






点击上方“AI算法与图像处理”,选择加"星标"或“置顶”
重磅干货,第一时间送达
转载自简书,仅用于学习交流,如有侵权请联系删除
编辑:Charlotte数据挖掘
作者主页:
https://www.jianshu.com/u/7809064bce51
前言
小目标问题在物体检测和语义分割等视觉任务中一直是存在的一个难点,小目标的检测精度通常只有大目标的一半。
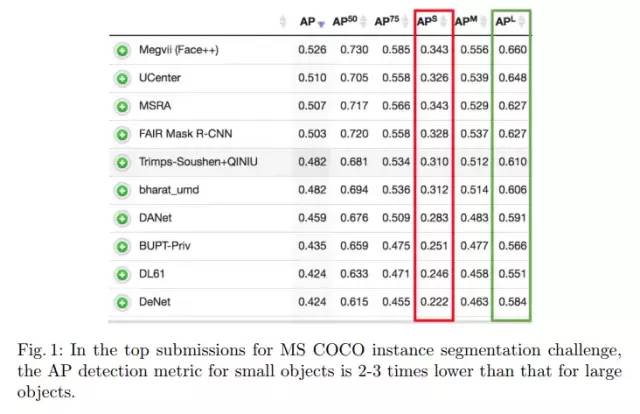
MS COCO instance segmentation challenge
CVPR2019论文: Augmentation for small object detection 提到了一些应对小目标检测的方法,笔者结合这篇论文以及查阅其它资料,对小目标检测相关技巧在本文进行了部分总结。
小目标的定义:在MS COCO数据集中,面积小于 32*32 的物体被认为是小物体。
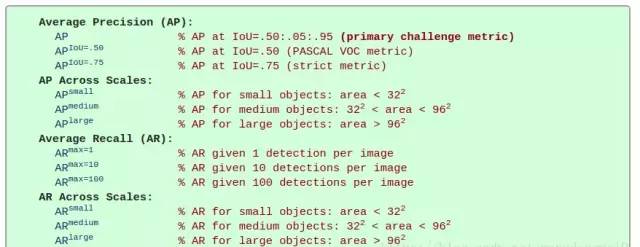
MS COCO Metrics
在COCO数据集中,小目标的数量更多,具体为:41% of objects are small (area < 322)34% are medium (322 < area < 962)24% are large (area > 962)
area的计算方法:像素点的个数。MS COCO Metrics 详细介绍参考:
https://blog.csdn.net/wangdongwei0/article/details/83033340
小目标难以检测的原因:分辨率低,图像模糊,携带的信息少。由此所导致特征表达能力弱,也就是在提取特征的过程中,能提取到的特征非常少,这不利于我们对小目标的检测。
现有的比较流行的方法是如何解决小目标检测问题的?
1、由于小目标面积太小,可以放大图片后再做检测,也就是在尺度上做文章,如FPN(Feature Pyramid Networks for Object Detection),SNIP(An Analysis of Scale Invariance in Object Detection – SNIP)。
Feature-Fused SSD: Fast Detection for Small Objects, Detecting Small Objects Using a Channel-Aware Deconvolutional Network 也是在多尺度上做文章的论文。
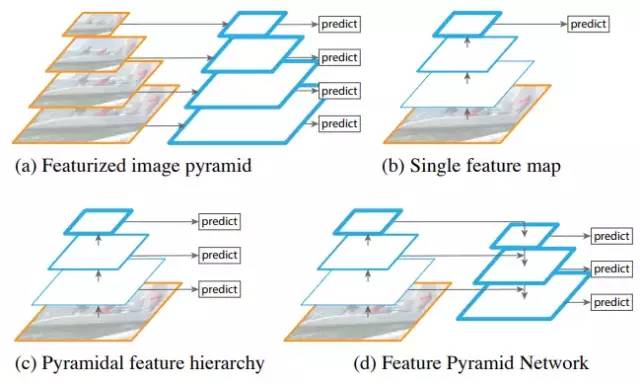
FPN
2、在Anchor上做文章(Faster Rcnn,SSD, FPN都有各自的anchor设计),anchor在设置方面需要考虑三个因素:
anchor的密度:由检测所用feature map的stride决定,这个值与前景阈值密切相关。
anchor的范围:RetinaNet中是anchor范围是32~512,这里应根据任务检测目标的范围确定,按需调整anchor范围,或目标变化范围太大如MS COCO,这时候应采用多尺度测试。
anchor的形状数量:RetinaNet每个位置预测三尺度三比例共9个形状的anchor,这样可以增加anchor的密度,但stride决定这些形状都是同样的滑窗步进,需考虑步进会不会太大,如RetinaNet框架前景阈值是0.5时,一般anchor大小是stride的4倍左右。
该部分anchor内容参考于:https://zhuanlan.zhihu.com/p/55824651
3、在ROI Pooling上做文章,文章SINet: A Scale-Insensitive Convolutional Neural Network for Fast Vehicle Detection 认为小目标在pooling之后会导致物体结构失真,于是提出了新的Context-Aware RoI Pooling方法。
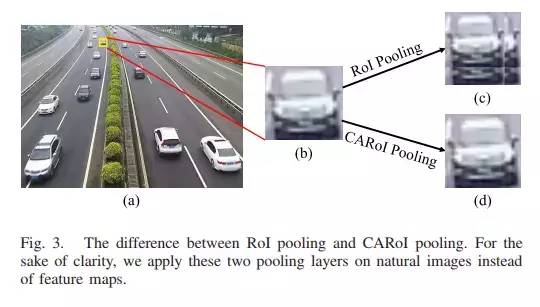
Context-Aware RoI Pooling
4、用生成对抗网络(GAN)来做小目标检测:Perceptual Generative Adversarial Networks for Small Object Detection。
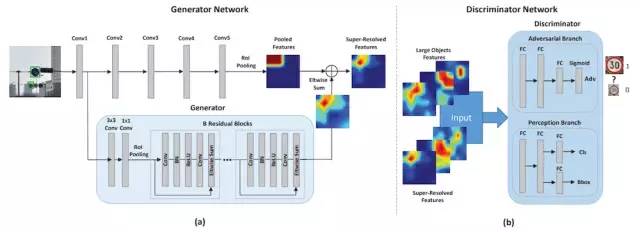
Perceptual Generative Adversarial network
进一步从量化的角度来分析
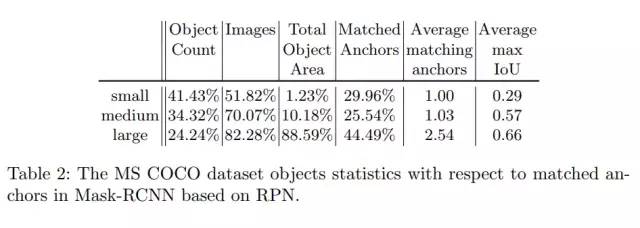
COCO上的统计图
1、从COCO上的统计图可以发现,小目标的个数多,占到了41.43%,但是含有小目标的图片只有51.82%,大目标所占比例为24.24%,但是含有大目标的图像却有82.28%。这说明有一半的图像是不含小目标的,大部分的小目标都集中在一些少量的图片中。这就导致在训练的过程中,模型有一半的时间是学习不到小目标的特性的。
此外,对于小目标,平均能够匹配的anchor数量为1个,平均最大的IoU为0.29,这说明很多情况下,有些小目标是没有对应的anchor或者对应的anchor非常少的,即使有对应的anchor,他们的IoU也比较小,平均最大的IoU也才0.29。
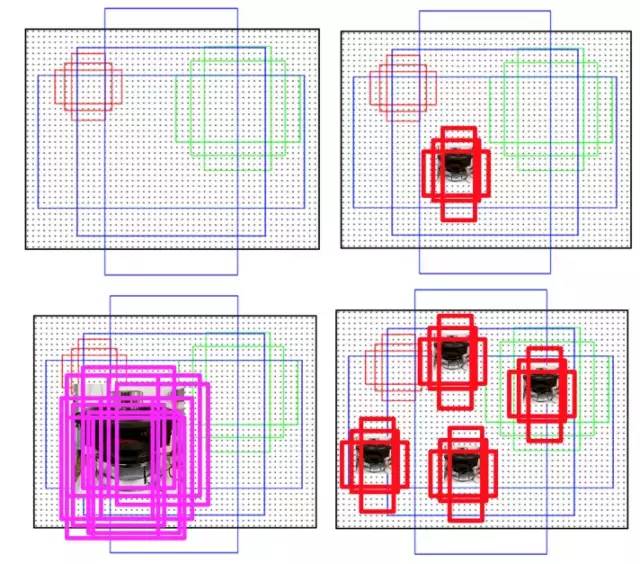
anchor示意图
如上图,左上角是一个anchor示意图,右上角是一个小目标所对应的anchor,一共有只有三个anchor能够与小目标配对,且配对的IoU也不高。左下角是一个大目标对应的anchor,可以发现有非常多的anchor能够与其匹配。匹配的anchor数量越多,则此目标被检出的概率也就越大。
实现方法
1、Oversampling :我们通过在训练期间对这些图像进行过采样来解决包含小对象的相对较少图像的问题(多用这类图片)。在实验中,我们改变了过采样率和研究不仅对小物体检测而且对检测中大物体的过采样效果
2、Copy-Pasting Strategies:将小物体在图片中复制多分,在保证不影响其他物体的基础上,增加小物体在图片中出现的次数(把小目标扣下来贴到原图中去),提升被anchor包含的概率。
如上图右下角,本来只有一个小目标,对应的anchor数量为3个,现在将其复制三份,则在图中就出现了四个小目标,对应的anchor数量也就变成了12个,大大增加了这个小目标被检出的概率。从而让模型在训练的过程中,也能够有机会得到更多的小目标训练样本。
具体的实现方式如下图:图中网球和飞碟都是小物体,本来图中只有一个网球,一个飞碟,通过人工复制的方式,在图像中复制多份。同时要保证复制后的小物体不能够覆盖该原来存在的目标。

Copy pasting the small objects
参考代码:https://github.com/zhpmatrix/VisDrone2018/tree/master/DataAug_Patching该部分参考文章:https://zhuanlan.zhihu.com/p/57760020
网上有人说可以试一下lucid data dreaming Lucid Data Dreaming for Multiple Object Tracking,这是一种在视频跟踪/分割里面比较有效的数据增强手段,据说对于小目标物体检测也很有效。
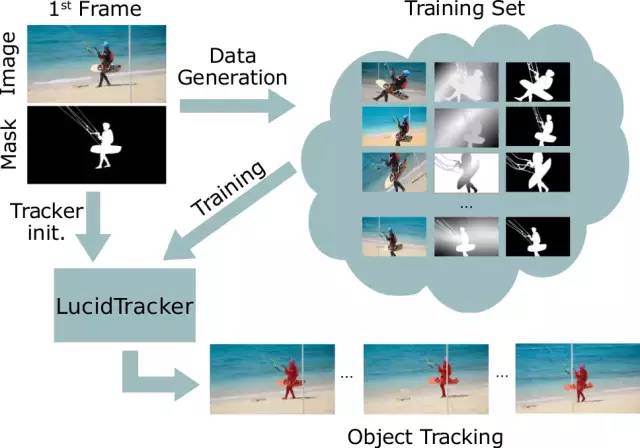
Lucid Data Dreaming for Multiple Object Tracking
参考代码:https://github.com/ankhoreva/LucidDataDreaming
其他
基于无人机拍摄图片的检测目前也是个热门研究点(难点是目标小,密度大)。相关论文:The Unmanned Aerial Vehicle Benchmark: Object Detection and Tracking(数据集)Drone-based Object Counting by Spatially Regularized Regional Proposal NetworkSimultaneously Detecting and Counting Dense Vehicles from Drone ImagesVision Meets Drones: A Challenge(数据集)
参考文献
1:https://zhuanlan.zhihu.com/p/558246512:https://zhuanlan.zhihu.com/p/577600203:https://www.zhihu.com/question/269877902/answer/5485940814:https://zhuanlan.zhihu.com/p/600332295:https://arxiv.org/abs/1902.072966:http://openaccess.thecvf.com/content_cvpr_2017/papers/Li_Perceptual_Generative_Adversarial_CVPR_2017_paper.pdf7:http://openaccess.thecvf.com/content_cvpr_2017/papers/Lin_Feature_Pyramid_Networks_CVPR_2017_paper.pdf

好文推荐:

同学快上车吧,一群大佬都在等你~
扫码添加助手,可申请加入AI_study交流群。一定要备注:研究方向+地点+学校/公司+昵称(如目标检测+上海+上交+卡卡西),不根据格式申请,一律不通过。
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









