







使用版本
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.1.1</version>
</dependency>
参考文档
起因
公司的一些记录表数据量到达几千万,有些已经一个多亿了,领导让用Sharding按照年月搞一下分库分表,接到任务后根据官方文档和一些帖子,整合了一下,自测基础crud都没啥问题,笑眯眯提交需求工单,提测没多久,测试指给我几个bug工单,基本都是数据导出和统计查询。
跟代码,发现几个问题相同点是用到了子查询或者函数,查询时执行的sql并没有如预想当中,查询对应的月份表。
SQL
查询所用sql:
SELECT
*
FROM
obc_outbound_log
INNER JOIN ( SELECT id FROM obc_outbound_log o WHERE ctime BETWEEN '2022-05-01 00:00:00' AND '2022-05-31 23:59:59' LIMIT 10 ) t ON obc_outbound_log.id = t.id
 执行的sql:
执行的sql:
SELECT * FROM obc_outbound_log_202205 inner join (SELECT id FROM obc_outbound_log o limit 10)t on obc_outbound_log.id=t.id where obc_outbound_log_202205.ctime between '2022-05-01T18:27:23.000+0800' and '2022-05-31T23:59:59.999+0800'
### Error querying database. Cause: java.sql.SQLSyntaxErrorException: Table 'obc_record.obc_outbound_log' doesn't exist
注:(sql这么写是为了解决分页偏移量过大)
参考文章:Mysql中limit分页大偏移量的原因分析与优化_xiaopang小白的博客-CSDN博客_limit分页偏移量较大的情况下去优化
问题分析
子查询中的记录表,并没有替换表名,怀疑是SQL解析引擎,解析出的token有问题,去官网去找了一下资料,发现Sharding JDBC有很多不支持的sql语法。

虽然官方说不支持,但是因为历史业务sql用到子查询的地方较多,挨个去改sql工作量就变得太大了, 领导让想办法兼容一下,既要分表,也要尽可能兼容一些子查询,结构特别复杂的可以先放一放。
然后就继续读文档,看博客得知,ShardingSphere 的三个产品对于分片的流程都是一样的
SQL解析 => 执行器优化 => SQL路由 => SQL改写 => SQL执行 => 结果归并
SQL解析
分为词法解析和语法解析。 先通过词法解析器将SQL拆分为一个个不可再分的单词。再使用语法解析器对SQL进行理解,并最终提炼出解析上下文。 解析上下文包括表、选择项、排序项、分组项、聚合函数、分页信息、查询条件以及可能需要修改的占位符的标记。
执行器优化
合并和优化分片条件,如OR等。
SQL路由
根据解析上下文匹配用户配置的分片策略,并生成路由路径。目前支持分片路由和广播路由。
SQL改写
将SQL改写为在真实数据库中可以正确执行的语句。SQL改写分为正确性改写和优化改写。
SQL执行
通过多线程执行器异步执行。
结果归并
将多个执行结果集归并以便于通过统一的JDBC接口输出。结果归并包括流式归并、内存归并和使用装饰者模式的追加归并这几种方式。

执行流程
问题和猜想的差不多,就是出在解析和重写那了,跟源码看执行流程





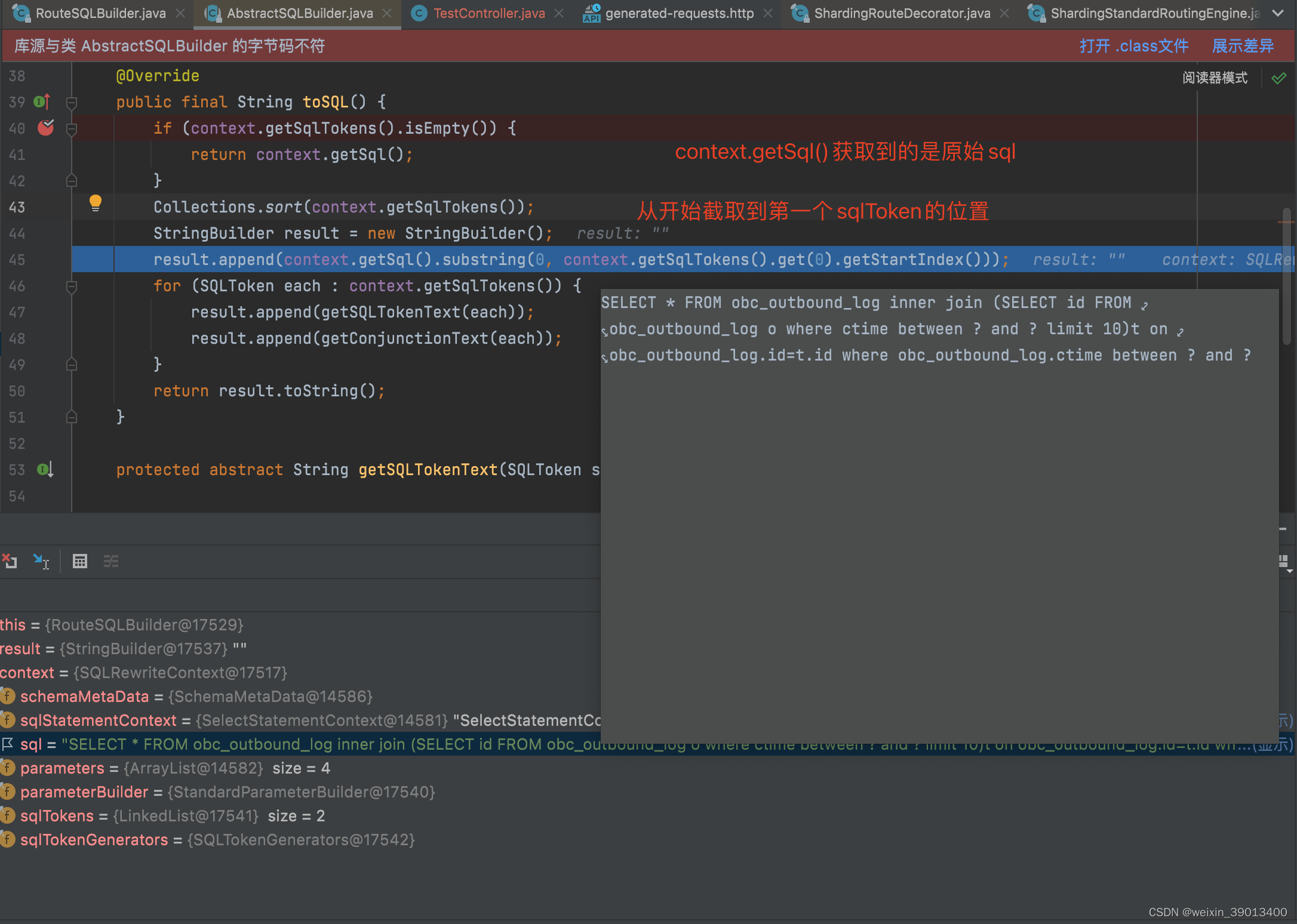


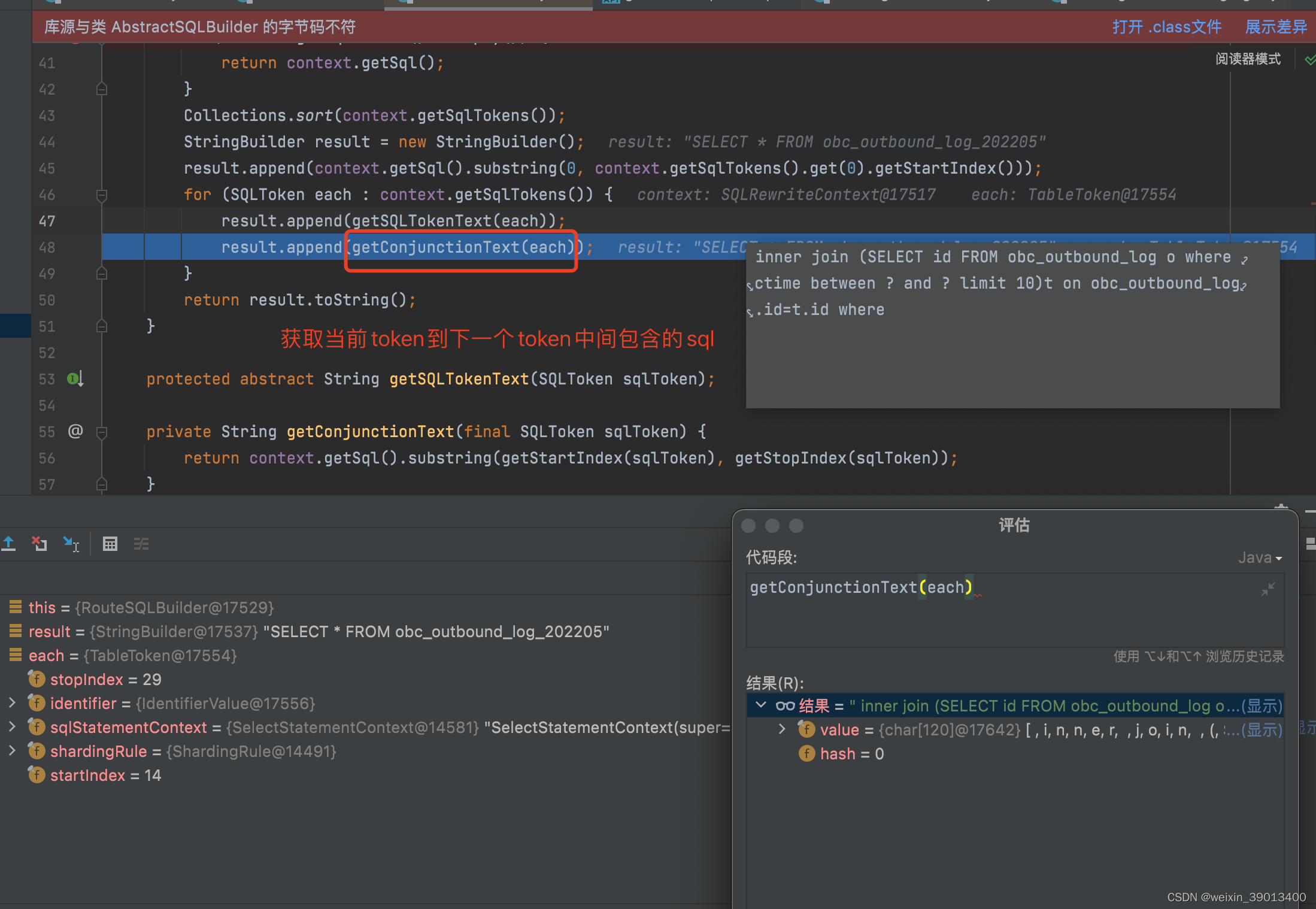

处理方案
问题定位到了,开始想解决方案
1:要么从源头(SQL解析引擎)解决,重写方法,得到预想的SqlToken。
2:重写AbstractSQLBuilder这个方法,加入额外的业务逻辑。

总结
目前只是一个解决思路,直接使用肯定会有问题,比如错误替换了别的表名,例如test_table替换为test_table_202205,但where sql中还存在test_table_log、test_table_record会有问题,慢慢完善,思路有了,问题就好解决了。
关于Sharding JDBC对于使用函数报错的问题,我是看的这篇博客
Sharding升级 4.0 版本升级到4.1 SQL 语法问题总结_魔力化的博客-CSDN博客
有理解错误的地方,希望各位大佬指出。














 329
329











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









