






【试题1】 5分
已知数据a=np.array([ [1,2,3,4],[5,6,7,25],[3,4,5,6],[4,5,6,11]]),
请根据数据完成如下任务:
(1)获取所有矩阵元素的平均值和中位数 。2分
(2)获取矩阵行方向的方差。1分
(3)获取矩阵列方向的标准差。1分
(4)对矩阵行方向求累积和。1分
import numpy as np
a=np.array([ [1,2,3,4],[5,6,7,25],[3,4,5,6],[4,5,6,11]])
a.mean()
np.median(a)
a.var(axis=1)
a.std(axis=0)
a.sum(axis=1)a.mean() 是 np.mean(a) 的简单版, 使用方法基本是相同的, 唯一的不同就是前者是numpy数组对象的方法, 后者作为numpy的函数使用.
【试题2】20分
鸢尾属植物数据集.\2\iris.txt,在这个数据集中,包括了三类不同的鸢尾属植物:Iris-setosa,Iris-versicolor,Iris-virginica。每类收集了50个样本,因此这个数据集一共包含了150个样本。
- SepalLengthCm:萼片长度
- SepalWidthCm:萼片宽度
- PetalLengthCm:花瓣长度
- PetalWidthCm:花瓣宽度
以上四个特征的单位都是厘米(cm)。
1. 导入鸢尾属植物数据集,保持文本不变。1分
import numpy as np
outfile=r'E:/PythonFile/venv/ai/iris.txt'
iris_data=np.loadtxt(outfile,dtype=object,skiprows=1)
#iris_data=np.loadtxt(outfile,dtype=object,delimeter="\t",skiprows=1)
iris_data 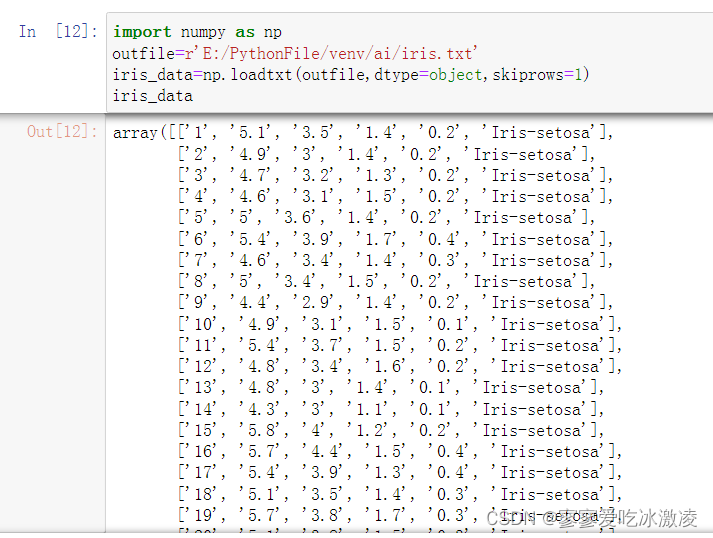
2. 求出鸢尾属植物萼片长度的平均值、中位数、标准差(第1列,SepalLengthCm)1分
SepalLengthCm=np.loadtxt(outfile,dtype=float,skiprows=1,usecols=1)
print(np.mean(SepalLengthCm))
print(np.median(SepalLengthCm))
print(np.std(SepalLengthCm))
#5.843333333333334
#5.8
#0.82530129178514093. 创建一种标准化形式的鸢尾属植物萼片长度,其值正好介于0和1之间,这样最小值为0,最大值为1(第1列,SepalLengthCm)。1分
SepalLengthCm=np.loadtxt(outfile,dtype=float,skiprows=1,usecols=1)
a=np.max(SepalLengthCm)
b=np.min(SepalLengthCm)
SepalLengthCm=(SepalLengthCm-b)/(a-b)
#归一化4. 找到鸢尾属植物萼片长度的第5和第95百分位数(第1列,SepalLengthCm)。1分
import numpy as np
outfile=r'E:/PythonFile/venv/ai/iris.txt'
SepalLengthCm=np.loadtxt(outfile,dtype=float,skiprows=1,usecols=1)
x=np.percentile(SepalLengthCm,[5,95])
print(x)
#[4.6 7.255]5. 把iris数据集中的20个随机位置修改为np.nan值。1分
import numpy as np
outfile=r'E:/PythonFile/venv/ai/iris.txt'
iris_data=np.loadtxt(outfile,dtype=object,skiprows=1)
i,j=iris_data.shape
np.random.seed(20220723)
iris_data[np.random.randint(i,size=20),np.random.randint(j,size=20)]=np.nan
iris_data6. 在iris的SepalLengthCm中查找缺失值的个数和位置(第1列)。1分
import numpy as np
import pandas as pd
outfile=r'E:/PythonFile/venv/ai/iris.txt'
iris_data=np.loadtxt(outfile,dtype=object,skiprows=1,usecols=[1,2,3,4])
i,j=iris_data.shape
np.random.seed(20220723)
iris_data[np.random.randint(i,size=20),np.random.randint(j,size=20)]=np.nan
SepalLengthCm=iris_data[:,0].astype('float')
x=np.sum(np.isnan(SepalLengthCm))
y=np.where(np.isnan(SepalLengthCm))
print(x)
print(y)
#SepalLengthCm=iris_data[:,0]
# pd.isnull(SepalLengthCm)
#np.isnan()对float类型起作用,pd.isnull可以不用改数据类型
7. 筛选具有 SepalLengthCm(第1列)< 5.0 并且 PetalLengthCm(第3列)> 1.5 的数据行。1分
import numpy as np
import pandas as pd
outfile=r'E:/PythonFile/venv/ai/iris.txt'
iris_data=np.loadtxt(outfile,dtype=object,skiprows=1,usecols=[1,2,3,4])
sepalLength=iris_data[:,0].astype('float')
petallength=iris_data[:,2].astype('float')
#str与int不能比较大小,要转为float
#或者导入数据的时候就转类型
#iris_data=np.loadtxt(outfile,dtype=object,skiprows=1,usecols=[1,2,3,4])
index=np.where(np.logical_and(sepalLength<5.0,petallength>1.5))
iris_data[index]
8. 选择没有任何 nan 值的数据行。
import numpy as np
import random
outfile=r'E:/PythonFile/venv/ai/iris.txt'
iris_data=np.loadtxt(outfile,dtype=float,skiprows=1,usecols=[1,2,3,4])
i,j=iris_data.shape
iris_data[np.random.randint(i,size=20),np.random.randint(j,size=20)]=np.nan
x=iris_data[np.sum(np.isnan(iris_data),axis=1)==0]
xnp.sum(np.isnan(iris_data),axis=1)==0
9. 计算数据集中SepalLengthCm(第1列)和PetalLengthCm(第3列)之间的相关系数。1分
import numpy as np
outfile=r'E:/PythonFile/venv/ai/iris.txt'
iris_data=np.loadtxt(outfile,dtype=float,skiprows=1,usecols=[1,3])
SepalLengthCm=iris_data[:,0]
PetalLengthCm=iris_data[:,1]
np.corrcoef(SepalLengthCm,PetalLengthCm)
# x=np.cov(sepalLength,petallength,ddof=False)
# y=np.std(sepalLength)*np.std(petallength)
# print('相关系数:',x[0,1]/y)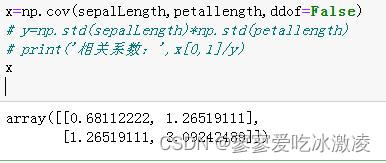

相关系数=两者协方差/标准差之积
10. 在numpy数组中将所有出现的nan替换为0。1分
import numpy as np
import random
outfile=r'E:/PythonFile/venv/ai/iris.txt'
iris_data=np.loadtxt(outfile,dtype=float,skiprows=1,usecols=[1,2,3,4])
iris_data[np.random.randint(i,size=20),np.random.randint(j,size=20)]=np.nan
iris_data[np.isnan(iris_data)]=0
11. 找出鸢尾属植物物种中的唯一值和唯一值出现的数量。1分
import numpy as np
import random
outfile=r'E:/PythonFile/venv/ai/iris.txt'
iris_data=np.loadtxt(outfile,dtype=str,skiprows=1,usecols=[5])
x,p=np.unique(iris_data,return_counts=True)12. 将数据集的花瓣长度(第3列)以形成分类变量的形式显示。定义:<=3 --> 'small';3-5 --> 'medium';'>=5 --> 'large'。2分
numpy:
import numpy as np
import random
outfile=r'E:/PythonFile/venv/ai/iris.txt'
iris_data=np.loadtxt(outfile,dtype=float,skiprows=1,usecols=[1,2,3,4])
x=np.digitize(iris_data[:,2],[0,3,5,10])
y={1:'small',2:'medium',3:'large',4:'np.nan'}
z=[y[i] for i in x]
print(z)pandas:
import pandas as pd
iris_data=pd.read_table("E:/PythonFile/venv/ai/iris.txt",index_col='Id')
result=pd.cut(iris_data.iloc[:,2],[0,3,5,10],labels=['small','medium','large'])13. 在数据集中创建一个新列,其中 volume 是 (pi x petallength x sepallength ^ 2)/ 3。1分
import numpy as np
outfile=r'E:/PythonFile/venv/ai/iris.txt'
iris_data=np.loadtxt(outfile,dtype=float,skiprows=1,usecols=[1,2,3,4])
petallength=iris_data[:,2]
sepallength=iris_data[:,0]
volume=(np.pi*petallength*sepallength**2)/3
volume=volume[:,np.newaxis]
iris_data=np.concatenate([iris_data,volume],axis=1)
iris_data功能:np.newaxis是用来给数组a增加维度的
格式:a[np.newaxis和:的组合],如a[:,np.newaxis],a[np.newaxis, np.newaxis, :]
详解:np.newaxis在[]中第几位,a.shape的第几维就变成1,a的原来的维度依次往后排。
例子:若a.shape=(a ,b, c)
a[:, np.newaxis].shape= (a, 1, b, c)
a[:, np.newaxis, np.newaxis].shape= (a, 1, 1, b, c)
a[np.newaxis, :].shape= (1, a, b, c)
a[np.newaxis, np.newaxis, :].shape= (1, 1, a, b, c)
a[np.newaxis, :, np.newaxis].shape= (1, a, 1, b, c)
a[np.newaxis, :, np.newaxis, :].shape= (1, a, 1, b, c)
14. 随机抽鸢尾属植物的种类,使得Iris-setosa的数量是Iris-versicolor和Iris-virginica数量的两倍。
import numpy as np
import random
specias=np.array(['Iris‐setosa', 'Iris‐versicolor', 'Iris‐virginica'])
specias_out=np.random.choice(specias,p=[0.5,0.25,0.25])
print(np.unique(species_out, return_counts=True))np.random.choice(a, size=None, replace=True, p=None)
a:一维数组或者int型变量,如果是数组,就按照里面的范围来进行采样,如果是单个变量,就对np.arange(a)进行采样。
size:int 或 tuple;可选参数; 确定了输出的shape. 如果给定的是(m, n, k), 那么 m * n * k 个采样点将会被采样. 默认为零,也就是只有一个采样点会被采样回来。
replace : 布尔参数;可选参数 ;决定采样中是否有重复值
p :一维数组;可选参数 ;对应着a中每个采样点的概率分布,如果没有标出,则使用标准分布
 15. 根据 sepallength 列对数据集进行排序。1分
15. 根据 sepallength 列对数据集进行排序。1分
import numpy as np
outfile=r'E:/PythonFile/venv/ai/iris.txt'
iris_data=np.loadtxt(outfile,dtype=float,skiprows=1,usecols=[1,2,3,4])
sepallength=iris_data[:,0]
iris_data[np.argsort(sepallength)]16. 在数据集中找到最常见的花瓣长度值(第3列)。1分
import numpy as np
outfile=r'E:/PythonFile/venv/ai/iris.txt'
iris_data=np.loadtxt(outfile,dtype=float,skiprows=1,usecols=[1,2,3,4])
petalLengt=iris_data[:,2]
val,counts=np.unique(petalLengt,return_counts=True)
print(val[np.argmax(counts)])17. 在数据集的 petalwidth(第4列)中查找第一次出现的值大于1.0的位置。2分
import numpy as np
outfile=r'E:/PythonFile/venv/ai/iris.txt'
iris_data=np.loadtxt(outfile,dtype=float,skiprows=1,usecols=[1,2,3,4])
petalwidth=iris_data[:,3]
index=np.where(petalwidth>1)
print(np.min(index))
#求索引用np.whereimport numpy as np
outfile=r'E:/PythonFile/venv/ai/iris.txt'
iris_data=np.loadtxt(outfile,dtype=object,skiprows=1)
iris_data[:,:1]#取【0,1)数据,切片左闭右开
#iris_data[:,0]取第0列数据














 195
195











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









