







摘要
一些与地理位置相关的业务(如租房业务),会基于地理兴趣点(以下简称POI)去构建,为该地点的用户提供更精细化的服务。
通常一个POI都会有一个官方名称,有的会有别名称呼,例如“北京大学”,又称为“北大”。这些POI点周围的用户通常习惯用别名去进行搜索,如果没有这些别名数据,可能会导致提供给用户的信息有误。因此如何获取现实中地址的别名,并通过别名知识系统服务于业务,就显得很重要。
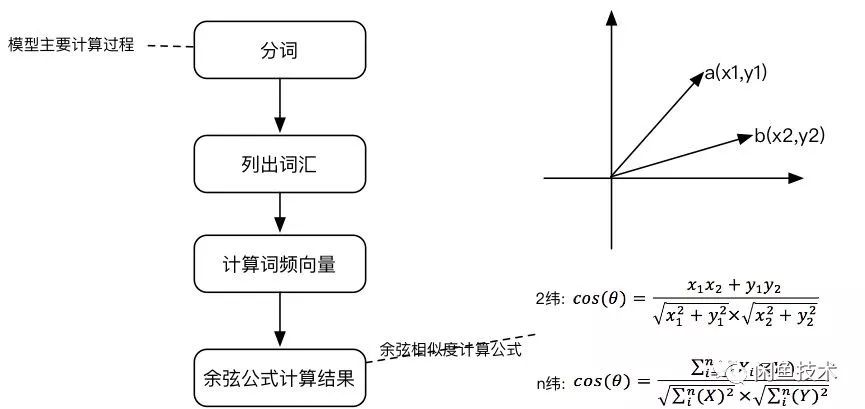
图1:别名生成模型概要图
业界目前还没有公开的地理别名数据信息,有些是通过人工采集,有些通过机器学习或深度学习对别名数据进行挖掘等,成本都比较高。本文另辟蹊径,通过二种方法对地理别名数据进行挖掘:1.基于内容上下文高维向量的别名抓取技术(如图1所示);2. 基于收货地址相同语境词的分析技术。这些方法实现程度相对简捷和高效,成本较低。此外,对挖掘出的别名数据,建立了一套知识库系统,用于支持地理别名数据的使用。
关键词:
地理别名,POI,收货地址,知识库
一. 别名数据的挖掘
1. 根据内容上下文高维向量的别名抓取技术
有图2两个收货地址

图2:收货地址上下文比较
如何判断两个收货地址是否相似,可以通过文本相似性算法进行计算,文本相似性算法有很多,本文选择余弦相似性算法。图3为三角形的余弦函数计算公式<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1343
1343

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









