






前言
要学习ANTLR4,首先需要知道antlr是干什么的?
ANTLR(全称:ANother Tool for Language Recognition)是目前非常流行的语言识别工具,使用Java语言编写,基于LL(*)解析方式,使用自上而下的递归下降分析方法。通过输入语法描述文件来自动构造自定义语言的词法分析器、语法分析器和树状分析器等各个模块。ANTLR使用上下无关文法描述语言,文法定义使用类似EBNF的方式。
所有编程语言的语法,都可以用ANTLR来定义。ANTLR提供了大量的官方grammar示例,包含了各种常见语言,比如Java、SQL、Javascript、PHP等等。ANTLR的应用非常广泛,比如Hive、Presto和SparkSQL等的SQL Parser模块都是基于ANTLR构建的。
LL是自顶向下(top-down)的语法分析方法,其中的第一个L表示分析器从左(Left)至右单向读取每行文本,第二个L表示最左派生(Leftmost derivation),ANTLR生成的就是LL分析器。
ALL全称:ALL Adaptive LL(*),是一种名为自适应的 LL(*)的新技术。ALL(*)是 ANTLR3 中 LL(*)的扩展,在实际生成的语法分析器执行之前,它能够在运行时以动态方式对语法执行分析,而非先前的静态方式。
一、Grammar语法定义
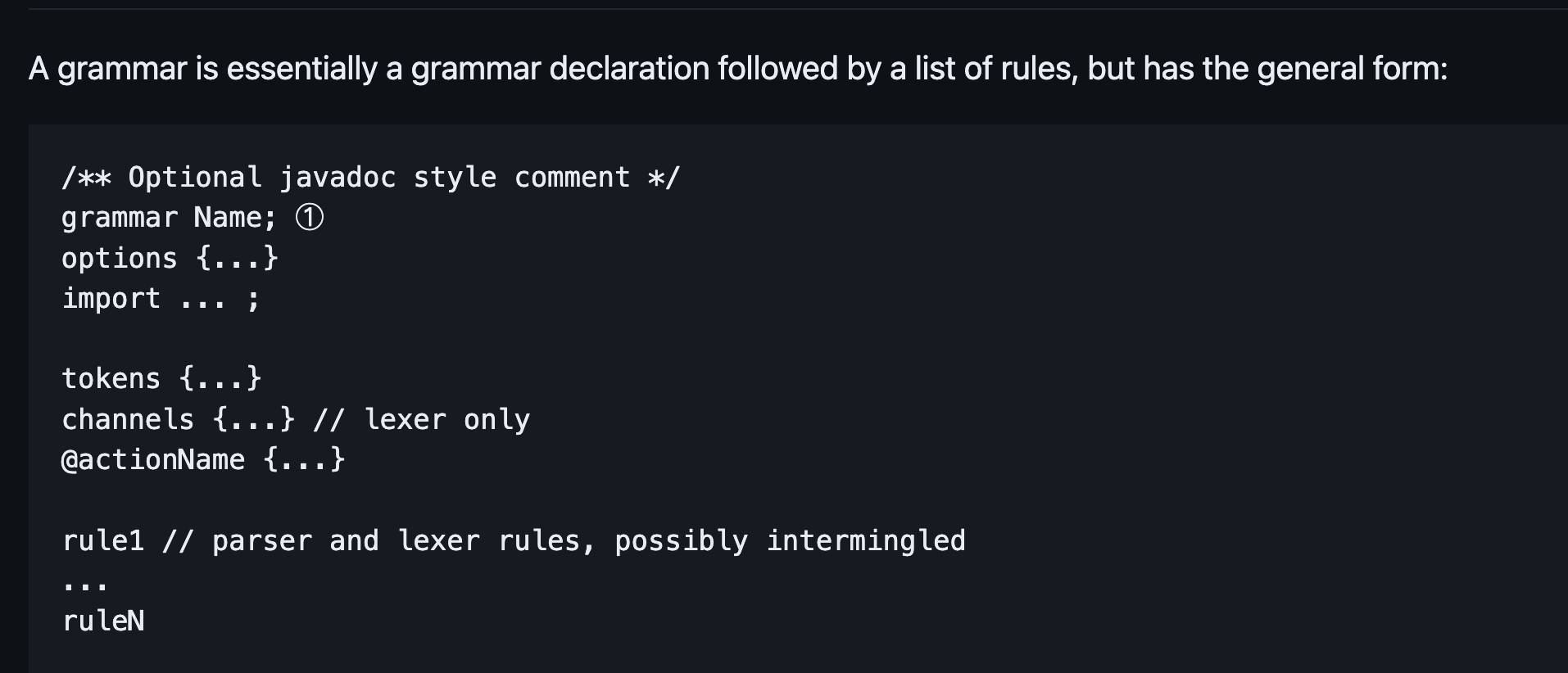
- 语法名称XXX必须和文件XXX.g4一致。
- 分为词法规则和语法(文法)规则:文法规则和词法规则可以同时存在一个文件中,但文法以小写开头,词法以大写开头。
- 我们在构建一个语法文件时,一般是先考虑文法,再考虑词法。就像是我们造句,先会考虑句子的结构,再往里面填词。但是实际语法分析的过程是:输入流先经过词法分析器生成匹配的词法符号流,词法符号流经过语法分析器生成匹配的语法结构。
- 必须有个名称(grammar Name;)和最少一个语法规则。
- 可以无序指定options、import、token和Actions,但是只能最多一次。
- 如果grammar没有前缀lexer 或者parser ,这个语法文件可以包含词法和语法规则。
- 如果前缀是lexer这个文件只能包含词法规则,如果是parser这个文件只能包含语法规则
例如语法规则名:parser grammar Name;
例如词法规则名:lexer grammar Name;
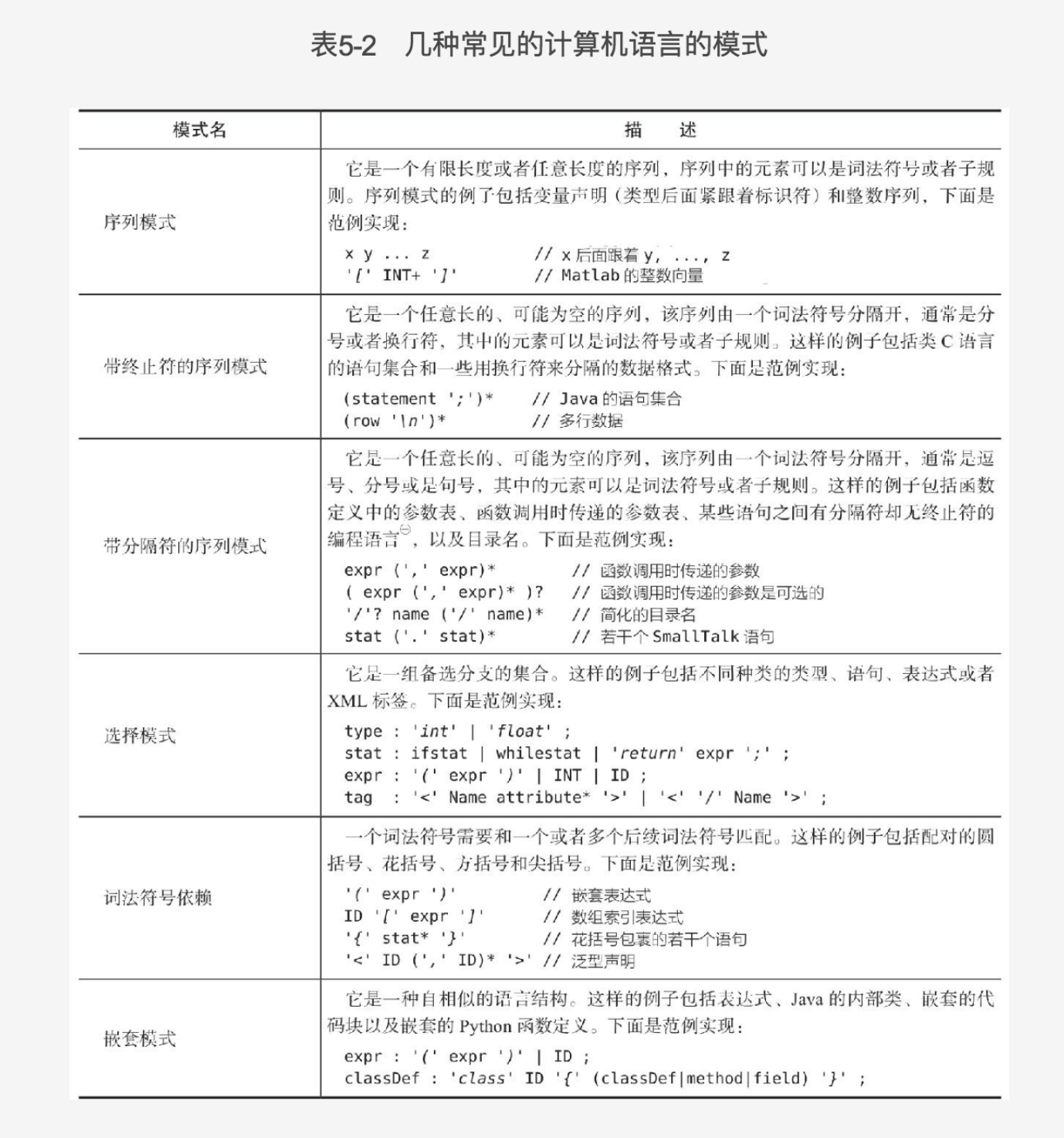
- antlr4中支持的关键字:import, fragment, lexer, parser, grammar, returns, locals, throws, catch, finally, mode, options, tokens。
二、ANTLR4的改进
- 语法上的改进,ALL(*)(读作“all star”)是ANTLR3中的LL(*)的扩展,在实际生成的语法分析器执行前,它能够在运行时以动态方式对语法执行分析,而非先前的静态方式
- ANTLR4极大的简化了匹配某些句法结构(如编程语言中的算术表达式)所需的语法规则
- 最大的改变是ANTLR4降低了语法中内嵌动作(代码)的重要性,取而代之的是监听器和访问器
- 由于ANTLR能够自动生成语法分析树和树的遍历器,在ANTLR4中,你无需再编写树语法,取而代之的是一些广为人知的设计模式,如访问者模式
- ANTLR3的LL(*)语法分析策略不如ANTLR4的ALL(*)强大,所以ANTLR3位了能够正确识别输入的文本,有时候不得不进行回溯,回溯的存在使得语法的调试格外困难
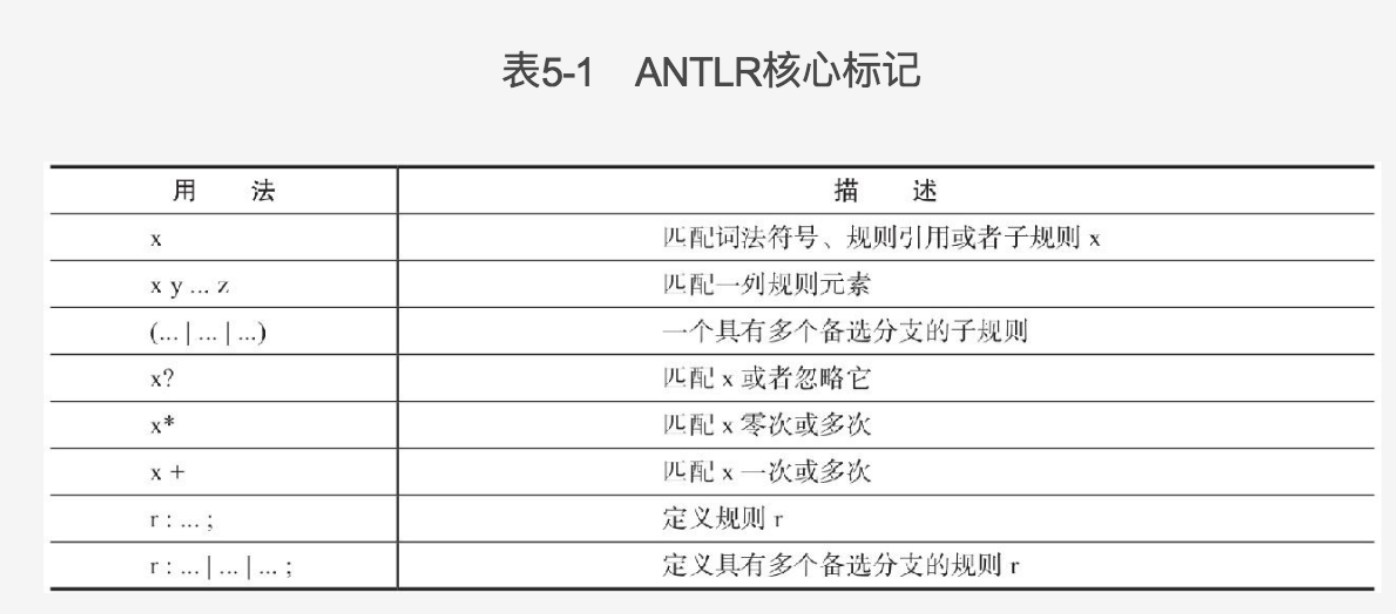
三、常用的ANTLR语言模式
- 序列模式,即一系列元素
file : (row '\n')* ; // 以一个'\n'作为终止符的序列
row : field (',' field)*; // 以一个','作为终止符的序列
field: INT; // 假设字段都是整数- 选择模式,在多个可选方案中做出选择:一条规则往往有多个分支,我们可以采用|符号
stmt: node_stmt
| edge_stmt
| attr_stmt
| id '=' id
|subgraph
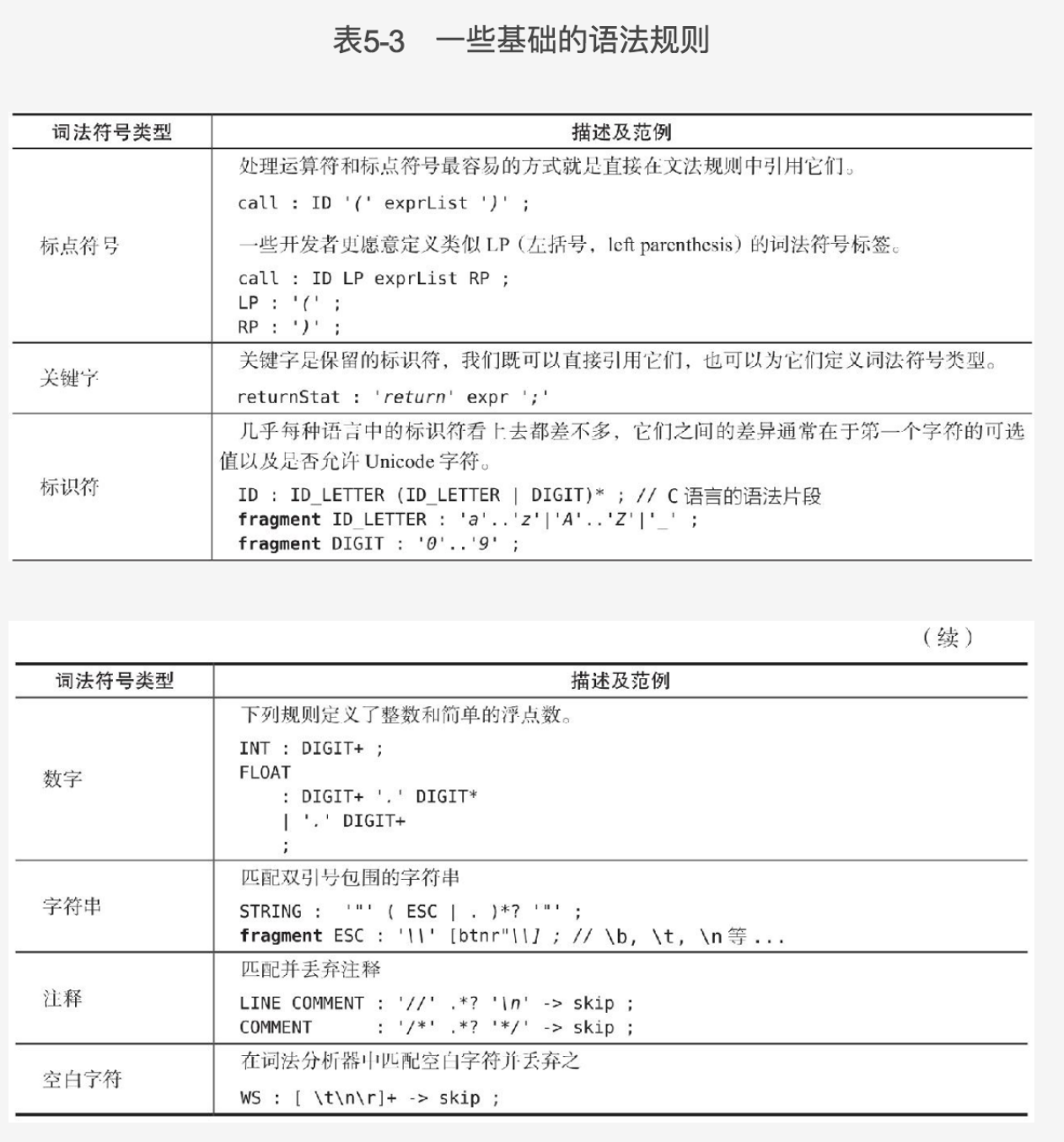
;- 词法符号以来,一个词法符号需要和某处另一个词法符号配对:非常常见,]需要匹配之前的[,}需要匹配之前的{。这种符号之前的依赖在ANTLR是自动完成的,我们只需要在文法规则中通过单引号支出即可。
expr: expr '(' exprList? ')' // 类似f(), f(x), f(1,2) 的函数调用
| expr '[' expr ']' //类似a[i], a[i][j]的数组索引
...
;- 嵌套结构,一种自相似的语言结构:往往与之前的词法符号依赖一起出现,因为嵌套本身是要通过各种括号实现
expr: ID '[' expr ']' // a[1], a[b[1]], a[(2*b[1])]
| '(' expr ')' // (1), (a(1)), (((1))), (2*a[1])
| INT // 1, 323
;
四、语法解读原则
最左匹配原则
如果如下g4语法
...
expr: expr '*' expr # MulDiv
| expr '+' expr # AddSub
| INT # int
;
INT : [0-9]+ ; 提问:上面的规则合理吗?
答:看起来合理,但是如果你把你的表达式放进去套用,发现上面的规则存在歧义。像1+2这种简单的整数表达式和单运算符表达式上,是绝对没有问题的,因为它只存在一种方式去匹配,只能用第二个备选分支去匹配,如图 4-1最左侧的语法分析树。但是对于1+2*3这种输入而言,上述规则能够用两种方式解释它,如图 4-1中间和右侧的语法分析树所示。
其实这就是运算符优先级带来的问题,传统的语法是无法指定优先级的。大多数语法工具,使用额外的标记来指定运算符优先级。但是,我们ANTLR通过优先选择位置靠前的备选分支来解决歧义问题,乘法规则在加法规则之前,所以ANTLR在解决1+2*3的歧义问题时会优先处理乘法。
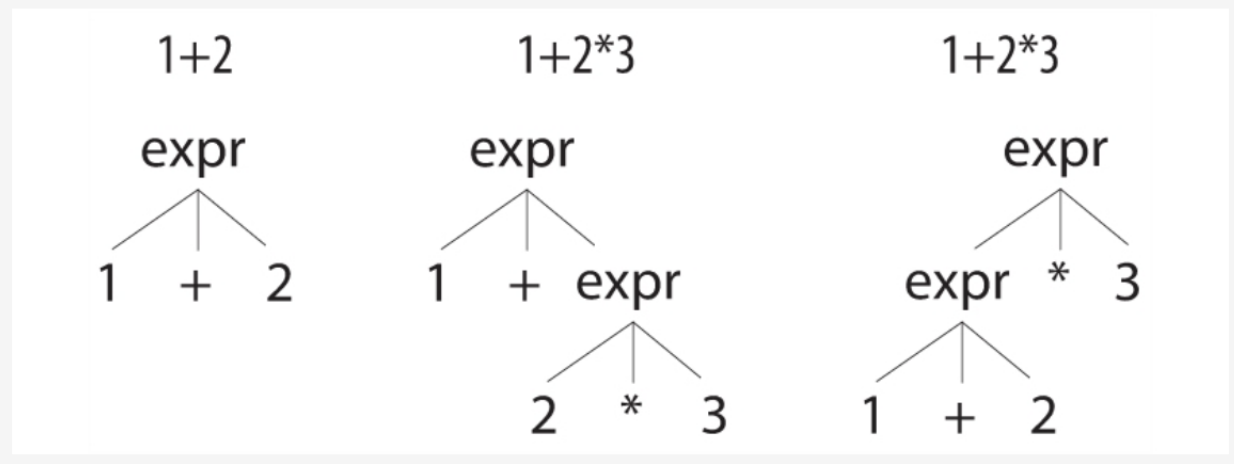
图 4-1 按照不同方式解释的语法分析树
但是如果我们将语法的备选分支交换一下位置呢?我们再输入1+2*3还能按照我们希望的优先级执行吗?
另外,如果我们遇到了指数运算符这样的计算呢?如果还按照从左到右的将运算符结合,明显是不行的。
这个时候就要在这样的运算符上使用assoc选项手工指定结合性,这样假设输入2^3^4才能够正确的被解释为2^(3^4):
expr: expr '^' <assoc=right> expr // 在ANTLR4.2之后<assoc=right>放到备选分支最左侧,否则会收到警告:<assoc=right> expr '^'expr
| INT
;
INT : [0-9]+ ;虽然ANTLR4已经能够处理直接左递归,但是它还无法处理间接左递归,所以我们无法将expr规则分解为下列规则,虽然语义上等价:
expr : expo
| ...
;
expo : expr '^'<assoc=right> expr;五、如何使用
1、安装Java包(要装JDK,而非JRE。java version "20.0.2" 2023-07-18)
2、安装antlr4(version 4.7.2)
$ cd /usr/local/lib
$ sudo curl -O https://www.antlr.org/download/antlr-4.7.2-complete.jar
// 设置环境变量
$ vim .bash_profile
$ export CLASSPATH=".:/usr/local/lib/antlr-4.7.2-complete.jar:$CLASSPATH"
$ alias antlr4='java -jar /usr/local/lib/antlr-4.7.2-complete.jar'
$ alias grun='java org.antlr.v4.gui.TestRig' // antlr4.0版本时用 org.antlr.v4.runtime.misc.TestRig
// TestRig 调试工具
$ wq! // 保存
$ source .bash_profile
$ antlr4

3、新建一个hello.g4文件,执行
grammar hello;
@header { package com.pioneeryi.learn.antlr; }
s : 'hello' ID ;
ID : [a-z]+ ;
WS : [ \t\r\n]+ -> skip ;||
||
\ /
$ antlr4 Hello.g4 // 生成语法分析器和词法分析器||
||
\ /

||
||
\ /
$ javac Hello*.java // 编译antlr生成的Java代码||
||
\ /

||
||
\ /

||
||
\ /

||
||
\ /

以上是一个示例以及解析出来的语法树
参考文献:

















 7374
7374

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









