







every blog every motto: There’s only one corner of the universe you can be sure of improving, and that’s your own self.
https://blog.csdn.net/weixin_39190382?spm=1010.2135.3001.5343
0. 前言
简单梳理Faster R-CNN
R-CNN
SSP-Net
Fast R-CNN
1. 正文
时间: 2015
论文: https://arxiv.org/abs/1506.01497
1.1 R-CNN系列 流程
1.1.1 R-CNN
流程:
- 利用selective search 在图像上选择2000个左右的候选区(Region Proposal)
- 将每个候选区缩放到227×227并输入到CNN,将CNN的fc7层输出作为特征
- 将上面提取到的特征输入SVM进行(二)分类
- 对SVM分好类的Region Proposal做边框回归,用Bounding box回归值校正原来的建议窗口,生成预测窗口坐标
缺点:
- 训练分多个阶段:微调网络、训练SVM、边框回归
- 训练耗时,占用磁盘空间大;CNN提取的特征由于要经过SVM分类,所以需要保存在本地,孔用几百G的空间
- 速度慢:使用GPU,一张图像需要47s
- 测试速度慢:每个候选区都需要经过CNN
1.1.2 Fast R-CNN
- 利用selective search 在原图上生成2000个候选区
- 将原图输入到CNN,进行特征提取
- 将候选区在映射到CNN最后的输出的特征图上
- 通过ROI pooling把每个候选区生成固定尺寸的特征图
- 利用softmax(分类)和smooth L1对分类概率和边框回归联合训练
相比R-CNN,主要有两处不同:
- CNN后加了ROI pooling
- 损失函数使用了多任务损失,将边框回归直接加到CNN网络中训练
改进:
- 不是将每个候选框都送入CNN,而是先输入整张原图,然后在得到特征图中找到候选框的映射位置
- 抛弃了SVM分类,而是使用softmax
- 分类和回归加入网络中
- 由于采用ROI Pooling,不需要对输入图像进行crop和wrap操作,避免信息丢失
1.1.3 Faster R-CNN
- 将原图输入CNN,进行特征提取
- 用RPN生成一堆Anchor box,对其进行裁剪过滤后通过softmax判断anchors属于前景还是背景(即,是物体/非物体),二分类任务。同时,另一个分支bounding box regression修正anchor box,形成相对精确的proposal
- 把建议候选框映射到CNN生成的特征图上
- 通过ROI Pooling层使每个ROI生成固定尺寸的特征图
- 利用softmax和smooth L1对分类概率和边框回归联合训练。
相比Fast R-CNN,主要不同:
- 使用RPN(Region Proposal Network)代替原来的selective search 方法产生的候选框
- 产生候选框的CNN和目标检测的CNN共享
改进:
Faster R-CNN创造性的采用卷积神经网络产生候选框,并且和目标检测的网络共享网络,使得候选框数目从原来的2000个减少到300个,且建议候选框质量有一定提高
一句话概况: Faster R-CNN 将候选框提议、特征提取、bounding box 回归、分类都整合到一起了,使得综合性能较大提高。
1.2 Faster R-CNN流程详解
整体流程图:
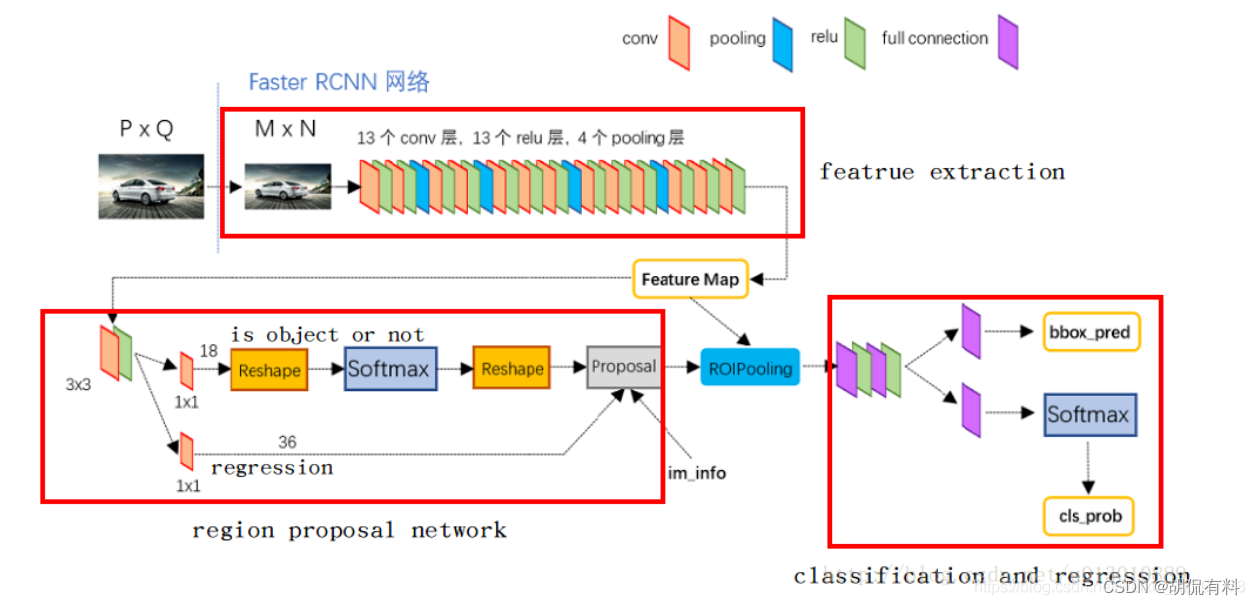
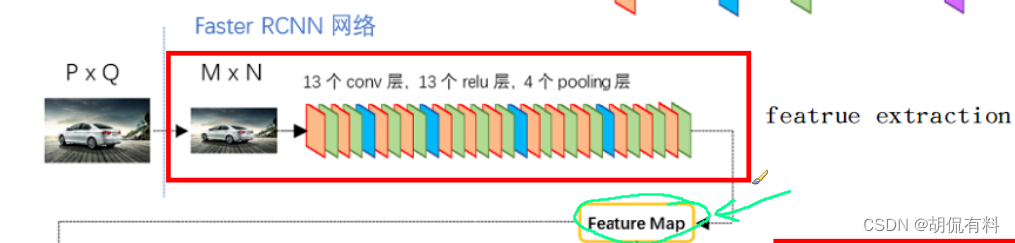
1.2.1 原图输入CNN
原图输入CNN后生成特定的特征图,
1.2.2 RPN (Region Proposal Network)操作
1. anchor
第一步的特征图提取中,我们以VGG16为例,输入图像进行了16倍下采样。即生成的特征图到一个像素点对应原图中16×16的区域(感受野)
**重点: ** 特征图上每个的像素点称为anchor(锚点)
更准确的说:
第一步生成的特征图 经过3×3的卷积(striding=1,padding=1)操作,特征图与卷积核(滑动窗口)的中心点(因为,padding=1,这个中心点就是特征图的中心)
根据anchor,可以在原图上生成9种不同的尺寸不同长宽比的边框,
尺寸:128×128、256×256、512×512
长宽比:1:2、1:1、2:1
所以共有9种。VGG16生成的特征图大小为40*60,因此一种生成40×60×9 个 anchor box.
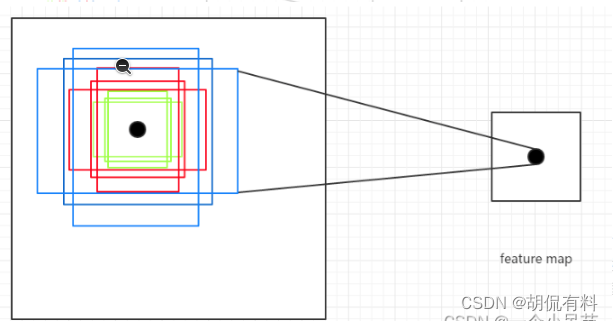
说明: 上面我们提到一个像素点对应原图16×16的大小的区域。我们又说三种不同的尺寸128、256、512,这难道不矛盾吗?其实是将16×16放大到这三种尺寸了。
2. 分类和回归
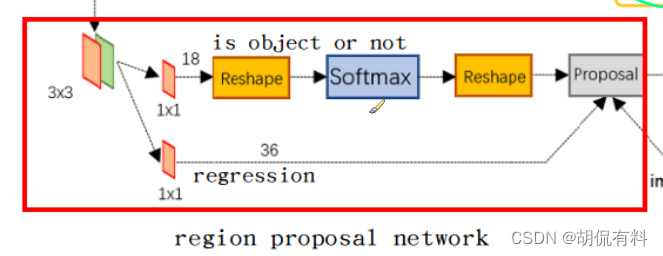
- 将anchor进行二分类,判断是positive 还是negative,即判断框内是否有目标,so easy是不是。
- bounding box regression: 边框回归,修正上面的anchor box,得到较为准确的结果。
最后的proposal结点负责综合positive anchors和对应的bounding boxregression偏移量获取修正后的proposals,同时剔除大小和超出边界的proposals,到这里相当于完成了目标定位的功能。
proposal是RPN的最后一个步骤,输入有三个:
k为anchor数,文中默认为9
- 分类层,生成的(M/16,N/16,2k),二分类,所以是2*k
- 回归层,生成的(M/16,N/16,4K),四个坐标值,所以是4*k
- im_info,[M,N,scale_factor]
- 利用回归层的偏移量,对所有原始的anchor 进行修正
- 利用分类的scores,按positives scores由大到小排列所有的anchor ,取前topN个
- 边界处理,把超出图像边界的positive anchor 超出部分收拢到图像边界处,防止后续的ROI pooling超出边界
- 剔除尺寸非常小的positive anchor
- 对剩余的positive anchors进行NMS(非极大抑制)
- 最后输出一堆的proposals左上角和右下角的坐标([x1,y1,x2,y2])
1.2.3 ROI
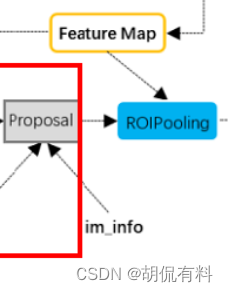
ROI层负责手机proposal,并计算proposal feature map(从第一步生成的特征图中抠出对应的位置,对抠出的特征图进行池化就是ROI过程)
输入有两个:
- 卷积层生成的特征图
- RPN网络生成的proposals(一堆的坐标[x1,y1,x2,y2])
主要是因为后续输入进全连接,全连接层需要固定的向量,具体可参考前面的文章
1.2.4 分类
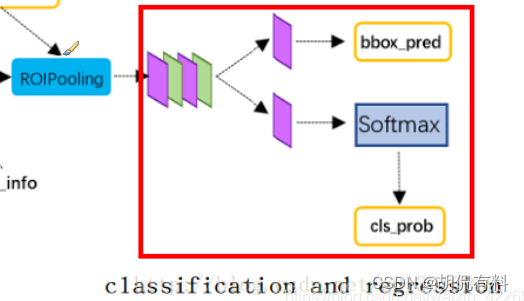
在RPN中已经有过分类,但那个分类是二分类,即区分box中是否有目标。
这里的分类的对positive anchor 识别具体是哪一类。
同时,会对边框进行回归,获得更高精度的box
由于并非要用faster R-CNN做什么,仅为后续阅读铺垫,故不做深入。更多细节参考后续参考文章
参考
[1] https://zhuanlan.zhihu.com/p/31426458
[2] https://blog.csdn.net/weixin_42310154/article/details/119889682#t7
[3] https://blog.csdn.net/weixin_55775980/article/details/125194384
[4] https://blog.csdn.net/qq_30121457/article/details/108918499
[5] http://events.jianshu.io/p/aa659406d8c4




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











