







引入
图算法指利用特制的线条算图求得答案的一种简便算法。无向图、有向图和网络能运用很多常用的图算法,这些算法包括:各种遍历算法(这些遍历类似于树的遍历),寻找最短路径的算法,寻找网络中最低代价路径的算法,回答一些简单相关问题(例如,图是否是连通的,图中两个顶点间的最短路径是什么,等等)的算法。图算法可应用到多种场合,例如:优化管道、路由表、快递服务、通信网站等。
GraphFrames提供与GraphX相同的标准图形算法套件以及一些新的算法。
目前,某些算法由GraphX的API实现的,因此在GraphFrames中可能没有比GraphX更可扩展的功能。
目前,我们的业务涉及到企业知识图谱,需要做路径搜索、社区发现、标签传播等基于图计算的应用,虽然neo4j也可以做,但是neo4j的分布式版本价格很高。于是考虑使用spark做分布式的图计算。
本文不介绍太多算法细节,主要展示官网和实际案例的代码实现。
广度优先搜索
广度优先搜索(Breadth-first search,简称BFS),是查找一个顶点到另外一个顶点的算法。
这里是用pyspark自带的friends数据集,实现路径搜索。
我们先看看friends数据集长啥样。
from pyspark import SparkContext
from pyspark.sql import SQLContext
from graphframes.examples import Graphs
# spark
sc = SparkContext("local", appName="mysqltest")
sqlContext = SQLContext(sc)
g = Graphs(sqlContext).friends()
g.vertices.show()
g.edges.show()
有7个节点代表7个人,然后用7个关系展示他们的人际关系,有friend和follow两种关系。
+---+-------+---+
| id| name|age|
+---+-------+---+
| a| Alice| 34|
| b| Bob| 36|
| c|Charlie| 30|
| d| David| 29|
| e| Esther| 32|
| f| Fanny| 36|
+---+-------+---+
+---+---+------------+
|src|dst|relationship|
+---+---+------------+
| a| b| friend|
| b| c| follow|
| c| b| follow|
| f| c| follow|
| e| f| follow|
| e| d| friend|
| d| a| friend|
+---+---+------------+
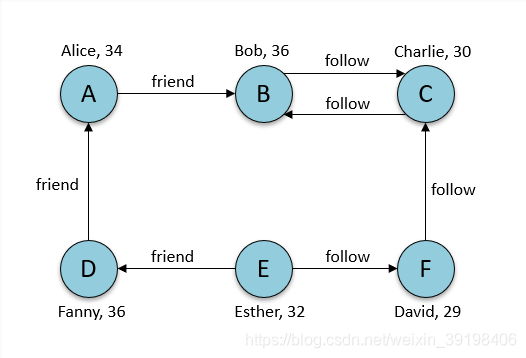
然后用BFS的API来做路径搜索,分别定义起点和终点的条件。
paths = g.bfs("name = 'Esther'", "age < 32")
paths.show()
+---------------+--------------+--------------+
| from| e0| to|
+---------------+--------------+--------------+
|[e, Esther, 32]|[e, d, friend]|[d, David, 29]|
+---------------+--------------+--------------+
可以看到,满足节点名称为Esther的有两条关系,但指向节点age小于32的只有David了,如图所示。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 4345
4345











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









