




序:最近公司的需求:做一个模拟LED屏的显示控件
中间各种曲折!此文做个记录,本来早就改写完的!各种原因前后隔了两个多月!
文章写的比较详细,熟悉的大佬可以跳过直接看代码!
PS:后面有完整的代码
正文:具体的读字库和点阵显示就不详细写了,可以参考 简书ForeverCy 大神的文章
传送门 https://www.jianshu.com/p/82301771b4eb

问题一:字符间隔太大!
分析原因:图中选择的是12字体大小!读取的12*12点阵字库数据,一个字符占12*2=24个字节,每个字符横向占2个字节也就是16位(绘制出来就是16个点),而英文字母实际上所占用的位置只有5-7位,所以字符间会有点大!当然不只是英文字符,其他字符也有一样的问题
解决思路:我们读取出来的字库字模数据最后是转换成二维布尔数组给显示控件绘制的,能动的就是这个数组了,所以将二维数组竖排取出判断,如果全是flase那就是没有数据的空格了!再做删除处理,当然为了保证程序的适应性,防止存在占满16位的字符(显示出来的效果就是两个字符连在一起)!在删除间隔之前,需在字符之间再添加一位空格!
代码实现:
step1:在字符间插入一位空格
/**
* 在字符间插入一位空格
* */
private void inserAemptyData(){
Log.e("matrix",matrix[0].length+"");
//初始化空值数组
empty_data = new boolean[dots];
for (int i=0;i<dots;i++) {
empty_data[i] = false;
}
ArrayList<boolean[]> tem = new ArrayList<>();
int position = -1;//更改后的数组当前下标
int matrix_index=-1;//更改前的数组当前下标
spaceIndexs = new ArrayList<>();
ArabicIndexs = new ArrayList<>();
for (int i=0;i<str.length();i++){
String indexstr = str.substring(i, i + 1);
String followstr = "";
if (i<str.length()-1){
followstr = str.substring(i+1,i+2);
}
boolean isSpace = indexstr.equals(" ");
boolean isArabic = (!followstr.equals(""))&&ArabicUtils.isArbic(followstr)&&ArabicUtils.isArbic(indexstr);
Log.e("indexstr>>>>",indexstr+"");
for (int j=0;j<16;j++){//无论是12还是16字体 横排都是两个字节 16位
position=position+1;
matrix_index+=1;
boolean[] indx = getstrbycolumn(matrix,matrix_index);//取一竖排
if (isArabic){
ArabicIndexs.add(position);
}
if (isSpace){
spaceIndexs.add(position);
}
tem.add(position,indx);
indx =null;
}
// 连续的两个阿拉伯字符之间不需要插入空格
if ((!followstr.equals(""))&&ArabicUtils.isArbic(followstr)&&ArabicUtils.isArbic(indexstr)){
}else{
Log.e("insert","1");
tem.add(position,empty_data);
position+=1;
}
}step2:取数组竖排判断并删除多余位空格(只留一个位)
/*
* 2017.12.25 添加
* 消除多余空格
* */
private void fillMatrixEmpty(){
//原则:判断boolean二维数组竖排是否出现连续为Flase的情况 如果是 便舍弃一个 否则添加到新的数组中
//
ArrayList<boolean[]> tem = new ArrayList<>();
int space_number=0;
for (int i = 0;i<matrix[0].length-1;i++){
boolean[] indx = getstrbycolumn(matrix,i);//取一竖排
boolean[] indy = getstrbycolumn(matrix,i+1);
if (i==matrix[0].length-1&&!Arrays.equals(empty_data,indy)){//最后一排加进去
// Log.e(i+">>>>","last_data");
tem.add(indy);
} else if (isSpaceVaules(i)&&isSpaceVaules(i+1)){//如果是空格的位置
space_number+=1;
// Log.e(i+">>>>","空格");
if (space_number<5){//空格位置过长 只取4个点作为空格
tem.add(indx);
}
if (space_number==16){
space_number=0;
}
}
else if (!isSpaceVaules(i)&&Arrays.equals(empty_data,indx)&&Arrays.equals(empty_data,indy)){//如果相邻两列都为空 不保存
// Log.e(i+">>>>","empty_data");
}
else if (isArabicVaules(i)&&!isSpaceVaules(i)&&Arrays.equals(empty_data,indx)){//阿拉伯文 清除所有空格
}
else{
//否则保存
// Log.e(i+">>>>","data");
tem.add(indx);
}
indx = null;
indy = null;
}
boolean[][] temps1 = new boolean[matrix.length][tem.size()];//12*n
for (int i = 0;i<tem.size();i++){
boolean[] pos = tem.get(i);
for (int j=0;j<matrix.length;j++){
temps1[j][i] = pos[j];
}
}
spaceIndexs=null;
ArabicIndexs =null;
matrix = temps1;
// Log.e("matrix>>>>",matrix[0].length+"");
// Log.e("tem>>>>",tem.size()+"");
// Log.e("temps1>>>>",temps1[0].length+"");
}
/**
* 取某一竖排值
* */
public boolean[] getstrbycolumn(boolean[][] strarray, int column){
int columnlength = strarray.length;
boolean[] result = new boolean[strarray.length];
for(int i=0;i<columnlength;i++) {
result[i] = strarray[i][column];
}
return result;
}
很明显间隔ok了,当然既然我们的主题是解决特殊国别的问题,先看下现在的效果如何

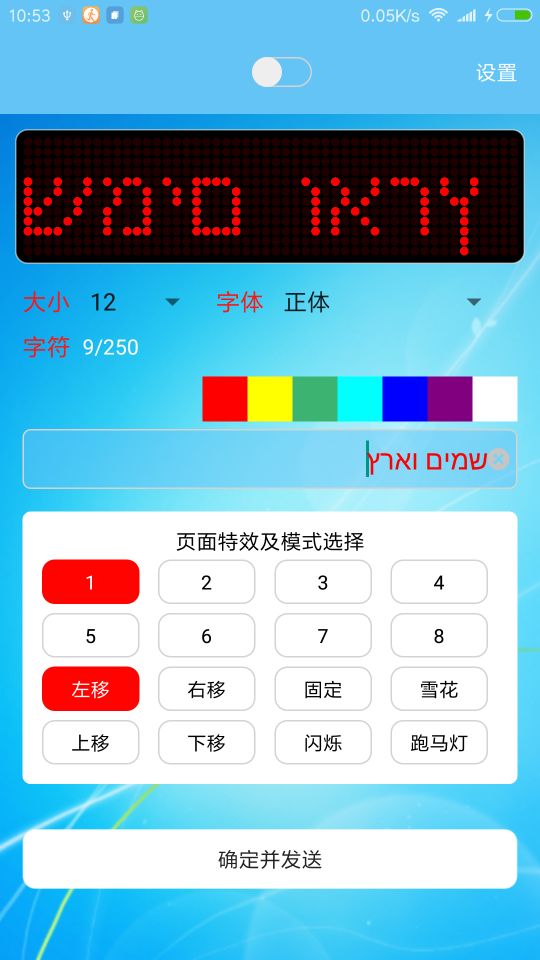
从左至右依次是:泰文,希伯来文,阿拉伯文
首先来看下泰文的问题:
问题二:字符上下标(估浅先这么叫)无法正常显示
原因分析:带上下标的文字根本不只是一个字符,但我们读取字模数据的时候是按照字符读取的,所以上下标字符肯定不会出现在对应字符的上标或者下标位置
解决思路:这里先看下 建国雄心 大佬新浪微博上的文章 泰文排版规则 ,可以先了解下泰文的基本字符知识,文章最后给出的那个解决方案,在下才疏学浅没有用得上!浪费了大佬的苦心,抱歉!那就另辟蹊径吧!

仔细看图中泰文的上标字符,其中区域1(暂时叫实部)是有用的,区域2(暂时叫虚部)是不需要的!再用字库软件打开字库文件看下:

所有的上下标的字符的虚部所占的位置都是一样的!既然这样,那在读取字库数据的时候就可以去掉虚部的部分,留下来的 实部再叠加到对应的字符上就行了,至于有哪些字符存在这种情况就需要一个个找了!我这里给我三种国别文字上下标字符的Unicode码,供参考:
//阿拉伯文上下标字符 unicode
static final int[] ArabicSup_Subs = {0x64b,0x64c,0x64d,0x64e,0x64f,0x650,0x651,0x652,0x653,0x654,0x655,0x656,0x657,0x658,0x659,0x65a,0x65b,0x65c,0x65d,0x65e,
0x6d6,0x6d7,0x6d8,0x6d9,0x6da,0x6db,0x6dc,
0x6df,0x6e0,0x6e1,0x6e2,0x6e3,0x6e4,
0x6e7,0x6e8,0x6ea,0x6eb,0x6ec
};//希伯来文上下标字符 unicode
static final int[] HebrewSup_Subs = {0x591,0x592,0x593,0x594,0x595,0x596,0x597,0x598,0x599,0x59a,0x59b,0x59c,0x59d,0x59e,0x59f,0x5a0,
0x5a1,0x5a2,0x5a3,0x5a4,0x5a5,0x5a6,0x5a7,0x5a8,0x5a9,0x5aa,0x5ab,0x5ac,0x5ad,0x5ae,0x5af,0x5b0,0x5b1,0x5b2,
0x5b3,0x5b4,0x5b5,0x5b6,0x5b7,0x5b8,
0x5bb,0x5bd,0x5bf,0x5c1,0x5c2,0x5c4,0x5c5,0x5c7
};
//泰文 上下标字符 unicode
static final int[] ThaiSup_Subs = {0x0e31,0x0e34,0x0e35,0x0e36,0x0e37,0x0e38,0x0e39,0x0e3a,
0x0e47,0x0e48,0x0e49,0x0e4a,0x0e4b,0x0e4c,0x0e4d,0x0e4e
};PS:实际上阿拉伯文和希伯来文都存在这种上下标的现象,在这里就一并处理了!后面就不再累述了!
实现代码:
step1:在读取字符字模数据时,去掉虚部并叠加到相应字符
//泰文上下标处理
if (ArabicUtils.isThai(subjectStr)&ArabicUtils.isThai(followStr)){//都为泰文字符
String follow2str = "";
if(index<str.length()-2){
follow2str = str.substring(index+2,index+3);//泰文存在上下标同时存在的情况
}
if (!follow2str.equals("")&&ArabicUtils.isSup_SubThai(follow2str)&&ArabicUtils.isSup_SubThai(followStr)){
byte[] data_follow2 = readAllZiMo(follow2str);
if(data_follow2!=null){//后续字符数据不为空
data = ArabicUtils.adminSup_SubThai(data_follow,data,dots);//将后面字符数据叠加到当前字符数据中
data = ArabicUtils.adminSup_SubThai(data_follow2,data,dots);//将后面字符数据叠加到当前字符数据中
index+=2;
System.arraycopy(data, 0, dataResult, hasDealByte, data.length);
hasDealByte = hasDealByte + data.length;
System.arraycopy(replacedata, 0, dataResult, hasDealByte, replacedata.length);
hasDealByte = hasDealByte + replacedata.length;
System.arraycopy(replacedata, 0, dataResult, hasDealByte, replacedata.length);
hasDealByte = hasDealByte + replacedata.length;
}
}else if (ArabicUtils.isSup_SubThai(followStr)){//后面字符是否为上下标特殊字符
if(data_follow!=null){//后续字符数据不为空
data = ArabicUtils.adminSup_SubThai(data_follow,data,dots);//将后面字符数据叠加到当前字符数据中
index+=1;
System.arraycopy(data, 0, dataResult, hasDealByte, data.length);
hasDealByte = hasDealByte + data.length;
System.arraycopy(replacedata, 0, dataResult, hasDealByte, replacedata.length);
hasDealByte = hasDealByte + replacedata.length;
}
}else {
System.arraycopy(data, 0, dataResult, hasDealByte, data.length);
hasDealByte = hasDealByte + data.length;
}
}else {
System.arraycopy(data, 0, dataResult, hasDealByte, data.length);
hasDealByte = hasDealByte + data.length;
}
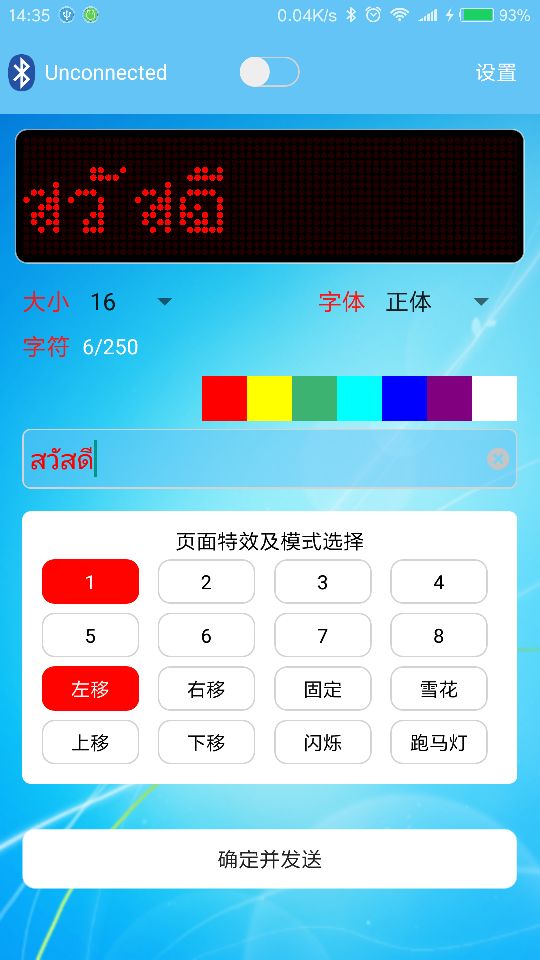
很明显 效果好很多了,上面只给出了泰文的处理方式,其他两种语言也都一样,这里我就不再贴了!如果需要完整代码,后面我会给出链接!
接下来,看阿拉伯文!
问题三:读取的字符混乱,而且反向相反
这里再次感谢 建国雄心的微博:阿拉伯文排版规则 的解惑,
原因分析:引用文章中的一句话:“阿拉伯文的字母没有大写和小写的区分,但有印刷体和书写体的区别,而且除去دذ ر زو五个字母以外,其他23个字母都可以和后面的字母连写,而且因其在词头,词中和词尾的位置不同,字形也有所变化。阿拉伯文字的书写方向和中文不同,它是自右向左横着写”,也就是说,我们看到的是书写体,而字库文件是以印刷体保存的!也因为阿拉伯文是连字体的,所以直接读取出来的数据是不对的,需要重新变形成新的字符串再读取byte数据
解决思路:大神的微博中给出的重排规则,至于方向,如果是纯阿拉伯文字,直接反向就行了!但对于阿拉伯文和中文或者英文混输就需要另外判断了,
实现代码:
/**
* 阿拉伯文排版
* **/
@NonNull
public static String getArbicResult(String str){
StringBuffer stringBuffer = new StringBuffer();
for (int i=0;i<str.length();i++){
//取连续的三个字符判断
String substr = str.substring(i,i+1);
String pre_sub ;
String for_sub ;
if (i==0){
pre_sub = "";
}else {
pre_sub = str.substring(i-1,i);
}
if (i==str.length()-1){
for_sub = "";
}else {
for_sub = str.substring(i+1,i+2);
}
if (isArbic(substr)){ //如果当前字符是阿拉伯文
boolean ispreconnect = false ;
boolean isforconnect = false;
//排版规则1:
// 1.判断是否前连
if (isArbic(pre_sub)&&!pre_sub.equals("")){//如果前一个字符是阿拉伯文,判断是否前连
ispreconnect = getIsPreConnect(pre_sub);
}else{//不需要判断是否前连
}
//2.判断是否后连
if (isArbic(for_sub)&&!for_sub.equals("")){//如果前一个字符是阿拉伯文,判断是否后连
isforconnect = getIsForConnect(for_sub);
}else{//不需要判断是否后连
}
//排版规则2:
//以0x644开头,后面跟的是0x622,0x623,0x625,0x627
if (Integer.parseInt(gbEncoding(substr),16)==0x0644&&!for_sub.equals("")) {//是0x0644
int fors = Integer.parseInt(gbEncoding(for_sub),16);
if (fors==0x0622||fors==0x0623||fors==0x0625||fors==0x0627){//后面接0x622,0x623,0x625,0x627
//这种情况处理后 两个字符合并成一个字符
//判断0x0644前一个字符是否前连
int temp = 0;
if (ispreconnect){//是前连 取arabic_specs数组 1
temp = 1;
}else{//不是 取arabic_specs数组 0
temp = 0;
}
switch (fors){
case 0x0622:
substr = arabic_specs[0][temp]+"";
break;
case 0x0623:
substr = arabic_specs[1][temp]+"";
break;
case 0x0625:
substr = arabic_specs[2][temp]+"";
break;
case 0x0627:
substr = arabic_specs[3][temp]+"";
break;
}
substr = getStrFromUniCode(substr);
i+=1;
}
}else if (isNeedChange(substr)){//不是0x0644,并且在需要变形的数组中
int index = 0;
if(!isforconnect&&ispreconnect){//前连
index = 1;
}
if (isforconnect&&!ispreconnect){//后连
index = 2;
}
if (isforconnect&&ispreconnect){//中间
index = 3;
}
if (!isforconnect&&!ispreconnect){//独立
index = 4;
}
substr = getChangeReturn(substr,index);
substr = getStrFromUniCode(substr);
}
}else{//不是阿拉伯文
}
stringBuffer.append(substr);
}
return stringBuffer.toString();
}
/**
*返回重排后的字符
* */
private static String getChangeReturn(String substr,int index) {
int subunicode = Integer.parseInt(gbEncoding(substr),16);
for (int i=0;i<Arbic_Position.length;i++){
if (Arbic_Position[i][0]==subunicode){
substr = "\\u"+Integer.toHexString(Arbic_Position[i][index]);
}
}
return substr;
}
//阿拉伯文 当前字符是否需要重排
private static boolean isNeedChange(String substr) {
int subunicode = Integer.parseInt(gbEncoding(substr),16);
for (int i=0;i<Arbic_Position.length;i++){
if (Arbic_Position[i][0]==subunicode){
return true;
}
}
return false;
}
//后连
private static boolean getIsForConnect(String for_sub) {
int subunicode = Integer.parseInt(gbEncoding(for_sub),16);
for (int i=0;i<theSet2.length;i++){
if (theSet2[i]==subunicode){
return true;
}
}
return false;
}
//前连
private static boolean getIsPreConnect(String pre_sub) {
int subunicode = Integer.parseInt(gbEncoding(pre_sub),16);
for (int i=0;i<theSet1.length;i++){
if (theSet1[i]==subunicode){
return true;
}
}
return false;
}下面是需要的Unicode数组:
//阿拉伯文中需要变形字符的unicode码 0x621-0x64a 集合中对应不同位置变形后的unicode码
static final int[][] Arbic_Position = //former first, last, middle, alone
{
{0x621, 0xfe80, 0xfe80, 0xfe80, 0xfe80}, // 0x621
{0x622, 0xfe82, 0xfe81, 0xfe82, 0xfe81},
{ 0x623,0xfe84, 0xfe83, 0xfe84, 0xfe83},
{ 0x624,0xfe86, 0xfe85, 0xfe86, 0xfe85},
{0x625, 0xfe88, 0xfe87, 0xfe88, 0xfe87},
{ 0x626,0xfe8a, 0xfe8b, 0xfe8c, 0xfe89},
{0x627, 0xfe8e, 0xfe8d, 0xfe8e, 0xfe8d},
{0x628, 0xfe90, 0xfe91, 0xfe92, 0xfe8f}, // 0x628
{ 0x629,0xfe94, 0xfe93, 0xfe94, 0xfe93},
{0x62a, 0xfe96, 0xfe97, 0xfe98, 0xfe95}, // 0x62A
{0x62b, 0xfe9a, 0xfe9b, 0xfe9c, 0xfe99},
{0x62c, 0xfe9e, 0xfe9f, 0xfea0, 0xfe9d},
{0x62d, 0xfea2, 0xfea3, 0xfea4, 0xfea1},
{ 0x62e,0xfea6, 0xfea7, 0xfea8, 0xfea5},
{0x62f, 0xfeaa, 0xfea9, 0xfeaa, 0xfea9},
{0x630, 0xfeac, 0xfeab, 0xfeac, 0xfeab}, // 0x630
{0x631, 0xfeae, 0xfead, 0xfeae, 0xfead},
{ 0x632,0xfeb0, 0xfeaf, 0xfeb0, 0xfeaf},
{0x633, 0xfeb2, 0xfeb3, 0xfeb4, 0xfeb1},
{0x634, 0xfeb6, 0xfeb7, 0xfeb8, 0xfeb5},
{ 0x635,0xfeba, 0xfebb, 0xfebc, 0xfeb9},
{0x636, 0xfebe, 0xfebf, 0xfec0, 0xfebd},
{0x637, 0xfec2, 0xfec3, 0xfec4, 0xfec1},
{0x638, 0xfec6, 0xfec7, 0xfec8, 0xfec5}, // 0x638
{0x639, 0xfeca, 0xfecb, 0xfecc, 0xfec9},
{ 0x63a,0xfece, 0xfecf, 0xfed0, 0xfecd}, //0x63A
{0x63b, 0x63b, 0x63b, 0x63b, 0x63b},
{0x63c, 0x63c, 0x63c, 0x63c, 0x63c},
{0x63d, 0x63d, 0x63d, 0x63d, 0x63d},
{0x63e, 0x63e, 0x63e, 0x63e, 0x63e},
{0x63f, 0x63f, 0x63f, 0x63f, 0x63f},
{ 0x640,0x640, 0x640, 0x640, 0x640}, // 0x640
{0x641, 0xfed2, 0xfed3, 0xfed4, 0xfed1},
{ 0x642,0xfed6, 0xfed7, 0xfed8, 0xfed5},
{0x643, 0xfeda, 0xfedb, 0xfedc, 0xfed9},
{ 0x644,0xfede, 0xfedf, 0xfee0, 0xfedd},
{0x645, 0xfee2, 0xfee3, 0xfee4, 0xfee1},
{0x646, 0xfee6, 0xfee7, 0xfee8, 0xfee5},
{ 0x647,0xfeea, 0xfeeb, 0xfeec, 0xfee9},
{ 0x648,0xfeee, 0xfeed, 0xfeee, 0xfeed}, // 0x648
{0x649, 0xfef0, 0xfef3, 0xfef4, 0xfeef},
{0x64a,0xfef2, 0xfef3, 0xfef4, 0xfef1}, // 0x64A
};
//前连集合
//判断是否是连接前面的,采用判断该字符前一个字符的判定方法,方法是,看前一个字符是否在集合set1中。如果在,则是有连接前面的
static final int[] theSet1={
0x62c, 0x62d, 0x62e, 0x647, 0x639, 0x63a, 0x641, 0x642,
0x62b, 0x635, 0x636, 0x637, 0x643, 0x645, 0x646, 0x62a,
0x644, 0x628, 0x64a, 0x633, 0x634, 0x638, 0x626, 0x640}; // 0x640 新增
//后连集合
//判断是否是连接后面的,采用判断该字符后一个字符的判定方法,方法是,看后一个字符是否在集合set2中。如果在,则是有连接后面的
static final int[] theSet2={
0x62c, 0x62d, 0x62e, 0x647, 0x639, 0x63a, 0x641, 0x642,
0x62b, 0x635, 0x636, 0x637, 0x643, 0x645, 0x646, 0x62a,
0x644, 0x628, 0x64a, 0x633, 0x634, 0x638, 0x626,
0x627, 0x623, 0x625, 0x622, 0x62f, 0x630, 0x631, 0x632,
0x648, 0x624, 0x629, 0x649, 0x640}; // 0x640 新增
//连字符是以0x644开头,后面跟的是0x622,0x623,0x625,0x627,并根据情况取下面的字符数组0或1,如果0x644前一个字符是在集合1(同上面的集合1)中间,那么取数组1,否则取数组0
static final int[][] arabic_specs=
{
{0xFEF5,0xFEF6},//0x622
{0xFEF7,0xFEF8},//0x623
{0xFEF9,0xFEFA},//0x625
{0xFEFB,0xFEFC},//0x627
};字符顺序处理:
/**
* 含阿拉伯/希伯来文字符串 重新排序
* 问题:阿拉伯/希伯来文字符串从右至左读取,一般来说直接全部反序就行
* 当时用String.sub()方法逐一取字符时(从右向左) 在遇到连续的非阿拉伯/希伯来文时,java默认从连续字符串的左边读取
*那么问题是:如果不区分开 在读取的时候就乱了
* 思路:按照正常字符串的方式 从左向右读取,第一个(也就是字符串的最后一个字符)必须是正常的字符(如果不是添加“1”)
* 从左至右 遇到正常的字符集 反序
* */
private String adminInverso(String str){
String result =str;
boolean isEndOfSpecial = false;//阿拉伯字符结尾
boolean isendofspace =false;//空格结尾
String endstr = str.substring(str.length()-1,str.length());
if (ArabicUtils.isArbic(endstr)||ArabicUtils.isHebrew(endstr)){//字符串以阿拉伯文/希伯来结尾,这种情况整个字符串从右至左
Log.e("isArbic>>>>>>",str.substring(str.length()-1,str.length()));
isEndOfSpecial = true;
str = str+"1";
// result = inverso(str);//整个字符串反序
}
// else if (endstr.equals(" ")){
// isendofspace = true;
// str = str+"1";
// }
// if (!str.substring(str.length()-1,str.length()).equals(" "))
// {//字符串不以阿拉伯文结尾,从右至左解码,解码时最后剩余的非阿拉伯字符为左到右
Log.e("isnomal>>>>>>",str.substring(str.length()-1,str.length()));
StringBuffer stringBuffer = new StringBuffer();
StringBuffer laststrs = new StringBuffer();
StringBuffer arabicstrs = new StringBuffer();
for (int i=str.length();i>0;i--){
String sub = str.substring(i-1,i);
String follow = "";
if (i>1){
follow = str.substring(i-2,i-1);
}
if (!ArabicUtils.isArbic(sub)&&!ArabicUtils.isHebrew(sub)){
laststrs.append(sub);
if ((!follow.equals(""))&&(ArabicUtils.isArbic(follow)||ArabicUtils.isHebrew(follow))){
stringBuffer.append(inverso(laststrs.toString()));
laststrs.delete(0,laststrs.length());
}
}
else {
stringBuffer.append(sub);
}
}
if (isEndOfSpecial){
stringBuffer.delete(0,1);
}
result = stringBuffer.toString();
return result;
}
//字符串反序
private String inverso (String str){
StringBuffer stringBuffer = new StringBuffer();
List<String> list = new ArrayList<>();
for (int i=0;i<str.length();i++){
String sub = str.substring(i,i+1);
list.add(sub);
}
for (int j=0;j<list.size();j++){
stringBuffer.append(list.get(list.size()-j-1));
}
return stringBuffer.toString();
}

好了,到目前为止!差不多都解决了!至于其他国别文字,思路都差不多!因为隔了很久,中间有些细节的东西就没逐一写出来了,后面给出完整的工具类!有需要的可以参考
资源链接:
点阵字库文件:http://download.csdn.net/download/weixin_38674502/10198094
完整代码:
特殊国别处理工具类:
package xc.LEDILove.utils;
import android.support.annotation.NonNull;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* Created by xcgd on 2018/1/5.
*/
public class ArabicUtils {
private static ArabicUtils single = null;
private ArabicUtils(){};
public static ArabicUtils getInstance(){
if (single==null){
single = new ArabicUtils();
return single;
}else {
return single;
}
}
public static void main(String[] args){
//下面写你要测试的方法,如:
// getArbicResult("مرحباً");
System.out.println("مرحباً");
System.out.println(getArbicResult("مرحباً"));
}
//阿拉伯文中需要变形字符的unicode码 0x621-0x64a 集合中对应不同位置变形后的unicode码
static final int[][] Arbic_Position = //former first, last, middle, alone
{
{0x621, 0xfe80, 0xfe80, 0xfe80, 0xfe80}, // 0x621
{0x622, 0xfe82, 0xfe81, 0xfe82, 0xfe81},
{ 0x623,0xfe84, 0xfe83, 0xfe84, 0xfe83},
{ 0x624,0xfe86, 0xfe85, 0xfe86, 0xfe85},
{0x625, 0xfe88, 0xfe87, 0xfe88, 0xfe87},
{ 0x626,0xfe8a, 0xfe8b, 0xfe8c, 0xfe89},
{0x627, 0xfe8e, 0xfe8d, 0xfe8e, 0xfe8d},
{0x628, 0xfe90, 0xfe91, 0xfe92, 0xfe8f}, // 0x628
{ 0x629,0xfe94, 0xfe93, 0xfe94, 0xfe93},
{0x62a, 0xfe96, 0xfe97, 0xfe98, 0xfe95}, // 0x62A
{0x62b, 0xfe9a, 0xfe9b, 0xfe9c, 0xfe99},
{0x62c, 0xfe9e, 0xfe9f, 0xfea0, 0xfe9d},
{0x62d, 0xfea2, 0xfea3, 0xfea4, 0xfea1},
{ 0x62e,0xfea6, 0xfea7, 0xfea8, 0xfea5},
{0x62f, 0xfeaa, 0xfea9, 0xfeaa, 0xfea9},
{0x630, 0xfeac, 0xfeab, 0xfeac, 0xfeab}, // 0x630
{0x631, 0xfeae, 0xfead, 0xfeae, 0xfead},
{ 0x632,0xfeb0, 0xfeaf, 0xfeb0, 0xfeaf},
{0x633, 0xfeb2, 0xfeb3, 0xfeb4, 0xfeb1},
{0x634, 0xfeb6, 0xfeb7, 0xfeb8, 0xfeb5},
{ 0x635,0xfeba, 0xfebb, 0xfebc, 0xfeb9},
{0x636, 0xfebe, 0xfebf, 0xfec0, 0xfebd},
{0x637, 0xfec2, 0xfec3, 0xfec4, 0xfec1},
{0x638, 0xfec6, 0xfec7, 0xfec8, 0xfec5}, // 0x638
{0x639, 0xfeca, 0xfecb, 0xfecc, 0xfec9},
{ 0x63a,0xfece, 0xfecf, 0xfed0, 0xfecd}, //0x63A
{0x63b, 0x63b, 0x63b, 0x63b, 0x63b},
{0x63c, 0x63c, 0x63c, 0x63c, 0x63c},
{0x63d, 0x63d, 0x63d, 0x63d, 0x63d},
{0x63e, 0x63e, 0x63e, 0x63e, 0x63e},
{0x63f, 0x63f, 0x63f, 0x63f, 0x63f},
{ 0x640,0x640, 0x640, 0x640, 0x640}, // 0x640
{0x641, 0xfed2, 0xfed3, 0xfed4, 0xfed1},
{ 0x642,0xfed6, 0xfed7, 0xfed8, 0xfed5},
{0x643, 0xfeda, 0xfedb, 0xfedc, 0xfed9},
{ 0x644,0xfede, 0xfedf, 0xfee0, 0xfedd},
{0x645, 0xfee2, 0xfee3, 0xfee4, 0xfee1},
{0x646, 0xfee6, 0xfee7, 0xfee8, 0xfee5},
{ 0x647,0xfeea, 0xfeeb, 0xfeec, 0xfee9},
{ 0x648,0xfeee, 0xfeed, 0xfeee, 0xfeed}, // 0x648
{0x649, 0xfef0, 0xfef3, 0xfef4, 0xfeef},
{0x64a,0xfef2, 0xfef3, 0xfef4, 0xfef1}, // 0x64A
};
//前连集合
//判断是否是连接前面的,采用判断该字符前一个字符的判定方法,方法是,看前一个字符是否在集合set1中。如果在,则是有连接前面的
static final int[] theSet1={
0x62c, 0x62d, 0x62e, 0x647, 0x639, 0x63a, 0x641, 0x642,
0x62b, 0x635, 0x636, 0x637, 0x643, 0x645, 0x646, 0x62a,
0x644, 0x628, 0x64a, 0x633, 0x634, 0x638, 0x626, 0x640}; // 0x640 新增
//后连集合
//判断是否是连接后面的,采用判断该字符后一个字符的判定方法,方法是,看后一个字符是否在集合set2中。如果在,则是有连接后面的
static final int[] theSet2={
0x62c, 0x62d, 0x62e, 0x647, 0x639, 0x63a, 0x641, 0x642,
0x62b, 0x635, 0x636, 0x637, 0x643, 0x645, 0x646, 0x62a,
0x644, 0x628, 0x64a, 0x633, 0x634, 0x638, 0x626,
0x627, 0x623, 0x625, 0x622, 0x62f, 0x630, 0x631, 0x632,
0x648, 0x624, 0x629, 0x649, 0x640}; // 0x640 新增
//连字符是以0x644开头,后面跟的是0x622,0x623,0x625,0x627,并根据情况取下面的字符数组0或1,如果0x644前一个字符是在集合1(同上面的集合1)中间,那么取数组1,否则取数组0
static final int[][] arabic_specs=
{
{0xFEF5,0xFEF6},//0x622
{0xFEF7,0xFEF8},//0x623
{0xFEF9,0xFEFA},//0x625
{0xFEFB,0xFEFC},//0x627
};
//阿拉伯文上下标字符 unicode
static final int[] ArabicSup_Subs = {0x64b,0x64c,0x64d,0x64e,0x64f,0x650,0x651,0x652,0x653,0x654,0x655,0x656,0x657,0x658,0x659,0x65a,0x65b,0x65c,0x65d,0x65e,
0x6d6,0x6d7,0x6d8,0x6d9,0x6da,0x6db,0x6dc,
0x6df,0x6e0,0x6e1,0x6e2,0x6e3,0x6e4,
0x6e7,0x6e8,0x6ea,0x6eb,0x6ec
};
//印地文上下标字符 unicode
static final int[] HindiSup_Subs = {0x901,0x902,0x903,0x93c,0x941,0x942,0x943,0x944,0x945,0x946,0x947,0x948,0x94d,
0x951,0x952,0x953,0x954,0x962,0x963,
};
//希伯来文上下标字符 unicode
static final int[] HebrewSup_Subs = {0x591,0x592,0x593,0x594,0x595,0x596,0x597,0x598,0x599,0x59a,0x59b,0x59c,0x59d,0x59e,0x59f,0x5a0,
0x5a1,0x5a2,0x5a3,0x5a4,0x5a5,0x5a6,0x5a7,0x5a8,0x5a9,0x5aa,0x5ab,0x5ac,0x5ad,0x5ae,0x5af,0x5b0,0x5b1,0x5b2,
0x5b3,0x5b4,0x5b5,0x5b6,0x5b7,0x5b8,
0x5bb,0x5bd,0x5bf,0x5c1,0x5c2,0x5c4,0x5c5,0x5c7
};
//泰文 上下标字符 unicode
static final int[] ThaiSup_Subs = {0x0e31,0x0e34,0x0e35,0x0e36,0x0e37,0x0e38,0x0e39,0x0e3a,
0x0e47,0x0e48,0x0e49,0x0e4a,0x0e4b,0x0e4c,0x0e4d,0x0e4e
};
//左右结构字符 unicode
static final int[] CRLH = {0x903,0x93e,
};
//阿拉伯文 28个字母unicode范围 :0x060C--0x06FE
/**
* 阿拉伯文排版
* **/
@NonNull
public static String getArbicResult(String str){
StringBuffer stringBuffer = new StringBuffer();
for (int i=0;i<str.length();i++){
//取连续的三个字符判断
String substr = str.substring(i,i+1);
String pre_sub ;
String for_sub ;
if (i==0){
pre_sub = "";
}else {
pre_sub = str.substring(i-1,i);
}
if (i==str.length()-1){
for_sub = "";
}else {
for_sub = str.substring(i+1,i+2);
}
if (isArbic(substr)){ //如果当前字符是阿拉伯文
boolean ispreconnect = false ;
boolean isforconnect = false;
//排版规则1:
// 1.判断是否前连
if (isArbic(pre_sub)&&!pre_sub.equals("")){//如果前一个字符是阿拉伯文,判断是否前连
ispreconnect = getIsPreConnect(pre_sub);
}else{//不需要判断是否前连
}
//2.判断是否后连
if (isArbic(for_sub)&&!for_sub.equals("")){//如果前一个字符是阿拉伯文,判断是否后连
isforconnect = getIsForConnect(for_sub);
}else{//不需要判断是否后连
}
//排版规则2:
//以0x644开头,后面跟的是0x622,0x623,0x625,0x627
if (Integer.parseInt(gbEncoding(substr),16)==0x0644&&!for_sub.equals("")) {//是0x0644
int fors = Integer.parseInt(gbEncoding(for_sub),16);
if (fors==0x0622||fors==0x0623||fors==0x0625||fors==0x0627){//后面接0x622,0x623,0x625,0x627
//这种情况处理后 两个字符合并成一个字符
//判断0x0644前一个字符是否前连
int temp = 0;
if (ispreconnect){//是前连 取arabic_specs数组 1
temp = 1;
}else{//不是 取arabic_specs数组 0
temp = 0;
}
switch (fors){
case 0x0622:
substr = arabic_specs[0][temp]+"";
break;
case 0x0623:
substr = arabic_specs[1][temp]+"";
break;
case 0x0625:
substr = arabic_specs[2][temp]+"";
break;
case 0x0627:
substr = arabic_specs[3][temp]+"";
break;
}
substr = getStrFromUniCode(substr);
i+=1;
}
}else if (isNeedChange(substr)){//不是0x0644,并且在需要变形的数组中
int index = 0;
if(!isforconnect&&ispreconnect){//前连
index = 1;
}
if (isforconnect&&!ispreconnect){//后连
index = 2;
}
if (isforconnect&&ispreconnect){//中间
index = 3;
}
if (!isforconnect&&!ispreconnect){//独立
index = 4;
}
substr = getChangeReturn(substr,index);
substr = getStrFromUniCode(substr);
}
}else{//不是阿拉伯文
}
stringBuffer.append(substr);
}
return stringBuffer.toString();
}
/**
*返回重排后的字符
* */
private static String getChangeReturn(String substr,int index) {
int subunicode = Integer.parseInt(gbEncoding(substr),16);
for (int i=0;i<Arbic_Position.length;i++){
if (Arbic_Position[i][0]==subunicode){
substr = "\\u"+Integer.toHexString(Arbic_Position[i][index]);
}
}
return substr;
}
//阿拉伯文 当前字符是否需要重排
private static boolean isNeedChange(String substr) {
int subunicode = Integer.parseInt(gbEncoding(substr),16);
for (int i=0;i<Arbic_Position.length;i++){
if (Arbic_Position[i][0]==subunicode){
return true;
}
}
return false;
}
//后连
private static boolean getIsForConnect(String for_sub) {
int subunicode = Integer.parseInt(gbEncoding(for_sub),16);
for (int i=0;i<theSet2.length;i++){
if (theSet2[i]==subunicode){
return true;
}
}
return false;
}
//前连
private static boolean getIsPreConnect(String pre_sub) {
int subunicode = Integer.parseInt(gbEncoding(pre_sub),16);
for (int i=0;i<theSet1.length;i++){
if (theSet1[i]==subunicode){
return true;
}
}
return false;
}
//阿拉伯文上下标处理
public static byte[] adminSup_SubArabic(byte[] str_byte,byte[] follow_byte,int dots){
byte[] resultbyte= follow_byte;
if (dots==12){//字体为12时 上下标字符 实体占第1-4,11-12行 虚体占5-10行
for (int i=4*2;i<10*2;i++){//每行两个字节
str_byte[i]=0x00;//将虚体部分清除
}
}else if (dots==16){//字体为12时 上下标字符 实体占第1-6,14-16行 7-13虚体占行
for (int i=6*2;i<12*2;i++){//每行两个字节
str_byte[i]=0x00;//将虚体部分清除
}
}
for (int k=0;k<str_byte.length;k++){
resultbyte[k]= (byte) (str_byte[k]|follow_byte[k]);
}
return resultbyte;
}
//是否为需要处理的上下标特殊字符
public static boolean isSup_SubArabic(String str){
int subunicode = Integer.parseInt(gbEncoding(str),16);
for (int i=0;i<ArabicSup_Subs.length;i++){
if (ArabicSup_Subs[i]==subunicode){
return true;
}
}
return false;
}
//判断字符是否是阿拉伯文
public static boolean isArbic (String sub){
for (int j=0;j<sub.length();j++){
String substr = sub.substring(j,j+1);
if (substr.equals("")){
return false;
}
int subunicode = 0x00;
subunicode = Integer.parseInt(gbEncoding(substr),16);
if (((subunicode>0x0600)&&(subunicode<0x06ff))||//0600-06FF:阿拉伯文 (Arabic)
((subunicode>0xfb50)&&(subunicode<0xfdff))||// FB50-FDFF:阿拉伯表達形式A (Arabic Presentation Form-A)
((subunicode>0xfe70)&&(subunicode<0xfeff))){//FE70-FEFF:阿拉伯表達形式B (Arabic Presentation Form-B)
return true;
}else {
return false;
}
}
return false;
}
//泰文上下标处理
public static byte[] adminSup_SubThai(byte[] str_byte,byte[] follow_byte,int dots){
byte[] resultbyte= follow_byte;
if (dots==12){//字体为12时 上下标字符 实体占第1-4,11-12行 虚体占5-10行
for (int i=5*2;i<10*2;i++){//每行两个字节
str_byte[i]=0x00;//将虚体部分清除
}
}else if (dots==16){//字体为12时 上下标字符 实体占第1-6,14-16行 7-13虚体占行
for (int i=6*2;i<12*2;i++){//每行两个字节
str_byte[i]=0x00;//将虚体部分清除
}
}
for (int k=0;k<str_byte.length;k++){
resultbyte[k]= (byte) (str_byte[k]|follow_byte[k]);
}
return resultbyte;
}
//是否为需要处理的上下标特殊字符
public static boolean isSup_SubThai(String str){
int subunicode = Integer.parseInt(gbEncoding(str),16);
for (int i=0;i<ThaiSup_Subs.length;i++){
if (ThaiSup_Subs[i]==subunicode){
return true;
}
}
return false;
}
//判断字符是否是泰文
public static boolean isThai (String sub){
for (int j=0;j<sub.length();j++){
String substr = sub.substring(j,j+1);
if (substr.equals("")){
return false;
}
int subunicode = 0x00;
subunicode = Integer.parseInt(gbEncoding(substr),16);
//泰文编码范围0E00-0E3a,0E3f-0E5b,
if (((subunicode>0x0e00)&&(subunicode<0x0e3a))||
((subunicode>0x0e3f)&&(subunicode<0x0e5b))){
return true;
}else {
return false;
}
}
return false;
}
//希伯来文上下标处理
public static byte[] adminSup_SubHebrew(byte[] str_byte,byte[] follow_byte,int dots){
byte[] resultbyte= follow_byte;
if (dots==12){//字体为12时 上下标字符 实体占第1-4,11-12行 虚体占5-10行
for (int i=4*2;i<10*2;i++){//每行两个字节
str_byte[i]=0x00;//将虚体部分清除
}
}else if (dots==16){//字体为16时 上下标字符 实体占第1-6,14-16行 7-13虚体占行
for (int i=6*2;i<13*2;i++){//每行两个字节
str_byte[i]=0x00;//将虚体部分清除
}
}
for (int k=0;k<str_byte.length;k++){
resultbyte[k]= (byte) (str_byte[k]|follow_byte[k]);
}
return resultbyte;
}
//是否为需要处理的上下标特殊字符
public static boolean isSup_SubHebrew(String str){
int subunicode = Integer.parseInt(gbEncoding(str),16);
for (int i=0;i<HebrewSup_Subs.length;i++){
if (HebrewSup_Subs[i]==subunicode){
return true;
}
}
return false;
}
//判断字符是否是希伯来文
public static boolean isHebrew (String sub){
for (int j=0;j<sub.length();j++){
String substr = sub.substring(j,j+1);
if (substr.equals("")){
return false;
}
int subunicode = 0x00;
subunicode = Integer.parseInt(gbEncoding(substr),16);
//希伯来文编码范围:0590-05ff
if (((subunicode>0x0590)&&(subunicode<0x05ff))
){
return true;
}else {
return false;
}
}
return false;
}
//印地文上下标处理
public static byte[] adminSup_SubHindi(byte[] str_byte,byte[] follow_byte,int dots){
byte[] resultbyte= follow_byte;
if (dots==12){//字体为12时 上下标字符 实体占第1-5,12行 虚体占6-11行
for (int i=5*2;i<11*2;i++){//每行两个字节
str_byte[i]=0x00;//将虚体部分清除
}
}else if (dots==16){//字体为16时 上下标字符 实体占第1-6,13-16行 7-12虚体占行
for (int i=7*2;i<13*2;i++){//每行两个字节
str_byte[i]=0x00;//将虚体部分清除
}
}
for (int k=0;k<str_byte.length;k++){
resultbyte[k]= (byte) (str_byte[k]|follow_byte[k]);
}
return resultbyte;
}
//是否为需要处理的印地文上下标特殊字符
public static boolean isSup_SubHindi(String str){
int subunicode = Integer.parseInt(gbEncoding(str),16);
for (int i=0;i<HindiSup_Subs.length;i++){
if (HindiSup_Subs[i]==subunicode){
return true;
}
}
return false;
}
//判断字符是否是印地文
public static boolean isHindi (String sub){
for (int j=0;j<sub.length();j++){
String substr = sub.substring(j,j+1);
if (substr.equals("")){
return false;
}
int subunicode = 0x00;
subunicode = Integer.parseInt(gbEncoding(substr),16);
//印地文编码范围:0900-097f
if (((subunicode>0x0900)&&(subunicode<0x097f))
){
return true;
}else {
return false;
}
}
return false;
}
/*
* 根据字符转unicode码
* */
private static String gbEncoding(final String gbString) {
char[] utfBytes = gbString.toCharArray();
String unicodeBytes = "";
for (int byteIndex = 0; byteIndex < utfBytes.length; byteIndex++) {
String hexB = Integer.toHexString(utfBytes[byteIndex]);
if (hexB.length() <= 2) {
hexB = "00" + hexB;
}
// unicodeBytes = unicodeBytes + "\\u" + hexB;
unicodeBytes = unicodeBytes + hexB;
}
// System.out.println("unicodeBytes is: " + unicodeBytes);
return unicodeBytes;
}
/*
* 根据unicode转字符
* */
@NonNull
private static String getStrFromUniCode(String unicode){
StringBuffer string = new StringBuffer();
String[] hex = unicode.split("\\\\u");
for (int i = 1; i < hex.length; i++) {
// 转换出每一个代码点
int data = Integer.parseInt(hex[i], 16);
// 追加成string
string.append((char) data);
}
String s = string.toString();
return string.toString();
}
public static String replaceUnicode(String sourceStr)
{
String regEx= "["+
"\u0000-\u001F"+//:C0控制符及基本拉丁文 (C0 Control and Basic Latin)
"\u007F-\u00A0" +// :特殊 (Specials);
// "\u0600-\u06FF"+// 阿拉伯文
"\u064b-\u064b"+// 阿拉伯文
// "\u0E00-\u0E7F"+//:泰文 (Thai)
"]";
// "\u4E00-\u9FBF"+//:CJK 统一表意符号 (CJK Unified Ideographs)
// "\u4DC0-\u4DFF"+//:易经六十四卦符号 (Yijing Hexagrams Symbols)
// "\u0000-\u007F"+//:C0控制符及基本拉丁文 (C0 Control and Basic Latin)
// "\u0080-\u00FF"+//:C1控制符及拉丁:补充-1 (C1 Control and Latin 1 Supplement)
// "\u0100-\u017F"+//:拉丁文扩展-A (Latin Extended-A)
// "\u0180-\u024F"+//:拉丁文扩展-B (Latin Extended-B)
// "\u0250-\u02AF"+//:国际音标扩展 (IPA Extensions)
// "\u02B0-\u02FF"+//:空白修饰字母 (Spacing Modifiers)
// "\u0300-\u036F"+//:结合用读音符号 (Combining Diacritics Marks)
// "\u0370-\u03FF"+//:希腊文及科普特文 (Greek and Coptic)
// "\u0400-\u04FF"+//:西里尔字母 (Cyrillic)
// "\u0500-\u052F"+//:西里尔字母补充 (Cyrillic Supplement)
// "\u0530-\u058F"+//:亚美尼亚语 (Armenian)
// "\u0590-\u05FF"+//:希伯来文 (Hebrew)
// "\u0600-\u06FF"+//:阿拉伯文 (Arabic)
// "\u0700-\u074F"+//:叙利亚文 (Syriac)
// "\u0750-\u077F"+//:阿拉伯文补充 (Arabic Supplement)
// "\u0780-\u07BF"+//:马尔代夫语 (Thaana)
// //"\u07C0-\u077F"+//:西非书面语言 (N'Ko)
// "\u0800-\u085F"+//:阿维斯塔语及巴列维语 (Avestan and Pahlavi)
// "\u0860-\u087F"+//:Mandaic
// "\u0880-\u08AF"+//:撒马利亚语 (Samaritan)
// "\u0900-\u097F"+//:天城文书 (Devanagari)
// "\u0980-\u09FF"+//:孟加拉语 (Bengali)
// "\u0A00-\u0A7F"+//:锡克教文 (Gurmukhi)
// "\u0A80-\u0AFF"+//:古吉拉特文 (Gujarati)
// "\u0B00-\u0B7F"+//:奥里亚文 (Oriya)
// "\u0B80-\u0BFF"+//:泰米尔文 (Tamil)
// "\u0C00-\u0C7F"+//:泰卢固文 (Telugu)
// "\u0C80-\u0CFF"+//:卡纳达文 (Kannada)
// "\u0D00-\u0D7F"+//:德拉维族语 (Malayalam)
// "\u0D80-\u0DFF"+//:僧伽罗语 (Sinhala)
// "\u0E00-\u0E7F"+//:泰文 (Thai)
// "\u0E80-\u0EFF"+//:老挝文 (Lao)
// "\u0F00-\u0FFF"+//:藏文 (Tibetan)
// "\u1000-\u109F"+//:缅甸语 (Myanmar)
// "\u10A0-\u10FF"+//:格鲁吉亚语 (Georgian)
// "\u1100-\u11FF"+//:朝鲜文 (Hangul Jamo)
// "\u1200-\u137F"+//:埃塞俄比亚语 (Ethiopic)
// "\u1380-\u139F"+//:埃塞俄比亚语补充 (Ethiopic Supplement)
// "\u13A0-\u13FF"+//:切罗基语 (Cherokee)
// "\u1400-\u167F"+//:统一加拿大土著语音节 (Unified Canadian Aboriginal Syllabics)
// "\u1680-\u169F"+//:欧甘字母 (Ogham)
// "\u16A0-\u16FF"+//:如尼文 (Runic)
// "\u1700-\u171F"+//:塔加拉语 (Tagalog)
// "\u1720-\u173F"+//:Hanunóo
// "\u1740-\u175F"+//:Buhid
// "\u1760-\u177F"+//:Tagbanwa
// "\u1780-\u17FF"+//:高棉语 (Khmer)
// "\u1800-\u18AF"+//:蒙古文 (Mongolian)
// "\u18B0-\u18FF"+//:Cham
// "\u1900-\u194F"+//:Limbu
// "\u1950-\u197F"+//:德宏泰语 (Tai Le)
// "\u1980-\u19DF"+//:新傣仂语 (New Tai Lue)
// "\u19E0-\u19FF"+//:高棉语记号 (Kmer Symbols)
// "\u1A00-\u1A1F"+//:Buginese
// "\u1A20-\u1A5F"+//:Batak
// "\u1A80-\u1AEF"+//:Lanna
// "\u1B00-\u1B7F"+//:巴厘语 (Balinese)
// "\u1B80-\u1BB0"+//:巽他语 (Sundanese)
// "\u1BC0-\u1BFF"+//:Pahawh Hmong
// "\u1C00-\u1C4F"+//:雷布查语(Lepcha)
// "\u1C50-\u1C7F"+//:Ol Chiki
// "\u1C80-\u1CDF"+//:曼尼普尔语 (Meithei/Manipuri)
// "\u1D00-\u1D7F"+//:语音学扩展 (Phone tic Extensions)
// "\u1D80-\u1DBF"+//:语音学扩展补充 (Phonetic Extensions Supplement)
// "\u1DC0-\u1DFF"+//结合用读音符号补充 (Combining Diacritics Marks Supplement)
// "\u1E00-\u1EFF"+//:拉丁文扩充附加 (Latin Extended Additional)
// "\u1F00-\u1FFF"+//:希腊语扩充 (Greek Extended)
// "\u2000-\u206F"+//:常用标点 (General Punctuation)
// "\u2070-\u209F"+//:上标及下标 (Superscripts and Subscripts)
// "\u20A0-\u20CF"+//:货币符号 (Currency Symbols)
// "\u20D0-\u20FF"+//:组合用记号 (Combining Diacritics Marks for Symbols)
// "\u2100-\u214F"+//:字母式符号 (Letterlike Symbols)
// "\u2150-\u218F"+//:数字形式 (Number Form)
// "\u2190-\u21FF"+//:箭头 (Arrows)
// "\u2200-\u22FF"+//:数学运算符 (Mathematical Operator)
// "\u2300-\u23FF"+//:杂项工业符号 (Miscellaneous Technical)
// "\u2400-\u243F"+//:控制图片 (Control Pictures)
// "\u2440-\u245F"+//:光学识别符 (Optical Character Recognition)
// "\u2460-\u24FF"+//:封闭式字母数字 (Enclosed Alphanumerics)
// "\u2500-\u257F"+//:制表符 (Box Drawing)
// "\u2580-\u259F"+//:方块元素 (Block Element)
// "\u25A0-\u25FF"+//:几何图形 (Geometric Shapes)
// "\u2600-\u26FF"+//:杂项符号 (Miscellaneous Symbols)
// "\u2700-\u27BF"+//:印刷符号 (Dingbats)
// "\u27C0-\u27EF"+//:杂项数学符号-A (Miscellaneous Mathematical Symbols-A)
// "\u27F0-\u27FF"+//:追加箭头-A (Supplemental Arrows-A)
// "\u2800-\u28FF"+//:盲文点字模型 (Braille Patterns)
// "\u2900-\u297F"+//:追加箭头-B (Supplemental Arrows-B)
// "\u2980-\u29FF"+//:杂项数学符号-B (Miscellaneous Mathematical Symbols-B)
// "\u2A00-\u2AFF"+//:追加数学运算符 (Supplemental Mathematical Operator)
// "\u2B00-\u2BFF"+//:杂项符号和箭头 (Miscellaneous Symbols and Arrows)
// "\u2C00-\u2C5F"+//:格拉哥里字母 (Glagolitic)
// "\u2C60-\u2C7F"+//:拉丁文扩展-C (Latin Extended-C)
// "\u2C80-\u2CFF"+//:古埃及语 (Coptic)
// "\u2D00-\u2D2F"+//:格鲁吉亚语补充 (Georgian Supplement)
// "\u2D30-\u2D7F"+//:提非纳文 (Tifinagh)
// "\u2D80-\u2DDF"+//:埃塞俄比亚语扩展 (Ethiopic Extended)
// "\u2E00-\u2E7F"+//:追加标点 (Supplemental Punctuation)
// "\u2E80-\u2EFF"+//:CJK 部首补充 (CJK Radicals Supplement)
// "\u2F00-\u2FDF"+//:康熙字典部首 (Kangxi Radicals)
// "\u2FF0-\u2FFF"+//:表意文字描述符 (Ideographic Description Characters)
// "\u3000-\u303F"+//:CJK 符号和标点 (CJK Symbols and Punctuation)
// "\u3040-\u309F"+//:日文平假名 (Hiragana)
// "\u30A0-\u30FF"+//:日文片假名 (Katakana)
// "\u3100-\u312F"+//:注音字母 (Bopomofo)
// "\u3130-\u318F"+//:朝鲜文兼容字母 (Hangul Compatibility Jamo)
// "\u3190-\u319F"+//:象形字注释标志 (Kanbun)
// "\u31A0-\u31BF"+//:注音字母扩展 (Bopomofo Extended)
// "\u31C0-\u31EF"+//:CJK 笔画 (CJK Strokes)
// "\u31F0-\u31FF"+//:日文片假名语音扩展 (Katakana Phonetic Extensions)
// "\u3200-\u32FF"+//:封闭式 CJK 文字和月份 (Enclosed CJK Letters and Months)
// "\u3300-\u33FF"+//:CJK 兼容 (CJK Compatibility)
// "\u3400-\u4DBF"+//:CJK 统一表意符号扩展 A (CJK Unified Ideographs Extension A)
// "\u4DC0-\u4DFF"+//:易经六十四卦符号 (Yijing Hexagrams Symbols)
// "\u4E00-\u9FBF"+//:CJK 统一表意符号 (CJK Unified Ideographs)
// "\uA000-\uA48F"+//:彝文音节 (Yi Syllables)
// "\uA490-\uA4CF"+//:彝文字根 (Yi Radicals)
// "\uA500-\uA61F"+//:Vai
// "\uA660-\uA6FF"+//:统一加拿大土著语音节补充 (Unified Canadian Aboriginal Syllabics Supplement)
// "\uA700-\uA71F"+//:声调修饰字母 (Modifier Tone Letters)
// "\uA720-\uA7FF"+//:拉丁文扩展-D (Latin Extended-D)
// "\uA800-\uA82F"+//:Syloti Nagri
// "\uA840-\uA87F"+//:八思巴字 (Phags-pa)
// "\uA880-\uA8DF"+//:Saurashtra
// "\uA900-\uA97F"+//:爪哇语 (Javanese)
// "\uA980-\uA9DF"+//:Chakma
// "\uAA00-\uAA3F"+//:Varang Kshiti
// "\uAA40-\uAA6F"+//:Sorang Sompeng
// "\uAA80-\uAADF"+//:Newari
// "\uAB00-\uAB5F"+//:越南傣语 (Vi?t Thái)
// "\uAB80-\uABA0"+//:Kayah Li
// "\uAC00-\uD7AF"+//:朝鲜文音节 (Hangul Syllables)
// //"\uD800-\uDBFF"+//:High-half zone of UTF-16
// //"\uDC00-\uDFFF"+//:Low-half zone of UTF-16
// "\uE000-\uF8FF"+//:自行使用区域 (Private Use Zone)
// "\uF900-\uFAFF"+//:CJK 兼容象形文字 (CJK Compatibility Ideographs)
// "\uFB00-\uFB4F"+//:字母表达形式 (Alphabetic Presentation Form)
// "\uFB50-\uFDFF"+//:阿拉伯表达形式A (Arabic Presentation Form-A)
// "\uFE00-\uFE0F"+//:变量选择符 (Variation Selector)
// "\uFE10-\uFE1F"+//:竖排形式 (Vertical Forms)
// "\uFE20-\uFE2F"+//:组合用半符号 (Combining Half Marks)
// "\uFE30-\uFE4F"+//:CJK 兼容形式 (CJK Compatibility Forms)
// "\uFE50-\uFE6F"+//:小型变体形式 (Small Form Variants)
// "\uFE70-\uFEFF"+//:阿拉伯表达形式B (Arabic Presentation Form-B)
// "\uFF00-\uFFEF"+//:半型及全型形式 (Halfwidth and Fullwidth Form)
// "\uFFF0-\uFFFF]";//:特殊 (Specials);
Pattern pattern= Pattern.compile(regEx);
Matcher matcher=pattern.matcher(sourceStr);
return matcher.replaceAll("");
}
}
字库文件读取工具类:
package xc.LEDILove.font;
import android.content.Context;
import android.content.res.AssetManager;
import android.util.Log;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import java.util.logging.Handler;
import xc.LEDILove.utils.ArabicUtils;
import xc.LEDILove.utils.Helpful;
import xc.LEDILove.utils.LangUtils;
/**
* craete by YuChang on 2017/3/6 09:34
* <p>
* 字库帮助类
* 目前支持 12 16
*/
public class FontUtils {
private Context context;
private boolean hasChinese = false;
private boolean hasJapanese = false;
private boolean hasKorean = false;
private boolean hasWestern = false;
//英文的 12点位高 占12字节宽8位,16点位高占16字节 宽8位
private int asciiwordByteByDots = 12;
/*
* 字库名
*/
public String dotMatrixFont = "";
/*
* 字库用几个点表示(行) 点阵字库高度
*/
public int dots = -1;
/***
* 正斜粗 字库的 通用后缀 默认 Z 正体
*/
public String zlx = "Z";
/***
* 列
*/
public int line = 16;
/*
* 一个字用点表示需要多少字节,12X16的字体需要24个字节 16x16需要32字节 ASCII 12*8 12字节 16*8 16字节
*/
public int wordByteByDots = 24;
private boolean[][] matrix;
public byte[] dataResult;
private int totalByte = 0;
private String str;
private int realLEDWidget = 0;
private int lineTotalByte = 0;
private boolean isReadBC =false;
private Thread word_stork;
public FontUtils(Context context, String zlcs, int pix) {
this.context = context;
// word_stork = new Thread(new)
if (zlcs!=null){
this.zlx = zlcs;
}
setPix(pix);
}
/**
* 获取字库信息
*/
public synchronized boolean[][] getWordsInfo(String str) {
//由于个别字符显示问题 在读字库前先做处理
// String inversod = inverso(str);//字符反序
String inversod = str;
inversod = ArabicUtils.getArbicResult(inversod);//阿拉伯文重排
//针对阿拉伯文和希伯来文 需要反序处理
if (ArabicUtils.isArbic(inversod)||ArabicUtils.isHebrew(inversod)){
// Log.e("befor>>>>>>",inversod.substring(inversod.length()-1,inversod.length()));
Log.e("befor>>>>>>",inversod);
inversod = adminInverso(inversod);//字符反序
// inversod = inverso(inversod);
// Log.e("after>>>>>>",inversod.substring(inversod.length()-1,inversod.length()));
Log.e("after>>>>>>",inversod);
}
// for (int i=0;i<inversod.length();i++){
// Log.e("after",gbEncoding(inversod.substring(i,i+1)));
// }
inversod = ArabicUtils.replaceUnicode(inversod);//unicode不可见字符屏蔽
// getWordsByte(adjustStr(inversod));
getzimodata(adjustStr(inversod));
return matrix;
}
/**
* 含阿拉伯/希伯来文字符串 重新排序
* 问题:阿拉伯/希伯来文字符串从右至左读取,一般来说直接全部反序就行
* 当时用String.sub()方法逐一取字符时(从右向左) 在遇到连续的非阿拉伯/希伯来文时,java默认从连续字符串的左边读取
*那么问题是:如果不区分开 在读取的时候就乱了
* 思路:按照正常字符串的方式 从左向右读取,第一个(也就是字符串的最后一个字符)必须是正常的字符(如果不是添加“1”)
* 从左至右 遇到正常的字符集 反序
* */
private String adminInverso(String str){
String result =str;
boolean isEndOfSpecial = false;//阿拉伯字符结尾
boolean isendofspace =false;//空格结尾
String endstr = str.substring(str.length()-1,str.length());
if (ArabicUtils.isArbic(endstr)||ArabicUtils.isHebrew(endstr)){//字符串以阿拉伯文/希伯来结尾,这种情况整个字符串从右至左
Log.e("isArbic>>>>>>",str.substring(str.length()-1,str.length()));
isEndOfSpecial = true;
str = str+"1";
// result = inverso(str);//整个字符串反序
}
// else if (endstr.equals(" ")){
// isendofspace = true;
// str = str+"1";
// }
// if (!str.substring(str.length()-1,str.length()).equals(" "))
// {//字符串不以阿拉伯文结尾,从右至左解码,解码时最后剩余的非阿拉伯字符为左到右
Log.e("isnomal>>>>>>",str.substring(str.length()-1,str.length()));
StringBuffer stringBuffer = new StringBuffer();
StringBuffer laststrs = new StringBuffer();
StringBuffer arabicstrs = new StringBuffer();
for (int i=str.length();i>0;i--){
String sub = str.substring(i-1,i);
String follow = "";
if (i>1){
follow = str.substring(i-2,i-1);
}
if (!ArabicUtils.isArbic(sub)&&!ArabicUtils.isHebrew(sub)){
laststrs.append(sub);
if ((!follow.equals(""))&&(ArabicUtils.isArbic(follow)||ArabicUtils.isHebrew(follow))){
stringBuffer.append(inverso(laststrs.toString()));
laststrs.delete(0,laststrs.length());
}
}
else {
stringBuffer.append(sub);
}
}
if (isEndOfSpecial){
stringBuffer.delete(0,1);
}
result = stringBuffer.toString();
return result;
}
//字符串反序
private String inverso (String str){
StringBuffer stringBuffer = new StringBuffer();
List<String> list = new ArrayList<>();
for (int i=0;i<str.length();i++){
String sub = str.substring(i,i+1);
list.add(sub);
}
for (int j=0;j<list.size();j++){
stringBuffer.append(list.get(list.size()-j-1));
}
return stringBuffer.toString();
}
//替换字符中英文状态下 - 字符显示错误问题
private String adjustStr(String str){
StringBuffer stringBuffer = new StringBuffer();
for (int i=0;i<str.length();i++){
String subStr = str.substring(i,i+1);
Log.e(subStr+"unicode>>>>",gbEncoding(subStr));
if (gbEncoding(subStr).equals("\\u2013")){
subStr = getStrFromUniCode("\\uff0d");
Log.e("unicode>>>>","shift");
}
stringBuffer.append(subStr);
}
return stringBuffer.toString();
}
// private boolean[] isReadBCs;
/**
* 读取字模数据
* */
public byte[] getzimodata(String str){
this.str = str;
dataResult = new byte[str.length()*dots*2];
int hasDealByte = 0;
for (int index = 0; index < str.length(); index++) {
String subjectStr = str.substring(index, index + 1);
String followStr ="";
if (index<str.length()-1){
followStr = str.substring(index+1,index+2);
}
byte[] data = readAllZiMo(subjectStr);
byte[] replacedata =new byte[dots*2];
for (int r =0;r<replacedata.length;r++){
replacedata[r]=0x00;
}
if (data != null) {
byte[] data_follow = readAllZiMo(followStr);
// 特殊国别上下标处理
if (!followStr.equals("")){//后续字符不为空
//阿拉伯文上下标处理
if (ArabicUtils.isArbic(subjectStr)&ArabicUtils.isArbic(followStr)){//都为阿拉伯字符
if (ArabicUtils.isSup_SubArabic(subjectStr)){//当前字符是否为上下标特殊字符 因为阿拉伯文输入方向为左到右 所以判断当前是否为下一字符的上下标
if(data_follow!=null){//后续字符数据不为空
data = ArabicUtils.adminSup_SubArabic(data,data_follow,dots);//将当前字符数据叠加到后面字符数据中
index+=1;
System.arraycopy(replacedata, 0, dataResult, hasDealByte, replacedata.length);//当前字符的数据用空数据代替
hasDealByte = hasDealByte + replacedata.length;
System.arraycopy(data, 0, dataResult, hasDealByte, data.length);
hasDealByte = hasDealByte + data.length;
}
}else {
System.arraycopy(data, 0, dataResult, hasDealByte, data.length);
hasDealByte = hasDealByte + data.length;
}
}else
//希伯来文上下标处理
if (ArabicUtils.isHebrew(subjectStr)&ArabicUtils.isHebrew(followStr)){//都为希伯来字符
if (ArabicUtils.isSup_SubHebrew(subjectStr)){//当前字符是否为上下标特殊字符 因为希伯来文输入方向为左到右 所以判断当前是否为下一字符的上下标
if(data_follow!=null){//后续字符数据不为空
data = ArabicUtils.adminSup_SubHebrew(data,data_follow,dots);//将当前字符数据叠加到后面字符数据中
index+=1;
System.arraycopy(replacedata, 0, dataResult, hasDealByte, replacedata.length);
hasDealByte = hasDealByte + replacedata.length;
System.arraycopy(data, 0, dataResult, hasDealByte, data.length);
hasDealByte = hasDealByte + data.length;
}
}else {
System.arraycopy(data, 0, dataResult, hasDealByte, data.length);
hasDealByte = hasDealByte + data.length;
}
}else if (ArabicUtils.isHindi(subjectStr)&ArabicUtils.isHindi(followStr)){//都为印地文
if(data_follow!=null&&ArabicUtils.isSup_SubHindi(followStr)){//后续字符数据不为空,且为上下标字符
data = ArabicUtils.adminSup_SubHindi(data_follow,data,dots);//将后面字符数据叠加到当前字符数据中
index+=1;
System.arraycopy(data, 0, dataResult, hasDealByte, data.length);
hasDealByte = hasDealByte + data.length;
System.arraycopy(replacedata, 0, dataResult, hasDealByte, replacedata.length);
hasDealByte = hasDealByte + replacedata.length;
}
else {
System.arraycopy(data, 0, dataResult, hasDealByte, data.length);
hasDealByte = hasDealByte + data.length;
}
}else
//泰文上下标处理
if (ArabicUtils.isThai(subjectStr)&ArabicUtils.isThai(followStr)){//都为泰文字符
String follow2str = "";
if(index<str.length()-2){
follow2str = str.substring(index+2,index+3);//泰文存在上下标同时存在的情况
}
if (!follow2str.equals("")&&ArabicUtils.isSup_SubThai(follow2str)&&ArabicUtils.isSup_SubThai(followStr)){
byte[] data_follow2 = readAllZiMo(follow2str);
if(data_follow2!=null){//后续字符数据不为空
data = ArabicUtils.adminSup_SubThai(data_follow,data,dots);//将后面字符数据叠加到当前字符数据中
data = ArabicUtils.adminSup_SubThai(data_follow2,data,dots);//将后面字符数据叠加到当前字符数据中
index+=2;
System.arraycopy(data, 0, dataResult, hasDealByte, data.length);
hasDealByte = hasDealByte + data.length;
System.arraycopy(replacedata, 0, dataResult, hasDealByte, replacedata.length);
hasDealByte = hasDealByte + replacedata.length;
System.arraycopy(replacedata, 0, dataResult, hasDealByte, replacedata.length);
hasDealByte = hasDealByte + replacedata.length;
}
}else if (ArabicUtils.isSup_SubThai(followStr)){//后面字符是否为上下标特殊字符
if(data_follow!=null){//后续字符数据不为空
data = ArabicUtils.adminSup_SubThai(data_follow,data,dots);//将后面字符数据叠加到当前字符数据中
index+=1;
System.arraycopy(data, 0, dataResult, hasDealByte, data.length);
hasDealByte = hasDealByte + data.length;
System.arraycopy(replacedata, 0, dataResult, hasDealByte, replacedata.length);
hasDealByte = hasDealByte + replacedata.length;
}
}else {
System.arraycopy(data, 0, dataResult, hasDealByte, data.length);
hasDealByte = hasDealByte + data.length;
}
}else {
System.arraycopy(data, 0, dataResult, hasDealByte, data.length);
hasDealByte = hasDealByte + data.length;
}
}else {
System.arraycopy(data, 0, dataResult, hasDealByte, data.length);
hasDealByte = hasDealByte + data.length;
}
}
}
getbooleandata(dataResult);//将读取的byte数组数据转化成boolean二维数组
//字模读取出来的数据为十六进制,
// fillMatrix(lineTotalByte);
inserAemptyData();//为解决某些字库 字模数据之间连在一起没有间隔 所以在消除多余间隔前在所有字符字模数据之间插入一排空值
fillMatrixEmpty();//字符间隔判定-解决字符间隔过大的情况
return dataResult;
}
/***
* 1.
* @param str
* @return
*/
/*public byte[] getWordsByte(String str) {
List<byte[]> databytes = new ArrayList<>();
this.str = str;
//预先遍历,确认总的字节数,因为不同字库12点阵字模的 宽度和字节都不一样
totalByte = 0;
for (int index = 0; index < str.length(); index++) {
String subjectStr = str.substring(index, index + 1);
// totalByte = totalByte + wordByteByDots;
if (LangUtils.isChinese(subjectStr)) {
totalByte = totalByte + wordByteByDots;
} else if (LangUtils.isJapanese(subjectStr)) {
totalByte = totalByte + wordByteByDots;
} else if (LangUtils.isKorean(subjectStr)) {
totalByte = totalByte + wordByteByDots;
} else {
if ((int) subjectStr.charAt(0) < 128) {
//都不是,就按照 英文处理
if (dots == 12) {
totalByte = totalByte + 12;
}
if (dots == 16) {
totalByte = totalByte + 16;
}
} else {
// //特殊字符
totalByte = totalByte + wordByteByDots;
}
}
}
//初始化总的大小
dataResult = new byte[totalByte];
// isReadBCs = new boolean[str.length()];//记录读取的字库文件
//依次读取字模信息
//已经处理的字节
int hasDealByte = 0;
for (int index = 0; index < str.length(); index++) {
//判断是 中 英 韩 日 标点符号
String subjectStr = str.substring(index, index + 1);
String followStr = "";
if (index<str.length()-1){
followStr = str.substring(index+1,index+2);
}
// byte[] data = readAllZiMo(subjectStr);
// System.arraycopy(data, 0, dataResult, hasDealByte, data.length);
// hasDealByte = hasDealByte + data.length;
if (LangUtils.isChinese(subjectStr)) {
hasChinese = true;
byte[] data = readChineseZiMo(subjectStr);
// databytes.add(data);
System.arraycopy(data, 0, dataResult, hasDealByte, data.length);
hasDealByte = hasDealByte + data.length;
} else if (LangUtils.isJapanese(subjectStr)) {
hasJapanese = true;
byte[] data = readJapaneseZiMo(subjectStr);
// databytes.add(data);
System.arraycopy(data, 0, dataResult, hasDealByte, data.length);
hasDealByte = hasDealByte + data.length;
} else if (LangUtils.isKorean(subjectStr)) {
hasKorean = true;
byte[] data = readKoreanZiMo(subjectStr);
// databytes.add(data);
System.arraycopy(data, 0, dataResult, hasDealByte, data.length);
hasDealByte = hasDealByte + data.length;
}
// {
//标点符号
else if ((int) subjectStr.charAt(0) < 128) {
byte[] data = readAsciiZiMo(subjectStr);
if (data != null) {
// databytes.add(data);
System.arraycopy(data, 0, dataResult, hasDealByte, data.length);
hasDealByte = hasDealByte + data.length;
}
}
else {
hasWestern = true;
byte[] replacedata =new byte[24];
for (int r =0;r<replacedata.length;r++){
replacedata[r]=0x00;
}
byte[] data = readTSZiMo(subjectStr);
if (data != null) {
byte[] data_follow = readTSZiMo(followStr);
if (!followStr.equals("")){//后续字符不为空
//阿拉伯文上下标处理
if (ArabicUtils.isArbic(subjectStr)&ArabicUtils.isArbic(followStr)){//都为阿拉伯字符
if (ArabicUtils.isSup_SubArabic(subjectStr)){//当前字符是否为上下标特殊字符 因为阿拉伯文输入方向为左到右 所以判断当前是否为下一字符的上下标
if(data_follow!=null){//后续字符数据不为空
data = ArabicUtils.adminSup_SubArabic(data,data_follow,dots);//将当前字符数据叠加到后面字符数据中
index+=1;
// System.arraycopy(data, 0, dataResult, hasDealByte, data.length);
// hasDealByte = hasDealByte + data.length;
// System.arraycopy(replacedata, 0, dataResult, hasDealByte, replacedata.length);
// hasDealByte = hasDealByte + replacedata.length;
}
}else {
// System.arraycopy(data, 0, dataResult, hasDealByte, data.length);
// hasDealByte = hasDealByte + data.length;
}
}
//希伯来文上下标处理
if (ArabicUtils.isHebrew(subjectStr)&ArabicUtils.isHebrew(followStr)){//都为希伯来字符
if (ArabicUtils.isSup_SubHebrew(subjectStr)){//当前字符是否为上下标特殊字符 因为希伯来文输入方向为左到右 所以判断当前是否为下一字符的上下标
if(data_follow!=null){//后续字符数据不为空
data = ArabicUtils.adminSup_SubHebrew(data,data_follow,dots);//将当前字符数据叠加到后面字符数据中
index+=1;
// System.arraycopy(data, 0, dataResult, hasDealByte, data.length);
// hasDealByte = hasDealByte + data.length;
// System.arraycopy(replacedata, 0, dataResult, hasDealByte, replacedata.length);
// hasDealByte = hasDealByte + replacedata.length;
}
}else {
// System.arraycopy(data, 0, dataResult, hasDealByte, data.length);
// hasDealByte = hasDealByte + data.length;
}
}
//泰文上下标处理
if (ArabicUtils.isThai(subjectStr)&ArabicUtils.isThai(followStr)){//都为泰文字符
String follow2str = "";
if(index<str.length()-2){
follow2str = str.substring(index+2,index+3);//泰文存在上下标同时存在的情况
}
if (!follow2str.equals("")&&ArabicUtils.isSup_SubThai(follow2str)&&ArabicUtils.isSup_SubThai(followStr)){
byte[] data_follow2 = readTSZiMo(follow2str);
if(data_follow2!=null){//后续字符数据不为空
data = ArabicUtils.adminSup_SubThai(data_follow,data,dots);//将后面字符数据叠加到当前字符数据中
data = ArabicUtils.adminSup_SubThai(data_follow2,data,dots);//将后面字符数据叠加到当前字符数据中
index+=2;
// System.arraycopy(data, 0, dataResult, hasDealByte, data.length);
// hasDealByte = hasDealByte + data.length;
// System.arraycopy(replacedata, 0, dataResult, hasDealByte, replacedata.length);
// hasDealByte = hasDealByte + replacedata.length;
// System.arraycopy(replacedata, 0, dataResult, hasDealByte, replacedata.length);
// hasDealByte = hasDealByte + replacedata.length;
}
}else
if (ArabicUtils.isSup_SubThai(followStr)){//后面字符是否为上下标特殊字符
if(data_follow!=null){//后续字符数据不为空
data = ArabicUtils.adminSup_SubThai(data_follow,data,dots);//将后面字符数据叠加到当前字符数据中
index+=1;
// System.arraycopy(data, 0, dataResult, hasDealByte, data.length);
// hasDealByte = hasDealByte + data.length;
// System.arraycopy(replacedata, 0, dataResult, hasDealByte, replacedata.length);
// hasDealByte = hasDealByte + replacedata.length;
}
}else {
// System.arraycopy(data, 0, dataResult, hasDealByte, data.length);
// hasDealByte = hasDealByte + data.length;
}
}
}
// databytes.add(data);
System.arraycopy(data, 0, dataResult, hasDealByte, data.length);
hasDealByte = hasDealByte + data.length;
}
// }
}
// isReadBCs[index] = isReadBC;
}
//
// List<Byte> byteList =new ArrayList<>();
//
// for (int k=0;k<databytes.size();k++){
// byte[] index =databytes.get(k);
// for (int j=0;j<index.length;j++){
// byteList.add(index[j]);
// }
// }
// dataResult = new byte[byteList.size()];
// for (int s = 0;s<byteList.size();s++){
// dataResult[s] = byteList.get(s);
// }
dataResult = getResultWordsByte(dataResult);
// getbooleandata(dataResult);
//字模读取出来的数据为十六进制,
fillMatrix(lineTotalByte);
insertEmptyData();//为解决某些字库 字模数据之间连在一起没有间隔 所以在消除多余间隔前在所有字符字模数据之间插入一排空值
fillMatrixEmpty();//字符间隔判定-解决字符间隔过大的情况
return dataResult;
}*/
private List<Integer> spaceIndexs;//空格所在占有
private List<Integer> ArabicIndexs;//阿拉伯文所在位置
private List<Integer> HindiIndexs;//印地文所在位置
private List<Integer> CRLHIndexs;//左右结构字符所在位置
public int getLEDWidget() {
return realLEDWidget;
}
/**
* 在字符间插入一位空格
* */
private void inserAemptyData(){
Log.e("matrix",matrix[0].length+"");
//初始化空值数组
empty_data = new boolean[dots];
for (int i=0;i<dots;i++) {
empty_data[i] = false;
}
ArrayList<boolean[]> tem = new ArrayList<>();
int position = -1;//更改后的数组当前下标
int matrix_index=-1;//更改前的数组当前下标
spaceIndexs = new ArrayList<>();
ArabicIndexs = new ArrayList<>();
HindiIndexs = new ArrayList<>();
CRLHIndexs = new ArrayList<>();
for (int i=0;i<str.length();i++){
String indexstr = str.substring(i, i + 1);
String followstr = "";
if (i<str.length()-1){
followstr = str.substring(i+1,i+2);
}
boolean isSpace = indexstr.equals(" ");
boolean isArabic = (!followstr.equals(""))&&ArabicUtils.isArbic(followstr)&&ArabicUtils.isArbic(indexstr);
boolean isHindi = (!followstr.equals(""))&&ArabicUtils.isHindi(followstr)&&ArabicUtils.isHindi(indexstr);
Log.e("indexstr>>>>",indexstr+"");
for (int j=0;j<16;j++){//无论是12还是16字体 横排都是两个字节 16位
position=position+1;
matrix_index+=1;
boolean[] indx = getstrbycolumn(matrix,matrix_index);//取一竖排
if (isArabic){
ArabicIndexs.add(position);
}
if (isSpace){
spaceIndexs.add(position);
}
if (isHindi){
HindiIndexs.add(position);
}
tem.add(position,indx);
indx =null;
}
// 连续的两个阿拉伯字符之间不需要插入空格
if ((!followstr.equals(""))&&ArabicUtils.isArbic(followstr)&&ArabicUtils.isArbic(indexstr)){
// 连续的两个印地文字符之间不需要插入空格
}else if ((!followstr.equals(""))&&ArabicUtils.isHindi(followstr)&&ArabicUtils.isHindi(indexstr)) {
}else {
Log.e("insert","1");
tem.add(position,empty_data);
position+=1;
}
}
// if (matrix[0].length>=16){//两个字符以上才需要增加
//
// for (int i=0;i<matrix[0].length;i++){
// boolean[] indx = getstrbycolumn(matrix,i);//取一竖排
// tem.add(indx);
//
// if (LangUtils.isChinese(subjectStr)){
// if ((i+1)%12==0){
// Log.e("添加空格>>>>","+1");
// tem.add(empty_data);
// }
// }else {
// if ((i+1)%8==0){
// Log.e("添加空格>>>>","+1");
// tem.add(empty_data);
// }
// }
// indx=null;
// }
boolean[][] temps1 = new boolean[matrix.length][tem.size()];//12*n
for (int i = 0;i<tem.size();i++){
boolean[] pos = tem.get(i);
for (int j=0;j<matrix.length;j++){
temps1[j][i] = pos[j];
}
}
matrix = temps1;
Log.e("matrix>>>",matrix[0].length+"");
}/*
private void insertEmptyData(){//无论12*8 还是16*8 矩阵 横排都是八位 可以在每隔八位插入 中文除外
//初始化空值数组
empty_data = new boolean[dots];
for (int i=0;i<dots;i++) {
empty_data[i] = false;
}
Log.e("empty_data>>>>",empty_data.length+"");
ArrayList<boolean[]> tem = new ArrayList<>();
int position = 0;//更改后的数组当前下标
int matrix_index=0;//更改前的数组当前下标
spaceIndexs = new ArrayList<>();
ArabicIndexs = new ArrayList<>();
for (int i=0;i<str.length();i++){//因为中文位12位或者16位 其他为8位 用字符判断是否是中文
String indexstr = str.substring(i, i + 1);
String followstr = "";
if (i<str.length()-1){
followstr = str.substring(i+1,i+2);
}
boolean isSpace = indexstr.equals(" ");
boolean isArabic = (!followstr.equals(""))&&ArabicUtils.isArbic(followstr)&&ArabicUtils.isArbic(indexstr);
Log.e("indexstr>>>>",indexstr+"");
// isReadBC = isReadBCs[i];
// ArrayList<boolean[]> chararrs = new ArrayList<>();
// if (dots==12){//如果是为12字体中文
// for (int j=0;j<12;j++){//取12位
// boolean[] indx = getstrbycolumn(matrix,matrix_index);//取一竖排
// tem.add(position,indx);
// position=position+1;
// matrix_index=matrix_index+1;
// indx =null;
// }
//
// }else {//如果是16字体中文
// for (int j=0;j<16;j++){//取16位
// boolean[] indx = getstrbycolumn(matrix,matrix_index);//取一竖排
// tem.add(position,indx);
// position=position+1;
// matrix_index=matrix_index+1;
// indx =null;
// }
// }
// if (isSpace){
// Log.e("字符>>>>","space");
// for (int j=0;j<8;j++){//取12位
// boolean[] indx = getstrbycolumn(matrix,matrix_index);//取一竖排
// tem.add(position,indx);
// position=position+1;
// matrix_index+=1;
// spaceIndexs.add(matrix_index);
// indx =null;
// }
// } else
if (LangUtils.isChinese(indexstr) || LangUtils.isJapanese(indexstr) || LangUtils.isKorean(indexstr) || ((int) indexstr.charAt(0) > 128)){//如果是中文
Log.e("字符>>>>","chinese");
if (dots==12){//如果是为12字体中文
for (int j=0;j<12;j++){//取12位
boolean[] indx = getstrbycolumn(matrix,matrix_index);//取一竖排
if (isArabic){
ArabicIndexs.add(position);
}
tem.add(position,indx);
position=position+1;
matrix_index+=1;
indx =null;
}
}else {//如果是16字体中文
for (int j=0;j<16;j++){//取16位
boolean[] indx = getstrbycolumn(matrix,matrix_index);//取一竖排
tem.add(position,indx);
position=position+1;
matrix_index+=1;
indx =null;
}
}
} else if (isReadBC){//特殊字符
// if (isSpechars(indexstr)){//如果是特殊字符 ❤形 ❤形在字库中是按照英文处理的 但实际上字模宽度比一般英文大 12字体为12位
//16字体为16位 所以要在英文处理中 单独判读字模宽
Log.e("字符>>>>","Spechars");
if (dots==12){
for (int j=0;j<12;j++){//取12位
boolean[] indx = getstrbycolumn(matrix,matrix_index);//取一竖排
tem.add(position,indx);
position=position+1;
matrix_index+=1;
indx =null;
}
}else {
for (int j=0;j<16;j++){//取16位
boolean[] indx = getstrbycolumn(matrix,matrix_index);//取一竖排
tem.add(position,indx);
position=position+1;
matrix_index+=1;
indx =null;
}
}
}else {
Log.e("字符>>>>","other");
for (int k=0;k<8;k++){//取8位
boolean[] indx = getstrbycolumn(matrix,matrix_index);//取一竖排
// Log.e("position>>>>",position+"");
tem.add(position,indx);
if (isSpace){
spaceIndexs.add(position);
}
position =position+1;
matrix_index+=1;
indx =null;
}
}
//连续的两个阿拉伯字符之间不需要插入空格
if ((!followstr.equals(""))&&ArabicUtils.isArbic(followstr)&&ArabicUtils.isArbic(indexstr)){
}else{
Log.e("insert","1");
tem.add(position,empty_data);
position+=1;
}
}
// if (matrix[0].length>=16){//两个字符以上才需要增加
//
// for (int i=0;i<matrix[0].length;i++){
// boolean[] indx = getstrbycolumn(matrix,i);//取一竖排
// tem.add(indx);
//
// if (LangUtils.isChinese(subjectStr)){
// if ((i+1)%12==0){
// Log.e("添加空格>>>>","+1");
// tem.add(empty_data);
// }
// }else {
// if ((i+1)%8==0){
// Log.e("添加空格>>>>","+1");
// tem.add(empty_data);
// }
// }
// indx=null;
// }
boolean[][] temps1 = new boolean[matrix.length][tem.size()];//12*n
for (int i = 0;i<tem.size();i++){
boolean[] pos = tem.get(i);
for (int j=0;j<matrix.length;j++){
temps1[j][i] = pos[j];
}
}
matrix = temps1;
}*/
private final String[] specstrsunicode={"\\u2764","\\u00a5","\\u20ac","\\ufe49","\\u2665","\\u2661"};
private boolean isSpechars(String str){
boolean result =false;
for (int i=0;i<specstrsunicode.length;i++){
if (gbEncoding(str).equals(specstrsunicode[i])){
result=true;
break;
}
}
return result;
}
/*
* 根据字符转unicode码
* */
private String gbEncoding(final String gbString) {
char[] utfBytes = gbString.toCharArray();
String unicodeBytes = "";
for (int byteIndex = 0; byteIndex < utfBytes.length; byteIndex++) {
String hexB = Integer.toHexString(utfBytes[byteIndex]);
if (hexB.length() <= 2) {
hexB = "00" + hexB;
}
unicodeBytes = unicodeBytes + "\\u" + hexB;
}
// System.out.println("unicodeBytes is: " + unicodeBytes);
return unicodeBytes;
}
/*
* 根据unicode转字符
* */
private String getStrFromUniCode(String unicode){
StringBuffer string = new StringBuffer();
String[] hex = unicode.split("\\\\u");
for (int i = 1; i < hex.length; i++) {
// 转换出每一个代码点
int data = Integer.parseInt(hex[i], 16);
// 追加成string
string.append((char) data);
}
return string.toString();
}
private boolean[] empty_data ;
private boolean isSpaceVaules(int index){
boolean result=false;
if (spaceIndexs!=null&&spaceIndexs.size()>0){
for (int i=0;i<spaceIndexs.size();i++){
if (spaceIndexs.get(i)==index){
result =true;
break;
}
}
}else {
return false;
}
return result;
}
private boolean isArabicVaules(int index){
boolean result=false;
if (ArabicIndexs!=null&&ArabicIndexs.size()>0){
for (int i=0;i<ArabicIndexs.size();i++){
if (ArabicIndexs.get(i)==index){
result =true;
break;
}
}
}else {
return false;
}
return result;
}
private boolean isHindiVaules(int index){
boolean result=false;
if (HindiIndexs!=null&&HindiIndexs.size()>0){
for (int i=0;i<HindiIndexs.size();i++){
if (HindiIndexs.get(i)==index){
result =true;
break;
}
}
}else {
return false;
}
return result;
}
/*
* 2017.12.25 添加
* 消除多余空格
* */
private void fillMatrixEmpty(){
//原则:判断boolean二维数组竖排是否出现连续为Flase的情况 如果是 便舍弃一个 否则添加到新的数组中
//
ArrayList<boolean[]> tem = new ArrayList<>();
int space_number=0;
for (int i = 0;i<matrix[0].length-1;i++){
boolean[] indx = getstrbycolumn(matrix,i);//取一竖排
boolean[] indy = getstrbycolumn(matrix,i+1);
if (i==matrix[0].length-1&&!Arrays.equals(empty_data,indy)){//最后一排加进去
// Log.e(i+">>>>","last_data");
tem.add(indy);
} else if (isSpaceVaules(i)&&isSpaceVaules(i+1)){//如果是空格的位置
space_number+=1;
// Log.e(i+">>>>","空格");
if (space_number<5){//空格位置过长 只取4个点作为空格
tem.add(indx);
}
if (space_number==16){
space_number=0;
}
}
else if (!isSpaceVaules(i)&&Arrays.equals(empty_data,indx)&&Arrays.equals(empty_data,indy)){//如果相邻两列都为空 不保存
// Log.e(i+">>>>","empty_data");
}
else if (isArabicVaules(i)&&!isSpaceVaules(i)&&Arrays.equals(empty_data,indx)){//阿拉伯文 清除所有空格
}else if (isHindiVaules(i)&&!isSpaceVaules(i)&&Arrays.equals(empty_data,indx)){//印地文 清除所有空格
}
else{
//否则保存
// Log.e(i+">>>>","data");
tem.add(indx);
}
indx = null;
indy = null;
}
boolean[][] temps1 = new boolean[matrix.length][tem.size()];//12*n
for (int i = 0;i<tem.size();i++){
boolean[] pos = tem.get(i);
for (int j=0;j<matrix.length;j++){
temps1[j][i] = pos[j];
}
}
spaceIndexs=null;
ArabicIndexs =null;
HindiIndexs =null;
matrix = temps1;
// Log.e("matrix>>>>",matrix[0].length+"");
// Log.e("tem>>>>",tem.size()+"");
// Log.e("temps1>>>>",temps1[0].length+"");
}
/**
* 取某一竖排值
* */
public boolean[] getstrbycolumn(boolean[][] strarray, int column){
int columnlength = strarray.length;
boolean[] result = new boolean[strarray.length];
for(int i=0;i<columnlength;i++) {
result[i] = strarray[i][column];
}
return result;
}
/**
* 将读取出来的字模数据 按byte转成二维数组
* 再转成boolean数组
* */
private void getbooleandata (byte[] data){
int s = 0;
matrix = new boolean[dots][str.length()*8*2];
byte[][] tem = new byte[dots][str.length()*2];
for (int i=0;i<str.length();i++){
for (int j=0;j<dots;j++){
tem[j][i*2] = data[s];
tem[j][i*2+1] = data[s+1];
s+=2;
}
}
for (int m = 0; m < dots; m++) {
for (int line = 0; line < tem[0].length; line++) {
byte tmp = tem[m][line];
for (int j2 = 0; j2 < 8; j2++) {
if (((tmp >> (7 - j2)) & 1) == 1) {
matrix[m][line * 8 + j2] = true;
} else {
matrix[m][line * 8 + j2] = false;
}
}
}
}
}
/***
*
* @param totalLinesByte 一行多少字节
*/
private void fillMatrix(int totalLinesByte) {
matrix = new boolean[dots][totalLinesByte * 8];
for (int i = 0; i < dots; i++) {
for (int line = 0; line < totalLinesByte; line++) {
byte tmp = dataResult[totalLinesByte * i + line];
for (int j2 = 0; j2 < 8; j2++) {
if (((tmp >> (7 - j2)) & 1) == 1) {
matrix[i][line * 8 + j2] = true;
} else {
matrix[i][line * 8 + j2] = false;
}
}
}
}
}
/**
*
* 将布尔型二维数组转化成一维十六进制数组 作为最终数据
*
*/
public byte[] getAdjustedData(boolean[][] datass){
List<Byte> results = new ArrayList<>();
Log.e("datass.length",datass.length+"");
Log.e("datass[0].length",datass[0].length+"");
realLEDWidget = datass[0].length;
for (int i=0;i<datass.length;i++){
//用一个最大的十六进制数 与二进制进行|运算 最低位参与运算 如果是0 最低位变成1 否则为0
//然后再将新的十六进制数 左移一位
byte bite = 0x00;
int position = 0;
int m = 0;//行尾补齐计数
for (int j=0 ;j<datass[0].length;j++){
byte boolea_bite = 0b0;
if (datass[i][j]){
boolea_bite=0b1;
}
bite= (byte) (( bite) <<1);//全部左移一位 最高位去掉 最低位0补齐
bite= (byte) (( bite|boolea_bite));//最低位(0)或上boolean数据 即将boolean数据插入到最低位
position+=1;
if (position==8){//放满了 添加到集合中
// Log.e("bite",(bite&0xff)+"");
Log.e("bite",(bite)+"");
// results.add((byte) (bite&0xff));
results.add((byte) (bite));
bite=0x00;
position=0;
}
if ((j+1==datass[0].length)&m==0) {//位图末尾 需要换行
if ((datass[0].length%8)==0){//如果是八的倍数就不需要做末尾补齐处理,
// 如果没有这个判断,当位图数量是八的倍数时,在每行后面会添加八位的空字节 2018/01/01
}else {
bite = (byte) (bite<<(8-position));
Log.e("bite_end>>>>"+m,bite+"");
m+=1;
results.add(bite);
// results.add((byte) (bite&0xff));
bite=0x00;
position=0;
}
}
m=0;
}
}
// short bite = 0x00;
// int position = 0;
// for (int j=0 ;j<datass[0].length;j++){
// short boolea_bite = 0x00;
//
// if (datass[i][j]){
// boolea_bite=0x01;
// }
// bite= (short) (( bite|boolea_bite) <<1);
// position+=1;
// if (position==15){//放满了 添加到集合中
// Log.e("bite",bite+"");
// results.add(bite);
// bite=0x00;
// position=0;
// }
// if (j+1==datass[0].length) {//位图末尾 需要换行
// bite = (short) (bite<<(15-position));
// Log.e("bite_end",bite+"");
// results.add(bite);
// bite=0x00;
// }
// }
// }
byte[] data =new byte[results.size()];
for (int k = 0;k<results.size();k++){
// data = intToBytes2(results.get(k));
// data[k] = 0x10;
// int s =0x00;
// s=results.get(k);
data[k] = (results.get(k));
// Helpful.catByte(data,0,intToBytes2(results.get(k)),data.length);
}
return data;
}
/**
* 将int数值转换为占四个字节的byte数组,本方法适用于(高位在前,低位在后)的顺序。 和bytesToInt2()配套使用
*/
public static byte[] intToBytes2(int value)
{
byte[] src = new byte[4];
src[0] = (byte) ((value>>24) & 0xFF);
src[1] = (byte) ((value>>16)& 0xFF);
src[2] = (byte) ((value>>8)&0xFF);
src[3] = (byte) (value & 0xFF);
return src;
}
public static byte[] int2BytesArray(int n) {
byte[] b = new byte[4];
for (int i = 0; i < 4; i++) {
b[i] = (byte) (n >> (24 - i * 8));
}
return b;
}
public byte[] getResultWordsByte(byte[] preByte) {
byte[] dataCmdResult = preByte;
//横向取模
byte[] result = new byte[dataCmdResult.length];
boolean currentStrIsEnglish = false;
int preIndex = 0;
boolean preStrIsEnglish = false;
int totalByteSize = 0;
for (int line = 0; line < dots; line++) {
int hasDealByte = 0;
realLEDWidget = 0;
lineTotalByte = 0;
totalByteSize = 0;
for (int index = 0; index < str.length(); index++) {
String subjectStr = str.substring(index, index + 1);
int bytewei = 0;
// bytewei = this.line;
if (LangUtils.isChinese(subjectStr) || LangUtils.isJapanese(subjectStr) || LangUtils.isKorean(subjectStr) || ((int) subjectStr.charAt(0) > 128)) {
bytewei = this.line;
currentStrIsEnglish = false;
} else {
bytewei = 8;
currentStrIsEnglish = true;
}
// index >0 总长度是8的倍数就不要位移
if (realLEDWidget % 8 != 0 && dots == 12) {
//需要进行位移
if (currentStrIsEnglish) {
byte preByte1 = result[preIndex - 1];
byte preByte2 = dataCmdResult[hasDealByte + 0 + line * (bytewei / 8)];
result[preIndex - 1] = (byte) (((preByte1 & 0xff)) | ((preByte2 & 0xff) >>> 4));
result[preIndex] = (byte) (dataCmdResult[hasDealByte + 0 + line * (bytewei / 8)] << 4);
preIndex++;
hasDealByte = hasDealByte + asciiwordByteByDots;
totalByteSize = totalByteSize + 12;
realLEDWidget = realLEDWidget + 8;
lineTotalByte = lineTotalByte + 1;
}
else {
for (int position = 0; position < 2; position++) {
//preIndex-1 是上一个字节
if (position == 0) {
byte preByte1 = result[preIndex - 1];
byte preByte2 = dataCmdResult[hasDealByte + 0 + line * (bytewei / 8)];
result[preIndex - 1] = (byte) (((preByte1 & 0xff)) | ((preByte2 & 0xff) >>> 4));
} else {
//上一个字节
byte preByte1 = dataCmdResult[hasDealByte + 0 + line * (bytewei / 8)];
byte preByte2 = dataCmdResult[hasDealByte + 1 + line * (bytewei / 8)];
result[preIndex] = (byte) (((preByte1 & 0xff) << 4) | ((preByte2 & 0xff) >>> 4));
preIndex++;
}
}
hasDealByte = hasDealByte + wordByteByDots;
totalByteSize = totalByteSize + 12;
realLEDWidget = realLEDWidget + 12;
lineTotalByte = lineTotalByte + 1;
}
} else {
//不需要进行位移
// bytewei = 16;
if (currentStrIsEnglish) {
bytewei = 8;
} else {
bytewei = 16;
}
for (int position = 0; position < (bytewei / 8); position++) {
result[preIndex] = dataCmdResult[hasDealByte + position + line * (bytewei / 8)];
preIndex++;
}
if (LangUtils.isChinese(subjectStr) || LangUtils.isJapanese(subjectStr) || LangUtils.isKorean(subjectStr)|| ((int) subjectStr.charAt(0) > 128)) {
hasDealByte = hasDealByte + wordByteByDots;
totalByteSize = totalByteSize + wordByteByDots;
realLEDWidget = realLEDWidget + 12;
lineTotalByte = lineTotalByte + 2;
} else {
hasDealByte = hasDealByte + asciiwordByteByDots;
totalByteSize = totalByteSize + asciiwordByteByDots;
realLEDWidget = realLEDWidget + 8;
lineTotalByte = lineTotalByte + 1;
}
}
preStrIsEnglish = currentStrIsEnglish;
}
}
result = Helpful.subByte(result, 0, totalByteSize);
return result;
}
/**
* @param str 单个字符
* @return 读取韩文字模信息
*/
protected byte[] readKoreanZiMo(String str) {
Log.e("readKoreanZiMo",str);
byte[] data = new byte[wordByteByDots];
try {
if (str.charAt(0) >= 0xAC00) {
dotMatrixFont = wordName("HZK", "K", dots, zlx);
AssetManager.AssetInputStream in = (AssetManager.AssetInputStream) context.getResources().getAssets().open(dotMatrixFont);
in.skip(((int) str.charAt(0) - 0xAC00) * wordByteByDots);
in.read(data, 0, wordByteByDots);
in.close();
} else {
dotMatrixFont = wordNameBC("HZK", "R", dots, zlx);
AssetManager.AssetInputStream in = (AssetManager.AssetInputStream) context.getResources().getAssets().open(dotMatrixFont);
in.skip(((int) str.charAt(0)) * wordByteByDots);
in.read(data, 0, wordByteByDots);
in.close();
}
} catch (Exception ex) {
}
return data;
}
/**
* @param str 单个字符
* @return 读取中文字模信息
* 12 点中文寻址 [(GHH-0xa1)*94+GLL-0xa1]*24
*/
protected byte[] readChineseZiMo(String str) {
Log.e("readChineseZiMo",str);
byte[] data = new byte[wordByteByDots];
try {
dotMatrixFont = wordName("HZK", "S", dots, zlx);
AssetManager.AssetInputStream in = (AssetManager.AssetInputStream) context.getResources().getAssets().open(dotMatrixFont);
in.skip((((str.getBytes("GB2312")[0] < 0 ? 256 + str.getBytes("GB2312")[0] : str.getBytes("GB2312")[0]) - 0xa1) * 94 + (str.getBytes("GB2312")[1] < 0 ? 256 + str.getBytes("GB2312")[1] : str.getBytes("GB2312")[1]) - 0xa1) * wordByteByDots);
in.read(data, 0, wordByteByDots);
in.close();
if (data.length == 0) {
dotMatrixFont = wordNameBC("HZK", "R", dots, zlx);
in = (AssetManager.AssetInputStream) context.getResources().getAssets().open(dotMatrixFont);
in.skip((((str.getBytes("GB2312")[0] < 0 ? 256 + str.getBytes("GB2312")[0] : str.getBytes("GB2312")[0]) - 0xa1) * 94 + (str.getBytes("GB2312")[1] < 0 ? 256 + str.getBytes("GB2312")[1] : str.getBytes("GB2312")[1]) - 0xa1) * wordByteByDots);
in.read(data, 0, wordByteByDots);
in.close();
}
} catch (Exception ex) {
}
return data;
}
/**
* @param str 单个字符
* @return 读取日文字模信息
* [(Jhh-0X80)*189+JLL-0X40]*24
*/
protected byte[] readJapaneseZiMo(String str) {
Log.e("readJapaneseZiMo",str);
byte[] data = new byte[wordByteByDots];
try {
dotMatrixFont = wordNameBC("HZK", "R", dots, zlx);
AssetManager.AssetInputStream in = (AssetManager.AssetInputStream) context.getResources().getAssets().open(dotMatrixFont);
in.skip(str.charAt(0)*wordByteByDots);
in.read(data, 0, wordByteByDots);
in.close();
} catch (Exception ex) {
}
return data;
}
/**
* @param str 单个字符
* @return 读取Ascii字模信息
*/
protected byte[] readAsciiZiMo(String str) {
Log.e("readAsciiZiMo",str);
byte[] data = null;
try {
// dotMatrixFont = wordName("AS", "C", dots, zlx);
dotMatrixFont = wordName("HZK", "LD1", dots, zlx);
// dotMatrixFont = wordNameBC("HZK", "LD1", dots, zlx);
//header + languge + type + wordSize + ".DZK"
data = new byte[asciiwordByteByDots];
Log.e("charAt",(int) str.charAt(0)+"");
if ((int) str.charAt(0) < 128) {
//英文字符
AssetManager.AssetInputStream in = (AssetManager.AssetInputStream) context.getResources().getAssets().open(dotMatrixFont);
in.skip((int) str.charAt(0) * asciiwordByteByDots);
in.read(data, 0, asciiwordByteByDots);
in.close();
}
} catch (Exception ex) {
}
return data;
}
protected byte[] readTSZiMo(String str) {
Log.e("readTSZiMo",str);
byte[] data = null;
try {
data = new byte[wordByteByDots];
dotMatrixFont = wordNameBC("HZK", "C", dots, zlx);
AssetManager.AssetInputStream in = (AssetManager.AssetInputStream) context.getResources().getAssets().open(dotMatrixFont);
in.skip(((int) str.charAt(0)) * wordByteByDots);
in.read(data, 0, wordByteByDots);
in.close();
} catch (Exception ex) {
Log.e("readTSZiMo","read fail");
}
return data;
}
public void setPix(int pix) {
if (pix == 12) {
dots = 12;
wordByteByDots = 24;
line = 16;
asciiwordByteByDots = 12;
}
if (pix == 16) {
dots = 16;
line = 16;
wordByteByDots = 32;
asciiwordByteByDots = 16;
}
}
protected byte[] readAllZiMo(String str) {
Log.e("readAllZiMo",str);
byte[] data = null;
try {
data = new byte[wordByteByDots];
dotMatrixFont = wordNameOveral(zlx,dots);
AssetManager.AssetInputStream in = (AssetManager.AssetInputStream) context.getResources().getAssets().open(dotMatrixFont);
in.skip(((int) str.charAt(0)) * wordByteByDots);
in.read(data, 0, wordByteByDots);
in.close();
} catch (Exception ex) {
}
return data;
}
private String wordName(String header, String languge, int wordSize, String wordType) {
isReadBC =false;
String type = "Z";
if (wordType.equals("正体") || wordType.equals("Normall")) {
type = "Z";
}
if (wordType.equals("斜体") || wordType.equals("Italic")) {
type = "L";
}
if (wordType.equals("粗体") || wordType.equals("Bold")) {
type = "C";
}
Log.e("wordName>>>",header + languge + type + wordSize + ".DZK");
return header + languge + type + wordSize + ".DZK";
}
/***
* 补充
* 上面的字库没有读到,用这个里面的继续读取。
* @param wordSize
* @param wordType
* @return
*/
private String wordNameOveral(String wordType,int wordSize){
String type = "Z";
if (wordType.equals("正体") || wordType.equals("Normall")) {
type = wordSize + "" + wordSize + "";
}
if (wordType.equals("斜体") || wordType.equals("Italic")) {
type = wordSize + "" + wordSize + "L";
}
if (wordType.equals("粗体") || wordType.equals("Bold")) {
type = wordSize + "" + wordSize + "C";
}
return type + ".DZK";
}
private String wordNameBC(String header, String languge, int wordSize, String wordType) {
isReadBC=true;
String type = "Z";
if (wordType.equals("正体") || wordType.equals("Normall")) {
type = wordSize + "" + wordSize + "";
}
if (wordType.equals("斜体") || wordType.equals("Italic")) {
type = wordSize+ "" + wordSize + "L";
}
if (wordType.equals("粗体") || wordType.equals("Bold")) {
type = wordSize+ "" + wordSize + "C";
}
Log.e("wordNameBC>>>",type + ".DZK");
return type + ".DZK";
}
}

















 1万+
1万+






 到【灌水乐园】发言
到【灌水乐园】发言







