







目录
2.3.1什么是high memory,为什么要有high memory
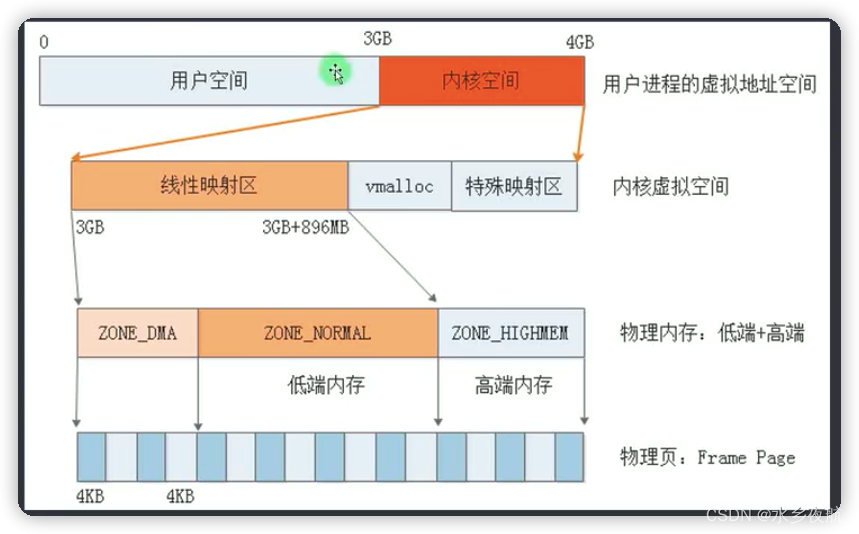
1.虚拟内存空间布局
32位平台经典的虚拟内存划分比例是 用户:内核=3:1,可以通过宏CONFIG_PAGE_OFFSET自行配置
内核虚拟空间再次做了划分:vector,fixmap,线性映射区,vmalloc,特殊映射区,.bss,.init, .text, swapper_page_dir(页表)等。这里的区域划分和前文探索的物理地址是不一样的,虚拟空间和物理地址空间独立设计,通过缺页映射等操作联系起来。
代码:在arch/arm/mm/init.c 中的内存初始化函数mem_init()中,这个函数主要就是实现了物理内存从一级页表块映射转换到伙伴算法子系统,以页面为单位的更精细管理;同时将内核虚拟内存的相关块划分输出到串口,至于具体的划分是由链接脚本vmlinux.lds或者不同头文件的宏所决定.宏不存在,相应的分区划分也会消失。
/*
* mem_init() marks the free areas in the mem_map and tells us how much
* memory is free. This is done after various parts of the system have
* claimed their memory after the kernel image.
*/
void __init mem_init(void)
{
unsigned long reserved_pages, free_pages;
struct memblock_region *reg;
int i;
max_mapnr = pfn_to_page(max_pfn + PHYS_PFN_OFFSET) - mem_map;
/* this will put all unused low memory onto the freelists */
free_unused_memmap(&meminfo);
totalram_pages += free_all_bootmem(); /* 释放所有块映射页表 内存块,由buddyinfo子系统接管*/
free_highpages();
reserved_pages = free_pages = 0;
/* ... ... ... ...*/
printk(" = %luMB total\n", num_physpages >> (20 - PAGE_SHIFT));
printk(KERN_NOTICE "Memory: %luk/%luk available, %luk reserved, %luK highmem\n",
nr_free_pages() << (PAGE_SHIFT-10),
free_pages << (PAGE_SHIFT-10),
reserved_pages << (PAGE_SHIFT-10),
totalhigh_pages << (PAGE_SHIFT-10));
printk(KERN_NOTICE "Virtual kernel memory layout:\n"
" vector : 0x%08lx - 0x%08lx (%4ld kB)\n"
#ifdef CONFIG_HAVE_TCM
" DTCM : 0x%08lx - 0x%08lx (%4ld kB)\n"
" ITCM : 0x%08lx - 0x%08lx (%4ld kB)\n"
#endif
" fixmap : 0x%08lx - 0x%08lx (%4ld kB)\n"
" vmalloc : 0x%08lx - 0x%08lx (%4ld MB)\n"
" lowmem : 0x%08lx - 0x%08lx (%4ld MB)\n"
#ifdef CONFIG_HIGHMEM
" pkmap : 0x%08lx - 0x%08lx (%4ld MB)\n"
#endif
#ifdef CONFIG_MODULES
" modules : 0x%08lx - 0x%08lx (%4ld MB)\n"
#endif
" .text : 0x%p" " - 0x%p" " (%4d kB)\n"
" .init : 0x%p" " - 0x%p" " (%4d kB)\n"
" .data : 0x%p" " - 0x%p" " (%4d kB)\n"
" .bss : 0x%p" " - 0x%p" " (%4d kB)\n",
MLK(UL(CONFIG_VECTORS_BASE), UL(CONFIG_VECTORS_BASE) +
(PAGE_SIZE)),
#ifdef CONFIG_HAVE_TCM
MLK(DTCM_OFFSET, (unsigned long) dtcm_end),
MLK(ITCM_OFFSET, (unsigned long) itcm_end),
#endif
MLK(FIXADDR_START, FIXADDR_TOP),
MLM(VMALLOC_START, VMALLOC_END),
MLM(PAGE_OFFSET, (unsigned long)high_memory),
#ifdef CONFIG_HIGHMEM
MLM(PKMAP_BASE, (PKMAP_BASE) + (LAST_PKMAP) *
(PAGE_SIZE)),
#endif
#ifdef CONFIG_MODULES
MLM(MODULES_VADDR, MODULES_END),
#endif
MLK_ROUNDUP(_text, _etext),
MLK_ROUNDUP(__init_begin, __init_end),
MLK_ROUNDUP(_sdata, _edata),
MLK_ROUNDUP(__bss_start, __bss_stop));
}
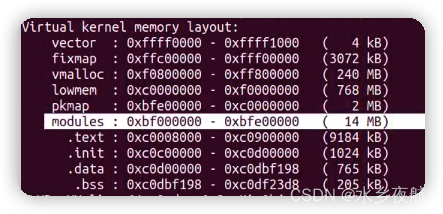
Virtual kernel memory layout:
vector : 0xffff0000 - 0xffff1000 ( 4 kB)
fixmap : 0xffc00000 - 0xfff00000 (3072 kB)
vmalloc : 0xf0000000 - 0xff000000 ( 240 MB)
lowmem : 0xc0000000 - 0xef800000 ( 760 MB)
pkmap : 0xbfe00000 - 0xc0000000 ( 2 MB)
modules : 0xbf000000 - 0xbfe00000 ( 14 MB)
.text : 0xc0008000 - 0xc0658750 (6466 kB)
.init : 0xc0659000 - 0xc0782000 (1188 kB)
.data : 0xc0782000 - 0xc07b1920 ( 191 kB)
.bss : 0xc07b1920 - 0xc07db378 ( 167 kB)
编译器在编译目标文件并且链接完成之后,就可以知道内核映像文件最终的大小,接下来将其打包成二进制文件,该操作由arch/arm/kernel/vmlinux.ld.S 控制,其中也划定了内核的内存布局。
内核image本身占据的内存空间从_text段到_end段,并分为如下几个段。
text段:_text和_etext为代码段的起始和结束地址,包含了编译后的内核代码。
init段:__init_begin和__init_end为init段的起始和结束地址,包含了大部分内核模块初始化的数据。
data段:_sdata和_edata为数据段的起始和结束地址,保存大部分内核的已初始化的变量。
BSS段:__bss_start和__bss_stop为BSS段的开始和结束地址,包含初始化为0的所有静态全局变量
2.内核映射区
2.1 线性映射区
虚拟地址空间和物理内存空间之间只存在一个offset的差异,地址一一对应称之为线性映射。
这样做的好处就是可以加快映射效率,加快内核访问。线性映射区是内核虚拟内存区域的一部分,从内核-用户虚拟空间边界PAGE_OFFSET开始 。负责直接映射管理低端的物理内存,形成NORMAL_ZONE区域,除此之外映射不到的物理内存ZONE_HIGHMEM由内核的vmalloc区和其他区负责映射管理。

线性映射专用接口:
/* Drivers should NOT use these either.*/
#define __pa(x) __virt_to_phys((unsigned long)(x)) 线性映射区的虚拟地址转换为物理地址,转换公式很简单,即用虚拟地址减去PAGE_OFFSET(3GB),然后加上PHYS_OFFSET
#define __va(x) ((void *)__phys_to_virt((unsigned long)(x)))
#define pfn_to_kaddr(pfn) __va((pfn) << PAGE_SHIFT)
2.2 低端内存
2.2.1 线性映射区大小确定
查看代码可知线性映射区大小起始于PAGE_OFFSET(实际上就是物理内存起始地址), 结束于VMALLOC_START, VMALLOC_START又受到high_memory影响,因此我们必须要搞清楚什么是high_memory.
#define PHYS_OFFSET UL(CONFIG_DRAM_BASE) //代表起始物理地址
#ifndef PAGE_OFFSET
#define PAGE_OFFSET (PHYS_OFFSET)
#endif
#define VMALLOC_OFFSET (8*1024*1024) // 高端内存和低端内存之间的隔离带
#define VMALLOC_START (((unsigned long)high_memory + VMALLOC_OFFSET) & ~(VMALLOC_OFFSET-1))
static void * __initdata vmalloc_min =
(void *)(VMALLOC_END - (240 << 20) - VMALLOC_OFFSET);
2.3 高端内存
以下文字来源于Linux high_memory_windyf2013的博客-CSDN博客
high memory只存在于32位kernel下,以下文字都针对32位kernel。
2.3.1什么是high memory,为什么要有high memory
Linux人为的把4G虚拟地址空间(32位地址最多寻址4G)分为3G+1G,其中0~3G为用户程序地址空间,3G~4G为kernel地址空间(为什么要这么分?为什么用户程序和kernel不能各自独享4G虚拟地址空间?这两个问题下次再说吧,这里不表),这就是说kernel最多寻址1G的虚拟地址空间。
当CPU启用MMU的paging机制后,CPU访问的是虚拟地址,然后由MMU根据页表转换成物理地址。页表是由kernel维护的,所以kernel可以决定1G的虚拟地址空间具体映射到什么物理地址。但是kernel最多只有3G~4G这1G地址空间,所以不管kernel怎么映射,最多只能映射1G的物理内存。所以如果一个系统有超过1G的物理内存,在某一时刻,必然有一部分kernel是无法直接访问到的(这个一定要想清楚,不然无法明白high memory)。另外,kernel除了访问内存外,还需要访问很多IO设备。在现在的计算机体系结构下,这些IO设备的资源(比如寄存器,片上内存等)一般都是通过MMIO的方式映射到物理内存地址空间来访问的,就是说kernel的1G地址空间除了映射内存,还要考虑到映射这些IO资源--换句话说,kernel还需要预留出一部分虚拟地址空间用来映射这些IO设备(ioremap就是干这个的)。
Linux kernel采用了最简单的映射方式来映射物理内存,即把物理地址+3G按照线性关系直接映射到kernel空间。考虑到一部分kernel虚拟地址空间需要留给IO设备(以及一些其他特殊用途),Linux kernel最多直接映射896M物理内存,而预留了最高端的128M虚拟地址空间给IO设备(还有其他的用途)。所以,当系统有大于896M内存时,超过896M的内存kernel就无法直接访问到了(想明白了么?),这部分内存就是high memory。那kernel就永远无法访问到超过896M的内存了马?不是的,kernel已经预留了128M虚拟地址,我们可以用这个地址来动态的映射到high memory,从而来访问high memory。所以预留的128M除了映射IO设备外,还有一个重要的功能是提供了一种动态访问high memory的一种手段(kmap主要就是干这个的,当然还有vmalloc)。
当然,在系统物理内存<896M,比如只有512M的时候,就没有high memory了,因为512M的物理内存都已经被kernel直接映射。事实上,在物理内存<896M时,从3G+max_phy ~ 4G的空间都作为上述的预留的内核地址空间(未考证)。
要理解high memory,关键是把物理内存管理,虚拟地址空间管理,以及两者间的映射(页表管理)三个部分分开考虑,不要把物理内存管理和虚拟地址空间管理混在一起。比如high memory也参与kernel的物理内存分配,你调用get_page得到的物理页有可能是low memory,也可以是high memory,这个物理页可以被映射到kernel,同时也可以被映射到user space。再比如vmalloc,只保证返回的虚拟地址是在预留的vmalloc area里,对应的物理内存,可以是low memory,也可以是high memory。当然出于性能考虑,kernel可能会优先分配直接映射的low memory,但我们不能假设high memory就不会被分配到。
2.3.2一些结论:
1)high memory针对的是物理内存,不是虚拟内存,更确切的,虚拟地址空间。
2)high memory也是被内核管理的(有对应的page结构),只是没有映射到内核虚拟地址空间。当kernel需要分配high memory时,通过kmap等从预留的地址空间中动态分配一个地址,然后映射到high memory,从而访问这个物理页。
3)high memory和low memory一样,都是参与内核的物理内存分配,都可以被映射到kernel地址空间,也都可以被映射到user space地址空间。
4)物理内存 < 896M时,没有high memory,因为所有的内存都被kernel直接映射了。
5)64位系统下不会有high memory,因为64位虚拟地址空间非常大(分给kernel的也很大),完全能够直接映射全部物理内存。
6)题外话1 -- 关于最高端的128M内核虚拟地址(或者当物理内存<896M时更大)的分配:
这部分地址空间被划分为4段,分别是fixed mapping,kmap area,vmalloc area,还有8M用来catch kernel指针错误。其中fixed mapping主要用在boot阶段用来永久性映射一些物理地址固定的数据结构或者硬件地址(比如ACPI表,APIC地址,等等)。kmap area是kernel用来临时建立映射来访问物理页用的,可用的地址空间也比较小。128M中绝大部分reserve了给vmalloc area,vmalloc和ioremap返回的都是这个空间里的地址。
2.3.3 vmalloc
vmalloc分配的内存从哪块区域获取,取决于gfp_mask参数表示的区域,他会优先从HIGHMEM_ZONE虚拟地址空间分配空闲内存,再使用伙伴算法获取物理页,建立映射。
/**
* vmalloc - allocate virtually contiguous memory
* @size: allocation size
* Allocate enough pages to cover @size from the page level
* allocator and map them into contiguous kernel virtual space.
*
* For tight control over page level allocator and protection flags
* use __vmalloc() instead.
*/
/* vmalloc 可以从高端内存 也可以从低端内存分配物理内存,最终通过调用不同ZONE区域的伙伴接口来实现不同区域的内存分配 */
void *vmalloc(unsigned long size)
{
return __vmalloc_node_flags(size, -1, GFP_KERNEL | __GFP_HIGHMEM);
}
EXPORT_SYMBOL(vmalloc);
static inline void *__vmalloc_node_flags(unsigned long size,
int node, gfp_t flags)
{
return __vmalloc_node(size, 1, flags, PAGE_KERNEL,
node, __builtin_return_address(0));
}
/**
* __vmalloc_node - allocate virtually contiguous memory
* @size: allocation size
* @align: desired alignment
* @gfp_mask: flags for the page level allocator
* @prot: protection mask for the allocated pages
* @node: node to use for allocation or -1
* @caller: caller's return address
*
* Allocate enough pages to cover @size from the page level
* allocator with @gfp_mask flags. Map them into contiguous
* kernel virtual space, using a pagetable protection of @prot.
*/
static void *__vmalloc_node(unsigned long size, unsigned long align,
gfp_t gfp_mask, pgprot_t prot,
int node, void *caller)
{
return __vmalloc_node_range(size, align, VMALLOC_START, VMALLOC_END,
gfp_mask, prot, node, caller);
}
void *__vmalloc_node_range(unsigned long size, unsigned long align,
unsigned long start, unsigned long end, gfp_t gfp_mask,
pgprot_t prot, int node, void *caller)
{
struct vm_struct *area;
void *addr;
unsigned long real_size = size;
area = __get_vm_area_node(size, align, VM_ALLOC | VM_UNLIST,
start, end, node, gfp_mask, caller);
//从VMALLOC_START到 VMALLOC_END之间查找空闲的虚拟地址范围。
addr = __vmalloc_area_node(area, gfp_mask, prot, node, caller);
//为申请到的虚拟空间分配物理页,建立页映射关系,并填充页表
/*
* In this function, newly allocated vm_struct is not added
* to vmlist at __get_vm_area_node(). so, it is added here.
*/
insert_vmalloc_vmlist(area);
/*
* A ref_count = 3 is needed because the vm_struct and vmap_area
* structures allocated in the __get_vm_area_node() function contain
* references to the virtual address of the vmalloc'ed block.
*/
kmemleak_alloc(addr, real_size, 3, gfp_mask);
return addr;
}
static void *__vmalloc_area_node(struct vm_struct *area, gfp_t gfp_mask,
pgprot_t prot, int node, void *caller)
{
/* ... ... ... ... ... */
for (i = 0; i < area->nr_pages; i++) {
struct page *page;
gfp_t tmp_mask = gfp_mask | __GFP_NOWARN;
if (node < 0)
page = alloc_page(tmp_mask);// 伙伴算法接口分配物理页面
else
page = alloc_pages_node(node, tmp_mask, order);
area->pages[i] = page;
}当HIGHMEM不存在(比如64位平台),kmalloc会从线性映射区映射,然而当我们要再使用线性映射的时候,这样理论上会产生映射冲突!
实际上这种情况是不会发生的,因为线性区域的物理地址分配给kmalloc之后,建立了页表映射,此时再想使用线性映射方式(phys_to_virt)通过MMU访问同一块物理地址会访问失败(没有建立正确映射),只有kmalloc申请到的虚拟地址才能通过MMU访问到正确物理位置。

2.4 pkmap区(在64位上慢慢被舍弃)
系统中的高端内存是不能作为直接映射区映射到内核空间的,那么我们想要使用它怎么办呢?可以使用三种方法,分别是pkmap(永久映射)/fixmap(临时固定映射)/vmlloc,本文主要介绍pkmap,也就是永久映射。
pkmap(page kernel map),他是内核配置了CONFIG_HIGHMEM后从modules分出来的。
接口:需要结合alloc_page()接口使用
void kmap(struct *page);建立物理页面page到虚拟地址之间的映射
void unkmap(struct *page);释放物理页面资源
2.5 fixmap区(3M)
fixmap(临时固定映射)内核编译期间就确定了虚拟地址,主要用于内核初始化之前,MMU未开启,相关内存子系统位初始化的时候,内核用于临时使用。

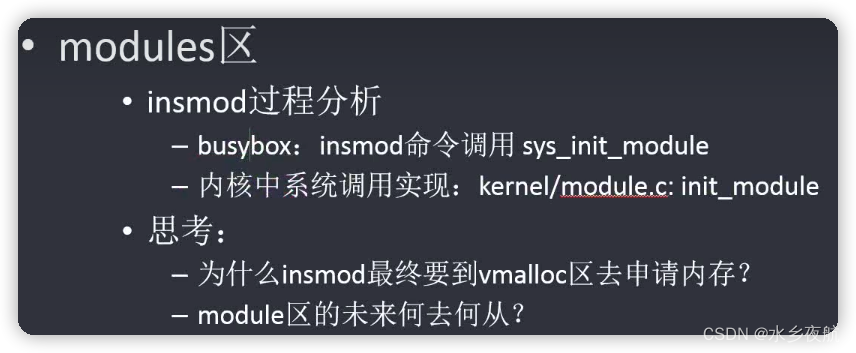
2.6 modules区(很鸡肋,未来内核可能考虑去掉)
用于驱动加载,其位置处于用户空间。驱动内部变量,数组等都会放在此虚拟区域。
插入模块后首先尝试去modules区域申请虚拟内存,申请失败再去kmalloc申请。
3.用户进程
3.1 用户页表
每个用户进程都代表一个分配资源的实体,存在和内核一样的代码段,数据段,bss段,init段以及堆栈段stack...这些段存放在用户态虚拟地址空间(0-3G),每个进程都使用自己的页表来保存映射信息;但是所有的进程都共用一个内核,自然也只有一个共用的内核页表(见前文,页表基址保存在寄存器中)。

fork创建进程的时候,会将内核页表基地址和用户进程的页表拷贝放到pgd段,执行进程切换的时候,内核页表和用户进程页表基地址都被拷贝到ARM的寄存器当中,这样就保证可每个进程使用的都是自己的虚拟地址映射。

3.2 fork函数
/*
* Ok, this is the main fork-routine.
*
* It copies the process, and if successful kick-starts
* it and waits for it to finish using the VM if required.
*/
long do_fork(unsigned long clone_flags,
unsigned long stack_start,
struct pt_regs *regs,
unsigned long stack_size,
int __user *parent_tidptr,
int __user *child_tidptr)
{
struct task_struct *p;
int trace = 0;
long nr;
p = copy_process(clone_flags, stack_start, regs, stack_size,
child_tidptr, NULL, trace);
/* ... ... */
}
static struct task_struct *copy_process(unsigned long clone_flags,
unsigned long stack_start,
struct pt_regs *regs,
unsigned long stack_size,
int __user *child_tidptr,
struct pid *pid,
int trace)
{
int retval;
struct task_struct *p;
int cgroup_callbacks_done = 0;
/* ... ... ... */
retval = copy_files(clone_flags, p);
retval = copy_fs(clone_flags, p);
retval = copy_sighand(clone_flags, p);
retval = copy_signal(clone_flags, p);
retval = copy_mm(clone_flags, p);
if (retval)
/* ... ... ... */
}
static int copy_mm(unsigned long clone_flags, struct task_struct *tsk)
{
struct mm_struct *mm, *oldmm;
int retval;
oldmm = current->mm;
mm = dup_mm(tsk);//拷贝父进程的mm_struct 结构信息
}
struct mm_struct *dup_mm(struct task_struct *tsk)
{
struct mm_struct *mm, *oldmm = current->mm;
int err;
mm = allocate_mm();
memcpy(mm, oldmm, sizeof(*mm));
if (!mm_init(mm, tsk)) //创建pgd 拷贝父进程内核部分页表
goto fail_nomem;
err = dup_mmap(mm, oldmm); //拷贝父进程的用户进程页表
if (err)
goto free_pt;
/*... ... ... ...*/
}
static struct mm_struct *mm_init(struct mm_struct *mm, struct task_struct *p)
{
if (likely(!mm_alloc_pgd(mm))) { //分配新的pgd指针
return mm;
}
return NULL;
}
/*
* need to get a 16k page for level 1
*/
pgd_t *pgd_alloc(struct mm_struct *mm)
{
new_pgd = __pgd_alloc();
memset(new_pgd, 0, USER_PTRS_PER_PGD * sizeof(pgd_t));
/*
* Copy over the kernel and IO PGD entries
*/
init_pgd = pgd_offset_k(0); //获取内核一级页表的内存地址
memcpy(new_pgd + USER_PTRS_PER_PGD, init_pgd + USER_PTRS_PER_PGD,
(PTRS_PER_PGD - USER_PTRS_PER_PGD) * sizeof(pgd_t));//跳过一级页表中的用户页表,拷贝内核部分页表
//... ... ... ...
}
/* to find an entry in a page-table-directory */
#define pgd_index(addr) ((addr) >> PGDIR_SHIFT)
#define pgd_offset(mm, addr) ((mm)->pgd + pgd_index(addr))
/* to find an entry in a kernel page-table-directory */
#define pgd_offset_k(addr) pgd_offset(&init_mm, addr)
截止目前,fork都只是拷贝页表,没有真正给子进程分配物理内存,直到真的去写子进程的时候会产生缺页异常,这时才会去分配物理页,父子进程分道扬镳。
3.3 缺页异常
3.3.1 什么是缺页异常
当进程需要访问某一页时, 操作系统通过查看页表核对此项是否在物理内存中,若不在物理内存中,就触发了缺页异常( Page Fault)。此时,由于CPU没有数据就无法进行计算,CPU罢工了用户进程也就出现了缺页中断,进程会从用户态切换到内核态,操作系统将进程放入阻塞队列中,并将缺页中断交给内核的 Page Fault Handler 处理,待处理过后在将进程放进就绪队列。
3.3.2缺页的原因
·访问数据被swap换出
·使用malloc新申请内存
malloc机制是延时分配内存,当使用malloc申请内存时并未真实分配物理内存,等到真正开始使用malloc申请的物理内存时发现没有才会启动申请,期间就会出现Page Fault。
·非法操作访问越界
这种情况产生的影响也是最大的,也是Coredump的重要来源,比如空指针解引用或者权限问题等都会出现缺页错误。
3.3.3 缺页异常处理流程
Page Fault Handler对不同情况缺页的处理:
以下内容引用自:https://www.zhihu.com/org/dong-li-jie-dian-55
Hard Page Fault 也被称为Major Page Fault,翻译为硬缺页错误/主要缺页错误,这时物理内存中没有对应的页帧,需要CPU打开磁盘设备读取Swap分区的对应内容写到物理内存中,再让MMU建立虚拟内存和物理内存的映射。
Soft Page Fault 也被称为Minor Page Fault,翻译为软缺页错误/次要缺页错误,这时物理内存中是存在对应页帧的,只不过可能是其他进程调入的,发出缺页异常的进程不知道而已,此时MMU只需要建立映射即可,无需从磁盘读取写入内存,一般出现在多进程共享内存区域。
Invalid Page Fault 翻译为无效缺页错误,比如进程访问的内存地址越界访问,又比如对空指针解引用内核就会报segment fault错误中断进程直接挂掉。
发生缺页中断的时候进入do_DataAbort,通过中断号进入注册好的处理函数中do_translation_fault
static struct fsr_info fsr_info[] = {
/*
* The following are the standard ARMv3 and ARMv4 aborts. ARMv5
* defines these to be "precise" aborts.
*/
{ do_translation_fault, SIGSEGV, SEGV_MAPERR, "section translation fault"},
{ do_page_fault, SIGSEGV, SEGV_MAPERR, "page translation fault" },
{ do_page_fault, SIGSEGV, SEGV_ACCERR, "page permission fault" },
};
asmlinkage void __exception
do_DataAbort(unsigned long addr, unsigned int fsr, struct pt_regs *regs)
{
if (!inf->fn(addr, fsr & ~FSR_LNX_PF, regs))
return;
}3.3.4 用户进程缺页异常的处理(略)
// 用户空间减去8M modules空间,剩下的是真正的进程空间
#define TASK_SIZE (UL(CONFIG_PAGE_OFFSET) - UL(0x01000000))
static int __kprobes
do_translation_fault(unsigned long addr, unsigned int fsr,
struct pt_regs *regs)
{
/*缺页异常发生在用户空间的处理入口*/
if (addr < TASK_SIZE)
return do_page_fault(addr, fsr, regs);
/* 缺页异常发生在内核空间
* ... ... ... */
return 0;
}缺页异常详细分析后面再开一篇新文章详细分解。。。。。。
3.3.5 用户页表刷新

前面提到,创建新的用户进程会单独拷贝内核页表和父进程的进程页表来组成自己的进程页表。当新进程开始写入新内容(写时复制),触发缺页中断,发生了新的物理页分配和映射。这时候就涉及到新进程的页表更新了。其逻辑图如上,发生物理页分配和映射的时候其实更新的是内核空间的内核页表,进程本地的内核页表要等到真正去访问物理页面的时候才会从内核空间拷贝到用户空间(迟滞访问)。
内核源码:
可以看到,当更新用户页表的时候,访问的内核页表发生了更新,导致要拷贝的内核页表没有映射(可能被交换出去,也可能被释放掉),带么直接走到了我们最常见到的内核oops报错。这就是我们常见的缺页oops异常产生的原因。
为什么内核页表缺失,不重新映射而是抛出oops呢?因为用户态进程去访问内核地址空间的时候,默认内核页表之前是已经映射过了的,直接去拷贝内核页表的映射内容即可;但是这时候对应的内核页表缺失只能说明这块映射在此期间被交换出去或者被破坏了,况且也不知道之前映射的是哪块物理页面,因此只能抛出oops异常!
#ifdef CONFIG_MMU
static int __kprobes
do_translation_fault(unsigned long addr, unsigned int fsr,
struct pt_regs *regs)
{
unsigned int index;
pgd_t *pgd, *pgd_k;
pud_t *pud, *pud_k;
pmd_t *pmd, *pmd_k;
if (addr < TASK_SIZE)
return do_page_fault(addr, fsr, regs);
/*
* FIXME: CP15 C1 is write only on ARMv3 architectures.
*/
pgd = cpu_get_pgd() + index;//从页表寄存器取出出错地址的entry,获取的是当前进程的mm->pgd页表
pgd_k = init_mm.pgd + index;//获取内核页表的PGD
/* ... ... ... ... */
pmd = pmd_offset(pud, addr);
pmd_k = pmd_offset(pud_k, addr);
if (pmd_none(pmd_k[index]))//如果待拷贝的内核页表entry是空的,直接做bad area处理
goto bad_area;
copy_pmd(pmd, pmd_k);// 开始拷贝刷新内核页表到用户进程空间的内核页表
return 0;
bad_area:
do_bad_area(addr, fsr, regs);
return 0;
}
void do_bad_area(unsigned long addr, unsigned int fsr, struct pt_regs *regs)
{
struct task_struct *tsk = current;
struct mm_struct *mm = tsk->active_mm;
/*
* If we are in kernel mode at this point, we
* have no context to handle this fault with.
*/
if (user_mode(regs))
__do_user_fault(tsk, addr, fsr, SIGSEGV, SEGV_MAPERR, regs);
else
__do_kernel_fault(mm, addr, fsr, regs);
}
/*
* Oops. The kernel tried to access some page that wasn't present.
*/
static void
__do_kernel_fault(struct mm_struct *mm, unsigned long addr, unsigned int fsr,
struct pt_regs *regs)
{
/*
* Are we prepared to handle this kernel fault?
*/
if (fixup_exception(regs))
return;
/*
* No handler, we'll have to terminate things with extreme prejudice.
*/
bust_spinlocks(1);
printk(KERN_ALERT
"Unable to handle kernel %s at virtual address %08lx\n",
(addr < PAGE_SIZE) ? "NULL pointer dereference" :
"paging request", addr);
show_pte(mm, addr);
die("Oops", regs, fsr); /* 内核页表映射的缺失 抛出oops */
bust_spinlocks(0);
do_exit(SIGKILL);
}















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









