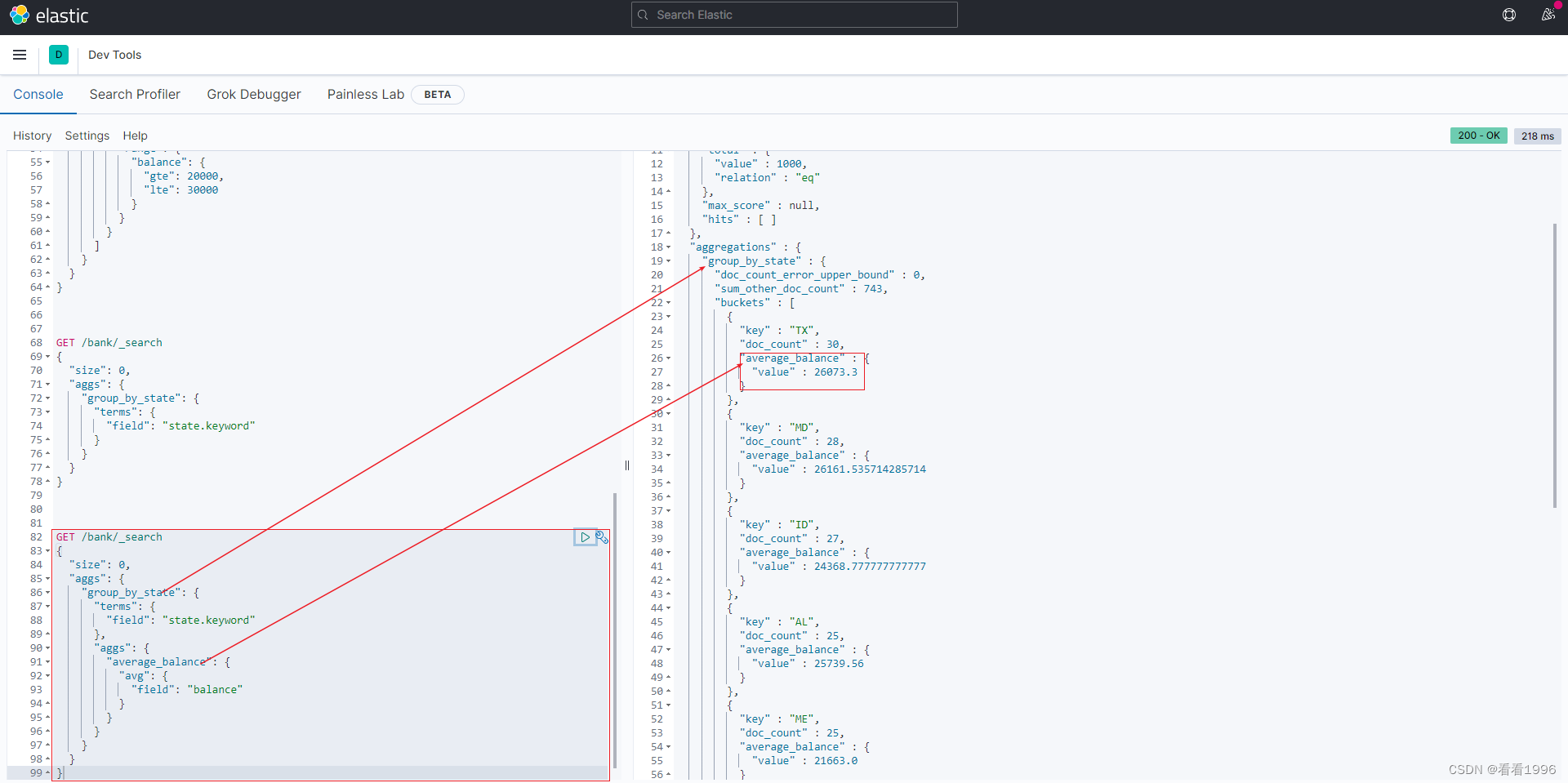
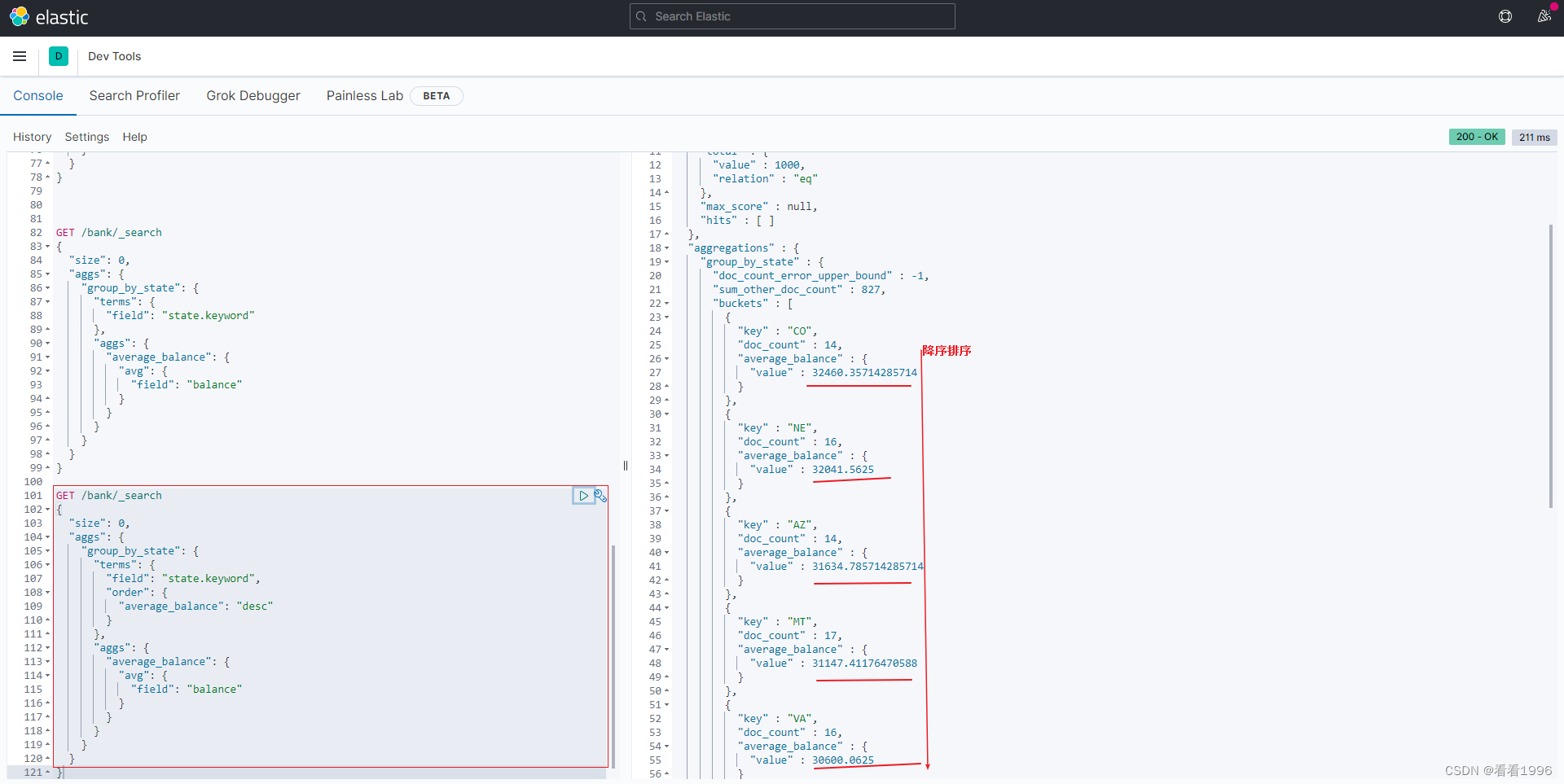
对聚合结果排序
可以通过在aggs中对嵌套聚合的结果进行排序
比如承接上个例子, 对嵌套计算出的avg(balance),这里是average_balance,进行排序
GET /bank/_search
{
"size": 0,
"aggs": {
"group_by_state": {
"terms": {
"field": "state.keyword",
"order": {
"average_balance": "desc"
}
},
"aggs": {
"average_balance": {
"avg": {
"field": "balance"
}
}
}
}
}
}
索引操作
POST /test-index-users/_open 打开索引
POST /test-index-users/_close 关闭索引
GET /test-index-users/_mapping 查看索引
DELETE /test-index-users 删除索引
PUT /test-index-users 创建索引
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1
},
"mappings": {
"properties": {
"name": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"age": {
"type": "long"
},
"remarks": {
"type": "text"
}
}
}
}
settings: 用来设置分片,副本等配置信息
mappings: 字段映射,类型等
properties: 由于type在后续版本中会被Deprecated, 所以无需被type嵌套















 94
94











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









