







every blog every motto: You can do more than you think.
https://blog.csdn.net/weixin_39190382?type=blog
0. 前言
swin
1. 前言
论文: https://arxiv.org/pdf/2103.14030v1.pdf
时间: 2021.3.25
作者: Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo
2. 网络
2.1 整体结构
网络的整体结构如下:
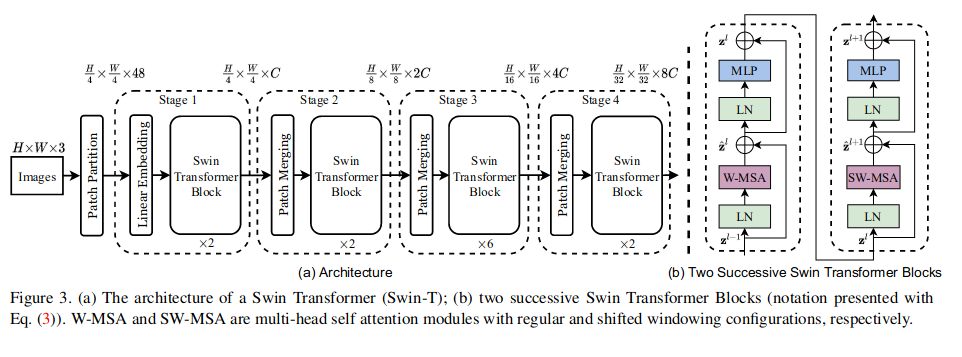
主要有三部分组成:
- patch embedding
- patch merging
- sin Transformer block
2.2 embedding
在之间的vit中,通过将图片切割成不同的patch,然后将每个patch转成token形式,即一个patch代表一个token。
如,我们的输入图片大小为(224,224),切割成patch大小为(4,4),那么我们的输入图片就可以被切割成(56,56)个patch。
具体的实现只需要用卷积就行,把步幅设置成卷积核大小即可。
nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
这样,我们就将一张图片shape改变了:(224,224,3)->(56,56,96)
不同与vit的点在于其中涉及到window的概念。在vit中,每个patch和所有的patch进行计算。计算量是 N p a t c h 2 N_patch^2 Npatch2,这个计算量是很大的。
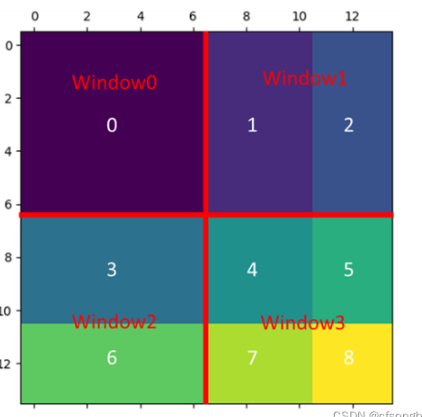
在swin中,我们引入了window的概念。即,将patch分成不同的组(window),一个窗口(window)里面有少量的patch。仅在窗口内部进行计算attention,这样计算就大大降低了,计算机中的常用的分而治之思想。
如果不理解的话,想象切豆腐,横切一刀竖切一刀。这样豆腐就变成了4块(window)。每块里面在更进一步切成更小的子块(patch)。
如下:
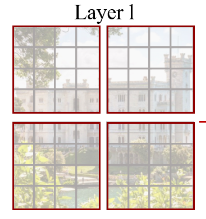
但是这里面涉及到一个,上面的window分割,是无重叠的,降低计算量是依赖局部计算,这就意味着只计算了局部的相关性,丢失了全局相关性。
如何按下不表,后面我们在讨论
2.3 patch merging
整个网络是Sin Transformer Block(STB)和Pactch Merging(PM)不断堆叠而来。有点类似VGG的感觉。这里,我们先介绍一下PM模块。
PM模块是进行降采样。如下图。
因为我们输入的是一个token形式,所以是2维的。所以会有一个维度转换的关系:(B,H * W,C) -> (B,H,W,C)。
然后,间隔一个像素采样,合成一个新的特征图。因为起始点的不同,所有有4张特征图,再将这4张特征图再通道方向上进行合并。
这样分辨率变成原来的一半,通道维度扩大4倍。后面会跟一个通道减少的线性变换,使得通道变为原来的2倍。
PM中间过程的shape变化:(h,w,c) -> (h * w/2,c * 4)-> (h * w/2,c * 2)。
PM最后输出的时候会有一个逆操作。(B,H,W,C) -> (B,H * W,C)。
整体的token shape: (B,L,C) -> (B,L/4,C * 4) -> (B,L/4,C*2)
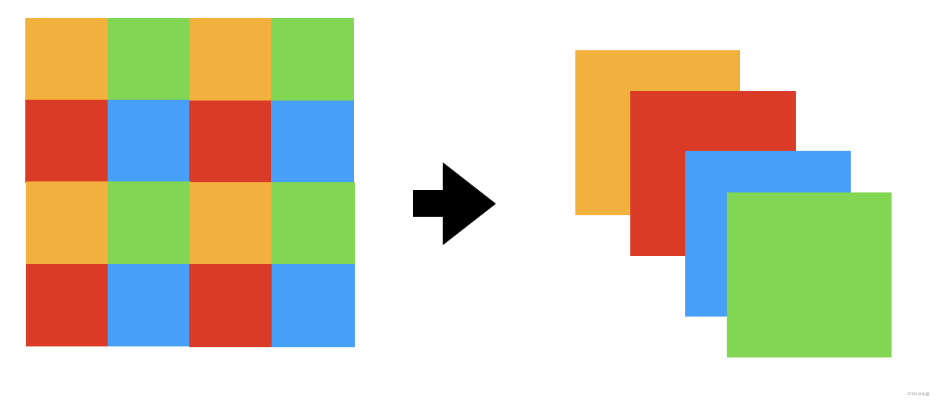
具体代码如下:
class PatchMerging(nn.Module):
r""" Patch Merging Layer.
Args:
input_resolution (tuple[int]): Resolution of input feature.
dim (int): Number of input channels.
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
"""
def __init__(self, input_resolution, dim, norm_layer=nn.LayerNorm):
super().__init__()
self.input_resolution = input_resolution
self.dim = dim
self.reduction = nn.Linear(4 * dim, 2 * dim, bias=False)
self.norm = norm_layer(4 * dim)
def forward(self, x):
"""
x: B, H*W, C
"""
H, W = self.input_resolution
B, L, C = x.shape
assert L == H * W, "input feature has wrong size"
assert H % 2 == 0 and W % 2 == 0, f"x size ({H}*{W}) are not even."
x = x.view(B, H, W, C)
x0 = x[:, 0::2, 0::2, :] # B H/2 W/2 C
x1 = x[:, 1::2, 0::2, :] # B H/2 W/2 C
x2 = x[:, 0::2, 1::2, :] # B H/2 W/2 C
x3 = x[:, 1::2, 1::2, :] # B H/2 W/2 C
x = torch.cat([x0, x1, x2, x3], -1) # B H/2 W/2 4*C
x = x.view(B, -1, 4 * C) # B H/2*W/2 4*C
x = self.norm(x)
x = self.reduction(x)
return x
2.4 Sin Transformer Block
Sin Transformer Block是整个网络的核心。
2.4.1 整体结构
整体结构如下,两个串联的子模块作为一个单元。
说明:
- W-MSA和SW-MSA是交替,成对出现
- 下图的一半即是STB模块
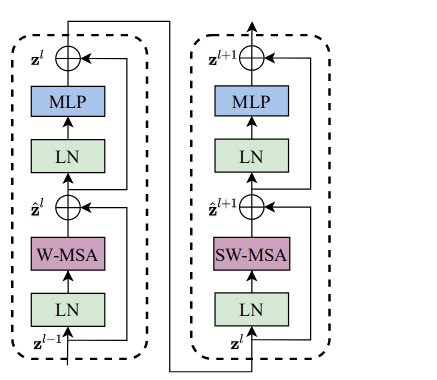
与标准的Transformer不同在于第一个模块中用的是W-MSA,第二个模块中用的是SW-MSA。
W-MSA就是在patch embedding中介绍的在window内部计算Multi-Head Self-Attention。而SW-MSA作用就是弥补上面介绍的由于W-MSA操作而丢失全局相关性的问题。
2.4.2 SW-MSA
这个模块是在W-MSA上加了一个移动(shift)。如,一张图片里面的内容向上、向左移动x个像素,超出部分填充在最下边和最右边。直观理解如下图:
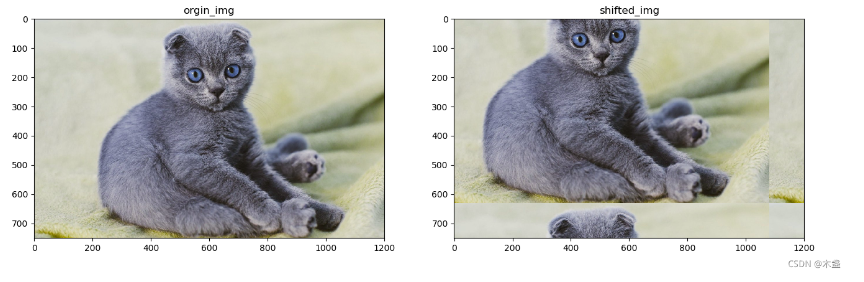
然后再划分成不同的window,再window内部计算attention。现在看下面这张图应该比较好理解了。
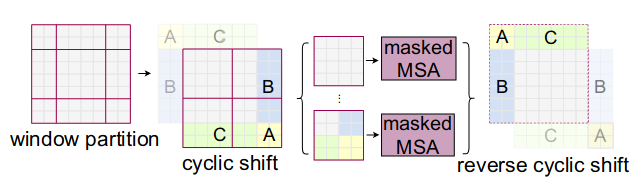
这里涉及到一个关键的点,即通过将图片移动,会有部分图片原始位置“不相邻”变成“相邻”,如下图中相邻的区域用同一种颜色表示。我们以其中的左图的左上角
的黄色方块举例,当移动移动,他被移动到右下角,但是他和原本的4、5、7在原图上是不相邻的。如果我们及计算他们的attention,那么是有问题的。
所以就用到mask!
核心思想是,只计算在原图相邻位置之间的attetion。
简单来说,他的逻辑是将相邻区域设置为0,不相邻区域设置为-100。计算的注意力和这个mask相加再进经过softmax,softmax(-100)梯度非常小,不激活。
还有另一个小的trick,就是共享key。
2.5 小结
亮点主要在:
- 划分不同的window,计算window内部的patch之间的attention,降低了计算量
- 丢失了全局相关信息,引入了移动窗口,来平衡上面的问题
- 最后就是mask和共享key的使用
总的来说,上述改变也在情理之中(分而治之思想),有点类似之间卷积网络时期产生的各种变形卷积。
参考
- https://zhuanlan.zhihu.com/p/362672090
- https://zhuanlan.zhihu.com/p/401661320
- https://www.zhihu.com/question/485266305
- https://muzhan.blog.csdn.net/article/details/120826980
- https://blog.csdn.net/qq_16227333/article/details/125116344
- https://blog.csdn.net/leviopku/article/details/120822635
- https://blog.csdn.net/weixin_42899627/article/details/116095067




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











