






前言:本文通俗易懂地介绍了 Prometheus 标签,并且直击用户痛点,提供避坑指南。以下内容由腾讯云 Prometheus 团队雷畅、徐帅、赵志勇共同创作。
用 Prometheus 监控一个指标,总共分几步?
-
找服务发现拉清单,搞清楚要监控的对象(targets)。
-
定期找各个 target 采集数据样本(samples),塞进时序数据库(本地 or 远程)。
-
把 samples 从数据库里捞出来用:摆上时间轴能做仪表盘;配进告警规则能发告警。
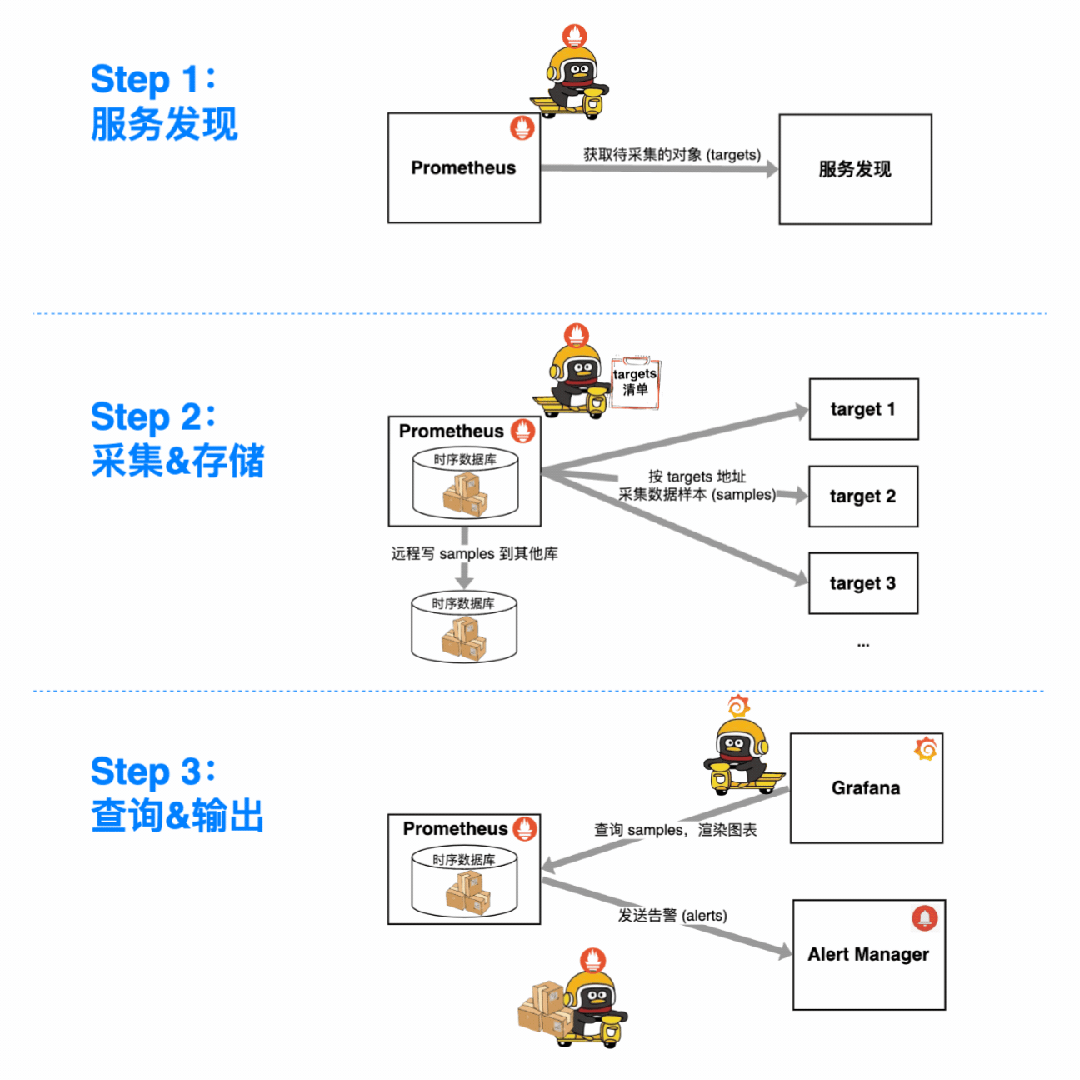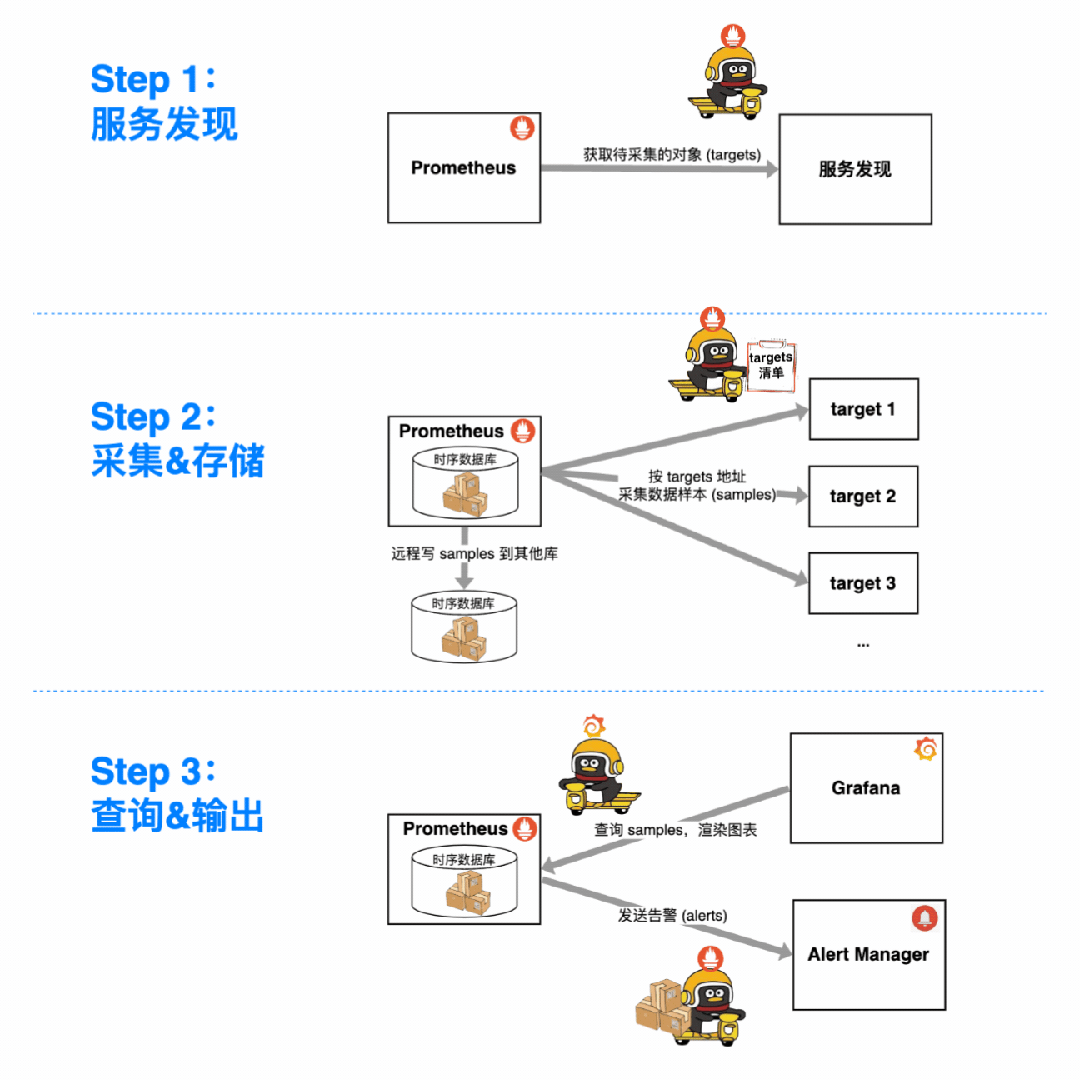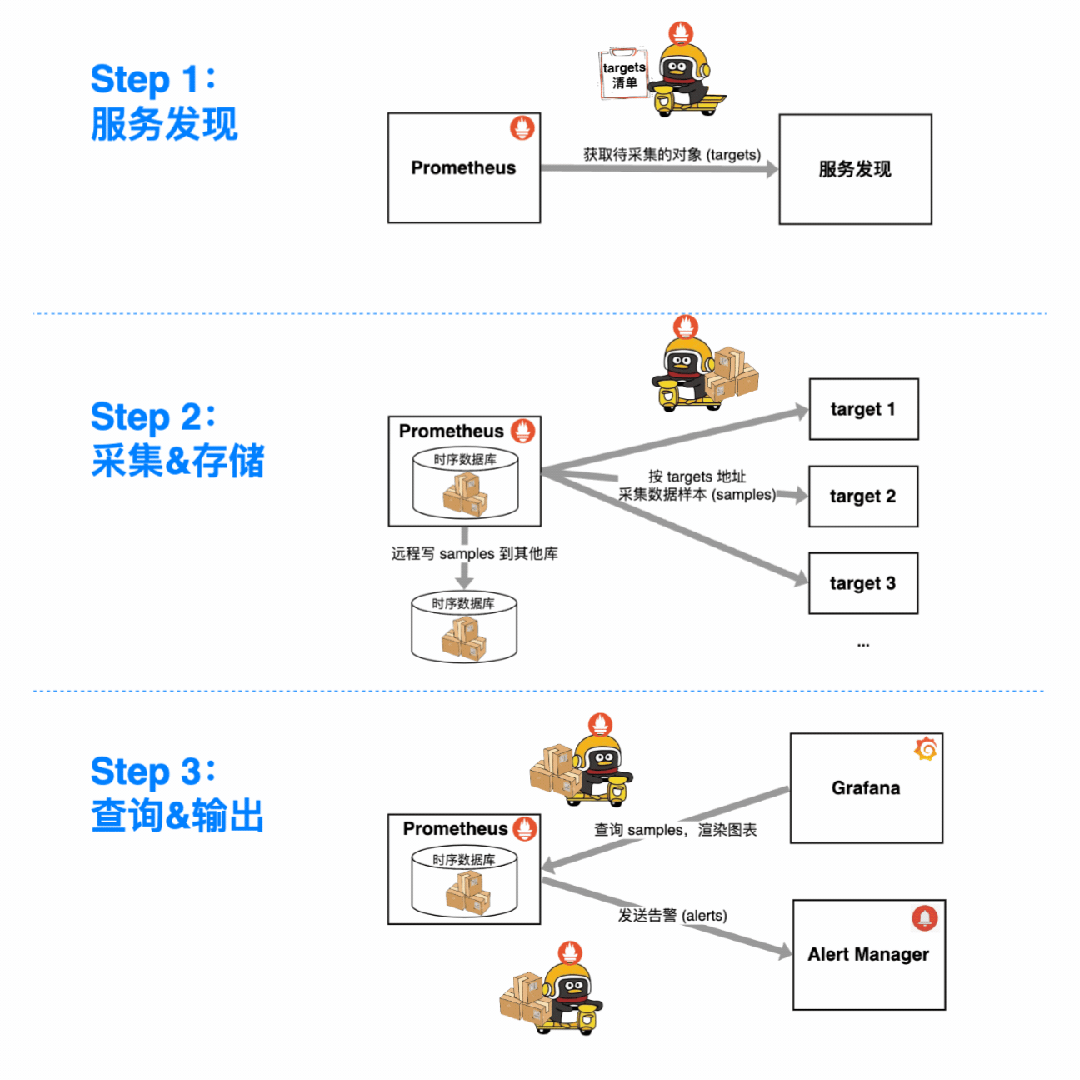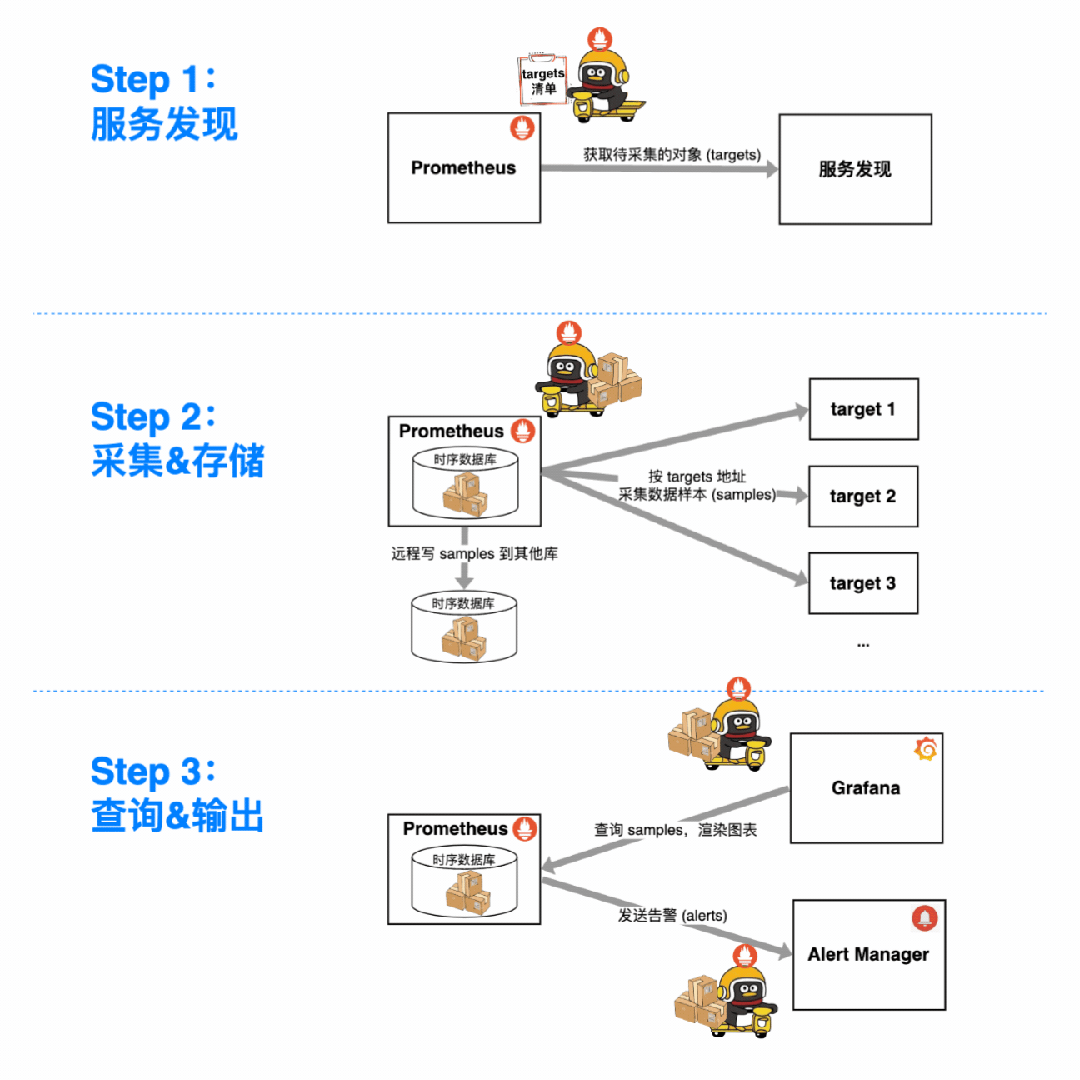
那么问题来了:这些来自四面八方、所属的对象和指标各不相同的 samples,是如何被 Prometheus 分类存储、灵活聚合,供我们花式查询、观察/告警的呢?
这就不得不提 Prometheus 数据的灵魂元素——标签(labels)了。
接下来,本文将:
-
围绕指标生命周期,以深入浅出、看图说话的形式,揭示标签是如何为指标“注入灵魂”的。
-
针对 Prometheus 标签相关的典型问题、和腾讯云 Prometheus 客户的常见痛点,提供避坑实践和解决方案,助您充分享用 Prometheus 的强大功能,实现高效、精准的监控。
核心通识
首先,简要回顾与指标相关的冷/热知识,以便沉浸式 Get 标签的重要意义。
标签起源
抛开现有的监控方案不谈,我想自己设计一个监控系统,该如何建模指标呢?
比如想监控主机的“CPU 使用时间”,这就意味着:
-
我的监控对象:主机。
-
在监控对象身上,我关心的特征维度:CPU 使用时间(不妨叫它
cpu_seconds_total)。
那如果我有两台名为 foo、bar 的主机,该如何区分它俩各自的 cpu_seconds_total?

拍脑袋第一直觉:取个全局唯一的字符串,比如将主机名 foo / bar ,与狭义的指标名 cpu_seconds_total 拼接在一起,能分类存/取、别搞混就行了。
巧了,这正是老一辈监控系统的做法(如 Graphite、Collectd 等)。例如,创建这俩指标,简单粗暴直观:
host_foo_cpu_seconds_total
host_bar_cpu_seconds_total
那如果我的主机不仅有主机名(foo、bar),还存在着地域维度(北京、上海)、环境维度(生产、测试)呢?
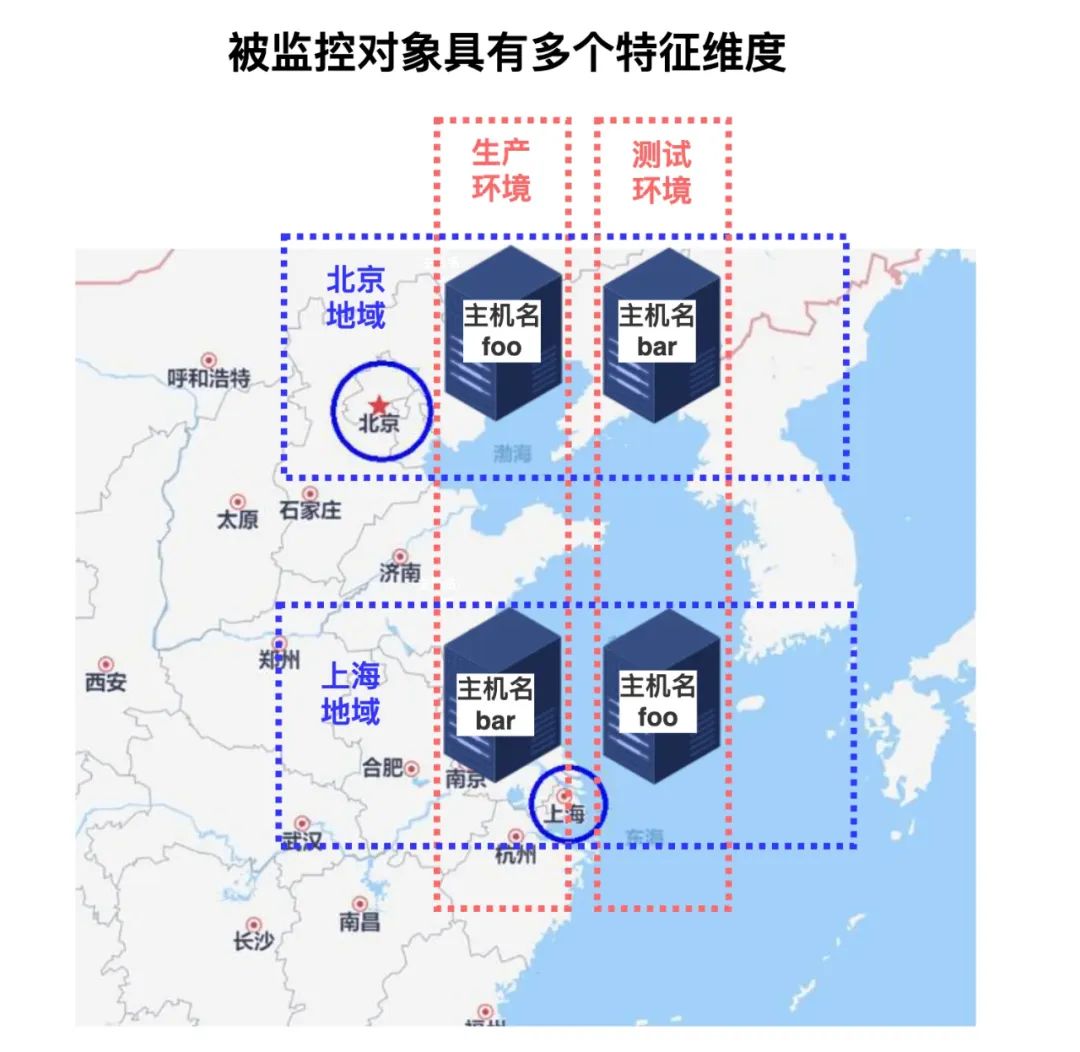
也没关系,一把梭把所有特征拼接在同一个维度里,作为指标名就行了:

但是,如果我查询的时候,并不关心某一台主机,而是想要排列组合、花式聚合呢:
-
所有生产环境的主机的 CPU 使用时间
-
所有北京地域的主机的 CPU 使用时间之和
-
所有生产环境且在北京地域的主机的 CPU 使用时间的平均数
-
……
有正则匹配,问题仍然不大:先用 prod、foo 等关键字,正则匹配出想要的指标名,分别拉取它们的监控数据;然后就能直接观察,或者聚合出总数/平均值等。
那如果我监控的不是主机,而是应用层的、维度爆炸多的对象呢?例如:web 服务的 HTTP 请求,其特征维度可能包括:环境、地域、主机名、HTTP 方法、HTTP 状态码……等等。
更进一步,当我采用了云原生环境、微服务架构,我的基础设施规模更大、应用实例数量更多,还会时不时因动态扩缩容而销毁重建、因动态调度而在底层资源间漂移……此时的被监控对象,其特征维度将更加复杂、动态、多变。
例如:下图中 web 服务的请求时延,10+个特征维度,指标名大概要叫 shanghai-foo-test-stable-job-1-200-pod-0-main-80-http-svc-1-ins-1-duration-seconds,查询时再做正则匹配?
此外,像 pod ID、容器名称这样,在云原生环境中动态多变的值,还适合拼接在指标名里吗?……
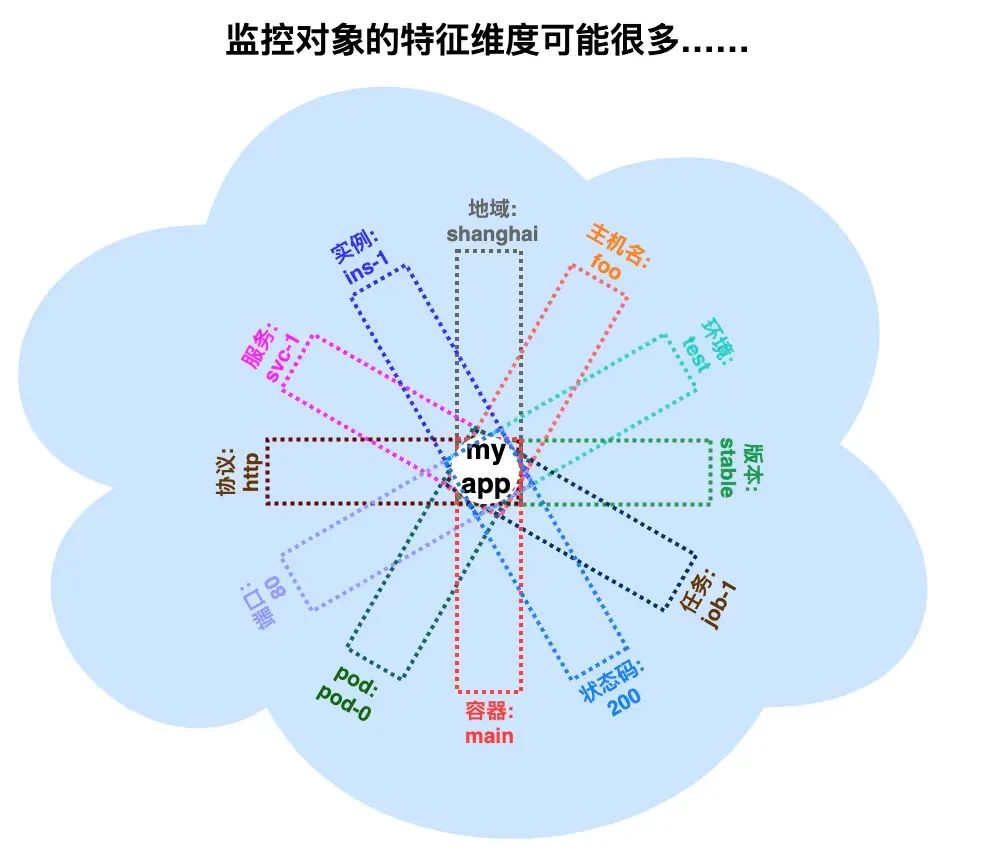
可见,在云原生时代,被监控的对象的特征维度不仅多,还易变。如果仍将它们塌缩在一维的指标名里,不仅指标名可读性差、存储效率低;更要命的是,想要灵活聚合查询,也异常麻烦、异常低效。
为了解决进入云原生、微服务时代后,被监控对象的特征维度多、且动态性飙升的问题,2010 年 OpenTSDB(一款时序数据库)率先引入标签,来灵活定义多种维度特征;2012 年 Google 开源的监控系统 Borgmon 也引入了标签;Prometheus 则受 Borgmon 启发,允许为指标添加多个标签。
因此,我们可以说,Prometheus 的标签不仅仅是一种 metadata 信息,它还是一种 architecture 结构。正是这种结构,支撑起了一维指标名之外的更多维度,才使得指标的定义、存储、查询,拥有了前所未有的灵活性。
在下面的部分,我们将围绕 Prometheus 指标的数据模型和生命周期,详细说明这一点。
数据模型
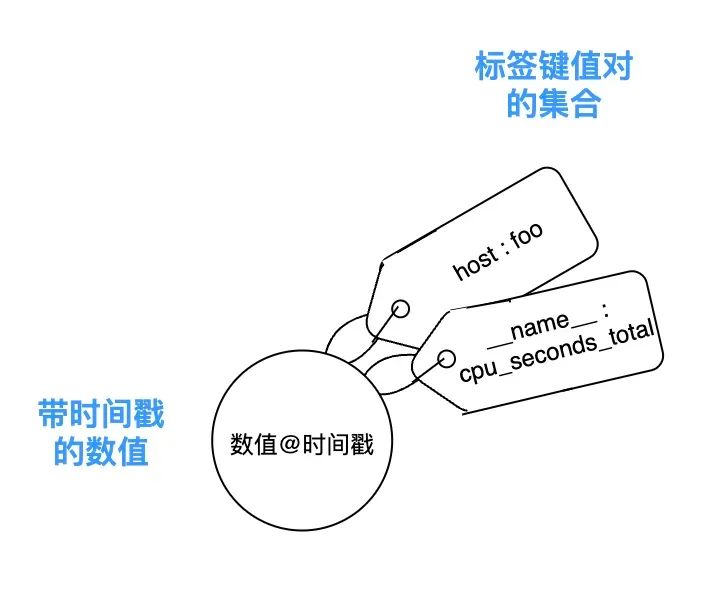
在 Prometheus 的模型里,指标数据流转的基本单位,是数据样本(sample)。一个数据样本由唯一性标识 identifier(指标名+标签键值对集合)、value(数值)、timestamp(时间戳) 组成:
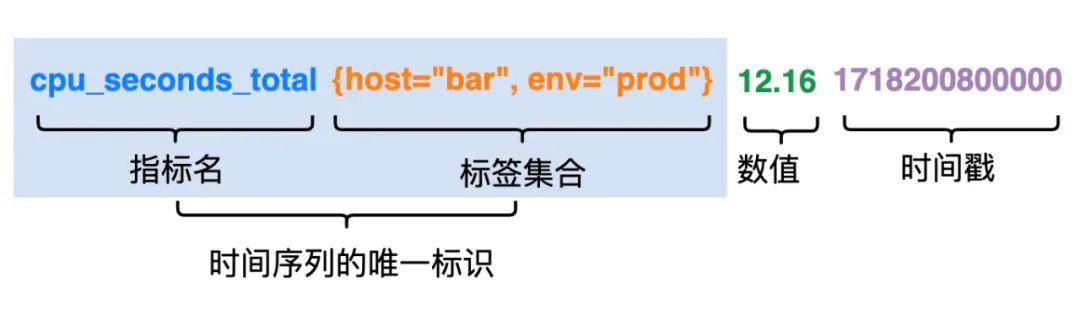
(顺便一提:在 Prometheus 里,指标名也是一种标签:名为 __name__ 的内部标签。例如 cpu_seconds_total{host="bar", env="prod"},在 Prometheus 视角里,它实际上是{__name__="cpu_seconds_total", host="bar", env="prod"}。)
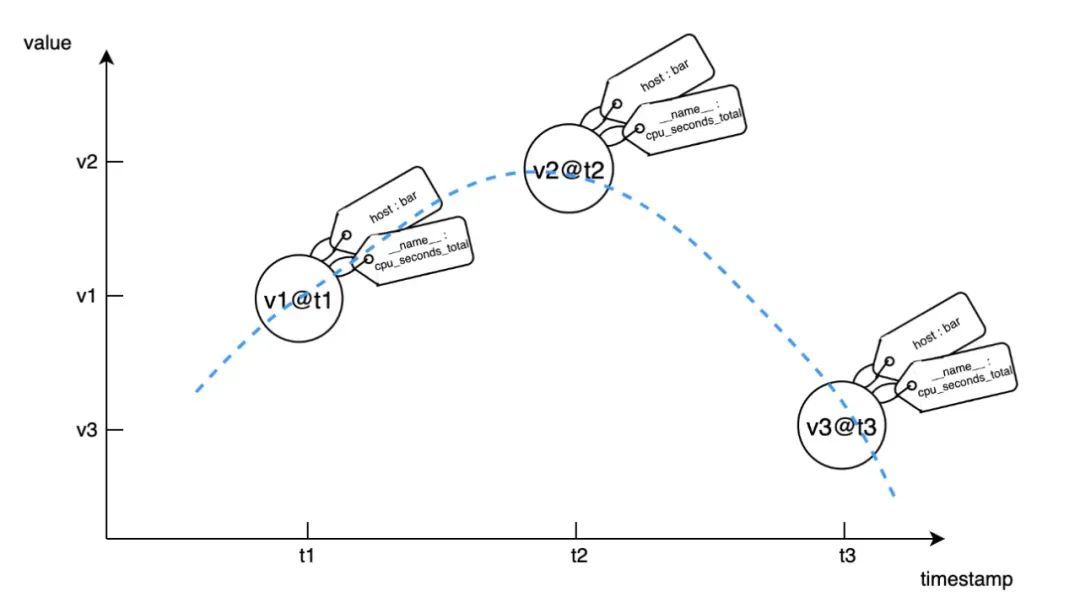
由归属于同一个指标名 + 同一组标签键值对、携带着在不同时刻被采集到的不同数值,这样的一系列数据样本所组成的数据流,就是时间序列。
时间序列可以理解为是对指标的具体实现,两者具有如下对应关系:
-
用来唯一标识一个指标的,是指标名+维度集合。
-
用来唯一标识一个时间序列,是指标名+一组标签键值对(对上述维度集合赋了具体值后形成的键值对)的集合。
以 cpu_seconds_total{host="bar"} 为例,它的一个数据样本示意如下:
若将这些点摆在时间-数值的坐标轴上,可以这样示意时间序列:
对比老一代监控系统的数据模型,当我们用了 Prometheus,原本名字冗长、且难以聚合查询的指标,则可以被建模成以下示例形式:
-
指标定义:指标名
cpu_seconds_total,维度host、 env 、region。 -
时间序列:
cpu_seconds_total{host="foo", env="prod", region="beijing"} -
聚合查询:
sum(cpu_seconds_total{env="prod", region="beijing"})
显然,像 Prometheus 这样基于标签建模多维指标,就具备了更强的灵活性和查询能力:

这得益于标签提供的分类结构和检索方法:通过为数据对象贴上多个标签,可以非常灵活地将一个对象归类到多个分类中,而不是固定在一个层级结构的单一路径上。这样,数据的检索和组织将更加灵活和多维度,也更容易适应变化。
生命周期
在这一部分,我们探究在 Prometheus 指标的整个生命周期里,标签是如何“串场”,将数据流转的整个过程串联起来的。
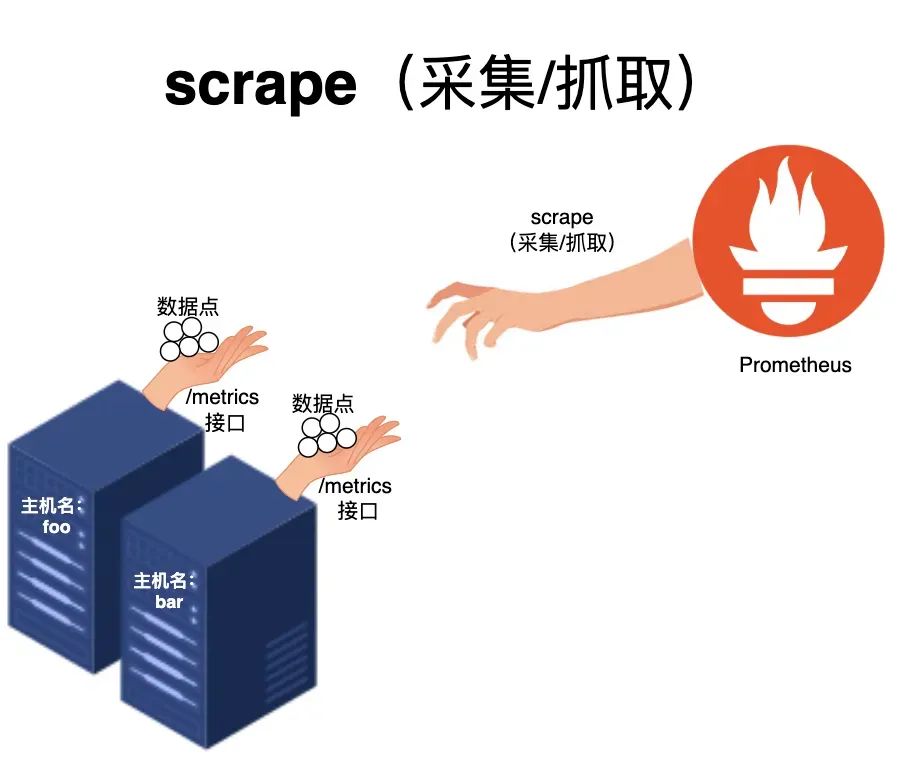
一、采集
数据样本的来源,是 Prometheus 按照自身配置,从被监控对象所暴露的指标端点(一般为 HTTP /metrics),周期性地采集而来:
二、存储
采集到数据点之后,Prometheus 会把数据点存储下来。Prometheus 内部使用基于时间序列的存储引擎,将数据存储在磁盘上的块文件(block)中,每个块文件包含一段时间内(默认是2小时)的所有数据,包括每个时间序列的:
-
元数据:主要是基于标签(含指标名标签
__name__)的倒排索引,用于快速查找具有特定标签的时间序列。 -
数据点/样本点:如上文所述,时间序列的每个数据点,都包含一个时间戳和对应的值。
Prometheus 的块文件存储的数据示意如下:

三、查询
在查询阶段,每当用户发出一个 PromQL 查询,Prometheus 便会执行基于标签的查询步骤。
例如:我们有一个 PromQL 是sum(rate(cpu_seconds_total{env="prod", region="beijing"}[5m])),用于计算 env="prod", region="beijing" 的主机的 CPU 使用时间的速率,并对其进行求和,查询的时间范围是过去 5 分钟。
其执行步骤如下:
-
解析查询:Prometheus 首先解析 PromQL 查询语法,生成查询计划。它会识别出查询中的函数
rate和聚合操作sum,以及标签选择器env="prod", region="beijing"和时间范围[5m]。 -
标签匹配:Prometheus 根据标签选择器
env="prod", region="beijing",从存储中找到所有匹配的时间序列。例如,假设我们有以下匹配的时间序列:
-
cpu_seconds_total{host="foo", env="prod", region="beijing"} -
cpu_seconds_total{host="bar", env="prod", region="beijing"}
-
数据检索:在这一步,Prometheus 会从匹配的时间序列中检索所需的样本数据。具体来说,它会从
cpu_seconds_total{host="foo", env="prod", region="beijing"}和cpu_seconds_total{host="bar", env="prod", region="beijing"这两个时间序列中提取过去 5 分钟内的样本点。
假设 cpu_seconds_total{host="foo", env="prod", region="beijing"} 在过去 5 分钟内的样本数据如下:
-
时间戳:10:00,值:100
-
时间戳:10:01,值:105 -
时间戳:10:02,值:110 -
时间戳:10:03,值:115 -
时间戳:10:04,值:120
同样,cpu_seconds_total{host="bar", env="prod", region="beijing"} 在过去 5 分钟内的样本数据如下:
-
时间戳:10:00,值:200 -
时间戳:10:01,值:205 -
时间戳:10:02,值:210 -
时间戳:10:03,值:215 -
时间戳:10:04,值:220
Prometheus 会从存储中读取这些样本数据,以便在后续步骤中进行计算。
-
聚合计算:在数据检索完成后,Prometheus 会根据查询中的聚合操作,对样本数据进行计算。在这个例子中,首先会计算每个时间序列的速率(
rate),然后对速率进行求和(sum)。
例如,计算 cpu_seconds_total{host="foo", env="prod", region="beijing"} 的速率:
-
rate(cpu_seconds_total{host="foo", env="prod", region="beijing"}[5m])
计算 cpu_seconds_total{host="bar", env="prod", region="beijing" 的速率:
-
rate(cpu_seconds_total{host="bar", env="prod", region="beijing"}[5m])
然后对这两个速率进行求和:
-
sum(rate(cpu_seconds_total{env="prod", region="beijing"}[5m]))
-
返回结果:最后,Prometheus 将计算结果返回给用户,用作可视化或者告警。


可见,在指标数据的整个生命周期中,标签起着至关重要的作用:
-
在数据采集阶段,标签提供了必要的标识和区分机制。
-
在数据存储阶段,标签帮助进行有效的分类和索引,从而优化存储结构。
-
在数据查询阶段,标签作为查询参数,使得检索更加精确和高效。
技术揭秘
在这一部分,我们将探讨 Prometheus 标签的内容是从哪儿来、到哪儿去,以及在哪些环节允许通过重新打标(relabel),供我们来做“魔改”。
标签来源
前文提过,Prometheus 的标签既是一种 architecture 结构,又携带了 metadata 信息。
它作为 architecture,承载着时间序列的标识区分/存储索引/查询参数等功能,已在前文核心通识部分做过介绍;而它作为 metadata,则承载着时间序列的元数据、上下文,使得 value@timestamp 不仅仅是一个裸露的数值,而是一个富有信息的、可查询的数据样本点。
那么,每个 Prometheus 标签的 key-value 键值对的内容,又是从哪里来的呢?
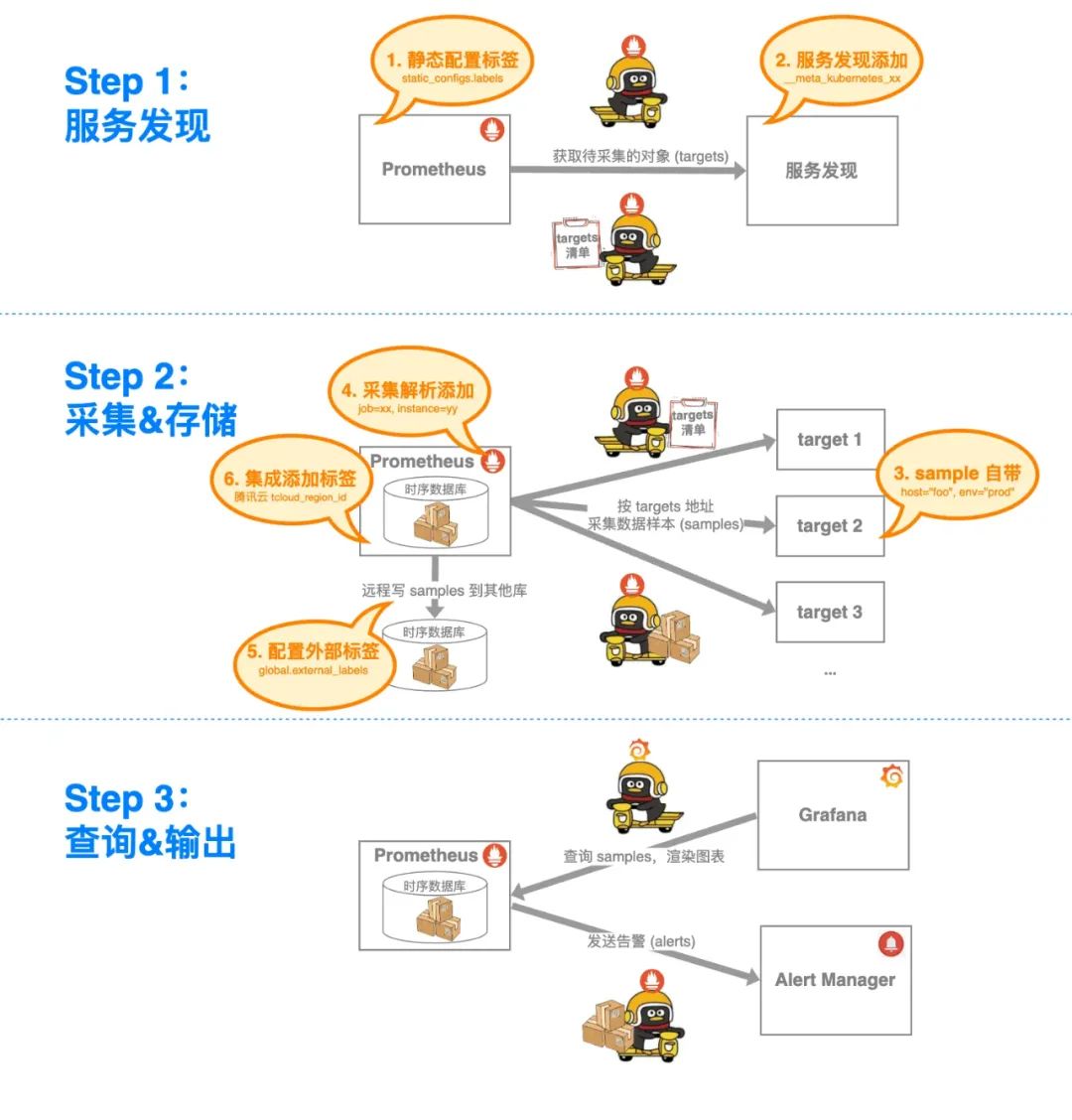
如下图所示:
-
从来源主体上看,它可能来自用户手工配置、系统自动添加、采集样本携带。
-
从生命周期上看,它可能来自于从静态配置、到服务发现、采集解析,再到外部交互的各个环节。
1. 静态配置
用户可在采集配置中,使用 scrape_configs.static_config,为特定的 target 自行添加标签。
这样给来自特定 target 的指标数据,提供额外的上下文信息(如服务名称、环境、版本等),有助于在查询和聚合数据时,进行更细致的分析。
例如,为某个 target 静态配置 env 和 region 标签:
scrape_configs:
- job_name: 'test'
static_configs:
- targets: ['localhost:8080']
labels:
env: 'production'
region: 'ap-shanghai'2. 服务发现
Prometheus 支持多种服务发现机制(如 Kubernetes、Consul、EC2 等)。
服务发现机制可以自动发现 target。并且,Prometheus 会自动从服务发现源(如 Kubernetes 集群)获取关于每个 target 的元数据,并基于这些元数据,自动生成标签。
例如,使用 Kubernetes 做服务发现时,通过 kubernetes_sd_configs 配置项指定监控的角色为 pod,Prometheus 会监控集群中的所有 pod,收集与这些 pod 相关的指标:
scrape_configs:
- job_name: 'test'
kubernetes_sd_configs:
- role: pod每个角色会自动附带一些基本的标签(如 pod 名称、节点 IP 等),这些标签在 Prometheus 收集数据时被附加到指标上,如 __meta_kubernetes_pod_name(Pod 的名称)、__meta_kubernetes_pod_node_name(运行该 Pod 的节点名称)、__meta_kubernetes_pod_ip(Pod 的 IP 地址)。
这些标签使得用户在查询和分析监控数据时,能够按照具体的服务、节点或其他关键属性来过滤和定位信息,大大增强了 Prometheus 在 Kubernetes 环境中的监控能力。
3. sample 自带
一些 target 会在其 /metrics 端点上,直接暴露带有标签的指标数据。在下面的示例中,method 和 handler 标签是由目标端点直接暴露的。
http_requests_total{method="GET", handler="/api/v1"} 1234. 采集解析
当 Prometheus 抓取 target 的指标时,它会自动添加一些 Prometheus 内置的系统标签、以及系统指标。
-
添加系统标签,有助于识别和区分抓取的数据:
-
job: 其值来自配置文件中定义的job_name,用于区分来自不同 job 的指标,特别是当多个 job 可能抓取相同 target 时。 -
instance:默认情况下,这个标签包含 target 的<host>:<port>,用于标识具体的被监控实例。这对于区分同一 job 下的不同实例非常有用。 -
添加系统指标,提供关于抓取本身的信息:
-
up: 这个指标表明抓取操作是否成功。如果最近的抓取成功,up的值为 1;如果失败,值为 0。 -
scrape_duration_seconds: 这个指标显示了抓取操作所花费的时间(秒)。它有助于监控 Prometheus 抓取的性能。 -
scrape_samples_scraped:这个指标代表 target 暴露出来的 sample 数量,可用于查看采集到的数据量。 -
scrape_samples_post_metric_relabeling:这个指标代表 relabel 应用之后,剩余的 sample 数量,可用于查看写入到存储的数据量。
5. 外部标签
是一种在 Prometheus 级别定义的标签,用于在数据发送到外部系统时,提供额外的上下文信息,对于在复杂的监控架构中管理和区分数据来源非常有用。
-
目的:用于在 Prometheus 向外部系统(如远程存储、另一个 Prometheus 服务器、Alertmanager)发送数据时,标识和区分来自不同 Prometheus 实例的数据,如
cluster或region标签。 -
用法:配置在
global.external_labels字段。用户可以指定任何键值对作为外部标签,这些标签将应用于所有由该 Prometheus 实例抓取的指标数据,并在数据离开 Prometheus 实例时被添加。
例如,这两个外部标签 monitor 和 team,将被添加到从该 Prometheus 实例发送到任何外部系统的所有指标数据中:
global:
external_labels:
monitor: 'my-monitor'
team: 'my-team'PS:由于外部标签并不直接存储在本地时序数据库中,所以它只影响外部数据流,不影响本地 PromQL 查询。
6. 跨系统集成
-
远程存储和集成:如果 Prometheus 将数据发送到远程存储或其他监控系统,这些系统可能会在接收数据时,添加额外的系统级标签,以识别和分类数据。
-
云服务提供商的自定义集成:在使用特定云服务提供商的监控服务时,这些服务可能会自动添加与云环境相关的标签,以便更好地集成和利用云平台的特性。(例如:腾讯云 Prometheus 会自动添加指标存储所在的腾讯云地域信息
tcloud_region_name、tcloud_region_id)
重新打标
尽管标签已经非常灵活、丰富,有时我们可能需要进一步优化数据,这时重新打标(relabel) 就派上用场了。
relabel 是 Prometheus 中一个非常强大的功能,它允许用户配置 relabel 规则,以在数据采集、存储、发送时修改标签,其目的一般是标准化标签、过滤数据、重命名标签、或者生成动态标签。这样,用户就能灵活控制和优化标签,从而满足不同的监控需求,以及简化配置、方便管理。
在 Prometheus 中,relabel 可以在多个阶段进行,每个阶段的 relabel 应用不同的上下文、满足不同的需求。
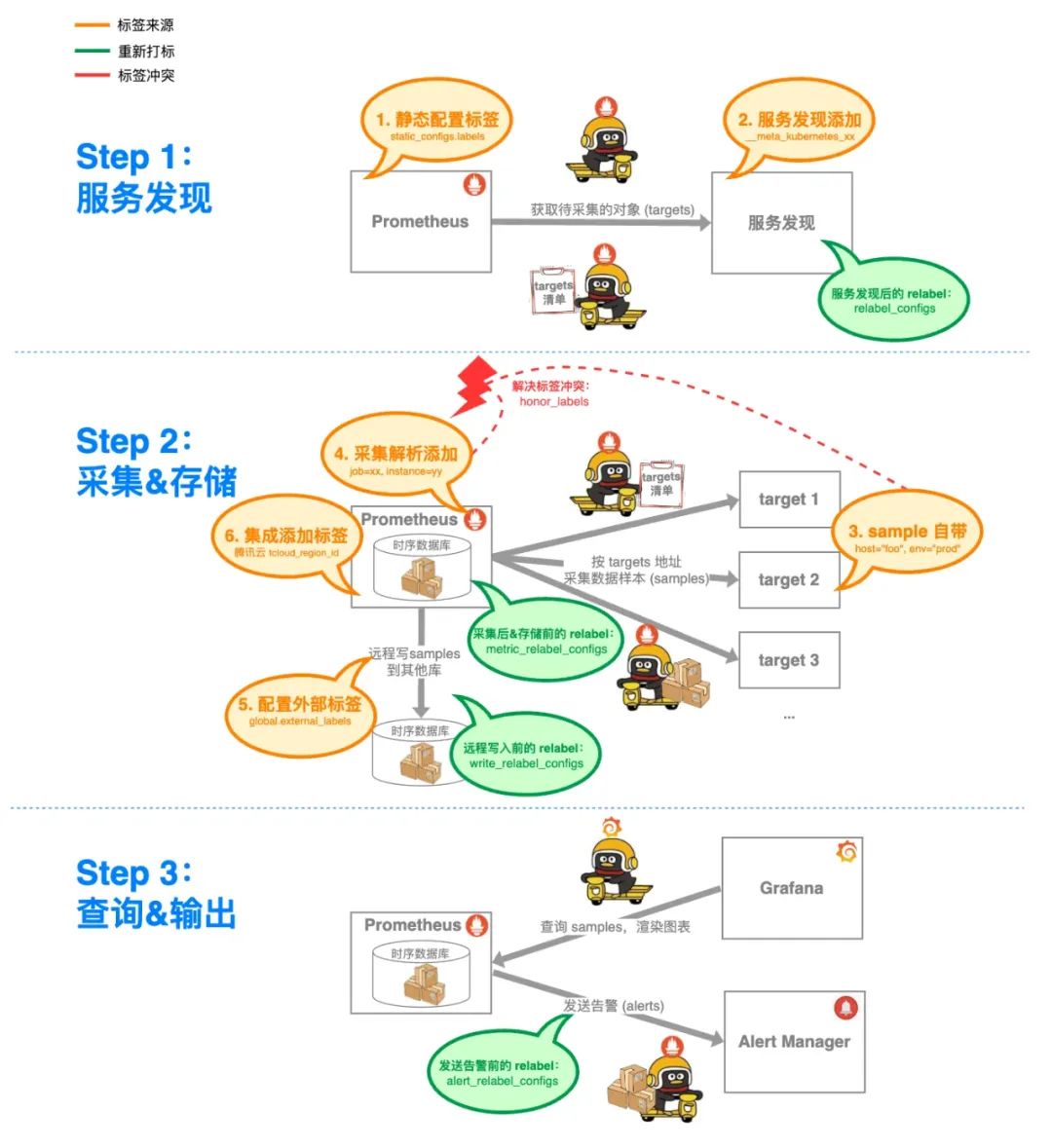
仍然看这张生命周期图,relabel 可以发生在绿色圈圈的阶段:
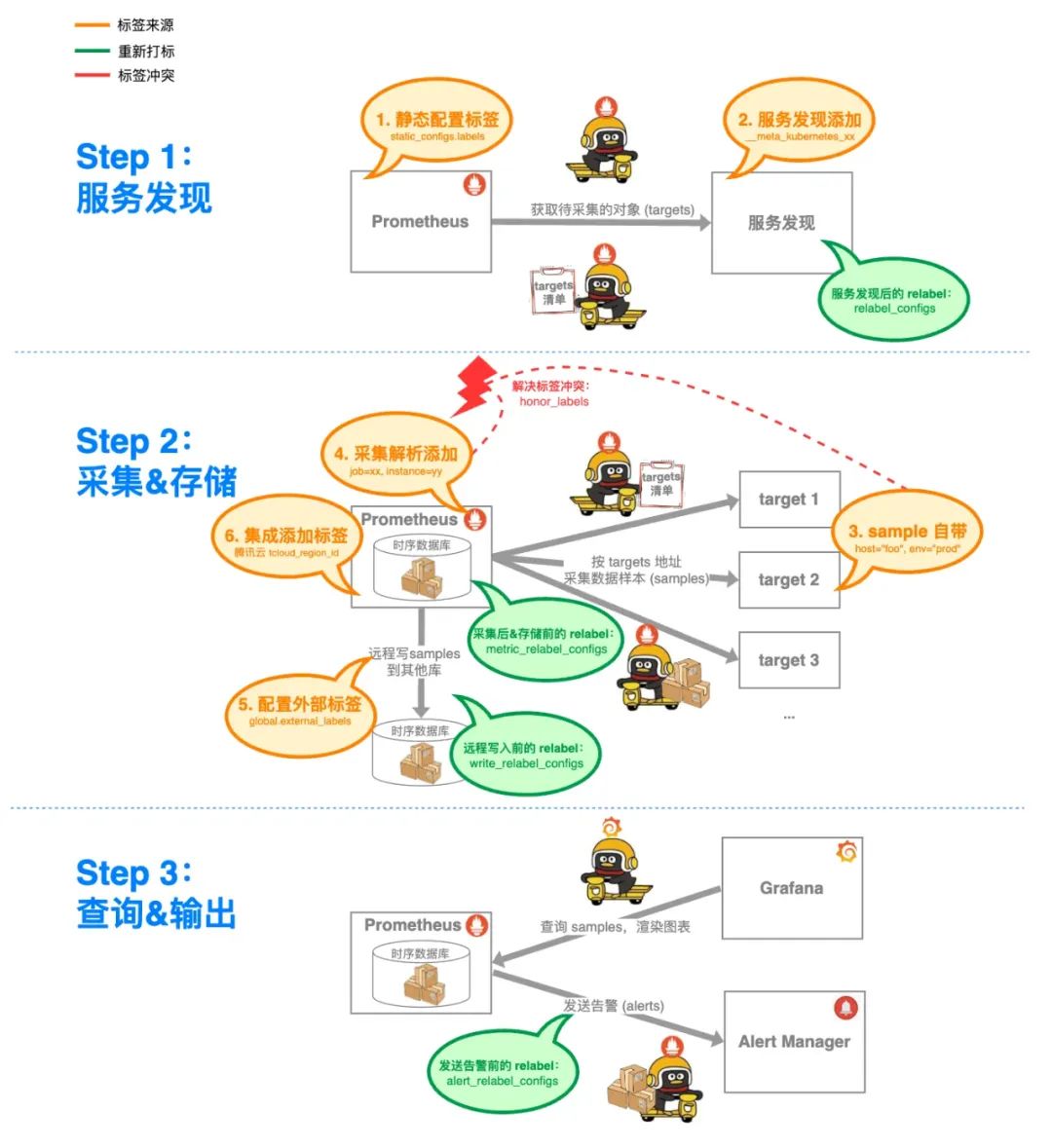
具体到采集配置里,对应的是这些字段:
# 采集配置
scrape_configs:
- job_name: "test"
...
# 针对 target 的 relabel 配置;应用在服务发现之后、采集之前
relabel_configs:
[ - <relabel_config> ... ]
# 针对 metric 的 relabel 配置;应用在采集之后、存储之前
metric_relabel_configs:
[ - <relabel_config> ... ]
# 与远程写入有关的配置
remote_write:
url: [https://remote-write-endpoint.com/api/v1/push](https://remote-write-endpoint.com/api/v1/push)
...
# 针对远程写入的 relabel 配置;应用在存储之后、远程写入之前
write_relabel_configs:
[ - <relabel_config> ... ]
# 与发送告警有关的配置
alerting:
# 针对告警的 relabel 配置;应用在存储之后、发送告警之前
alert_relabel_configs:
[ - <relabel_config> ... ]<relabel_config> 中的每条规则,可以包含以下字段,来表达 relabel 时的语义:
-
source_labels:要匹配的源标签。 -
regex:用于匹配source_labels的正则表达式。 -
target_label:要修改或生成的标签。 -
replacement:用于替换匹配结果的字符串。 -
action:操作类型(如replace、keep、drop等)。
具体来讲,在各个阶段进行 relabel 的场景和用法如下:
1. 服务发现阶段
Prometheus 从服务发现机制获取targets后,可以在 scrape_config.relabel_configs 中配置 relabel 规则,以修改 target 标签、过滤 target、或生成新的标签:
-
针对的是 target。
-
应用在服务发现之后、采集之前。
-
只能访问和操纵基于服务发现而添加的标签(例如:过滤由服务发现返回的 target、操纵基于服务发现为 target 打的标签)。
例如,我们想从服务发现生成的 __address__标签中提取主机名,并将其存储在一个名为 hostname 的新标签中,可以配置如下:
scrape_configs:
- job_name: 'example'
static_configs:
- targets: ['localhost:8080']
relabel_configs:
- source_labels: [__address__]
regex: "([^:]+):.*"
target_label: hostname
replacement: "$1"2. 采集阶段
Prometheus 从目标抓取指标后,可根据 scrape_config.metric_relabel_configs 中配置的规则,修改指标的标签、过滤指标或生成新的标签。修改后的指标用于存储和后续查询。
-
针对的是 metric。
-
应用在采集之后、存储之前。
-
可用于选择哪些时间序列的数据被存储到 Prometheus。
例如,从 Prometheus 抓取的数据中,删除名为 http_requests_total 的指标:
scrape_configs:
- job_name: 'example'
static_configs:
- targets: ['localhost:8080']
metric_relabel_configs:
- source_labels: [__name__]
regex: "http_requests_total"
action: drop3. 远程写入阶段
Prometheus在将指标写入远程存储之前,应用 remote_write.write_relabel_configs中配置的规则,修改指标的标签、过滤指标或生成新的标签。修改后的指标被写入远程存储。
remote_write.write_relabel_configs 里配置的 relabel 规则:
-
针对的是 remote write。
-
应用在存储之后、发送到远程端点之前。
-
可用于过滤指标,或将指标路由到特定的远程写入目标。
例如,将所有以 system_ 开头的指标发送到 remote-storage-1,而所有以 app_ 开头的指标发送到 remote-storage-2:
remote_write:
- url: "[http://remote-storage-1.example.com/api/write"](http://remote-storage-1.example.com/api/write)
write_relabel_configs:
- source_labels: [__name__]
regex: 'system_.*'
action: keep
- url: "[http://remote-storage-2.example.com/api/write"](http://remote-storage-2.example.com/api/write)
write_relabel_configs:
- source_labels: [__name__]
regex: 'app_.*'
action: keep4. 告警阶段
alerting.alert_relabel_configs 用于对警报标签进行修改或过滤,以在警报被发送出去之前,对其进行最后一步的标签重写或选择性过滤。
-
针对的是告警。
-
应用在存储之后、发送告警到 alert manager 之前。
例如,在发送到 Alertmanager 之前,从所有警报中删除 instance 标签:
alerting:
alert_relabel_configs:
- source_labels: [instance]
action: labeldrop避坑实战
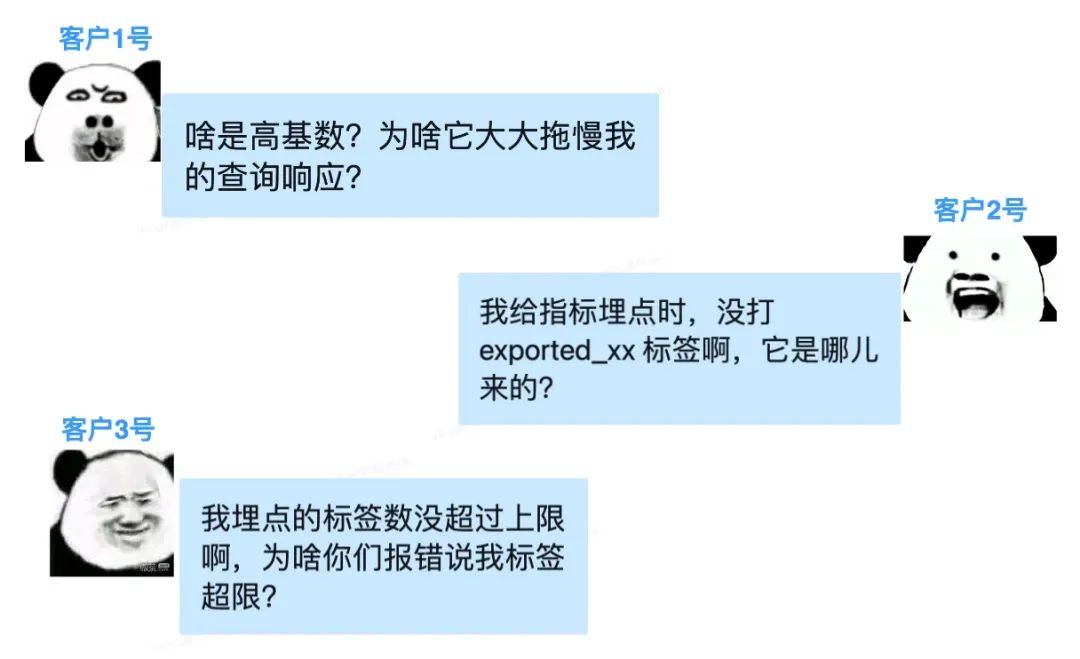
在日常工作中,我们腾讯云 Prometheus 团队经常受到来自客户的灵魂拷问:
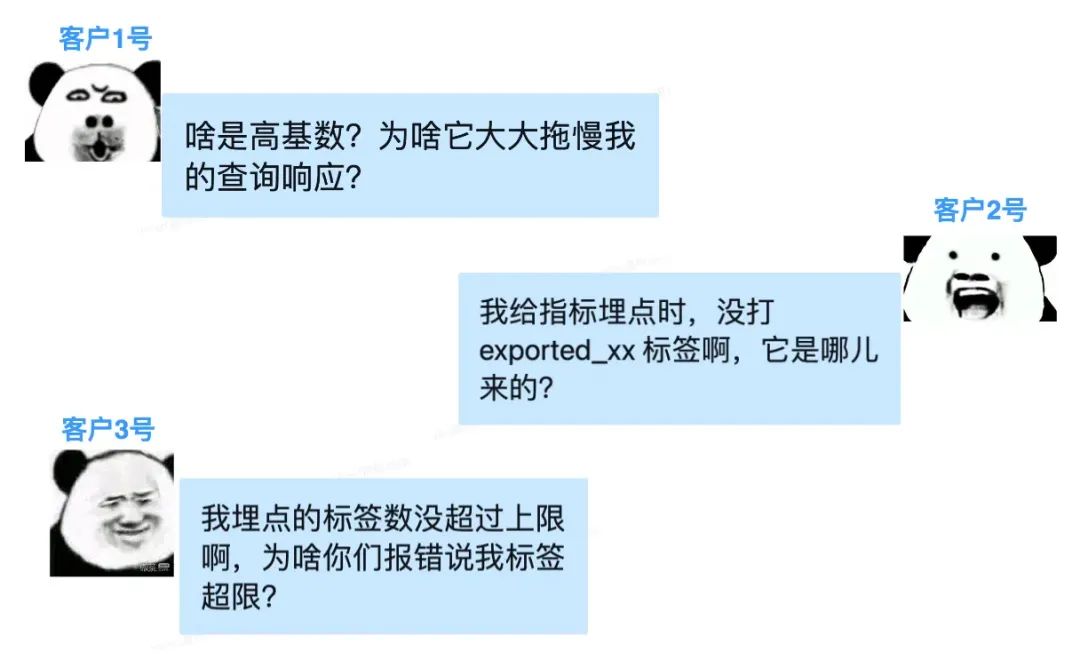
以上客户遇到的常见问题,同时也是 Prometheus 标签领域的常见痛点。
下面我们就来扒一扒这些问题的起因、表现,以及如何避坑;同时预报一波我们针对常见大坑,计划推出的产品新功能。
基数爆炸
使用 Prometheus 时,有时会遇到这种现象:
-
当我们开始采集某个指标后,它的活跃时间序列数量非常庞大。
-
当我们配好 Grafana 大盘、准备花式查询时,却发现查询的响应极慢,系统资源水位也涨得很高。
这是为什么呢?
仔细观察,这个指标名下的标签组合可能非常多,导致时间序列数量急剧增加。而这,就是 Prometheus 领域令人闻风丧胆的高基数问题。
所谓基数(Cardinality),也即不同的时间序列的数量,它是由标签(labels)的不同的键值对组合的数量决定的。仍用前文提过的 CPU 指标举例:

可以看出,假如我有 100 台主机、3个环境、10 个地域,那么动用我残存的初中排列组合知识,这三组标签键值对,总共可能有 100*3*10 种组合,那么此时该指标的时间序列是 3000个。
3000 个时间序列不算多。但当我的业务扩张、基础设施扩容,达到主机数 1000 台、环境 10 个、全球地域 100 个,此时时间序列数就达到了 100万个。
可见,随着标签组合可能性的增加,时间序列数会随之增加。
那么,假如某次标签规划中,我们添加了一个取值高度动态的标签,比如:时间戳、含动态参数的 URL、各种 UUID……可以推断出,这可能导致时间序列在短时间内急剧增加,而这就是我们所说的——基数爆炸。
基数爆炸,不仅会消耗大量的存储资源,还可能严重影响 Prometheus 的查询性能和整体稳定性。

高基数乃至基数爆炸,究其原因,很可能是我们使用指标的姿势不对——须知,指标不是日志,指标的标签也不是日志的字段,使用时不该事无巨细啥都塞。
在使用日志监控时,我们通常会将关键信息全部打印,以确保在排查问题时,能取到足够的上下文信息,代价无非是对存储空间的占用。
然而,对于指标监控来说,为啥不能塞太多标签呢?
原因正如前文提过的,Prometheus 标签不仅仅是个 metadata 元数据,它还承担着 architecture 结构的任务。那么,在 Prometheus 中,每增加一个标签或标签值,就不是仅仅增加了一个字段这么简单,而是会翻着倍地,创建出新的时间序列。
那么,当标签取值的范围很宽、动态性很大,这就会导致时间序列爆炸式增长,而这会对存储空间、内存使用、查询速度和数据聚合的性能,产生重大影响。
为了高效避坑,我们需提前做好指标规划、标签管理,比如:
-
避免使用具有大量唯一值的标签(例如上文提到的 UUID 等);尽量使用有限的、预定义的标签值(例如状态码、服务模块等)。
-
提前配置预聚合规则,来预先计算常见查询结果,并存储为新的指标,减少在查询时需要处理的时间序列(例如:不使用具体的 UUID,而使用表示对象类型的标签;不使用带有动态参数的 URL,而使用汇总归类后的通用标签)。
-
将高基数数据保留在日志监控里,而不是指标监控里。
这样,我们就可以有效控制 Prometheus 中时间序列的数量,以避免基数爆炸带来的问题、维护 Prometheus 的性能和稳定性。
exported 前缀
在用 Prometheus 的时候,有时会碰到前缀为 exported_ 、并非我本人定义的标签,不知道怎么突然冒出来的,着实让人摸不到头脑。
其实,这是由于 标签冲突 导致的。也即,不同来源的标签名称重复了,触发 Prometheus 为其中一个添加 exported_ 前缀,以此来解决冲突。
通过 honor_labels 配置项,我们可以按需对冲突的标签名称进行处理。
根据原生 Prometheus 对 honor_labels 配置的解释,简单来说,honor_labels 用于管理来自 target sample 的标签与来自 Prometheus 自身生成的标签之间的冲突:
-
true:对于重名的标签键,采用来自 target sample 的标签值。 -
false:对于重名的标签键,采用 Prometheus 自动生成的标签值,与此同时,对来自 target sample 的标签键进行重命名(为其增加exported_前缀)。
例如,我有下面一段采集配置,默认情况下,Prometheus 在对这些 target 做采集解析时,会自动为其打上 instance 标签,其值为 target 的 <host>:<port>。
- job_name: 'test'
honor_labels: true
static_configs:
- targets: ['server1.example.com:9100', 'server2.example.com:9100']与此同时,好巧不巧的是,我的 target 暴露的指标 sample ,也携带了 instance 标签。例如:server1.example.com 暴露这样的指标 sample: cpu_seconds_total{instance="ServerOne"} 12345。
在这种标签冲突的情形下:
-
如果设置了
honor_labels: true,Prometheus 将保留 target sample 里的instance="ServerOne"标签,而无视 Prometheus 自动生成的instance="server1.example.com:9100"。 -
如果设置了
honor_labels: false(不设置时默认也是 false),Prometheus 会给 target sample 里的重名标签添加前缀exported_。例如,target sample 里的instance="ServerOne"标签,会变成exported_instance="ServerOne"。
指标丢弃
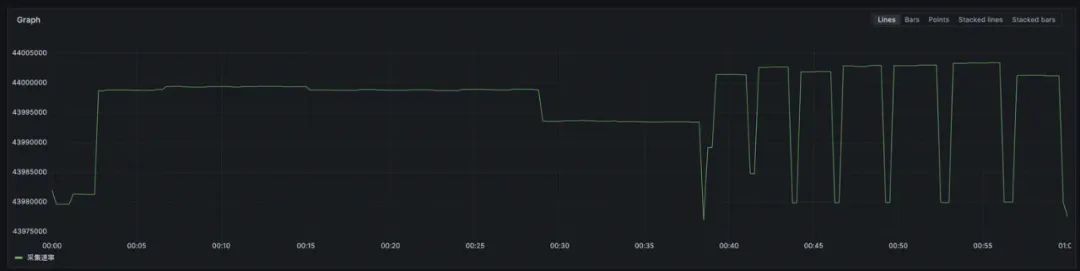
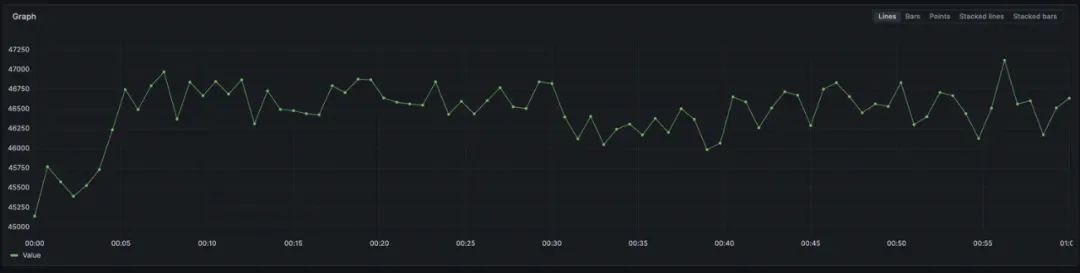
某用户有个腾讯云 Prometheus 实例,它的存储写入指标的速率为 5w,而实际上采集侧采集指标的速率高达 440w!这是为什么呢?
-
采集速率:
-
存储写入速率:
其实,这是 relabel 带来的指标丢弃 导致的。
根据前文介绍,我们了解到在指标的整个生命周期里,最关键的是采集+存储两步。
在我们腾讯云 Prometheus 中,最关键的同样是这两步:
-
采集步骤:在用户侧创建用于指标采集的组件,用于指标数据的采集和处理,并写入到存储中。
-
存储步骤:基于底层共享存储集群,来做指标数据的存储和查询。
可以看出,采集和存储是两个不同的模块,两者的资源消耗是独立的:
-
采集侧的资源消耗,主要来自采集对象的服务发现、指标的采集和处理。
-
存储侧的资源消耗,主要来自指标数据的存储和查询。
由于在指标写入存储之前,采集侧还会根据采集配置进行一系列处理,因此指标的采集量和存储量是不同的,甚至可能有很大的区别。
当我们要采集的 target 数量庞大、单个 target 的指标采集量也数量庞大的时候,我们就需要扩容出更多的采集侧资源。
基于上述背景,我们就可以推断出,这个用户的采集速率跟存储速率相差巨大的主要原因是:在采集侧采集到指标之后,根据采集配置中的 metric_relabel_config,对指标写入前进行处理,而这个处理步骤,会丢弃绝大部分指标,才最终写入到存储侧。
导致采集侧资源消耗如此多的原因,就是采集的原始指标的量比较大,而它和最终写入的数据量没有太大的关系。
那么,我们在哪里才能看到采集侧原始指标的具体数量呢?可以在腾讯云 Prometheus 实例对应的 Grafana 中,输入 sum(scrape_samples_scraped) ,来查询和采集状态相关的指标(该指标是个免费指标)。
标签上限
既然 Prometheus 都没有限制标签个数的上限,那么腾讯云 Prometheus 为啥要设置这个上限呢?
因为,在指标从采集到写入的路径上,标签数量可能在不知不觉间,越变越多。
对于一个指标来说,业务相关的标签显然非常重要;除此之外,从运维的层面,我们还需知道指标背后具体是哪个 pod、哪个 service、哪个集群等等信息。
所以,当我们通过服务发现获取 target,会被 Prometheus 添加服务发现相关的元数据标签;在采集配置中,我们也可以直接添加静态标签、全局标签等等(比如腾讯云 Prometheus 容器采集默认添加的 cluster 和 cluster_type 两个标签)。
但是,标签数量过大,会导致指标存储空间迅速增长、内存消耗巨大;而且引入了大量的复杂性,导致查询和存储的成本快速提升——特别是查询,进而影响最终的资源消耗和服务的定价策略。
作为用户来说,当然希望支持的标签数量越多越好;但是作为服务提供方来说,超限的标签数量会导致资源消耗量增加、运维难度增大,服务定价策略失效,不得不抬高价格。
所以,基于多方面考虑,腾讯云 Prometheus 为用户提供了 32 个标签的容量上限,几乎能够满足所有的指标监控场景。
与此同时,从最佳实践的角度,用户也可以采取一些措施,来应对潜在的指标标签数量过大的问题:
-
标签数量优化:只使用必要的标签,避免使用过多的标签,特别是对监控业务无关、标签值变化频繁的标签。
-
标签值规范化:确保标签值的一致性,避免不必要的标签变种。
-
监控和调整:定期监控标签使用情况,及时调整和优化。
产品预告
在 Prometheus 的指标采集阶段,如何编写出符合预期的采集配置,使得服务发现和指标抓取都如我所愿,常常是件颇为烧脑的事情。
针对采集过程中可能出现的问题,为了使用户能够快速锁定、方便调试,腾讯云 Prometheus 团队正计划增加以下功能,以提高用户体验:
-
将采集配置可视化
-
支持在线调试 relabel 规则
简而言之,有了上述新功能,在下图所示的指标流转、标签变幻的过程中,我们会把进入每个黄圈圈/绿圈圈的前后、以及圈圈之间的标签变化与冲突融合,都可视化在腾讯云 Prometheus 的控制台界面上,并且支持实时调试,以保证用户能自助玩转 Prometheus 标签、不再烧脑。
relabel 调试
以服务发现时的 relabel 规则调试为例:我们以服务发现生成的标签为输入源,然后应用 relabel_configs 里的 relabel 规则时,我们能在控制台界面上,动态地调试每个 relabel_config 规则处理前后,指标标签的变化。
其形式类似于 PromLabs 的标签 debugger 工具:
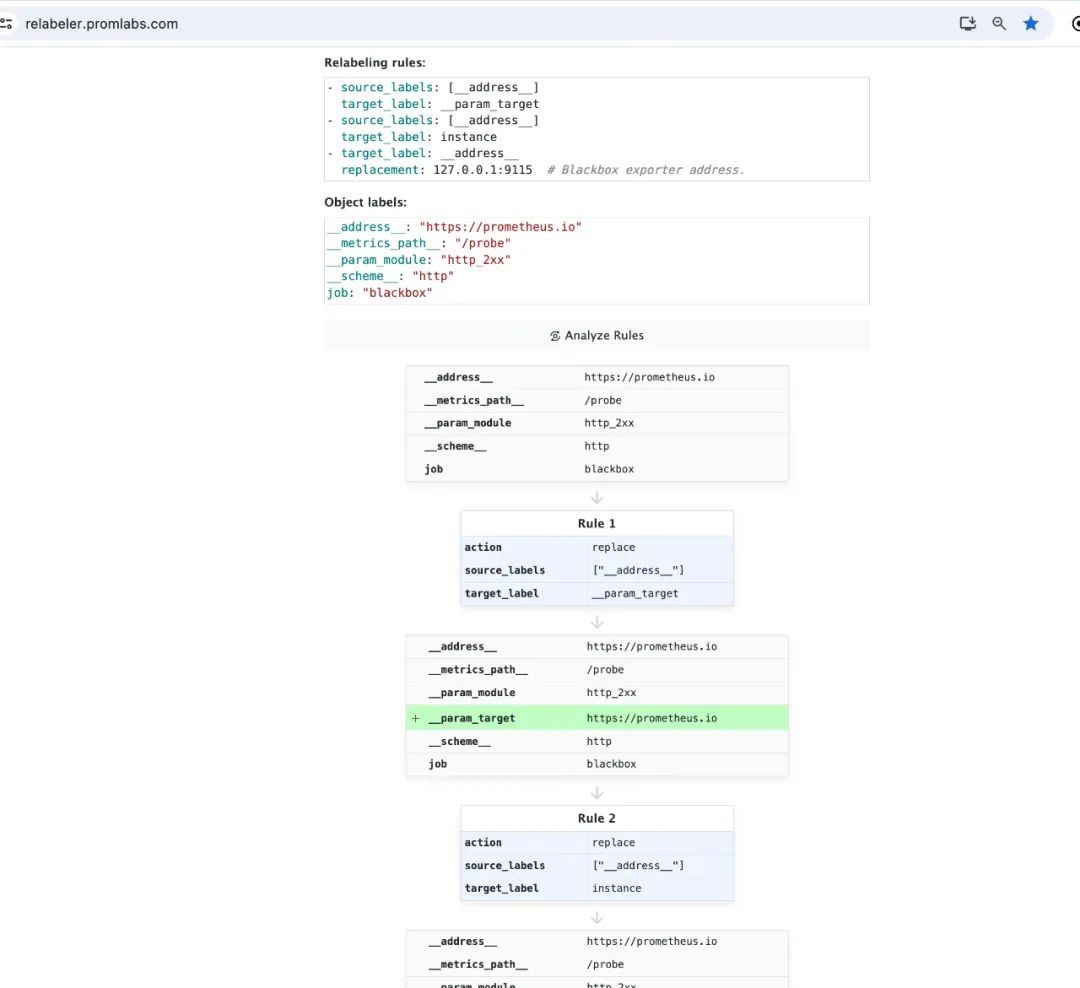
而与 PromLabs 这个小工具不同的是:使用腾讯 Prometheus 的一条龙服务,配置和指标都已经被托管在云上了,用户无需手工输入用于调试的数据,而只需在控制台界面上一键勾选,就能方便地调试 relabel 规则,查看指标标签的前后变化。
可视化变更
以从 target 实际抓取到的 sample、以及采集侧的实际配置为输入源,可视化地输出从采集解析后、到写入存储前,在各个处理阶段中,指标是如何变化的。
例如,我们可以利用这个功能,方便地观察在以下几个阶段,指标的前后变化:
-
指标采集解析后,如何与服务发现阶段生成的标签的融合。
-
指标经过
metric_relabel_configs处理前后的变化。 -
与系统指标
up、scrape_duration_seconds等的融合。 -
远程写入外部存储前,如何融合外部标签
external_labels。
结语
本文围绕 Prometheus 标签的灵魂地位,介绍了 Prometheus 指标的数据模型和生命周期,以及指标标签的诸多来源,还有如何在各阶段使用 relabel 重新打标,以优化指标和标签。
与此同时,基于我们腾讯云 Prometheus 团队的踩坑实践,我们还探讨了基数爆炸、标签冲突等常见痛点及避坑实践,并针对这些痛点,规划了一波产品的新功能:采集配置可视化、在线调试 relabel规则。
围绕着 Prometheus 标签的问题十分繁杂,即便写此长文,却仍然是挂一漏万、难以尽述。
而围绕着 Prometheus 宇宙,当然还有更复杂、更深入的问题亟待探讨。
欲知后事如何,欢迎强势关注腾讯云可观测团队,与我们一起 stay hungry, stay foolish;持续发掘、持续求索。
联系我们
如有任何疑问,欢迎加入官方技术交流群

关于腾讯云可观测平台
腾讯云可观测平台(Tencent Cloud Observability Platform,TCOP)基于指标、链路、日志、事件的全类型监控数据,结合强大的可视化和告警能力,为您提供一体化监控解决方案。满足您全链路、端到端的统一监控诉求,提高运维排障效率,为业务的健康和稳定保驾护航。功能模块有:
-
Prometheus 监控:开箱即用的 Prometheus 托管服务;
-
应用性能监控 APM:支持无侵入式探针,零配置获得开箱即用的应用观测能力;
-
云拨测 CAT:利用分布于全球的监测网络,提供模拟终端用户体验的拨测服务;
-
前端性能监控 RUM:Web、小程序等大前端领域的页面质量和性能监测;
-
Grafana 可视化服务:提供免运维、免搭建的 Grafana 托管服务;
-
云压测 PTS:模拟海量用户的真实业务场景,全方位验证系统可用性和稳定性;
-
......等等















 2694
2694

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









