






点击下方卡片,关注“小白玩转Python”公众号
作为一个健身爱好者,我一直对探索改善我的锻炼方式很感兴趣。我一直对使用计算机视觉和机器学习来分析和纠正锻炼过程中的姿势着迷。在这篇文章中,我将分享我构建一个使用姿态估计算法的简单健身房训练辅助应用的经历。
问题陈述
当我开始在家锻炼时,我意识到在没有私人教练或教练的情况下保持正确的姿势是很具挑战性的。在我的家庭健身房里放置镜子有所帮助,但还不够。我想找到一种方法来分析我的动作并得到关于我姿势的反馈。作为一个对指标和数字相当着迷的人,我渴望找到一种方法来量化我的进步,并跟踪我随时间的改进。我知道这可能不会完美地转化为像训练这样的实时活动,但我想有一些具体的东西来让我思考。
高层计划
我的目标是构建一个应用,它可以分析我进行锻炼的视频并提供关于我姿势的反馈。这是我方法的高层次概述:
使用关键点检测模型分析锻炼视频
将我的动作与专业人士的动作进行比较
想出某种度量标准,告诉我是否正确地进行了锻炼。它还应该突出改进的领域。
要求
当我开始探索潜在的解决方案时,我心中有几个关键要求。我希望找到一个易于实现的解决方案。我还希望它运行得快,最好是在我的MacBook Pro M1上,这样我就可以在不花费大量金钱购买高端GPU的情况下快速地进行迭代和尝试。我的目标是找到一个解决方案,让我可以在不被技术细节或昂贵的硬件困扰的情况下进行实验和完善我的方法。考虑到这些要求,我开始探索姿态估计算法和计算机视觉的世界。
姿态估计入门
姿态估计是研究领域的一个重要分支,它在动作识别、活动跟踪、增强现实、动画、游戏等领域都有应用。姿态估计的目标是在图像或视频中检测人体部位(如关节和四肢)的位置和方向。

姿态估计有两种主要方法:单人和多人。单人姿态估计在图像中找到一个人的姿势。它知道人在哪里以及要寻找多少关键点,这使得它成为一个回归问题。多人姿态估计则不同。它试图解决一个更难的问题,即图像中人的数目和位置是未知的。
单人姿态估计可以进一步分为两个框架:直接基于回归的和基于热图的。直接基于回归的框架从特征图预测关键点。基于热图的框架在图像中生成所有关键点的热图,然后使用额外的方法构建最终的人体骨架。
找到合适的关键点检测模型
当我沉浸在姿态估计的世界中时,我对众多可用的关键点检测模型并不感到惊讶。一些目前最好的模型,如OmniPose,拥有令人印象深刻的准确性。同样引起我注意的是OpenMMLab的姿态估计工具箱。它为与姿态估计相关的一切提供了一个全面而强大的框架,包括用于比较不同模型的基准。
我正在寻找一个简单且轻量级的解决方案来开始,所以我决定使用谷歌的MoveNet。MoveNet是一个紧凑且高效的姿态估计模型,非常适合移动设备和嵌入式设备。MoveNet只有大约400万个参数,而OmniPose有大约6800万个(或Lite版本中的约2000万个)。它的小尺寸和简单性使其成为我项目的理想选择,允许我快速实验和原型设计,而不需要大量的计算资源。虽然它可能无法提供一些更高级模型的准确性水平,但它是我项目的一个很好的起点。
MoveNet
但MoveNet是如何工作的呢?简而言之,MoveNet使用热图来准确定位人体关键点。它是一个自下而上的估计模型,这意味着它首先检测一个人的人体关节,然后将这些关节组装成姿势。MoveNet架构由两个主要组件组成:
特征提取器:一个带有附加特征金字塔网络的MobileNetV2。MobileNetV2是一个轻量级卷积神经网络,非常适合移动设备和嵌入式设备。特征金字塔网络允许MoveNet在多个尺度上捕获特征,这对于检测不同距离处的关键点很重要。
预测器头部:一组预测器头部附加在特征提取器上。这些预测器头部负责预测:
实例(人)的几何中心
人的全套关键点
所有关键点的位置
每个关键点从每个输出特征图像素到精确亚像素位置的局部偏移量

MoveNet在TensorFlow Hub上可用,并带有大量教程、文档和配套代码,使我的起步尽可能顺利。但真正让我印象深刻的是,MoveNet甚至可以在浏览器中运行,在包括智能手机在内的大多数现代设备上实现30+ FPS。这使其成为健身、健康和保健应用的理想选择,这些应用需要实时反馈和低延迟。
提取关键点
MoveNet检测全身17个关键点,从鼻子到脚踝。模型输出一个17x3的张量,其中每一行代表关键点的归一化X和Y坐标以及置信度分数。

我对我的录音进行了定性分析,对关键点检测的质量感到满意。模型能够准确地检测到我身体上的关键点,然而我的录音有不错的照明和清晰的角度。模型提供的置信度分数也让我很好地了解了检测的可靠性,允许我过滤掉任何检测置信度低的关键点。
从帧到序列——对齐录音
虽然从单独的帧中提取关键点是一个关键步骤,但对于现实世界的应用来说还不够。我们必须比单独的帧看得更广,并考虑到录音可能不会完全对齐。在这种情况下,逐帧比较关键点会产生错误的结果。如果一个录音比另一个录音早几分之一秒开始,那么两个录音的关键点就不会匹配,即使动作是相同的。要使分数真正有用,我必须对齐每个录音的帧。
为了实现这一点,我大部分工作是手动在视频编辑软件中完成的。我修剪和调整录音以确保它们是同步的。为了进一步细化对齐,我使用了动态时间规整(DTW)。这是一种允许比较可能长度或时间不同的序列的技术。DTW帮助微调对齐,确保每个录音的关键点尽可能准确地匹配。
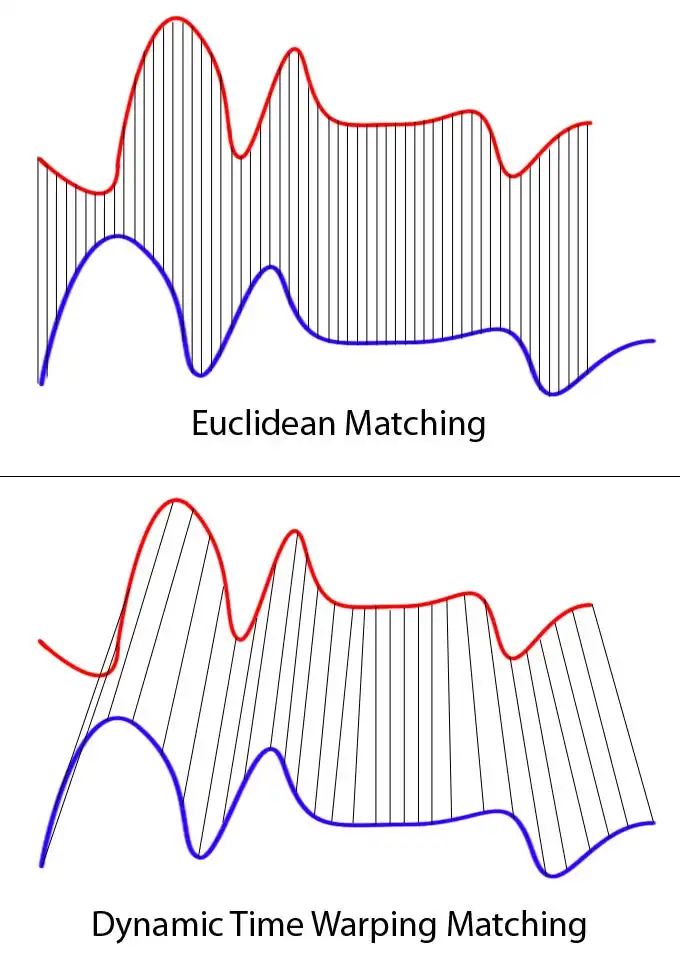
手动对齐与DTW细化适用于我的简单用例。这是劳动密集型的,因此不是现实世界应用的可扩展解决方案。对于这样的应用,必须自动化对齐录音的过程。这是另一个挑战,也是一个完全独立的文章的主题。自动化对齐需要开发算法,即使在噪声、变异性和其他现实世界复杂性存在的情况下,也能准确同步录音。

比较动作
现在我已经对齐了序列,我需要将我的动作与专业人士的动作进行比较。为此,我使用了余弦相似度,这是姿态估计问题空间中广泛使用的度量。
余弦相似度是衡量两个向量之间相似度的方法,它计算它们之间角度的余弦值。在姿态估计的背景下,它通常用于比较两组关键点(例如,身体关节或面部标志)的相似性。余弦相似度度量通常用于比较姿势,因为它对尺度和旋转的变化很鲁棒。
这个简单度量也有许多变体,我尝试了一些来看看它们的性能如何。结果和想法如下。
我录了两次自己——第一次尽可能正确地做锻炼(下面GIF的左边)。第二次我试图做得不正确(下面GIF的右边)——注意我在运动的第一阶段背部过于前倾。专业人士做锻炼在中间(参考)。

左边:我正确地做锻炼,中间:专业人士,右边:我做得不正确的锻炼
简单的余弦相似度
我能想到的最简单的度量是一次性地看整个动作。我简单地将所有关键点连接成一个形状为[num_frames * 17(关键点数)* 2(坐标)]的向量,并计算我和专业人士之间的余弦相似度。结果是:
cos_sim(正确动作,专业人士) = 0.8409
cos_sim(不正确动作,专业人士) = 0.8255
显然,第二个动作与参考动作的相似度较低,但差异的大小(0.0154)并不大。
逐帧和平均
我的第二种方法是利用这个事实,即帧是对齐的,计算对应帧(在运动的相应阶段)的关键点的余弦相似度并平均它们。
 左边:我正确地做锻炼,中间:专业人士,右边:我做得不正确的锻炼
左边:我正确地做锻炼,中间:专业人士,右边:我做得不正确的锻炼

逐帧余弦相似度
从上面的图表中,我可以得出结论,右边的动作与参考动作的相似度较低(因此更差)。右边的分数一直下降到0.79,并且(几乎)总是低于左边的分数。平均分数与第一种方法几乎相同:
mean cos_sim(正确动作,专业人士) = 0.8411
mean cos_sim(不正确动作,专业人士) = 0.8256
median cos_sim(正确动作,专业人士) = 0.8399
median cos_sim(不正确动作,专业人士) = 0.8257
加权相似度
我还没有利用MoveNet返回的第三个分数——关键点置信度分数。
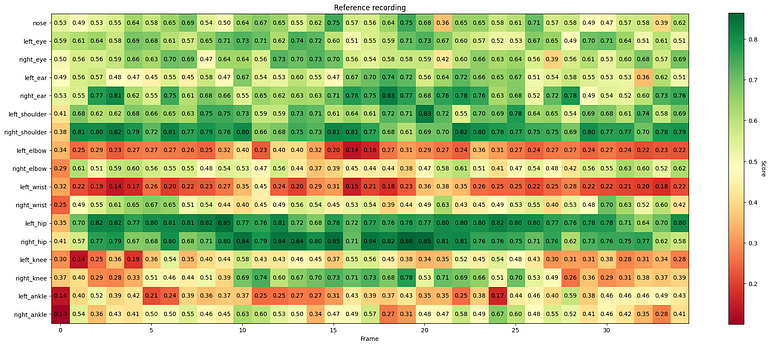
参考录音中的关键点置信度
一些关键点(如左肘)在参考录音中几乎不可见。我的录音也是如此,因为我试图从类似的角度录制。我在使用置信度分数作为权重计算加权余弦相似度时使用了它们。它应该更加关注在两个录音中都清晰可见的关键点。这种方法产生了以下分数:
mean cos_sim(正确动作,专业人士) = 0.8135
mean cos_sim(不正确动作,专业人士) = 0.7976
再次,分数确认第二个动作比第一个动作差,但差异很小。对于生产使用,度量必须进一步调整。
未来的改进
当我反思我的项目时,我可以看到有两个主要的改进领域。让我们分别深入探讨它们。
推进核心CV/AI技术
从技术角度来看,有几种方法可以增强姿态估计算法。例如,完善和调整比较度量可能会导致对锻炼形式的更准确评估。另一种方法可能是专注于分析骨骼或整个肢体而不仅仅是关节,这可能会提供对运动的更全面理解。此外,确保算法对相机角度、照明条件和其他环境因素不变,会使其更加健壮和可靠。
生产化和用户体验
第二个改进领域是生产化。为了创造无缝的用户体验,我需要完全自动化整个过程,这将需要在预处理和对齐数据上投入更多时间。这将涉及弄清楚如何简化工作流程,处理潜在的技术问题,并设计直观的界面。此外,构建一个包含各种设置的练习的全面库,如不同的相机角度和环境,对于为用户提供多样化的选择和场景来练习是至关重要的。
完整代码参考:
https://github.com/mystic123/ml_playground/tree/main/posts_code/pose_estimation_1
· END ·
🌟 想要变身计算机视觉小能手?快来「小白玩转Python」公众号!
回复“Python视觉实战项目”,解锁31个超有趣的视觉项目大礼包!🎁

本文仅供学习交流使用,如有侵权请联系作者删除


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









