







1. dt1 中有的数据,在dt2 中也有,取dt1中有,dt2中没有的数据
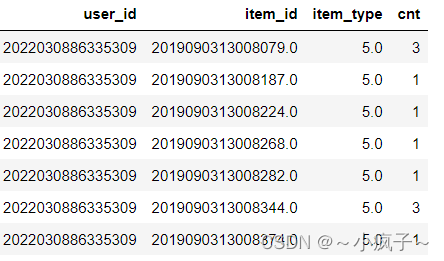
# 方法一:
user_push = pd.DataFrame(columns=dt1.columns)
for user, group in dt1.groupby(by=['user_id']):
push_history = dt2[dt2.user_id == user]['item_id'].values
group = group[~group.item_id.isin(push_history)]
if not group.empty:
# group = group.sample(1)
group.loc[:, 'user_id'] = user
user_push = pd.concat((user_push, group))
user_push
方法二:
slice_lable = (
dt1[['user_id','item_id']].apply(tuple, axis=1).isin(dt2[['user_id','item_id']].apply(tuple, axis=1).to_list())
)
slice_lable
user_push = dt1[~slice_lable]
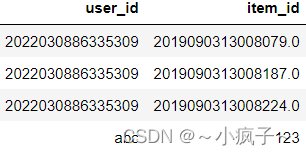
user_push返回结果:
2. 对dt1 中按照user_id 进行分组,按照cnt 进行排序,取用户的前n个
dt1.sort_values('cnt', ascending=False).groupby('user_id', as_index=False).first()
dt1.sort_values('cnt', ascending=False).groupby('user_id', as_index=False).head(4)
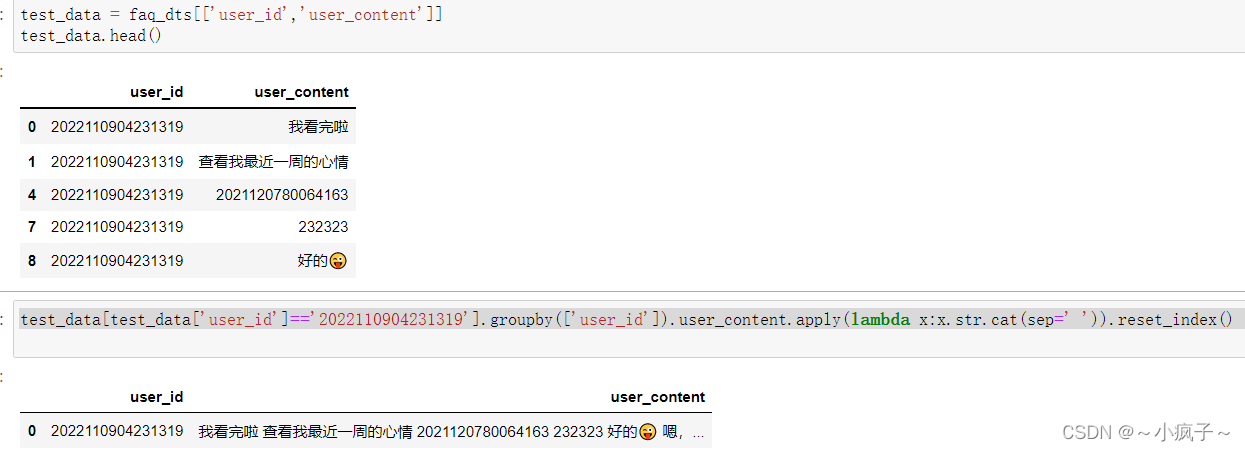
3. dataframe 进行分组,分组后将对应的数据进行按照一定的字符拼接
test_data = faq_dts[['user_id','user_content']]
test_data.head()
test_data[test_data['user_id']=='2022110904231319'].groupby(['user_id']).user_content.apply(lambda x:x.str.cat(sep=' ')).reset_index()
4. 把字符串的字典转化为字典类型
a = "{'name' : 'jim', 'sex' : 'male', 'age': 18}"
b = eval(a)
import json
c = json.loads(a)#c的类型也是字典类型的

















 404
404

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









