










本教程使用Chrome
最近看到了个网站:https://sc.chinaz.com/tubiao/
上面有1万多个图标
所以点一波鼠标图标(也可以换成别的):

URL:
https://sc.chinaz.com/tag_tubiao/DianNao.html
开F12:
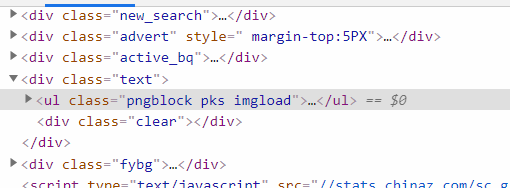
可以看到class为pngblock pks imgload的ul存放了这堆超链接:

找到超链接,在li标签下的span里:
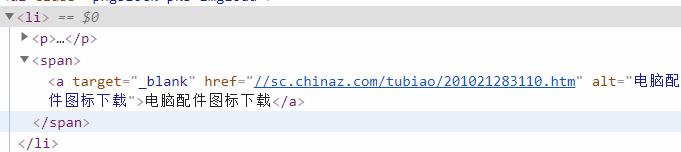
右键 Open in a new tab
URL:
https://sc.chinaz.com/tubiao/201021283110.htm

点一下每个图片上的ICO:

我直呼好家伙……
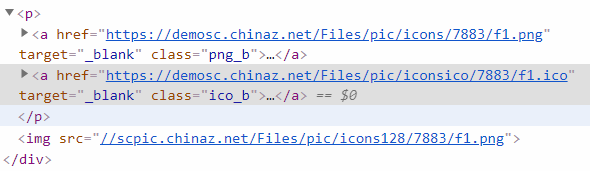
开F12,找到ICO,是个class为ico_b的a标签:
写代码
安装第三方库:
pip install requests
pip install beautifulsoup4
python代码:
import os
import requests
from bs4 import BeautifulSoup
def download_icons_from_chinaz(url, save_path='images', headers=None,
encoding='utf-8', parser='html.parser',
ul_class_name='pngblock pks imgload',
max_download=30):
if not os.path.isdir(save_path):
os.mkdir(save_path)
if headers is None:
headers = {
'User-Agent': (
'Mozilla/5.0 (Windows NT 6.2; WOW64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/30.0.1599.17 Safari/537.36'
)
} # 伪装请求头
response = requests.get(url, headers=headers)
response.encoding = encoding
soup = BeautifulSoup(response.text, parser) # beautifulsoup解析
ul = soup.find('ul', attrs={'class': ul_class_name})
lis = ul.find_all('li')
urls = []
for li in lis:
span = li.find('span')
a = span.find('a')
href = a['href'] # 获取每个页面的url
urls.append(href)
images = []
for url in urls:
url = 'https:' + url # 由获取到的url是“//”开头的,加上“https:”
response = requests.get(url, headers=headers) # requests请求
response.encoding = encoding
soup = BeautifulSoup(response.text, parser) # beautifulsoup解析
div = soup.find('div', attrs={'class': 'down_img'})
icons = div.find_all('a', attrs={'class': 'ico_b'})
for a in icons:
href = a['href']
images.append(href)
n = 0
for im in images:
print('█', flush=True, end='') # 显示进度条
n += 1
if n > max_download:
break
path = os.path.join(save_path, f'{n}.ico')
response = requests.get(im, headers=headers)
with open(path, 'wb') as fp:
fp.write(response.content)
| 参数 | 意义 | 类型 |
|---|---|---|
| url | 类似我的https://sc.chinaz.com/tag_tubiao/DianNao.html | str |
| save_path | 图片保存的文件夹 | str |
| headers | 自定义请求头 | dict |
| encoding | 网页编码 | str |
| parser | beautifulsoup解析器 | str |
| ul_class_name | 存放a标签的ul的class | str |
| max_download | 最大下载数量 | int |
注意:连续爬图片可能请求频繁,加个time.sleep就好了

nice!















 128
128











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









