







图像分类
目标:已有固定分类标签集合,对输入的图像,从分类标签集合中找出一个分类标签,最后把分类标签分配给该输入图像。这是计算机视觉领域核心问题之一。后面许多看似不同的问题(物体检测和分割)都可被归结为图像分类
困难和挑战:
- 视角变化(Viewpoint variation)
- 大小变化(Scale variation)
- 形变(Deformation)
- 遮挡(Occlusion)
- 光照条件(Illumination conditions)
- 背景干扰(Background clutter)
- 类内差异(Intra-class variation)

--------------------------------------------------------------------------------------------------------------------------
数据驱动方法:给计算机很多数据,然后实现学习算法,让计算机学习到每个类的外形。这种方法,就是数据驱动方法。
该方法第一步就是收集已经做好分类标注的图片来作为训练集,下面就看看数据库长什么样:

这是一个有4个视觉分类的训练集。实际中,可能有上千的分类,每个分类有成千上万图像。
--------------------------------------------------------------------------------------------------------------------------
图像分类流程:图像分类就是输入一个元素为像素值的数组,然后分配给他一个分类标签,完整流程:
- 输入:输入包含N个图像的集合,每个图像的标签是K种分类标签的一种。这个集合称为训练集。
- 学习:使用训练集来学习每个类到底长什么样。该步骤称为训练分类器或学习一个模型。
- 评价:让分类器预测从未见过的图像的分类标签并以此来评价分类器质量。把分类器预测的标签和图像真正的分类标签对比。
Nearest Neighbor分类器(最近邻分类器)简称NN
通过实现它来让读者对解决图像分类问题的方法有个基本认识。
图像分类数据集:CIFAR-10包含了60000张32X32小图像。每张图像有10种分类标签中的一种。这60000张图像被分为包含50000张图像的训练集和包含10000张图像的测试集。
NN算法将会拿测试图片和训练集中每一张图去比较,然后将它认为最相似的那个训练集图片的标签赋给这张测试图片。
比较两张32x32x3图片的方法:最简单的就是逐个像素比较,最后将差异值累加。即将两张图转化为向量I1和I2后计算他们的L1距离:
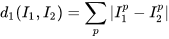
流程图例:

若两张图一模一样,L1距离为0,但两张图片很不一样,那L1值会非常大。
距离选择:计算向量间的距离有多种方法,另一个常用的方法是L2距离,从几何学的角度,可以理解为它在计算两个向量间的欧式距离。L2距离的公式如下:

L1和L2比较:在面对两个向量之间的差异时,L2比L1更加不能容忍这些差异。也就是说,相对于1个巨大的差异,L2距离更倾向于接受多个中等程度的差异。
代码:
待补充
----------------------------------------------------------------------------------------------------------------
k-Nearest Neighbor分类器(k近邻分类器)简称kNN
为什么不能用最相似的k张图片的标签来作为测试图像的标签呢?使用kNN分类器能取得更好效果。当k=1的时候,kNN分类器就是NN分类器。
思想:找最相似的k个图片的标签,然后让他们针对测试图片进行投票,最后把票数最高的标签作为对测试图片的预测。直观感受上,更高的k值会让分类的效果更平滑,使分类器对异常值更有抵抗力。

上例使用2维的点,分3类(红,蓝和绿)。不同颜色区域代表用L2距离的分类器决策边界。白色区域是分类模糊的例子(即图像与两个以上的分类标签绑定)。
在NN分类器中,异常的数据点(比如:在蓝色区域中的绿点)制造出一个不正确预测的孤岛。
5-NN分类器将这些不规则都平滑了,使它针对测试数据的泛化(generalization)能力更好(例子中未展示)。5-NN中也存在一些灰色区域,是因为近邻标签的最高票数相同导致的(比如:2个邻居是红色,2个邻居是蓝色,还有1个是绿色)。
在实际中,大多使用k-NN分类器。但是k值如何确定呢?接下来第二弹就讨论这个问题。
------------------------------------------------------------------------------------------------------------
以上内容转载整理来自知乎专栏点击打开链接,侵删侵删。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









