







大数据量处理的方案
- 分布式计算
- 列式存储
ClickHouse的性能
数据的查询性能:
不支持高并发,官方建议qps不超过100。
单表查询更有优势,不推荐多表联合查询。
每秒可处理1.2GB(亿行)数据,单机支撑40亿以上的数据查询无压力。
数据的写入性能
建议每次写入不少于1000行的批量写入,或每秒不超过一个写入请求
ClickHouse的特点
列式存储
同一个文件的数据类型一致,可实现高效压缩。
宽表查询时,需要处理的处理量可大大减小。
分区存储,查询时可跳过筛选条件外的分区。
数据落盘时,根据排序键将数据顺序写入。
根据主键,生成主键索引,加快检索效率;另外根据需要,还可建立二级索引。
(ClickHouse的索引均为稀疏索引,所以索引字段的区分度要适中)
并行处理(极限压榨CPU):
向量引擎:为了高效利用CPU,数据不仅按列存储,同时还按向量(列的一部分)进行处理。
复杂查询支持多核心并行处理
支持近似计算。
支持副本(高可用)、分片(水平扩容),单机性能已足够,分片特性不一定有用。
检索方式
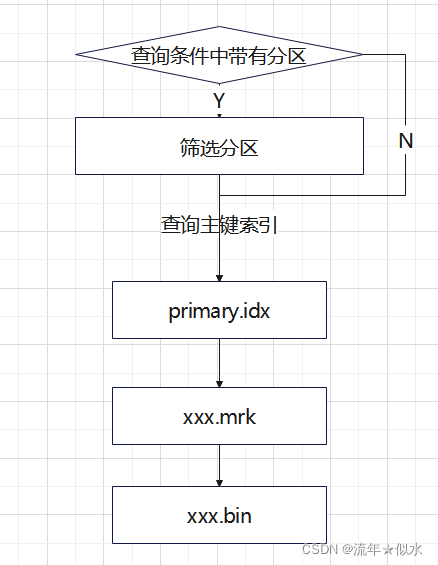
稀疏索引

二级索引
-
minmax:存储指定表达式的极值 -
set(max_rows):存储指定表达式的不重复值(不超过max_rows个,max_rows=0则表示无限制) -
ngrambf_v1(n, size_of_bloom_filter_in_bytes, number_of_hash_functions, random_seed):存储一个包含数据块中所有 n元短语(ngram) 的 布隆过滤器 。只可用在字符串上。可用于优化equals,like和in表达式的性能。-
n– 短语长度。 size_of_bloom_filter_in_bytes– 布隆过滤器大小,字节为单位。(因为压缩得好,可以指定比较大的值,如 256 或 512)。number_of_hash_functions– 布隆过滤器中使用的哈希函数的个数。-
random_seed– 哈希函数的随机种子。
-
-
tokenbf_v1(size_of_bloom_filter_in_bytes, number_of_hash_functions, random_seed)
跟ngrambf_v1类似,但是存储的是token而不是ngrams。Token是由非字母数字的符号分割的序列。 -
bloom_filter(bloom_filter([false_positive])– 为指定的列存储布隆过滤器,可选参数false_positive用来指定从布隆过滤器收到错误响应的几率。取值范围是 (0,1),默认值:0.025。
重要:
ClickHouse索引也遵循左缀原理,如果遇到查询瓶颈,可从该角度考虑优化查询语句,使其走索引。















 149
149











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









