






首先抱歉用「标题党」的形式把大家引进来看,但我的确只用了 2 个晚上,开着 1.75 倍的语速听课,拿到了 TensorFlow in Practice 专项课的证书。证明如下三张图:
8 月 6 日登记
8 月 8 日拿证
7 天免费到 8 月 13 日才过期

我说标题党不是两天学完、免费、最新 16 周、TF 实践这些词,而是这门课不是吴恩达教的 (他只在每个系列里做了简短采访),而是谷歌大脑 (Google Brain) 的 Laurence Moroney 教的。专门提他的名字是因为他这门课设计和讲得非常好,很费心血的做了无数 colab notebook,而且在讲解代码时,真的是一行行讲,一个个参数讲,还是以非常友好的方式,这一点很厉害。
接下来我们来看看 TF 实践专项课的具体内容。该系列分成四门课,每门上 4 周:
TF 简介
TF 里的卷积神经网络 (Convolutional Neural Networks, CNN)
TF 里的自然语言处理 (Natural Language Processing, NLP)
序列和时间序列 (Time Series)

这个专项课的特点是偏重用代码实现,对理论知识只是做了简单的介绍或者细节去推荐看吴恩达的 Deep Learning Specialization 那门课,但确实教了很多有用的技巧,比如:
如何用 callbacks 来控制停止训练的时点
如何用 ImageGenerator 来即时 (on-the-fly) 做数据增强
如何可视化 CNN 中每层结果
如何锁住已经训练好的模型的层来做迁移学习
如何从零开始将句子分词并填充成等长序列
如何可视化词向量 (word2vec)
如何用 Lambda Layer 来定义任意函数
等等。。。
本帖不可能涵盖该课的所有知识点,就挑一些我觉得重要的说下吧。
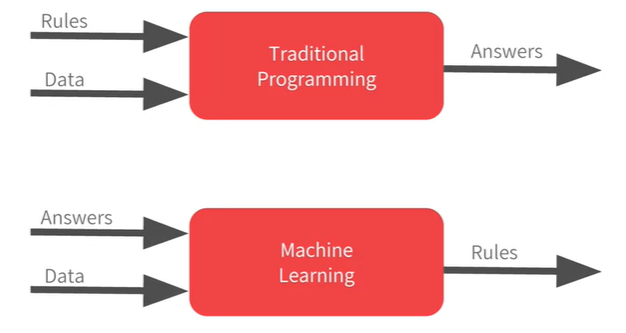
传统编程和机器学习的区别:
传统编程:根据数据和规则,生成结果
机器学习:根据数据和结果,生成规则
这门课重点放在深度学习 (机器学习的子集),因此一上来就用神经网络来解决单变量线性回归问题。其实仔细想想,一层含一个神经元的神经网络 + 均方损失函数 = 单变量线性回归。代码如下:
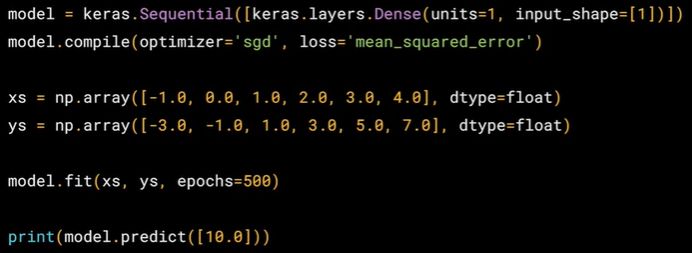
在 TensorFlow 里,深度学习模型绝大部分都是 keras 实现的,而用 keras 见神经网络有三种方法:
序列式 (sequential)
函数式 (functional)
子类化 (subclassing)
上图代码是用序列式建神经网络,只需调用 Sequential() 即可。
网络是由层 (layer) 组成的,那么 Sequential() 括号里面就是一些层,比如:
Dense():全连接层
Flatten():展开层
Dropout():舍弃层 (实在找不到一个好的翻译名词)
BatchNormalization():批量标准化层
Conv1D(), Conv2D():一维、二维卷积层
MaxPooling1D(), MaxPooling2D():一维、二维最大池化层
AveragePooling1D(), AveragePooling2D():一维、二维平均池化层
RNN():循环层
GRU():门限循环单元层
LSTM():长短期记忆层
Bidiretional():双向层
Embedding():嵌入层
Lambda():任意表达式封装层
本例用全连接层 Dense(),括号里面又可以继续设定参数,比如
units:神经元个数
input_shape:输入数据的维度
用 Sequential() 构建网络的通用写法就是
Sequential( [layer1, ..., layerN] )
将其命名为 model,接下来就是编译 (compile) 模型,拟合 (fit) 模型和预测 (predict) 模型,语法分别如下:
model.compile( optimizer, loss )
model.fit( x_train, y_train, epoch )
model.predict( x_new )
虽然本例是极简神经网络,但是复杂的神经网络也是由这四步构成:
创建模型:用序列式、函数式、子类化
编译模型:用 compile()
拟合模型:用 fit()
预测模型:用 predict()
这样看用 keras 和用 scikit-learn 差不多呢。
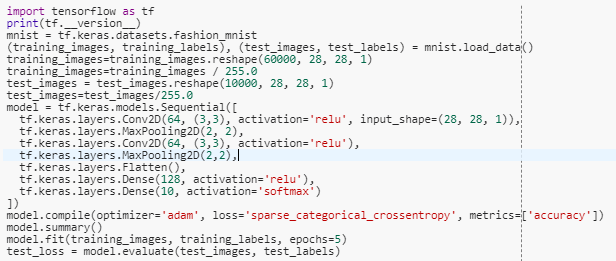
接下来看一个稍微复杂的网络 (对 Fashion MNIST 做多分类),按照前面的四步大框架思路 (不用注意细节比如激活函数是什么,损失函数是什么) ,是不是下面代码就可以看懂了。
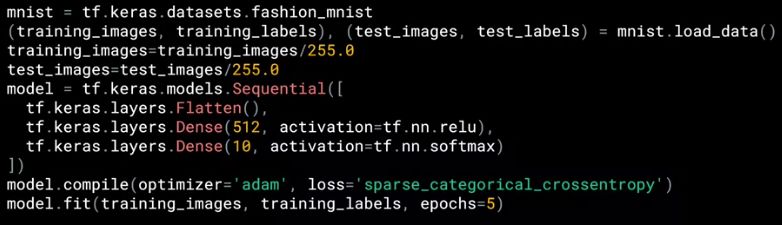
有个问题,假如我们在损失函数值小于 0.4 时就想停止训练而不再浪费资源,那么该怎么做呢?用 Callback!代码如下:
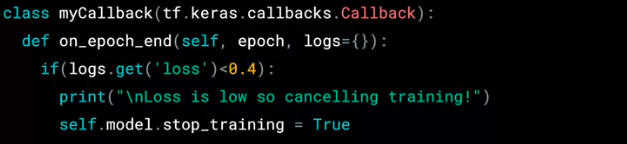
不用每行懂,几个关键点:
on_epoch_end:是说每次 epoch 结束才运行 Callback
log.get('loss')<0.4:Callback 条件
self.model_step_training = True:停止训练模型
最后只用实例化上页代码定义的 myCallBack(),再在 fit() 函数用设置 callbacks 参数即可。是不是很简单?代码如下
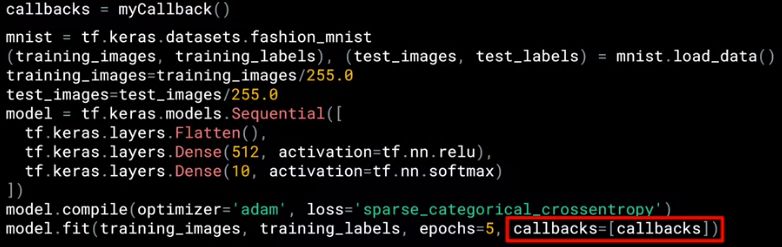
看个实例,在 MNIST 分类上,设定精度超过 99% 就停止训练。

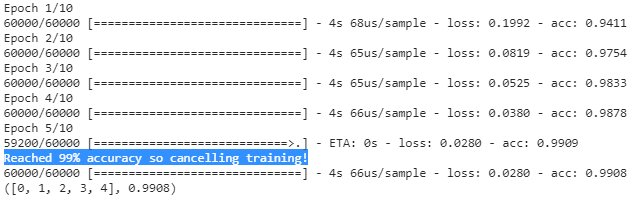
当训练精度到了 0.9909 时 (第 5 个 epoch),训练结束。这就是 Callback 的用处,不需要再继续把 10 个 epoch 就运行完。节省资源!
用 CNN 对 Fashion MNIST 做分类为例,下面是数据集,包含十类衣饰。
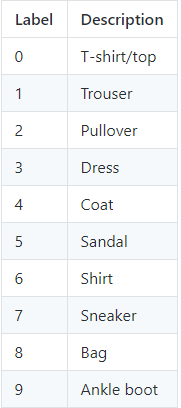
部分数据集的图展示如下。

动态可视图如下,可以看出不同类别的物体聚类在一起。

接下来用两层卷积层 + 两层全连接层训练一发。
我们看看测试集前 100 个标签,发现索引 2,3 和 5 位的标签都是 1,对应的物体是裤子 (Trouser)。
print(test_labels[:100])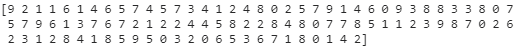
接下来我们可以做各种可视化实验,比如看看裤子在不同 filter 中不同层下学到的特征是什么样的。
下图代码先看第 2 个 Filter (CONVOLUTION_NUMBER = 1) 下两个 Conv2D 层和两个 MaxPooling2D 学到的特征,看起来好像是一个直角。

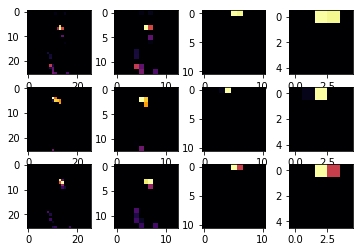
接着来,下图代码再看第 3 个 Filter (CONVOLUTION_NUMBER = 2) 下两个 Conv2D 层和两个 MaxPooling2D 学到的特征,看起来是裤子的两条腿。

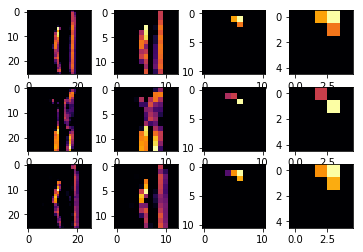
我们设定的两层 Conv2D 都包含 64 个 filter,因此可以一个个看它们学到的特征是怎么样的。此外从图中可以看出 MaxPooling2D 的作用,即将最显著的像素点放大了。
做图像分类 (image classification) 任务两个常用的数据集是 MNIST 和 Fashion-MNIST,本课也用它们做了展示。但是在实际做图像分类时,图片都不是事先剪裁好的 (像前面两个 28×28),也不会事先分成 X 和 y 的。
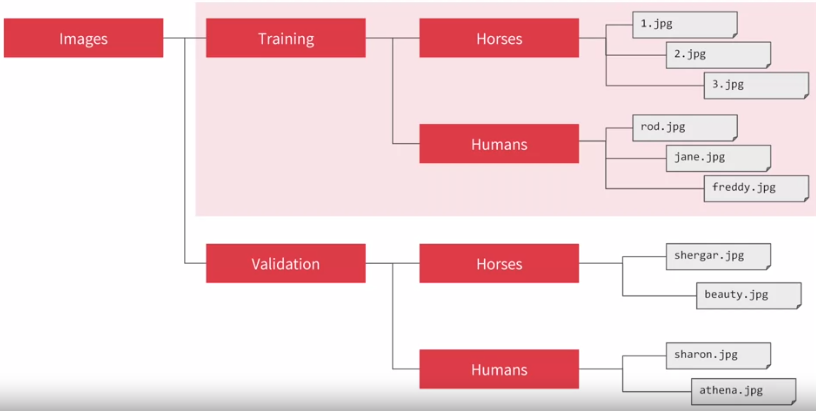
首先把收集 (网上下载的、电脑制造的) 的照片放在不同的文件夹 (比如训练和验证时分两个子文件夹、它们又按不同类别再放入不同的子文件夹) 中,如下图所示。
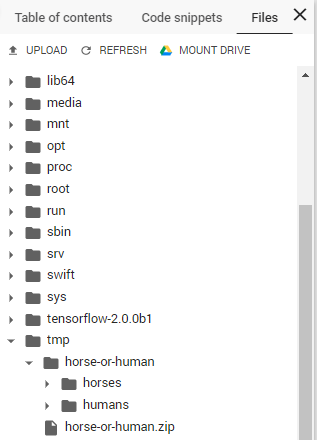
在 colab notebook 里运行
可在 notebook 左边的 files 中的 tmp 文件看到照片已传到其虚拟环境上了。
这是需要用到 ImageDataGenerator() 来做剪裁、生成特征数组 X 和标签数组 y。代码如下:
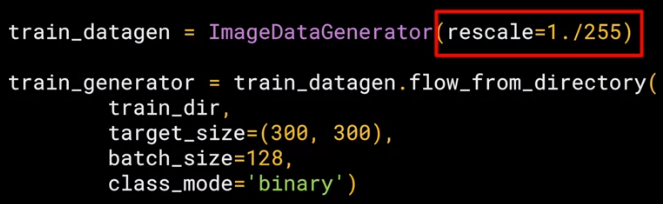
第一行把 0-255 的像素值单位化到 0-1,接着再设定路径 train_dir,图片尺寸 300×300,每批 128 张,类别是两类。
ImageDataGenerator() 美妙的地方是以上这些操作都是当使用时而即时 (on-the-fly) 做的,它不会改变原始图片。
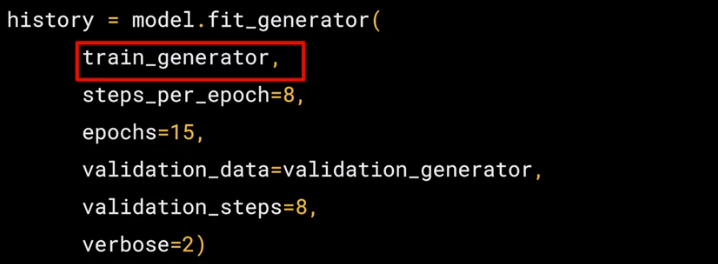
之后可以用 Dense() 或 Conv2D() 构建 DNN 和 CNN 模型,但是在训练模型是用的不是 fit() 函数而是 fit_generator()。代码如下,里面的参数有 6 个,看名字就知道是什么意思了。
数据是宝贵的,深度学习模型基本上都是数据越多效果越好。当数据很少时,数据增强(data augmentation) 是能提升模型效果的一个重要手段。代码如下:
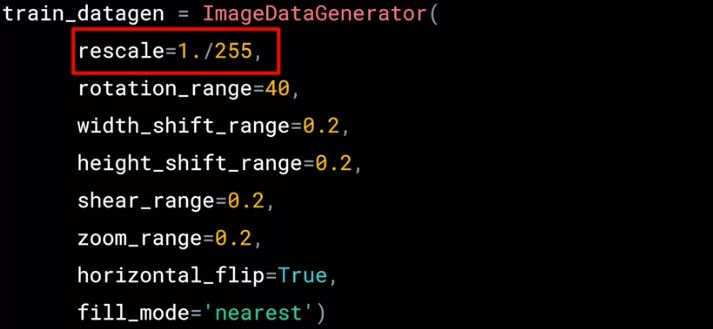
还是用 ImageDataGenerator() ,但是多了不少参数
rotation_range:旋转图片 40 度
width_shift_range:横向移动 20%
height_shift_range:纵向移动 20%
shear_range:逆时针剪切 20% 强度
zoom_range:放大 20% 强度
horizontal_filp:是否水平翻转
fill_mode:缺失值如何被填满
我们来看看剪切、缩放和翻转的例子,以及为什么这样做有效。

在对左边照片做完剪切之后,人会倾斜,那么当网络学到这个也是人时,那么对类似躺着的人可能会预测正确。

左边是训练图片,右边是未见过的新图片。

将训练图片放大之后,和训练图片的人 占照片同等比例 的新照片的人会更有可能预测正确。


水平翻转训练图片后,当从训练图片中学到举起右手的物体是人,那么新照片中举起右手的物体也大概率是人。

数据增强在实战中真的有效,其实道理也很简单,就是神经网络和人比起来太 TM 的蠢了,要看过很多种不同形态 (旋转移位、放大缩小、左翻右翻等) 的同类物体才知道是这个物体。收集的图片不可能有这么丰富的体位,那不只能「愚蠢」地做数据增强,来喂饱「愚蠢」的神经网络吗?
人绝对不是这样识别物体的,小孩看几张猫就永远能识别出来猫,哪需要成千上万张?深度学习的路还很长,这也是那么多大牛还在探索人脑的原因。
本课也用了猫狗分类的例子比较了做数据增强前后的分类效果,结果就不贴出来了。
如果说数据增强是增多数据来提高模型的牛逼程度,那迁移学习 (transfer learning) 就是直接去找个更牛逼的模型「偷」过来用。
如下图,比如你用自己写的 CNN 来一层层提取人脸的特征,但是你的模型很烂,那么该怎么办?
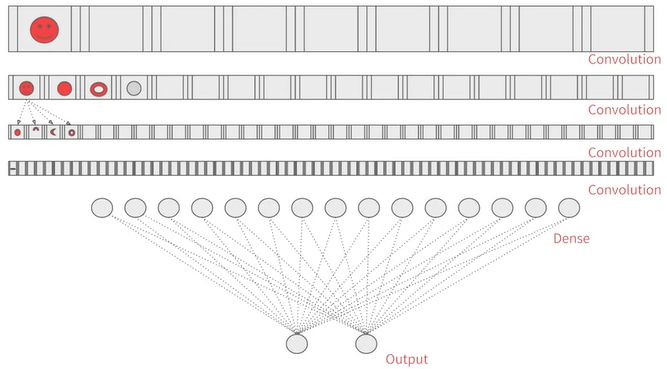
找市面上牛逼的模型呗!超级多层,提取特征有效,把前面若干层锁住,移花接木到你的任务上,训练最后若干层即可。
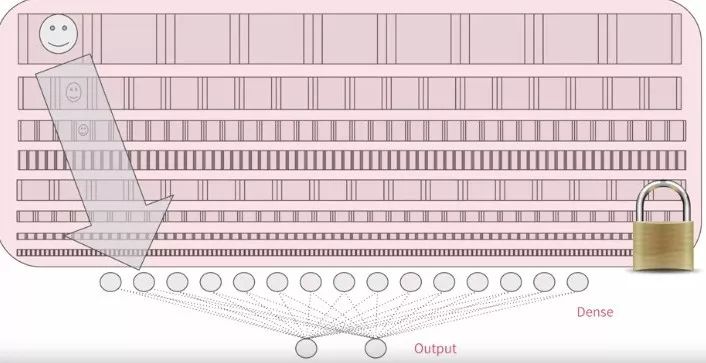
吴恩达说他经常用迁移学习,我信了,也下定决心要学会这移花接木的本事,但问题是
如何移花,即如何找到牛逼的模型?
如何接木,即如何无缝连到自己模型?
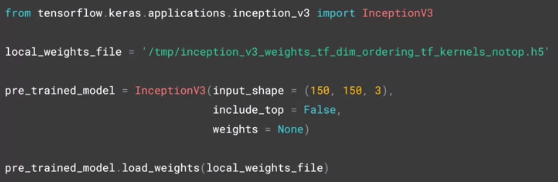
Google 的 Inception 模型够牛逼,而且在庞大的图片集中训练出很多好的特征。模型说白了就是权重,因此用 load_weights 的方法相等于把 Inception 模型借过来了,命名为 pre_trained_model。
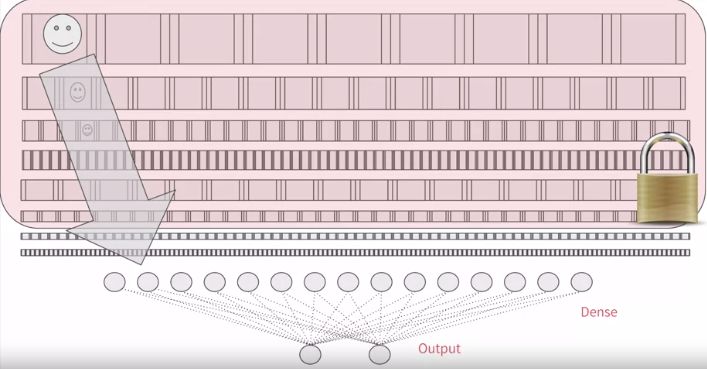
细心的读者可能注意到上面两图有个「锁」,看起来像每层都锁住,即锁住的层都不参与训练,因此下面代码非常重要,将 layer.trainable 设置为 False。

这样移花的步骤就完成了。
Keras 在模型每层都可以起名,假设我们想从 'mixed7' 这层开始接,那么只用 get_layer 来找到这一层。

接下来就把 last_output 当做输入,开始建立自己的神经网络了,后面的代码可以一气呵成了。
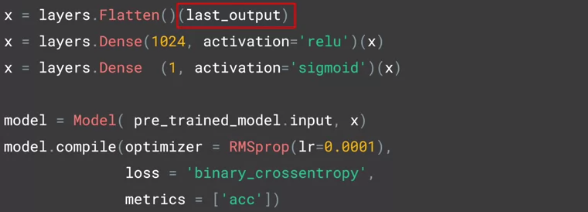
还记得 Keras 里面的三种构建模型的方法么?
序列式 (sequential)
函数式 (functional)
子类化 (subclassing)
上节介绍了序列式,上面代码是函数式。这种方式更灵活,可以这么说,只要能做序列式的模型一定能用函数式写出来,反之不行。
函数式的通用写法是:
定义一个 Input 并赋给 x
然后不停用
x = layer1(x)
x = layer2(x)
...
Output = layerN(x)
用 Model() 函数将 Input 和 Output 联系起来
model = Model(Input, Output)
之后怎么编译模型、拟合模型和预测模型,和之前的套路一模一样!
文本类和图像类数据非常不一样。
图像是由像素组成,而像素是连续的数值型变量
文本是由词或字组成,而词或字是字符型变量
各种神经网络的输入不能处理字符型变量,我们需要一种能将「字符型变量转换成数值型变量」的编码方法。
说实话我太敬佩 Laurence 这种大牛居然能耐心地从零开始教。他一上来并没有从 NLP 里大家都会必讲的 word2vec 开始,而且从更基础更自然的内容开始。
比如如何对 LISTEN 这个单词编码?那么正常人一开始想到的肯定是 ASCII 表 (见下图),因为里面有字符和数字的一一对应关系。
比如 LISTEN 这个词里每个大写字母通常查 ASCII 表得到下图的编码。
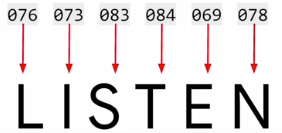
但这样给每个字母编码会有一个问题。比如 SILENT 和 LISTEN 两个词有同样的字母组成,那么从相同的编码角度看应该是意思相同,但实际在两词意思甚至想反。

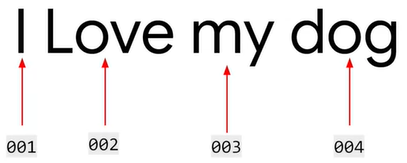
如果给每个字母编码不好,那么给每个单词编码如何呢?举例 I love my dog 这一句话有四个词,每个词用简单的 001, 002, 003 和 004 来编码。
用这个思路,那么继续对 I love my cat 编码,因此 cat 是个新词,顺着用 005 编码,那么上句的编码就是 001, 002, 003, 005。
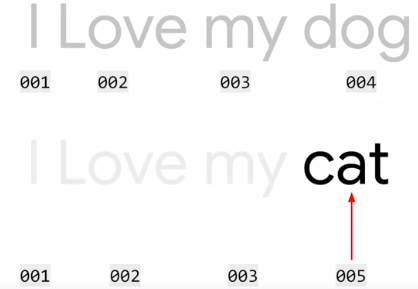
显然,两句话意思相近,从编码角度也能看出来。

上面这套编码流程虽然很朴素,但这至少是一个正确的方向。
下面看如何用 tensorflow + keras 里面的工具包来实现编码。重要的工具包是 Tokenizer,代码如下。
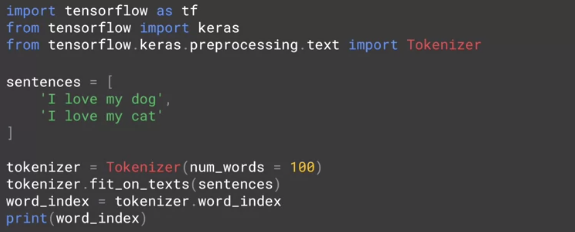
倒数第四行用 Tokenizer 并设定其参数 num_words = 100,然后此对象下面的 fit_on_texts 方法会根据句子里面词的出现频率从 1,2, ... 开始编码。结果如下。

当新加一个句子 you love my dog!,Tokenizer 可以忽略标点符号,把 dog! 当成 dog,而不是当成一个新词。
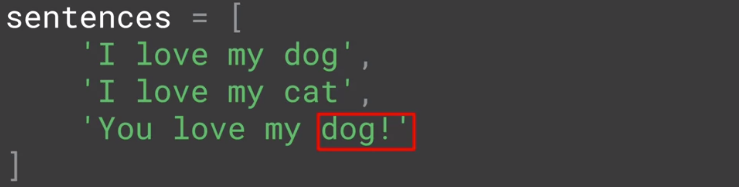
You 是一个新词,因此给它编码为 6,看结果如下。

给每个词编码就是用一个整数代表一个词,接下来很自然就是把一句话转成一个整数序列。用的是 Tokenizer 下面的 texts_to_sequences 方法,代码如下。
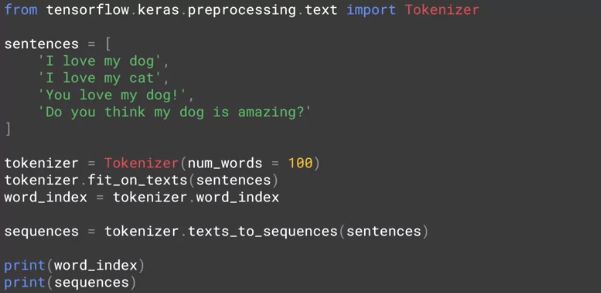
现在有四个句子了,最后两行就是输出
每个词编码 word_index
每句话的序列 sequences
结果如下。
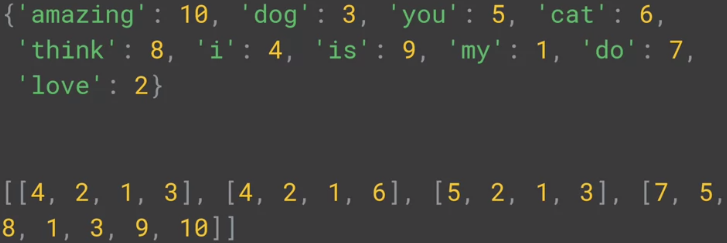
上面四句话属于训练集,假如测试集有两句话:
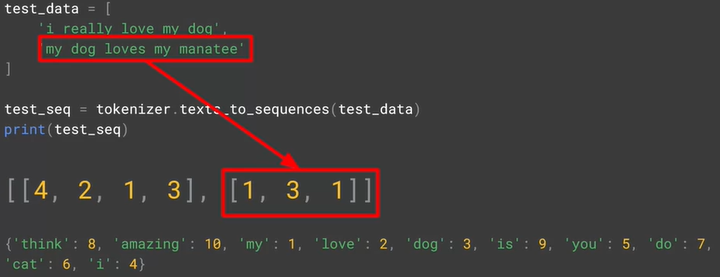
i really love my dog
my dog loves my manatee
在训练集的词中没有出现 really, loves 和 manatee 这三个词,因此在编码中会忽略,如下图所示
第一句的序列 [4, 2, 1, 3],没有对 really 进行编码,译过来就是 i love my dog
第二句的序列 [1, 3, 1],没有对 loves 和 manatee 进行编码,译过来就是 my dog my
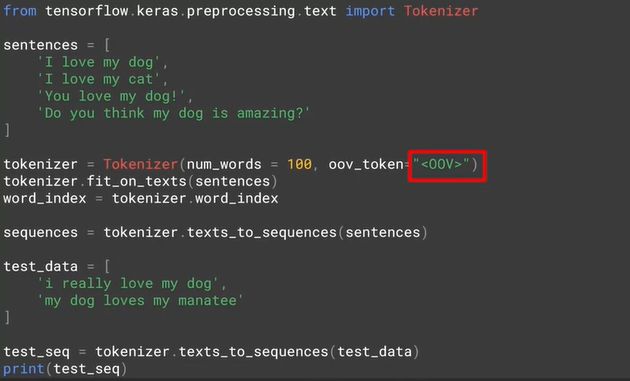
其实大训练集不太会出现这种问题,因此基本的词都会在训练集中出现,但对小训练集这的确是个问题。解决方法就是用 oov_token 来专门表示新词,OOV 是 Out-Of-Vocabulary 的缩写。
如下图代码所示,只用在 Tokenizer 里面多加一个参数 oov_token="<OOV>" 即可。
现在,测试集的三个新词 really, loves 和 manatee 都编码成 <OOV>,对应的整数是 1。结果如下。

句子都是不等长的,那么编码后的序列也是不等长的。而喂进神经网络的数据都是等长的,这是需要一些填充 (padding) 手段。重要的工具包是 pad——sequences,代码和结果如下。
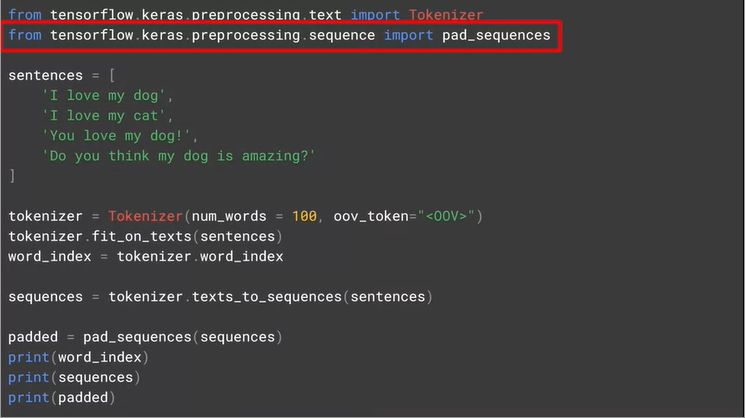
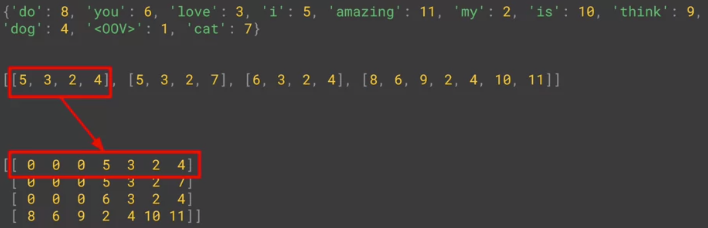
再看这四句话都被填充得等长了 (用 0 来填充)。但是默认是从前面填充
如果想从后填充,加 padding='post'
如果想限制填充后最大长度,加 maxlen
如果填充后超过最大长度要从后面删减,加 truncating='post'



上述编码也只是把单词转换成一个整数,一个句子转换成一系列整数序列。这种做法并没有抓住词与词的意思之间的联系。
常见的做法是把整数用独热编码转成高维稀疏向量再转成低维密集向量,因此一个词可能用 100D, 300D 或 500D 的向量来表示,而词与词之间的相似度就用向量之间内积表示。这个过程就叫做 word2vec,即把单词转成换向量的过程,在 keras 里用 Embedding() 来实现。这个操作放在最开始,一个好的 embedding 是整个模型好快的关键。
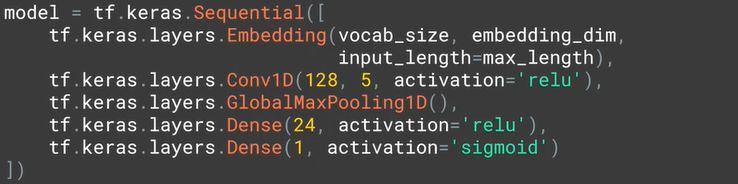
之后可以用 LSTM 层或 Conv1D 层来拼接。
比如用 1 个 LSTM 层。

比如用 2 个 LSTM 层。

比如用 1 个 Conv1D 层 + 1 个 GlobalMaxPooling1D 层。
写到这里真的要吐血了,就简短说下吧。
时间序列是量化金融里面一个重要课题,也是很多人想做量化投资必须内容。大家想做的事情就是给定一段序列 S(1), S(2), ... S(t),预测 S(t+1)。
时间序列通常由四个部分组成。
时间序列 = 季节性 + 趋势 + 自相关 + 噪声
传统的预测方式用很多,比如就用 S(t) 当做预测,比如用移动平均值等等,机器学习的方式就是融合不同的 Dense 层, LSTM 层和 Conv1D 层来看效果,反正在 keras 拼接它们非常简单。
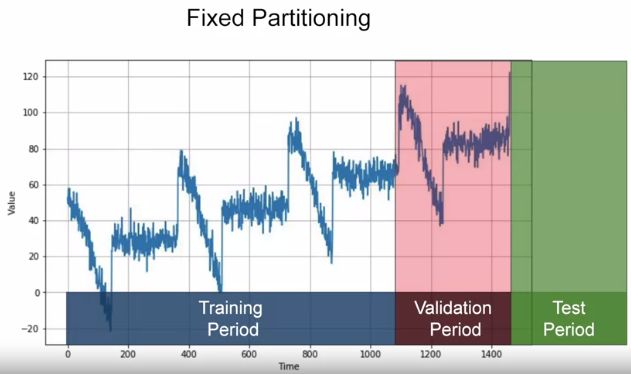
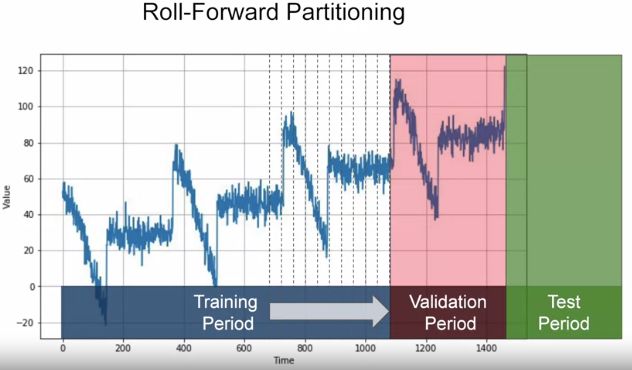
两种方法分训练-验证-测试集,首先测试集永远最新数据,此外训练集可以是用固定长度 (fixed),也可以不停向前 (roll-forward) 增长。
下面用了 Conv1D + 2 LSTM + Dense 的模型,在 Keras 里面构建非常简单。
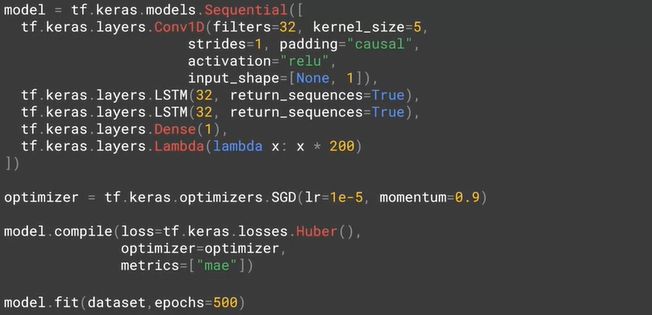
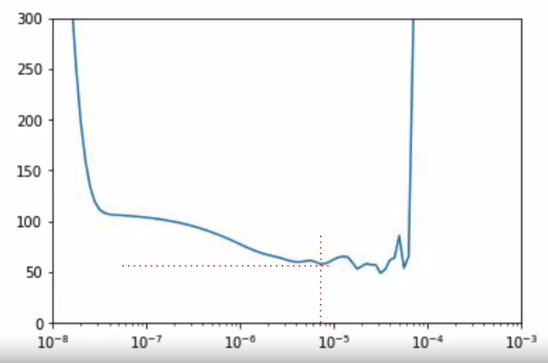
困难的就是调参数。学习率是个非常重要的参数,可用 LearningRateScheduler 作为 callbacks 找到一个最优学习率,然后在继续调整别的参数。


从下图看,大概学习率在 0.8×10-5 的地方损失最小。
本课主要就是介绍 TensorFlow + tf.Keras 的实战,主要内容包括:
DNN, CNN, RNN (LSTM) 等模型
CV, NLP, Time Series 等应用
图像分类、情感分类、文本生成、时间序列预测等任务
其实学知识很简单,但能 2 天学完这 16 周的课,这么快速学完这些知识,还是需要一些激励 (motivation) 的。
为面子:先吹牛 X 发朋友圈,再拼了命实现它。
为省钱:先填信用卡信息,再拼了命学完,学得越快省下钱越多 (我是免费
 )
)
还有执行力很重要,但很多号在转发这门课时,我选择的不是转发和收藏,而且去 Coursera 注册这门课。















 775
775











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









