







环境:
MacBook Air+ python3
爬虫技术简介:
一.类型
1.通用爬虫
起始地址URL发送请求---->解析响应,获取新的url---->下载存储网页信息--->发送新的请求 解析新的URL
2.聚焦爬虫
起始地址URL发送请求---->解析响应,获取新的url---->下载存储网页信息--->发送新的请求 解析新的URL
3.增量式爬虫
4.深层次爬虫
二.请求结构
·请求行 :请求方法 请求URL 协议以及版本
·请求头 :报文头包含若干个属性,格式为“属性名:属性值”,服务端据此获取客户端的信息,反扒一般会做在这里,这里的构造是重点
·请求体 :它将一个页面表单中的组件值通过param1=value1¶m2=value2的键值对形式编码成一个格式化串,它承载多个请求参数的数据
·空行 :换行符
三 响应结构
HTTP的响应报文也由三部分组成(响应行+响应头+响应体)
响应行:协议以及状态码
响应头:服务器信息
响应体:真正有效信息
和请求报文相比,响应报文多了一个“响应状态码”,它以“清晰明确”的语言告诉客户端本次请求的处理结果。
HTTP的响应状态码由5段组成:
1xx 消息,一般是告诉客户端,请求已经收到了,正在处理,别急…
2xx 处理成功,一般表示:请求收悉、我明白你要的、请求已受理、已经处理完成等信息.
3xx 重定向到其它地方。它让客户端再发起一个请求以完成整个处理。
4xx 处理发生错误,责任在客户端,如客户端的请求一个不存在的资源,客户端未被授权,禁止访问等。
5xx 处理发生错误,责任在服务端,如服务端抛出异常,路由出错,HTTP版本不支持等。
200 OK
四.爬虫协议
道德约束:你爬虫可以来爬 但是需要遵守我的约束!
五、headers请求
构造带有headers信息的请求,能够模拟手动点击 欺骗服务器
源码
import requests
from urllib.parse import quote
import env
import re
# # 网站访问请求头
baidu_header = {
'Cookie': 'BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; H_PS_PSSID=36560_37647_36920_37989_37802_37938_26350_37957_37881; PSINO=6; delPer=0; BDSVRTM=169; BD_CK_SAM=1; H_PS_645EC=4c18rx0nkoIvbMl5yyx5KTVB3aZlyAaOydRbV75iCutVjuTVI2Mf10u7%2BEU; ab_sr=1.0.1_NGZmMDU2MTFhYjIzZTYwMzU1ZTJiMDdhYWRkNzUyM2M1MDQ2ODRmMDgxYjY0NDI4NjUzYWVhZmI3MzJmMTAxNTU3ZmI1MDNkMjY5NDE1YTU0Mjc3NGQ3ZWIxNjE0ODEwMzVmNGEzZDBkNTJlNDljMmZhYjhjMzhmMjViMjkwZmYwZGU3ODM1OGE2M2I4YzM4MTFmYjVjM2ZmNTUwMzczYQ==; ZD_ENTRY=baidu; ZFY=FSUURJFJILl3b5spgLduOP23Fk4ZEbeZ1ZdH4sH20S8:C; BA_HECTOR=ah8l200g000k2001a52584781ht551s1l; newlogin=1; MCITY=-347%3A179%3A; BAIDUID=69180D11E23CE579E0830FB281264382:FG=1; __yjs_duid=1_2408c6280fcf615625d5e481c978baaf1619103223806; BIDUPSID=93FBE26AD6957DB38778F3B7C74E149D; PSTM=1514553704; FPTOKEN=CggjMgwLnWR45/RQCoI+hsKHKj2/r+awZrGhWyFleKTDzvVTaQxffq62Arf11KAK0nX8eVW7/hk46eEcvOTQtJWl0WMRpjg2qZQ6jcDiplLC2h5rYTUoVB8EaDf+McbZ5613hVy+LHFJkvl3WzxIqCcYUUEZvDWeWRlz9nIoWdVHLWn1zRnVGswtvMe/8hhre+Kq+efQk+nYIhJbtaa0+bbpjfUoVs4lQVAxS023Tk6Ewha9+irHZ9a8j0unfrBd2mOcrW3J51Q/Dg5065QlZfuM8Z5IfrZmii9UBrtlNnwiU3819axD4gYquI4RJKpO/SyDuWPKuTo+Cnv3WU//9Ks4f99T5WHOzTXbvy3Xb2i9qhUXfK7FzjytotF6BRVYQfwzrLRP4A60bcKTf/0s11kcG/o+bguzct6CtPoKDSkAIpyA6euFLuYji4ZvYkLg|wSTgbmmBUKPgSPIBExloPWbRifcMvK2uXJPaFaR/cMU=|10|c8dff7d879d84e92201c396c6e908ac2; __bid_n=185b0d764c474a5a104207; BD_UPN=143254'
, 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8'
, 'Accept-Encoding': 'br, gzip, deflate'
, 'Host': "www.baidu.com"
, 'User-Agent': "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/"
"13.1.2Safari/605.1.15"
}
east_money_header = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8'
, 'Upgrade-Insecure-Requests': '1'
, 'Host': 'guba.eastmoney.com'
, 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.1.2 Safari/605.1.15'
, 'Referer': 'http://guba.eastmoney.com/list,000519,99.html'
, 'Accept-Language': 'zh-cn'
, 'Connection': 'keep-alive'
}
def initial():
"""环境初始化"""
print("############################################################################################\n"
# # 常用网站
# 金融类
baidu_url = "https://www.baidu.com"
east_money_url = "http://guba.eastmoney.com"
xiu_qiu_url = "https://xueqiu.com"
# 政府官方网站
fa_gai_wei_url = "https://www.ndrc.gov.cn" # 发改委
PBOC_url = "http://www.pbc.gov.cn" # 人民银行
GOV_url = "http://www.gov.cn" # 中国政府网
# 公司官网
# #公共变量
global code
global key_words
# ################################# 函数定义 #################################
def input_params():
"""输入数据处理"""
global code
global key_words
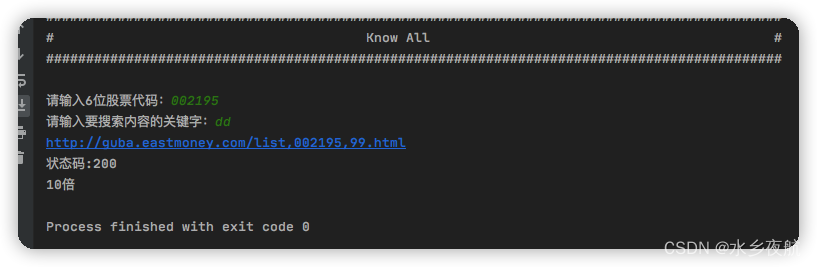
code = input("请输入6位股票代码:")
key_words = input("请输入要搜索内容的关键字:")
def east_money_info():
"""东财网站信息获取"""
# params = None, data = None,headers = None,cookies = None,files = None,auth = None, timeout = None,
# allow_redirects = True, proxies = None,hooks = None,stream = None,verify = None,cert = None,json = None,
# 'Referer': 'http://guba.eastmoney.com/list,000519,1,f.html'
old_code = re.search(pattern="[0-9]{6}", string=env.east_money_header["Referer"])
new_referer = env.east_money_header["Referer"].replace(old_code.group(), str(code))
print(new_referer)
response = requests.get(new_referer, headers=env.east_money_header) # 生成一个response对象
print("状态码:" + str(response.status_code)) # 打印状态码
print(re.search(pattern="10倍", string=response.content.decode()).group())
print(response.content.decode()) # 输出爬取的信息
#print(response.url)
# print(response.request.headers)
if __name__ == '__main__':
env.initial()
input_params()
east_money_info()
注意点:
Referer字段会随着不同页面变化,需要使用正则表达式进行过滤和替换,才能实现输入什么,爬什么
效果:自动根据输入的代码和关键字搜索页面相关信息,后期可以进行数据过滤 处理















 7万+
7万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









