







 本文探讨了数据中的相关性和因果性关系,通过AB测试验证发券效果,介绍了Uplift模型在智能营销中的重要性,特别是T-Learner、S-Learner和X-Learner的不同方法及其优缺点。着重强调了在营销决策中使用Uplift模型来预测用户对营销活动的响应和制定个性化策略的价值。
本文探讨了数据中的相关性和因果性关系,通过AB测试验证发券效果,介绍了Uplift模型在智能营销中的重要性,特别是T-Learner、S-Learner和X-Learner的不同方法及其优缺点。着重强调了在营销决策中使用Uplift模型来预测用户对营销活动的响应和制定个性化策略的价值。
数分
数据的欺骗性,发券是否是此间唯一变化的量,相关性!=因果性
发券后购买率上升 但是对应营收下降 得评估转换后人群是否持久
及撤销发券后购买率是否受更多影响
AB tset
AB测试是一种实验设计方法,用于比较两个或多个变体(A和B)的性能,以确定哪个变体在给定的指标上表现更好。
在AB测试中,被测试的两个或多个变体被随机分配给不同的用户或用户群体。用户将以不同的方式暴露于不同的变体,例如网页设计、产品功能、广告展示等。通过收集和分析用户的行为数据,可以评估每个变体的效果,并最终确定哪个变体在给定的目标指标上表现更佳。
AB测试通常包括以下步骤:
- 目标设定:明确定义要测试的指标和假设。
- 变体设计:设计和创建不同的变体(如A、B等),以及它们的实现方式。
- 随机分配:将用户随机分配到不同的变体中,以减少偏差。
- 数据收集:收集用户在不同变体下的行为数据(如点击率、转化率等)。
- 数据分析:比较不同变体的数据,并计算统计显著性以判断哪个变体更好。
- 结论和决策:根据数据分析结果,确定哪个变体在给定指标上表现更佳,并作出相应的决策。
分布检验
AB测试是一种常用的优化和决策工具,可以用于改进网站、产品、营销策略等方面。通过在真实环境中进行实验,可以获得数据支持的决策,从而提升业务绩效和用户体验。
在进行AB测试之前,进行数据分布检验是一个重要的步骤。数据分布检验旨在确定AB测试中所用到的两组数据是否来自同一分布。
常见的数据分布检验方法包括:
Shapiro-Wilk检验:用于检验数据是否服从正态分布。该检验基于样本数据与正态分布的拟合程度。
Anderson-Darling检验:同样用于检验数据是否服从正态分布。该检验考虑了拟合程度和尾部的情况。
Kolmogorov-Smirnov检验:可以用于检验两个样本数据是否来自同一分布。
Chi-square(卡方)检验:用于检验分类数据和观察数据之间的拟合程度。
什么是Uplift model?

这个模型建模的难点在于我们获取到的训练数据是不完整的,对于个体来说,我们不可能同时观测到在有干预和没有干预两种情况下的表现,也就是因果推断中经常提到的反事实的问题。
Uplift建模对样本的要求是比较高的,需要服从CIA ( Conditional Independence Assumption ) 条件独立假设,要求X与T是相互独立的。
什么样的样本有这样的特征,又如何获取呢?最简单的方式就是随机化实验A/B Test,因为通过A/B Test拆分流量得到的这两组样本在特征的分布上面是一致的,也就是X和T是相互独立的。因此随机化实验是Uplift Model建模过程中非常重要的基础设施,可以为Uplift Model提供无偏的样本。
uplift的意义

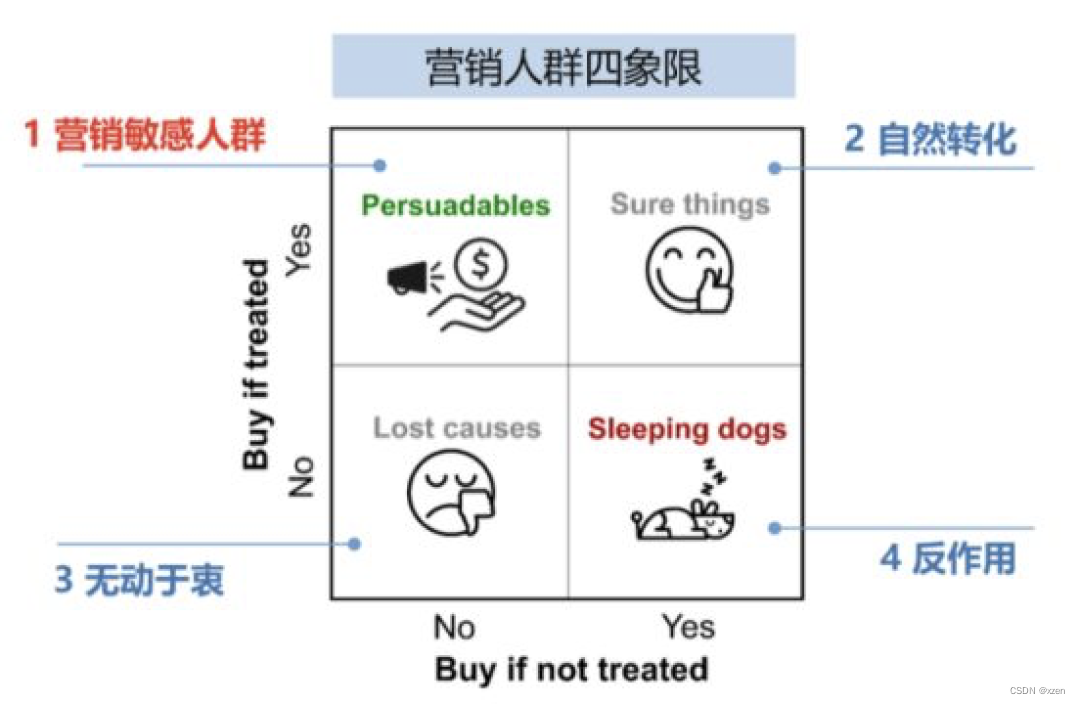
Response Model的目标是估计用户看过广告之后转化的概率,这本身是一个相关性,但这个相关性会导致我们没有办法区分出自然转化人群;
Uplift Model是估计用户因为广告而购买的概率,这是一个因果推断的问题,帮助我们锁定对营销敏感的人群。所以Uplift Model是整个智能营销中非常关键的技术,预知每个用户的营销敏感程度,从而帮助我们制定营销策略,促成整个营销的效用最大化。
uplift model分类
Two-Model:建立两个对于outcome的预测模型,一个用实验组数据、一个用对照组数据。
One-Model:Class Variable Transformation:响应结果为二元变量时可用。
对uplift直接建模:对现有ML模型(树、RF、SVM)的改造
T-Learner,其中T代表two的意思,也即用两个模型。它的主要思想是对干预数据和无干预数据分别进行建模,预估时数据进入两个模型,用两个模型的预测结果做差值,来得到预估的增量。该方法的优点是原理比较简单直观,可以快速实现。但缺点是,因为两个模型的精度不一定非常高,所以两个模型的误差会有叠加,并且因为有差分的操作,这是间接计算的增量。
S-Learner,其中S代表single,也即用一个模型。它的主要思想是把干预作为特征输入模型,在预测时,同样是用有干预的结果和无干预的结果做差,得到预估增量。和Response模型比较像,就相当于特征里面有“是否干预”这样的特征,它的优点是,相比T-Learner减少了误差的累积,但缺点同样是间接的计算增量。
X-Learner,它的思想是先分别对有干预、无干预数据进行建模,再用两个模型来交叉预测,得到干预数据和无干预数据分别的反事实结果。因为这是训练数据,它是有真实label的,再用真实label和刚才预测的反事实结果做差,得到增量;把增量再作为label,再针对增量进行建模。同时对有无干预进行建模,得到干预的倾向分,并在预测增量的时候引入倾向分权重。方法的优点在于,可以对前面我们预测出来的增量建模时加入先验知识进行优化,来提高预测的准确性,另外还引入了倾向分权重来减少预测的误差。但它的缺点也是多模型的误差,可能会有累积,并且归根结底也是间接得到预测增量。
tree uplift
















 368
368











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









