






tensorrtx搭建Zero-DCE部署
Zero-DCE介绍
paper作者Zero-DCE主页:https://li-chongyi.github.io/Proj_Zero-DCE.html
Zero-DCE使用深度学习方法参考了深度曲线估计,通过一个轻量的深度卷积神经网络设计了一个光线增强曲线,对微光图像进行增强,可以将不同的灯光条件下采集的光照不均匀和弱光的图像进行调整。
 对输入图像的每个信道分别做迭代操作,每次迭代操作的输出和输入图像map层再次结合作为下层输入。
对输入图像的每个信道分别做迭代操作,每次迭代操作的输出和输入图像map层再次结合作为下层输入。
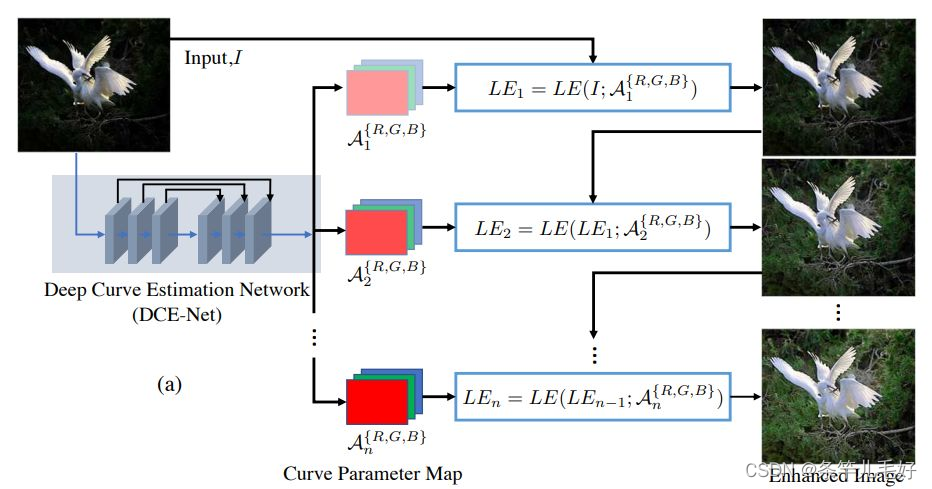
tensortx改写网络结构
pytorch实现:https://github.com/Li-Chongyi/Zero-DCE
class enhance_net_nopool(nn.Module):
def __init__(self):
super(enhance_net_nopool, self).__init__()
self.relu = nn.ReLU(inplace=True)
number_f = 32
self.e_conv1 = nn.Conv2d(3,number_f,3,1,1,bias=True)
self.e_conv2 = nn.Conv2d(number_f,number_f,3,1,1,bias=True)
self.e_conv3 = nn.Conv2d(number_f,number_f,3,1,1,bias=True)
self.e_conv4 = nn.Conv2d(number_f,number_f,3,1,1,bias=True)
self.e_conv5 = nn.Conv2d(number_f*2,number_f,3,1,1,bias=True)
self.e_conv6 = nn.Conv2d(number_f*2,number_f,3,1,1,bias=True)
self.e_conv7 = nn.Conv2d(number_f*2,24,3,1,1,bias=True)
self.maxpool = nn.MaxPool2d(2, stride=2, return_indices=False, ceil_mode=False)
self.upsample = nn.UpsamplingBilinear2d(scale_factor=2)
def forward(self, x):
x1 = self.relu(self.e_conv1(x))
x2 = self.relu(self.e_conv2(x1))
x3 = self.relu(self.e_conv3(x2))
x4 = self.relu(self.e_conv4(x3))
x5 = self.relu(self.e_conv5(torch.cat([x3,x4],1)))
x6 = self.relu(self.e_conv6(torch.cat([x2,x5],1)))
x_r = F.tanh(self.e_conv7(torch.cat([x1,x6],1)))
r1,r2,r3,r4,r5,r6,r7,r8 = torch.split(x_r, 3, dim=1)
x = x + r1*(torch.pow(x,2)-x)
x = x + r2*(torch.pow(x,2)-x)
x = x + r3*(torch.pow(x,2)-x)
enhance_image_1 = x + r4*(torch.pow(x,2)-x)
x = enhance_image_1 + r5*(torch.pow(enhance_image_1,2)-enhance_image_1)
x = x + r6*(torch.pow(x,2)-x)
x = x + r7*(torch.pow(x,2)-x)
enhance_image = x + r8*(torch.pow(x,2)-x)
r = torch.cat([r1,r2,r3,r4,r5,r6,r7,r8],1)
return enhance_image_1,enhance_image,r
Zero-DCE是一个轻量网络,使用到的算子也不复杂,算子都为tensorrt已经支持的操作,我们可以直接调用tensorrt的操作来部署,不需要重新自定义算子。
auto pow = network->addElementWise(*data, *data, ElementWiseOperation::kPROD);
auto sub = network->addElementWise(*pow->getOutput(0), *data, ElementWiseOperation::kSUB);
//e_conv1
IConvolutionLayer* conv1 = network->addConvolutionNd(*data, 32, DimsHW{ 3, 3 }, weightMap["e_conv1.weight"], weightMap["e_conv1.bias"]);
assert(conv1);
conv1->setPaddingNd(DimsHW{ 1, 1 });
conv1->setStrideNd(DimsHW{ 1,1 });
IActivationLayer* relu1 = network->addActivation(*conv1->getOutput(0), ActivationType::kRELU);
assert(relu1);
//e_conv2
IConvolutionLayer* conv2 = network->addConvolutionNd(*relu1->getOutput(0), 32, DimsHW{ 3, 3 }, weightMap["e_conv2.weight"], weightMap["e_conv2.bias"]);
conv2->setPaddingNd(DimsHW{ 1, 1 });
conv2->setStrideNd(DimsHW{ 1,1 });
IActivationLayer* relu2 = network->addActivation(*conv2->getOutput(0), ActivationType::kRELU);
//e_conv3
IConvolutionLayer* conv3 = network->addConvolutionNd(*relu2->getOutput(0), 32, DimsHW{ 3, 3 }, weightMap["e_conv3.weight"], weightMap["e_conv3.bias"]);
conv3->setPaddingNd(DimsHW{ 1, 1 });
conv3->setStrideNd(DimsHW{ 1,1 });
IActivationLayer* relu3 = network->addActivation(*conv3->getOutput(0), ActivationType::kRELU);
//e_conv4
IConvolutionLayer* conv4 = network->addConvolutionNd(*relu3->getOutput(0), 32, DimsHW{ 3, 3 }, weightMap["e_conv4.weight"], weightMap["e_conv4.bias"]);
conv4->setPaddingNd(DimsHW{ 1, 1 });
conv4->setStrideNd(DimsHW{ 1,1 });
IActivationLayer* relu4 = network->addActivation(*conv4->getOutput(0), ActivationType::kRELU);
//concat relu3 and relu4
ITensor* inputTensors34[] = { relu3->getOutput(0), relu4->getOutput(0) };
auto cat34 = network->addConcatenation(inputTensors34, 2);
//e_conv5
IConvolutionLayer* conv5 = network->addConvolutionNd(*cat34->getOutput(0), 32, DimsHW{ 3, 3 }, weightMap["e_conv5.weight"], weightMap["e_conv5.bias"]);
conv5->setPaddingNd(DimsHW{ 1, 1 });
conv5->setStrideNd(DimsHW{ 1,1 });
IActivationLayer* relu5 = network->addActivation(*conv5->getOutput(0), ActivationType::kRELU);
//concat relu2 and relu5
ITensor* inputTensors25[] = { relu2->getOutput(0), relu5->getOutput(0) };
auto cat25 = network->addConcatenation(inputTensors25, 2);
//e_conv6
IConvolutionLayer* conv6 = network->addConvolutionNd(*cat25->getOutput(0), 32, DimsHW{ 3, 3 }, weightMap["e_conv6.weight"], weightMap["e_conv6.bias"]);
conv6->setPaddingNd(DimsHW{ 1, 1 });
conv6->setStrideNd(DimsHW{ 1,1 });
IActivationLayer* relu6 = network->addActivation(*conv6->getOutput(0), ActivationType::kRELU);
//concat relu1 and relu6
ITensor* inputTensors16[] = { relu1->getOutput(0), relu6->getOutput(0) };
auto cat16 = network->addConcatenation(inputTensors16, 2);
//e_conv7
IConvolutionLayer* conv7 = network->addConvolutionNd(*cat16->getOutput(0), 24, DimsHW{ 3, 3 }, weightMap["e_conv7.weight"], weightMap["e_conv7.bias"]);
conv7->setPaddingNd(DimsHW{ 1, 1 });
conv7->setStrideNd(DimsHW{ 1,1 });
IActivationLayer* relu7 = network->addActivation(*conv7->getOutput(0), ActivationType::kTANH);
//addSlice
Dims d = relu7->getOutput(0)->getDimensions();
ISliceLayer* slice0 = network->addSlice(*relu7->getOutput(0), Dims3{ 0,0,0 }, Dims3{ d.d[0] / 8,d.d[1],d.d[2] }, Dims3{ 1,1,1 });
ISliceLayer* slice1 = network->addSlice(*relu7->getOutput(0), Dims3{ 1,0,0 }, Dims3{ d.d[0] / 8,d.d[1],d.d[2] }, Dims3{ 1,1,1 });
ISliceLayer* slice2 = network->addSlice(*relu7->getOutput(0), Dims3{ 2,0,0 }, Dims3{ d.d[0] / 8,d.d[1],d.d[2] }, Dims3{ 1,1,1 });
ISliceLayer* slice3 = network->addSlice(*relu7->getOutput(0), Dims3{ 3,0,0 }, Dims3{ d.d[0] / 8,d.d[1],d.d[2] }, Dims3{ 1,1,1 });
ISliceLayer* slice4 = network->addSlice(*relu7->getOutput(0), Dims3{ 4,0,0 }, Dims3{ d.d[0] / 8,d.d[1],d.d[2] }, Dims3{ 1,1,1 });
ISliceLayer* slice5 = network->addSlice(*relu7->getOutput(0), Dims3{ 5,0,0 }, Dims3{ d.d[0] / 8,d.d[1],d.d[2] }, Dims3{ 1,1,1 });
ISliceLayer* slice6 = network->addSlice(*relu7->getOutput(0), Dims3{ 6,0,0 }, Dims3{ d.d[0] / 8,d.d[1],d.d[2] }, Dims3{ 1,1,1 });
ISliceLayer* slice7 = network->addSlice(*relu7->getOutput(0), Dims3{ 7,0,0 }, Dims3{ d.d[0] / 8,d.d[1],d.d[2] }, Dims3{ 1,1,1 });
//split
auto mul = network->addElementWise(*slice0->getOutput(0), *sub->getOutput(0), ElementWiseOperation::kPROD);
auto add = network->addElementWise(*data, *mul->getOutput(0), ElementWiseOperation::kSUM);
pow = network->addElementWise(*add->getOutput(0), *add->getOutput(0), ElementWiseOperation::kPROD);
sub = network->addElementWise(*pow->getOutput(0), *add->getOutput(0), ElementWiseOperation::kSUB);
mul = network->addElementWise(*slice1->getOutput(0), *sub->getOutput(0), ElementWiseOperation::kPROD);
add = network->addElementWise(*add->getOutput(0), *mul->getOutput(0), ElementWiseOperation::kSUM);
pow = pow = network->addElementWise(*add->getOutput(0), *add->getOutput(0), ElementWiseOperation::kPROD);
sub = network->addElementWise(*pow->getOutput(0), *add->getOutput(0), ElementWiseOperation::kSUB);
mul = network->addElementWise(*slice2->getOutput(0), *sub->getOutput(0), ElementWiseOperation::kPROD);
add = network->addElementWise(*add->getOutput(0), *mul->getOutput(0), ElementWiseOperation::kSUM);
pow = network->addElementWise(*add->getOutput(0), *add->getOutput(0), ElementWiseOperation::kPROD);
sub = network->addElementWise(*pow->getOutput(0), *add->getOutput(0), ElementWiseOperation::kSUB);
mul = network->addElementWise(*slice3->getOutput(0), *sub->getOutput(0), ElementWiseOperation::kPROD);
add = network->addElementWise(*add->getOutput(0), *mul->getOutput(0), ElementWiseOperation::kSUM);
pow = network->addElementWise(*add->getOutput(0), *add->getOutput(0), ElementWiseOperation::kPROD);
sub = network->addElementWise(*pow->getOutput(0), *add->getOutput(0), ElementWiseOperation::kSUB);
mul = network->addElementWise(*slice4->getOutput(0), *sub->getOutput(0), ElementWiseOperation::kPROD);
add = network->addElementWise(*add->getOutput(0), *mul->getOutput(0), ElementWiseOperation::kSUM);
pow = network->addElementWise(*add->getOutput(0), *add->getOutput(0), ElementWiseOperation::kPROD);
sub = network->addElementWise(*pow->getOutput(0), *add->getOutput(0), ElementWiseOperation::kSUB);
mul = network->addElementWise(*slice5->getOutput(0), *sub->getOutput(0), ElementWiseOperation::kPROD);
add = network->addElementWise(*add->getOutput(0), *mul->getOutput(0), ElementWiseOperation::kSUM);
pow = network->addElementWise(*add->getOutput(0), *add->getOutput(0), ElementWiseOperation::kPROD);
sub = network->addElementWise(*pow->getOutput(0), *add->getOutput(0), ElementWiseOperation::kSUB);
mul = network->addElementWise(*slice6->getOutput(0), *sub->getOutput(0), ElementWiseOperation::kPROD);
add = network->addElementWise(*add->getOutput(0), *mul->getOutput(0), ElementWiseOperation::kSUM);
pow = network->addElementWise(*add->getOutput(0), *add->getOutput(0), ElementWiseOperation::kPROD);
sub = network->addElementWise(*pow->getOutput(0), *add->getOutput(0), ElementWiseOperation::kSUB);
mul = network->addElementWise(*slice7->getOutput(0), *sub->getOutput(0), ElementWiseOperation::kPROD);
add = network->addElementWise(*add->getOutput(0), *mul->getOutput(0), ElementWiseOperation::kSUM);
add->getOutput(0)->setName(OUTPUT_BLOB_NAME);
Zero-DCE使用的tensorrt算子:
| tensorrt | pytorch |
|---|---|
| addElementWise(ElementWiseOperation::kSUM) | + |
| addElementWise(ElementWiseOperation::kSUB) | - |
| addElementWise(ElementWiseOperation::kPROD) | torch.pow |
| addConvolutionNd | Conv2d |
| addActivation(ActivationType::kRELU) | ReLU |
| addActivation(ActivationType::kTANH) | tanh |
| addConcatenation | torch.cat |
| addSlice | split |
部署Zero-DCE
tensorrtx部署步骤参考:https://github.com/wang-xinyu/tensorrtx
将Zero-DCE模型转换为wts权重文件
python gen_wts.py -w zero_dce.pt -o zero_dec.wts
gen_wts.py
import sys
import argparse
import os
import struct
import torch
from utils.torch_utils import select_device
def parse_args():
parser = argparse.ArgumentParser(description='Convert .pt file to .wts')
parser.add_argument('-w', '--weights', required=True, help='Input weights (.pt) file path (required)')
parser.add_argument('-o', '--output', help='Output (.wts) file path (optional)')
args = parser.parse_args()
if not os.path.isfile(args.weights):
raise SystemExit('Invalid input file')
if not args.output:
args.output = os.path.splitext(args.weights)[0] + '.wts'
elif os.path.isdir(args.output):
args.output = os.path.join(
args.output,
os.path.splitext(os.path.basename(args.weights))[0] + '.wts')
return args.weights, args.output
pt_file, wts_file = parse_args()
# Initialize
device = select_device('cpu')
# Load model
model = torch.load(pt_file, map_location=device)['model'].float() # load to FP32
# update anchor_grid info
anchor_grid = model.model[-1].anchors * model.model[-1].stride[...,None,None]
# model.model[-1].anchor_grid = anchor_grid
delattr(model.model[-1], 'anchor_grid') # model.model[-1] is detect layer
model.model[-1].register_buffer("anchor_grid",anchor_grid) #The parameters are saved in the OrderDict through the "register_buffer" method, and then saved to the weight.
model.to(device).eval()
with open(wts_file, 'w') as f:
f.write('{}\n'.format(len(model.state_dict().keys())))
for k, v in model.state_dict().items():
vr = v.reshape(-1).cpu().numpy()
f.write('{} {} '.format(k, len(vr)))
for vv in vr:
f.write(' ')
f.write(struct.pack('>f' ,float(vv)).hex())
f.write('\n')
读取zero_dce.wts中权重信息,写入改写时weightMap
std::map<std::string, Weights> loadWeights(const std::string file) {
std::cout << "Loading weights: " << file << std::endl;
std::map<std::string, Weights> weightMap;
// Open weights file
std::ifstream input(file);
assert(input.is_open() && "Unable to load weight file. please check if the .wts file path is right!!!!!!");
// Read number of weight blobs
int32_t count;
input >> count;
assert(count > 0 && "Invalid weight map file.");
while (count--)
{
Weights wt{ DataType::kFLOAT, nullptr, 0 };
uint32_t size;
// Read name and type of blob
std::string name;
input >> name >> std::dec >> size;
wt.type = DataType::kFLOAT;
// Load blob
uint32_t* val = reinterpret_cast<uint32_t*>(malloc(sizeof(val) * size));
for (uint32_t x = 0, y = size; x < y; ++x)
{
input >> std::hex >> val[x];
}
wt.values = val;
wt.count = size;
weightMap[name] = wt;
}
return weightMap;
}
其余tensorrt初始化部分与tensorrtx其余项目类似不再赘述了。
之前部署yolov4时实现scatterNd算子花了不小的功夫(结果实现后,tensorrt22.01开始支持scatterplugin…),只要算子tensorrt已经提供支持,使用tensorrt部署还是很方便的,切记根据输入和输出大小修改开辟的空间(踩过坑…


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









