




 本文介绍了一个使用Python爬虫技术下载必应每日壁纸的实战案例。通过解析网页源代码,利用正则表达式截取大图地址,并通过requests库实现图片的批量下载。代码中详细展示了如何设置User-Agent,处理文件路径,以及异常捕获。
本文介绍了一个使用Python爬虫技术下载必应每日壁纸的实战案例。通过解析网页源代码,利用正则表达式截取大图地址,并通过requests库实现图片的批量下载。代码中详细展示了如何设置User-Agent,处理文件路径,以及异常捕获。
效果图片:


完整代码:
每段代码的功能都有注释
import re
import os
import time
import requests
from bs4 import BeautifulSoup
#获取大图地址并下载
def geturl(url):
user_agent = {'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36'}
rspon = requests.get(url,headers = user_agent) #url这个变量是由函数page()传入
htmltext = rspon.text #网页源代码
list_a = re.findall(r'(?<=pic=).*?(?=\?imageslim)',htmltext) # (?<=)表示开始界定 *?表示最小匹配 (?=)表示结束界定 由于?是系统保留字,所以在?imageslim前加转义符\
#用正则表达式截取【pic=】与【?imageslim】之间的字符,这是图片的地址。 htmltext里面有许多pic=http://h1.ioliu.cn/bing/LakeMoraineVideo_ZH-CN5910090911_1920x1080.jpg?imageslim
#循环保存图片
for L in list_a:
time.sleep(1) #间隔时间1秒
filename = L.split('/')[-1] #以‘/’为分隔进行切片,取右边第1组字符,用作图片的文件名
savepath = 'd://pyimg2//' #保存路径
imgname = savepath + filename #文件名
try:
if not os.path.exists (savepath): #如果目录不存在
os.mkdir (savepath) #创建目录
if not os.path.exists (imgname): #文件名不存在,才进行下载
r = requests.get(L,headers = user_agent) #请求图片地址
with open(imgname ,'wb') as f: #打开文件 , wb表示二进制
f.write(r.content) #写入文件
print(L + ' 下载完成')
except:
print('保存出错了')
#定义下载页面函数
def page():
s = int(input('请输入开始页码:'))
e = int(input('请输入结束页码:'))
#循环调用 geturl函数
for i in range(e-s+1):
geturl('https://bing.ioliu.cn/?p=%d'%(s)) #调用函数geturl(url) ,传入参数是页面的网址
s = s + 1
if __name__ == '__main__':
page() #调用page()函数
网页分析
每页有12张小图 ,https://bing.ioliu.cn/?p=3 这个数字代表第3页
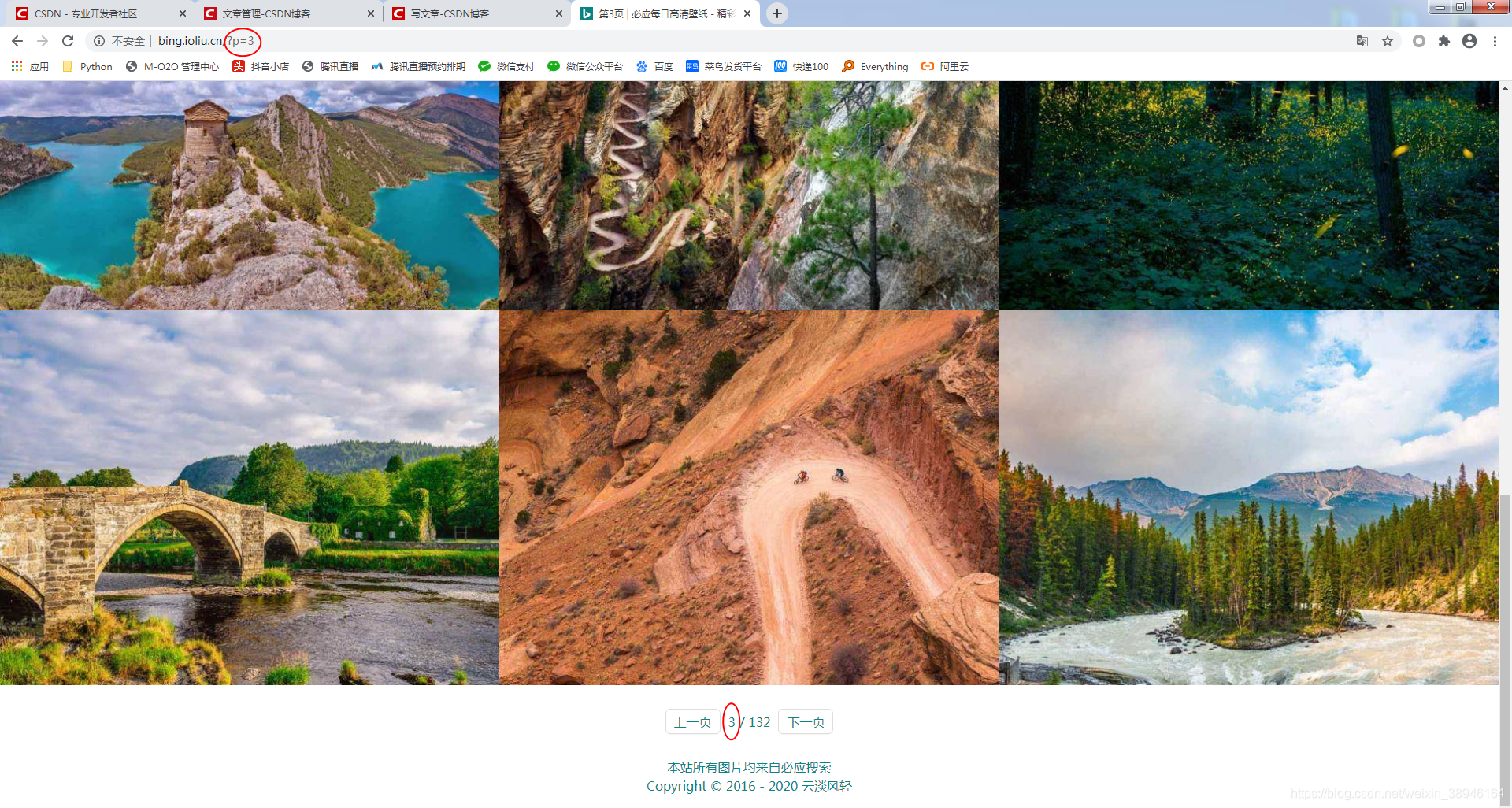
用变量s代表页码

查找大图的下载地址
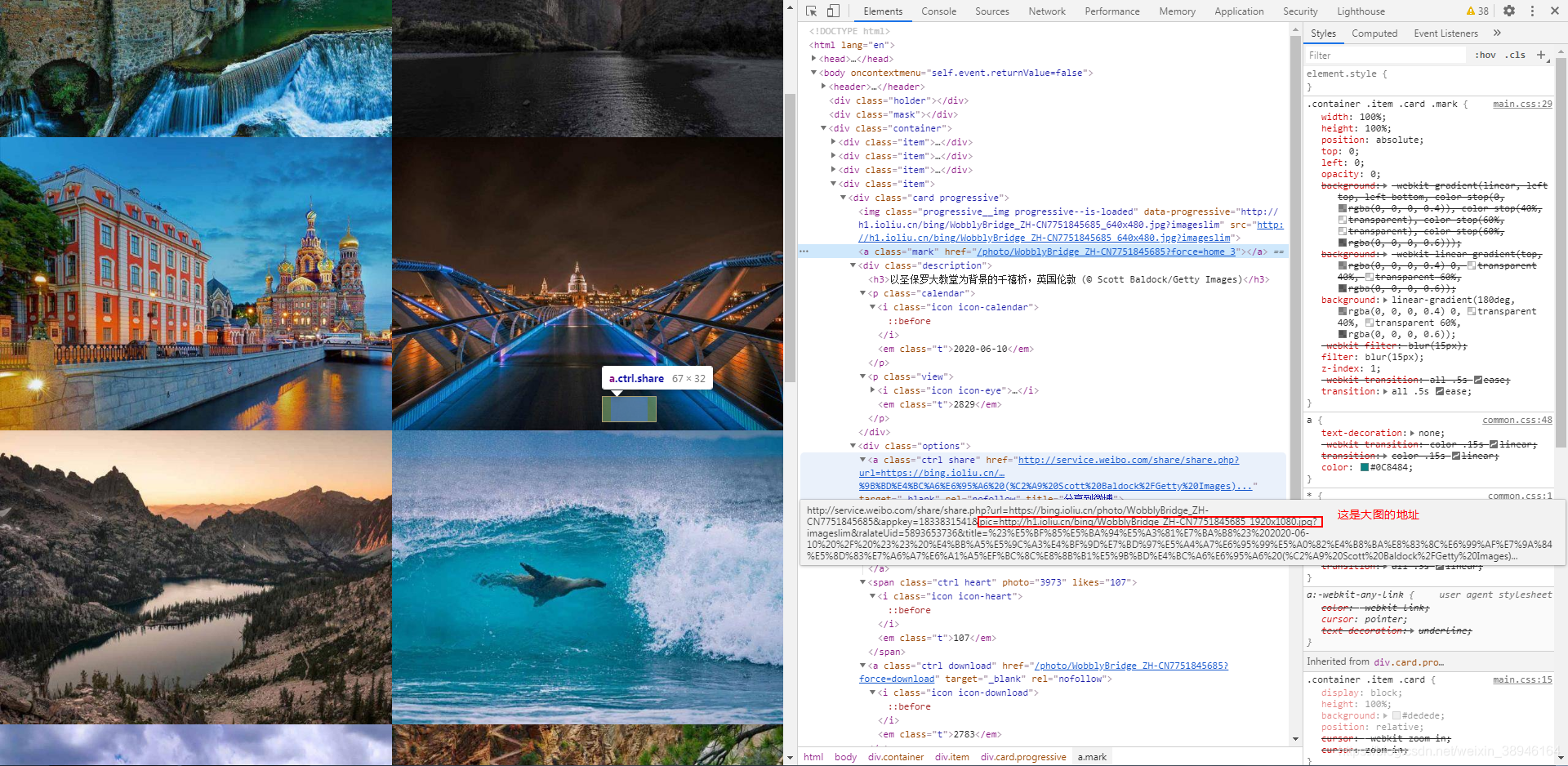

用正则表达式截取网址是重点,也是难点,具体内容要查看 re正则表达式 教程
https://blog.csdn.net/Eastmount/article/details/51082253


















 2207
2207

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









