








目录
本节实战
| 实战名称 |
|---|
| 💘 实战:NodeLocal DNSCache-2022.7.30(测试成功) |
| 💘 实战:NodeLocal DNSCache-2023.2.21(测试成功) |
DNS优化
前面我们讲解了在 Kubernetes 中我们可以使用 CoreDNS 来进行集群的域名解析,但是如果在集群规模较大并发较高的情况下我们仍然需要对 DNS 进行优化,典型的就是大家比较熟悉的 CoreDNS 会出现超时5s的情况。
1、dns 5s 超时问题
DNS 解析出现的 5s 超时的问题,并不是 Kubernertes 的问题,而是 conntrack 的一个 bug,也就是连接跟踪表。Weave works 的工程师 Martynas Pumputis 对这个问题做了很详细的分析:https://www.weave.works/blog/racy-conntrack-and-dns-lookup-timeouts。由于 conntrack 涉及到内核的一些知识,这里我们也不用太深入了,感兴趣的可以自行去了解,可以参考文章
https://opengers.github.io/openstack/openstack-base-netfilter-framework-overview/ 进行更多了解。
以上2篇文章已下载到本地:
Racy conntrack and DNS lookup timeouts-2023.2.19-剪藏
云计算底层技术 - netfilter 框架研究 _ opengers-2023.2.19-剪藏

我们简单总结下:当加载内核模块 nf_conntrack 后,conntrack 机制就开始工作,对于每个通过 conntrack 的数据包,内核都为其生成一个 conntrack 条目用以跟踪此连接,对于后续通过的数据包,内核会判断若此数据包属于一个已有的连接,则更新所对应的 conntrack 条目的状态(比如更新为 ESTABLISHED 状态),否则内核会为它新建一个conntrack 条目。所有的 conntrack 条目都存放在一张表里,称为连接跟踪表。连接跟踪表存放于系统内存中,可以用cat /proc/net/nf_conntrack 查看当前跟踪的所有 conntrack 条目(Ubuntu 则是 conntrack 命令)。
而出现该问题的根源在于 DNS 客户端( glibc 或 musl libc )会并发请求 A(ipv4 地址)和 AAAA(ipv6 地址)记录,跟 DNS Server 通信自然会先 connect 建立 fd,后面请求报文使用这个 fd 来发送,由于 UDP 是无状态协议,connect 时并不会创建 conntrack 表项, 而并发请求的 A 和 AAAA 记录默认使用同一个 fd 发包,这时它们源Port 相同,当并发发包时,两个包都还没有被插入 conntrack 表项,所以 netfilter 会为它们分别创建conntrack 表项,而集群内请求 kube-dns 都是访问的 Cluster-IP,报文最终会被 DNAT 成一个 endpoint 的Pod IP,当两个包被 DNAT 成同一个 IP,最终它们的五元组就相同了,在最终插入的时候后面那个包就会被丢掉,如果dns 的 pod 副本只有一个实例的情况就很容易发生,现象就是 dns 请求超时,client 默认策略是等待 5s 自动重试,如果重试成功,我们看到的现象就是 dns 请求有 5s 的延时。
netfilter conntrack 模块为每个连接创建 conntrack 表项时,表项的创建和最终插入之间还有一段逻辑,没有加锁,是一种乐观锁的过程。conntrack 表项并发刚创建时五元组不冲突的话可以创建成功,但中间经过 NAT 转换之后五元组就可能变成相同,第一个可以插入成功,后面的就会插入失败,因为已经有相同的表项存在。比如一个 SYN 已经做了NAT 但是还没到最终插入的时候,另一个 SYN 也在做 NAT,因为之前那个 SYN 还没插入,这个 SYN 做 NAT 的时候就认为这个五元组没有被占用,那么它 NAT 之后的五元组就可能跟那个还没插入的包相同。
所以总结来说,根本原因是内核 conntrack 模块的 bug,**DNS client(在 linux 上一般就是 上一般就是 resolver)**会并发地请求 A 和 AAAA 记录,netfilter 做 NAT 时可能发生资源竞争导致部分报文丢弃。
- 只有多个线程或进程,并发从同一个 socket 发送相同五元组的 UDP 报文时,才有一定概率会发生
- glibc、musl(alpine 的 libc 库)都使用 parallel query ,就是并发发出多个查询请求,因此很容易碰到这样的冲突,造成查询请求被丢弃
- 由于 ipvs 也使用了 conntrack, 使用 kube-proxy 的 ipvs 模式,并不能避免这个问题
解决办法
要彻底解决这个问题最好当然是内核上去 FIX 掉这个 BUG,除了这种方法之外我们还可以使用其他方法来进行规避,我们可以避免相同五元组 DNS请求的并发。
在 resolv.conf 中就有两个相关的参数可以进行配置:
single-request-reopen:发送 A 类型请求和 AAAA 类型请求使用不同的源端口,这样两个请求在 conntrack 表中不占用同一个表项,从而避免冲突。single-request:避免并发,改为串行发送 A 类型和 AAAA 类型请求。没有了并发,从而也避免了冲突。
要给容器的 resolv.conf 加上 options 参数,有几个办法:
-
在容器的
ENTRYPOINT或者CMD脚本中,执行/bin/echo 'options single-request-reopen' >> /etc/resolv.conf(不推荐) -
在 Pod 的 postStart hook 中添加:(不推荐)
lifecycle: postStart: exec: command: - /bin/sh - -c - "/bin/echo 'options single-request-reopen' >> /etc/resolv.conf -
使用
template.spec.dnsConfig配置:template: spec: dnsConfig: options: - name: single-request-reopen -
使用 ConfigMap 覆盖 Pod 里面的
/etc/resolv.conf:# configmap apiVersion: v1 data: resolv.conf: | nameserver 1.2.3.4 search default.svc.cluster.local svc.cluster.local cluster.local options ndots:5 single-request-reopen timeout:1 kind: ConfigMap metadata: name: resolvconf --- # Pod Spec spec: volumeMounts: - name: resolv-conf mountPath: /etc/resolv.conf subPath: resolv.conf # 在某个目录下面挂载一个文件(保证不覆盖当前目录)需要使用subPath -> 不支持热更新 ... volumes: - name: resolv-conf configMap: name: resolvconf items: - key: resolv.conf path: resolv.conf -
使用 TCP:默认情况下 dns 的请求一般都是使用 UDP 请求的, 因为力求效率,不需要三握四挥。由于 TCP 没有这个问题,我们可以在容器的 resolv.conf 中增加
options use-vc, 强制 glibc 使用 TCP 协议发送DNS query。template: spec: dnsConfig: options: - name: use-vc -
使用
MutatingAdmissionWebhook,用于对一个指定的资源的操作之前,对这个资源进行变更。我们也可以通过 MutatingAdmissionWebhook 来自动给所有 Pod 注入上面第三或第四种方法中的相关内容。
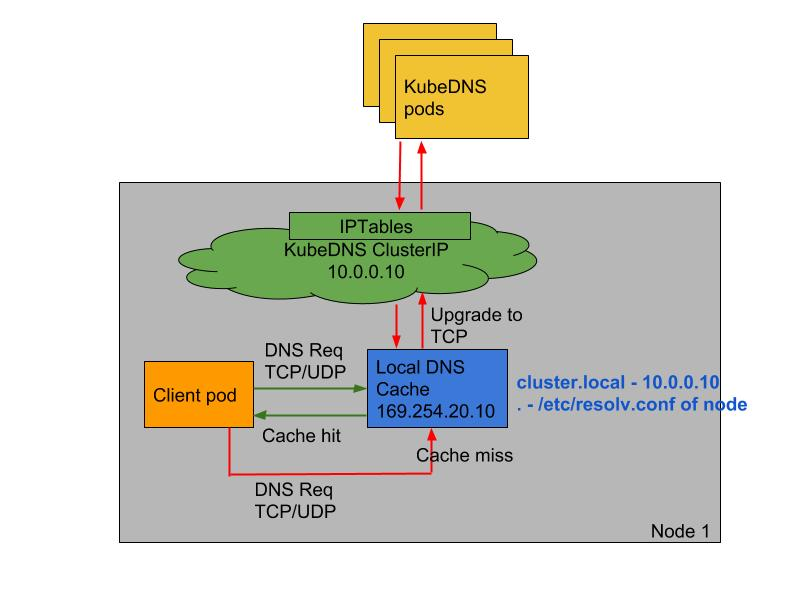
上面的方法在一定程度上可以解决 DNS 超时的问题,但更好的方式是使用本地 DNS 缓存,容器的 DNS 请求都发往本地的 DNS 缓存服务,也就不需要走 DNAT,当然也不会发生 conntrack 冲突了,而且还可以有效提升 CoreDNS 的性能瓶颈。
2、NodeLocal DNSCache
NodeLocal DNSCache 通过在集群节点上运行一个 DaemonSet 来提高集群 DNS 性能和可靠性。**处于 ClusterFirst 的 DNS 模式下的 Pod 可以连接到 kube-dns 的 serviceIP 进行 DNS 查询,**通过 kube-proxy 组件添加的 iptables 规则将其转换为 CoreDNS 端点。通过在每个集群节点上运行 DNS 缓存,NodeLocal DNSCache可以缩短 DNS 查找的延迟时间、使 DNS 查找时间更加一致,以及减少发送到 kube-dns 的 DNS 查询次数。
在集群中运行 NodeLocal DNSCache 有如下几个好处:
- 如果本地没有 CoreDNS 实例,则具有最高 DNS QPS 的 Pod 可能必须到另一个节点进行解析,使用
NodeLocal DNSCache后,拥有本地缓存将有助于改善延迟。 - 跳过 iptables DNAT 和连接跟踪将有助于减少 conntrack 竞争并避免 UDP DNS 条目填满 conntrack 表(上面提到的5s超时问题就是这个原因造成的)
注意:这里改成TCP的话,也是可以有效果的 - 从本地缓存代理到 kube-dns 服务的连接可以升级到 TCP,TCP conntrack 条目将在连接关闭时被删除,而 UDP 条目必须超时过后(默认
nfconntrackudp_timeout是 30 秒) - 将 DNS 查询从 UDP 升级到 TCP 将减少归因于丢弃的 UDP 数据包和 DNS 超时的尾部等待时间,通常长达 30 秒(3 次重试+ 10 秒超时)
💘 实战:NodeLocal DNSCache-2023.2.21(测试成功)
- 实验环境
实验环境:
1、win10,vmwrokstation虚机;
2、k8s集群:3台centos7.6 1810虚机,1个master节点,2个node节点
k8s version:v1.20.0
docker://20.10.7 #containerd都是一样的,次方法也使用k8s1.22/1.25
2021.12.28-实验软件-nodelocaldns
链接:https://pan.baidu.com/s/1cl474vfrXvz0hPya1EDIlQ
提取码:lpz1
nodelocaldns.yaml

1.获取NodeLocal DNSCache的资源清单
要安装 NodeLocal DNSCache 也非常简单,直接获取官方的资源清单即可:
wget https://github.com/kubernetes/kubernetes/raw/master/cluster/addons/dns/nodelocaldns/nodelocaldns.yaml
[root@master1 ~]#wget https://github.com/kubernetes/kubernetes/raw/master/cluster/addons/dns/nodelocaldns/nodelocaldns.yaml
--2021-12-28 16:38:36-- https://github.com/kubernetes/kubernetes/raw/master/cluster/addons/dns/nodelocaldns/nodelocaldns.yaml
Resolving github.com (github.com)... 20.205.243.166
Connecting to github.com (github.com)|20.205.243.166|:443... connected.
HTTP request sent, awaiting response... 302 Found
Location: https://raw.githubusercontent.com/kubernetes/kubernetes/master/cluster/addons/dns/nodelocaldns/nodelocaldns.yaml [following]
--2021-12-28 16:38:36-- https://raw.githubusercontent.com/kubernetes/kubernetes/master/cluster/addons/dns/nodelocaldns/nodelocaldns.yaml
Resolving raw.githubusercontent.com (raw.githubusercontent.com)... 185.199.108.133, 185.199.111.133, 185.199.109.133, ...
Connecting to raw.githubusercontent.com (raw.githubusercontent.com)|185.199.108.133|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 5334 (5.2K) [text/plain]
Saving to: ‘nodelocaldns.yaml’
100%[===================================================================>] 5,334 --.-K/s in 0.1s
2021-12-28 16:38:37 (51.4 KB/s) - ‘nodelocaldns.yaml’ saved [5334/5334]
[root@master1 ~]#ll nodelocaldns.yaml
-rw-r--r-- 1 root root 5334 Dec 28 16:38 nodelocaldns.yaml
[root@master1 ~]#
……
#该资源清单文件中我们重点看下 NodeLocalDNS 的配置对象:
---
apiVersion: v1
kind: ConfigMap
metadata:
name: node-local-dns
namespace: kube-system
labels:
addonmanager.kubernetes.io/mode: Reconcile
data:
Corefile: |
__PILLAR__DNS__DOMAIN__:53 {
errors
cache {
success 9984 30
denial 9984 5
}
reload
loop
bind __PILLAR__LOCAL__DNS__ __PILLAR__DNS__SERVER__
forward . __PILLAR__CLUSTER__DNS__ {
force_tcp
}
prometheus :9253
health __PILLAR__LOCAL__DNS__:8080
}
in-addr.arpa:53 {
errors
cache 30
reload
loop
bind __PILLAR__LOCAL__DNS__ __PILLAR__DNS__SERVER__
forward . __PILLAR__CLUSTER__DNS__ {
force_tcp
}
prometheus :9253
}
ip6.arpa:53 {
errors
cache 30
reload
loop
bind __PILLAR__LOCAL__DNS__ __PILLAR__DNS__SERVER__
forward . __PILLAR__CLUSTER__DNS__ {
force_tcp
}
prometheus :9253
}
.:53 {
errors
cache 30
reload
loop
bind __PILLAR__LOCAL__DNS__ __PILLAR__DNS__SERVER__
forward . __PILLAR__UPSTREAM__SERVERS__
prometheus :9253
}
……
该资源清单文件中包含几个变量值得注意,其中:
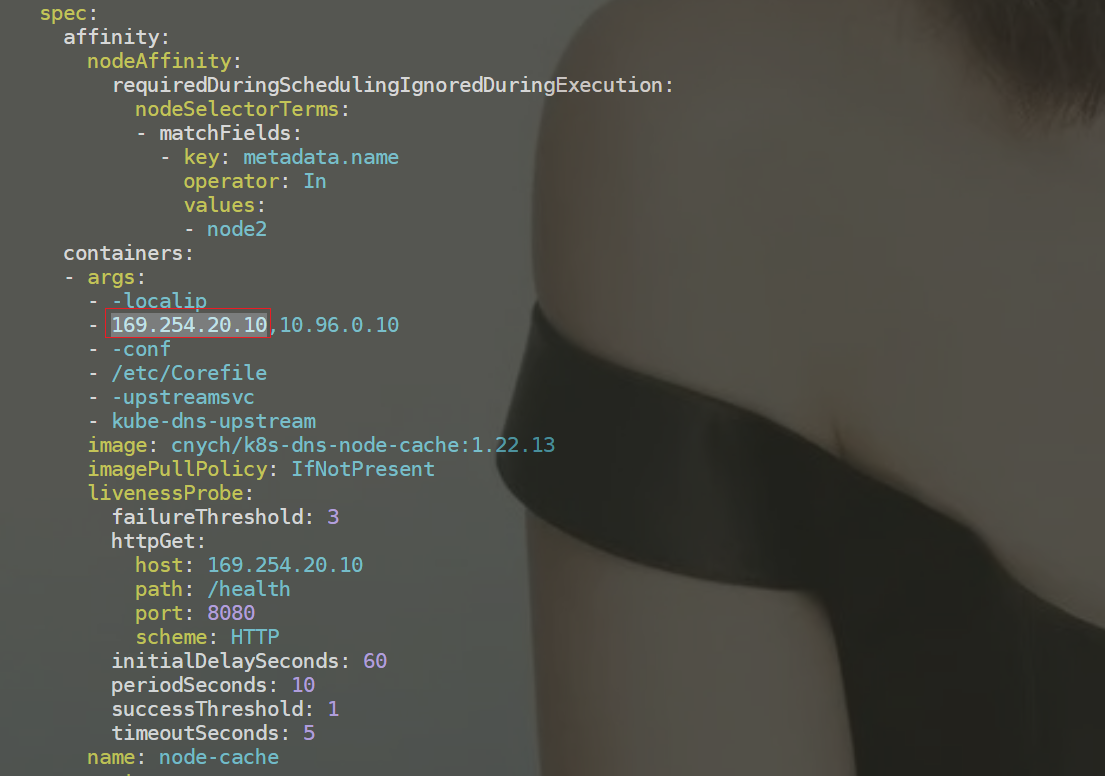
__PILLAR__DNS__SERVER__:表示 kube-dns 这个 Service 的 ClusterIP,可以通过命令kubectl get svc -n kube-system | grep kube-dns | awk'{ print $3 }'获取(我们这里就是10.96.0.10)__PILLAR__LOCAL__DNS__:表示 DNSCache 本地监听的 IP 地址,该地址可以是任何地址,只要该地址不和你的集群里现有的 IP 地址发生冲突。 推荐使用本地范围内的地址,例如 IPv4 链路本地区段 169.254.0.0/16 内的地址(默认一般取 169.254.20.10 即可),或者 IPv6 唯一本地地址区段fd00::/8内的地址__PILLAR__DNS__DOMAIN__:表示集群域,默认就是cluster.local
另外还有两个参数 __PILLAR__CLUSTER__DNS__ 和 __PILLAR__UPSTREAM__SERVERS__,这两个参数会进行自动配置,对应的值来源于 kube-dns 的 ConfigMap 和定制的 Upstream Server 配置。
2.部署资源
- ⚠️ 这里需要注意的是镜像版本,本次使用
k8s-dns-node-cache:1.21.1版本
直接执行如下所示的命令即可安装:
sed 's/k8s.gcr.io\/dns/cnych/g
s/__PILLAR__DNS__SERVER__/10.96.0.10/g
s/__PILLAR__LOCAL__DNS__/169.254.20.10/g
s/__PILLAR__DNS__DOMAIN__/cluster.local/g' nodelocaldns.yaml |
kubectl apply -f -
#注意:这个使用的是老师的镜像中转地址cnych。
- 可以通过如下命令来查看对应的 Pod 是否已经启动成功:
[root@k8s-master1 ~]#kubectl get po -nkube-system -l k8s-app=node-local-dns -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
node-local-dns-bsl2n 1/1 Running 0 35h 172.29.9.32 k8s-node1 <none> <none>
node-local-dns-gnjnw 1/1 Running 0 35h 172.29.9.31 k8s-master1 <none> <none>
node-local-dns-z4cpj 1/1 Running 0 35h 172.29.9.33 k8s-node2 <none> <none>
3.测试
- 我们导出来一个pod看下情况:
[root@master1 ~]#kubectl get po node-local-dns-6mhj8 -nkube-system -oyaml
这里可以看到显示从169.254.20.10解析地址,如果没有再去找10.96.0.10的。

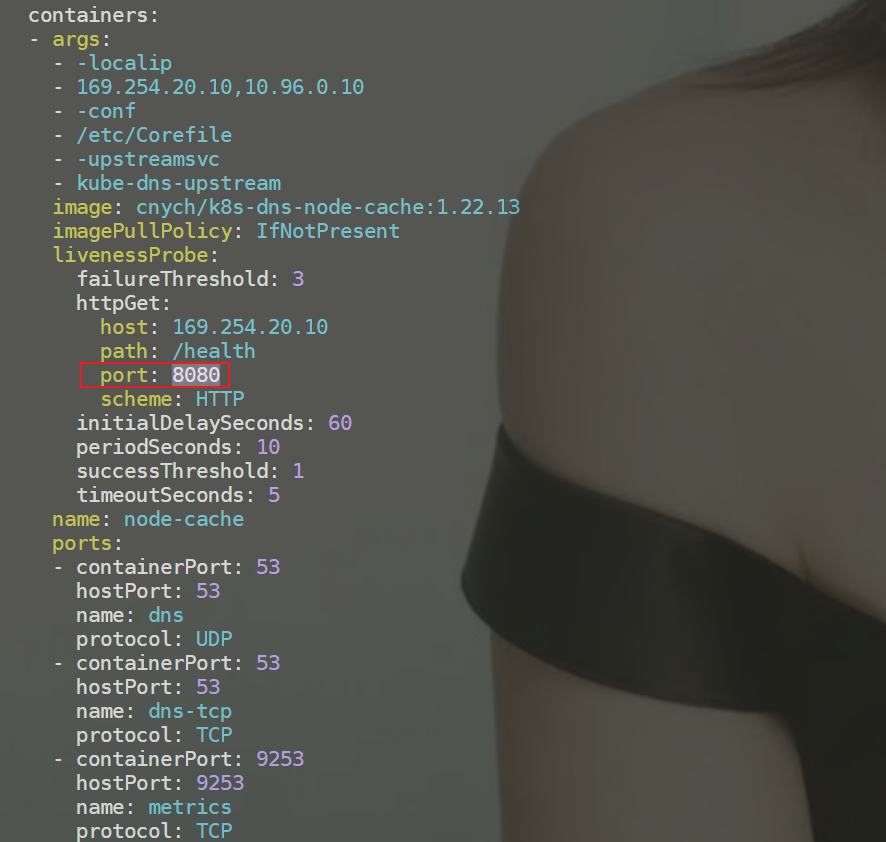
需要注意的是这里使用 DaemonSet 部署 node-local-dns 使用了 hostNetwork=true,会占用宿主机的 8080 端口,所以需要保证该端口未被占用。
4.修改 kubelet 的 --cluster-dns 参数
先来确认下当前kube-proxy组件使用的模式是什么?
[root@master1 NodeLocalDnsCache]#kubectl get cm kube-proxy -nkube-system -oyaml|grep mode
mode: ipvs
但是到这里还没有完,如果 kube-proxy 组件使用的是 ipvs 模式的话,我们还需要修改 kubelet 的 --cluster-dns 参数,将其指向 169.254.20.10,Daemonset 会在每个节点创建一个网卡来绑这个 IP,Pod 向本节点这个 IP 发 DNS 请求,缓存没有命中的时候才会再代理到上游集群 DNS 进行查询。
10: nodelocaldns: <BROADCAST,NOARP> mtu 1500 qdisc noop state DOWN group default
link/ether 6a:e9:a3:9b:03:a8 brd ff:ff:ff:ff:ff:ff
inet 169.254.20.10/32 scope global nodelocaldns
valid_lft forever preferred_lft forever
inet 10.96.0.10/32 scope global nodelocaldns
valid_lft forever preferred_lft forever
[root@master1 ~]#
**iptables 模式下 Pod 还是向原来的集群 DNS 请求,节点上有这个 IP 监听,会被本机拦截,再请求集群上游 DNS,所以不需要更改 **--cluster-dns参数。
- 由于我这里使用的是 kubeadm 安装的 1.20 版本的集群,所以我们只需要替换节点上
/var/lib/kubelet/config.yaml文件中的 clusterDNS 这个参数值,然后重启即可:
sed -i 's/10.96.0.10/169.254.20.10/g' /var/lib/kubelet/config.yaml
systemctl daemon-reload && systemctl restart kubelet
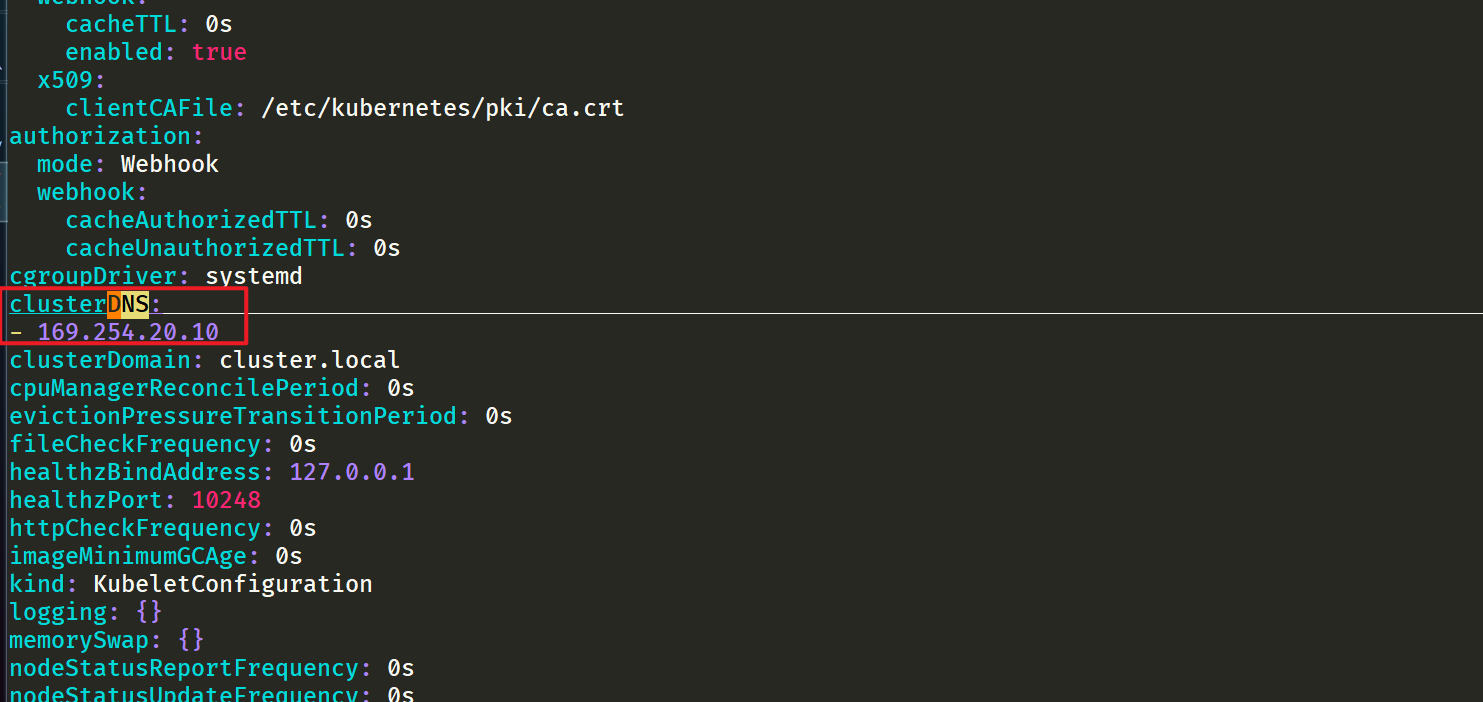
注意:all节点均要配置。
5.验证
- 待 node-local-dns 安装配置完成后,我们可以部署一个新的 Pod 来验证下:
# test-node-local-dns.yaml
apiVersion: v1
kind: Pod
metadata:
name: test-node-local-dns
spec:
containers:
- name: local-dns
image: busybox:1.28.3
command: ["/bin/sh", "-c", "sleep 60m"]
- 直接部署:
[root@master1 ~]#kubectl apply -f test-node-local-dns.yaml
pod/test-node-local-dns created
[root@master1 ~]#kubectl exec -it test-node-local-dns -- sh
/ # cat /etc/resolv.conf
search default.svc.cluster.local svc.cluster.local cluster.local
nameserver 169.254.20.10
options ndots:5
/ #
我们可以看到 nameserver 已经变成 169.254.20.10 了,当然对于之前的历史 Pod 要想使用 node-local-dns 则需要重建。
⚠️ 注意
如果担心线上环境修改
--cluster-dns参数会产生影响,我们也可以直接在新部署的 Pod 中通过 dnsConfig 配置使用新的 localdns 的地址来进行解析。
- 创建yaml文件
#test-node-local-dns-2.yaml
apiVersion: v1
kind: Pod
metadata:
name: test-node-local-dns-2
spec:
dnsPolicy: None #None的时候需要配置下面的dnsConfig
dnsConfig:
nameservers: # 如果dnsPolicy不等于None,则会将nameservers合并到原有的(dnsPolicy默认是ClusterFirst)
- 169.254.20.10
searches:
- default.svc.cluster.local
- svc.cluster.local
- cluster.local
options:
- name: ndots
value: "5"
containers:
- name: test
image: cnych/jessie-dnsutils:1.3
command:
- sleep
- "infinity"
imagePullPolicy: IfNotPresent
- 部署
[root@master1 ~]#kubectl apply -f test-node-local-dns-2.yaml
root@master1 ~]#kubectl exec -it test-node-local-dns-2 -- bash
# cat /etc/resolv.conf
search default.svc.cluster.local svc.cluster.local cluster.local
nameserver 169.254.20.10
options ndots:5
#
- 我们可以看到 nameserver 已经变成 169.254.20.10 了,同样简单测试下是否可以正常工作:
[root@k8s-master1 ~]#kubectl exec -it test-node-local-dns-2 -- bash
root@test-node-local-dns-2:/# cat /etc/resolv.conf
nameserver 169.254.20.10
search default.svc.cluster.local svc.cluster.local cluster.local
options ndots:5
root@test-node-local-dns-2:/# nslookup youdianzhishi.com
Server: 169.254.20.10
Address: 169.254.20.10#53
Non-authoritative answer:
Name: youdianzhishi.com
Address: 39.106.22.102
root@test-node-local-dns-2:/# nslookup kubernetes.default
Server: 169.254.20.10
Address: 169.254.20.10#53
Name: kubernetes.default.svc.cluster.local
Address: 10.96.0.1
root@test-node-local-dns-2:/#
⚠️ 说明:以下步骤是之前实验测试保留的数据。
6.重建前面压力测试 DNS 的 Pod
接下来我们重建前面压力测试 DNS 的 Pod,重新将 testdns 二进制文件拷贝到 Pod 中去:
[root@master1 ~]#kubectl delete -f nginx.yaml
deployment.apps "nginx" deleted
[root@master1 ~]#kubectl apply -f nginx.yaml
deployment.apps/nginx created
[root@master1 ~]#kubectl get po
NAME READY STATUS RESTARTS AGE
nginx-5d59d67564-kgd4q 1/1 Running 0 22s
nginx-5d59d67564-lxnt2 1/1 Running 0 22s
test-node-local-dns 1/1 Running 0 5m50s
[root@master1 ~]#kubectl cp go/testdns nginx-5d59d67564-kgd4q:/root
[root@master1 ~]#kubectl exec -it nginx-5d59d67564-kgd4q -- bash
root@nginx-5d59d67564-kgd4q:/# cd /root/
root@nginx-5d59d67564-kgd4q:~# ls
testdns
root@nginx-5d59d67564-kgd4q:~# cat /etc/resolv.conf
search default.svc.cluster.local svc.cluster.local cluster.local
nameserver 169.254.20.10
options ndots:5
root@nginx-5d59d67564-kgd4q:~#
#自己本次的测试数据
#再次压测
#先来个200个并发,测试三次
root@nginx-5d59d67564-kgd4q:~# ./testdns -host nginx-service.default -c 200 -d 30 -l 5000
request count:47344
error count:0
request time:min(1ms) max(976ms) avg(125ms) timeout(0n)
root@nginx-5d59d67564-kgd4q:~# ./testdns -host nginx-service.default -c 200 -d 30 -l 5000
request count:49744
error count:0
request time:min(1ms) max(540ms) avg(118ms) timeout(0n)
root@nginx-5d59d67564-kgd4q:~# ./testdns -host nginx-service.default -c 200 -d 30 -l 5000
request count:55929
error count:0
request time:min(2ms) max(463ms) avg(105ms) timeout(0n)
root@nginx-5d59d67564-kgd4q:~#
root@nginx-5d59d67564-kgd4q:~#
#再来个1000个并发,测试三次
root@nginx-5d59d67564-kgd4q:~# ./testdns -host nginx-service.default -c 1000 -d 30 -l 5000
request count:42177
error count:0
request time:min(16ms) max(2627ms) avg(690ms) timeout(0n)
root@nginx-5d59d67564-kgd4q:~# ./testdns -host nginx-service.default -c 1000 -d 30 -l 5000
request count:45456
error count:0
request time:min(29ms) max(2484ms) avg(650ms) timeout(0n)
root@nginx-5d59d67564-kgd4q:~# ./testdns -host nginx-service.default -c 1000 -d 30 -l 5000
request count:45713
error count:0
request time:min(3ms) max(1698ms) avg(647ms) timeout(0n)
root@nginx-5d59d67564-kgd4q:~#
#注意:这个1000并发测试效果就很明显了

老师笔记的测试数据:
# 拷贝到重建的 Pod 中
$ kubectl cp testdns svc-demo-546b7bcdcf-b5mkt:/root
$ kubectl exec -it svc-demo-546b7bcdcf-b5mkt -- /bin/bash
root@svc-demo-546b7bcdcf-b5mkt:/# cat /etc/resolv.conf
nameserver 169.254.20.10 # 可以看到 nameserver 已经更改
search default.svc.cluster.local svc.cluster.local cluster.local
options ndots:5
root@svc-demo-546b7bcdcf-b5mkt:/# cd /root
root@svc-demo-546b7bcdcf-b5mkt:~# ls
testdns
# 重新执行压力测试
root@svc-demo-546b7bcdcf-b5mkt:~# ./testdns -host nginx-service.default -c 200 -d 30 -l 5000
request count:16297
error count:0
request time:min(2ms) max(5270ms) avg(357ms) timeout(8n)
root@svc-demo-546b7bcdcf-b5mkt:~# ./testdns -host nginx-service.default -c 200 -d 30 -l 5000
request count:15982
error count:0
request time:min(2ms) max(5360ms) avg(373ms) timeout(54n)
root@svc-demo-546b7bcdcf-b5mkt:~# ./testdns -host nginx-service.default -c 200 -d 30 -l 5000
request count:25631
error count:0
request time:min(3ms) max(958ms) avg(232ms) timeout(0n)
root@svc-demo-546b7bcdcf-b5mkt:~# ./testdns -host nginx-service.default -c 200 -d 30 -l 5000
request count:23388
error count:0
request time:min(6ms) max(1130ms) avg(253ms) timeout(0n)
7.总结
从上面的结果可以看到无论是最大解析时间还是平均解析时间都比之前默认的 CoreDNS 提示了不少的效率,NodeLocal DNSCache 可以提升 DNS 的性能和可靠性的,所以也非常推荐用在生产环境,唯一的缺点就是由于LocalDNS 使用的是 DaemonSet 模式部署,所以如果需要更新镜像则可能会中断服务(不过可以使用一些第三方的增强组件来实现原地升级解决这个问题,比如 openkruise)。
阿里云也是比较推荐线上去部署这个的。
测试结束。😘
关于我
我的博客主旨:
- 排版美观,语言精炼;
- 文档即手册,步骤明细,拒绝埋坑,提供源码;
- 本人实战文档都是亲测成功的,各位小伙伴在实际操作过程中如有什么疑问,可随时联系本人帮您解决问题,让我们一起进步!
🍀 微信二维码
x2675263825 (舍得), qq:2675263825。

🍀 微信公众号
《云原生架构师实战》

🍀 csdn
https://blog.csdn.net/weixin_39246554?spm=1010.2135.3001.5421

🍀 知乎
https://www.zhihu.com/people/foryouone
最后
好了,关于本次就到这里了,感谢大家阅读,最后祝大家生活快乐,每天都过的有意义哦,我们下期见!
















 115
115











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









